emoji字符无法写入mysql数据库问题
 从处理日志发现有些字无法入库,类似以前遇到的数据源与目的数据库字段字符集不同导致的一样;字符集统一都是utf8,不应该是上述情况导致。
从处理日志发现有些字无法入库,类似以前遇到的数据源与目的数据库字段字符集不同导致的一样;字符集统一都是utf8,不应该是上述情况导致。Incorrect string value: '\xF0\x9F\x91\x8D' for column 'free_oa' at row 1
Incorrect string value: '\xF0\x9F\x8E\xB6\xF0\x9F…'
General error: 1366 Incorrect string value: '\xF0\x9F\x99\x80-e...' for column 'alias' at row 1
在Google上的查证,\xF0\x9F开头的确实是UTF8字符集范围;UTF8长度是2-4个字节,我们在Mysql常用的是2-3个字节长,但这个抛出来的错误显示是4个字节,所以就错在这了(用java写代码也会报同样错误,原因是jdbc在做数据插入前会严格检查字段的类型、长度,一但不符就会抛出异常;php在这方面稍微自作聪明点,会把多出来的字节截掉,但对数据本身就是丢掉了信息)。
种字符属于emoji表情符,关于emoji是什么,点这里有百度百科中可以找到。
找到问题就好办了,将字段的字符集改为utf8mb4,数据库工具连接高级设置中,设置当前会话字符集为utf8mb4,基本上可解决此问题,但前提是该工具必须内置支持utf8mb4码,不然依然可能不能正常显示(会以问号或其它看上去像乱码的字符替代或直接留空)。Mysql中的utf8实际上是UTF8标准的子集,涵盖到:0xFFFF,甚至utf8mb4也未能全部包括所有的UTF8字符,因为这个字符集标准目前仍然在扩展,目前是第8版。
经过这次问题,以后有些字段有必要考虑设置成utf8mb4字符集来支持更广阔的字符内容,缺点显而易见,就是多占空间了。是否采用,视具体情况而定吧。需要注意的是,utf8的字符空间目前还在增加,如果承载数据的软件对此不支持的话,那么该字符就不能正常地显示了。比如在win7 x64 sp1的系统里网页里能正常显示(网页浏览器应该是目前支持最好的最新字符集支持软件了),复制到notepad++,office 2007,libreoffice,navicat,dbeaver这些软件中都不能支持这些新的emoji字符;在xshell终端中用mysql指令访问数据库中的内容在utf-8的字符环境下,这些新的emoji字符依然不能显示。因此笔者认为:数据处理前及处理后要正常显示需要承载数据的数据软件支持才行,中间处理过程中只要将对应的数据流的编码设置正确即可。
要无痛地支持这些表情符号,需要将库、表、列、连接过程的字符集都设置为utf8mb4,即全部强制为4字节的宽度。
查看当前系统的字符类型:
mysql> SHOW CHARACTER SET;
mysql> SHOW VARIABLES LIKE 'character%';
mysql> show variables like "%coll%";
确保utf8mb4在数据库系统(5.5.3以上)中存在:
mysql> select * from information_schema.character_sets where CHARACTER_SET_NAME like 'utf8%';
修改配置文件my.cnf并在终端会话中指定会话级字符编码:
[client]
default-character-set=utf8mb4
[mysqld]
character-set-server = utf8mb4
[mysql]
default-character-set=utf8mb4
>mysql -uroot -p --default-character-set=utf8mb4
>SET NAMES utf8mb4;
ALTER DATABASE freeoa_db CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci;
看看结果如何:
SHOW VARIABLES WHERE Variable_name LIKE 'character%' OR Variable_name LIKE 'collation%';
将字段的字符集设置成与库一样的:
ALTER DATABASE MyDB CHARACTER SET 'utf8' COLLATE 'utf8_unicode_ci';
ALTER TABLE database.table MODIFY COLUMN column_name VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL;
补充:
在java web应用中,可在数据源配置中增加配置项来实现
<property name="connectionInitSqls" value="set names utf8mb4;"/>
java驱动使用
Java语言里面所实现的UTF-8编码就是支持4字节的,所以不需要配置 mb4 这样的字眼,但如果从MySQL读写emoji,MySQL驱动版本要在 5.1.13 及以上版本,数据库连接依然是 characterEncoding=UTF-8 。
但还没完,官方手册 里还有这么一段话:
Connector/J did not support utf8mb4 for servers 5.5.2 and newer.
Connector/J now auto-detects servers configured with character_set_server=utf8mb4 or treats the Java encoding utf-8 passed using characterEncoding=... as utf8mb4 in the SET NAMES= calls it makes when establishing the connection. (Bug #54175)
意思是,java驱动会自动检测服务端 character_set_server 的配置,如果为utf8mb4,驱动在建立连接的时候设置 SET NAMES utf8mb4。然而其他语言没有依赖于这样的特性。
将现行utf8的库环境转为utf8mb4
首先,最关键的是即时的备份,其次将mysql服务器版本升级到5.5.3以上
# For each database:
ALTER DATABASE
database_name
CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
# For each table:
ALTER TABLE
table_name
CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# For each column:
ALTER TABLE
table_name
CHANGE column_name column_name
VARCHAR(191)
CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
char,varchar, text, tinytext, mediumtext, longtext这些类型字段是其处理的重点,但同时要注意字段的长度是否够用。如果出现下面的错误,则要可能修改字段长度。
I had some varchar(255) columns in mysql keys. This causes an error:
ERROR 1071 (42000) at line 2229: Specified key was too long; max key length is 767 bytes
If that happens you can simply change the column to be smaller, like varchar(150), and rerun the command.
The InnoDB storage engine has a maximum index length of 767 bytes.
修改成功后,将到新的数据库连接的字符编码设定为utf8mb4,必要时修改配置文件(my.cnf):
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
最后将那些已经修改好的表修复优化一遍,确保万无一失。
# For each table
REPAIR TABLE table_name;
OPTIMIZE TABLE table_name;
如果可能的话,执行一次mysqlcheck utility,对全库优化:
mysqlcheck -u root -p --auto-repair --optimize --all-databases
见于目前浏览器是对该字符集的最新版本有很好的支持,这里提供一个Perl的Web界面脚本,采用Mojolicious::Lite开发,供大家测试:
use v5.12;
use utf8;
use DBI;
use DBD::mysql;
use Encode;
use Storable;
use Mojo::Log;
use Data::Dumper;
use Mojolicious::Lite;
binmode(STDOUT, ":encoding(utf8)");
# Init&Conn mysql db
my ($mdb,$tab,$dbhost,$dbuser,$dbpaswd)=('ubm','un','192.168.30.20','admin','freeoa.net');
#mysql obj attr
my %mydbattr=(RaiseError=>1,AutoCommit=>0,mysql_enable_utf8=>1,RaiseError=>1);
my $dbh=DBI->connect_cached("DBI:mysql:database=$mdb;host=$dbhost",$dbuser,$dbpaswd,\%mydbattr) or die $DBI::errstr;
$dbh->do("set names utf8mb4");
sub getrs{
my $getsql="select * from $tab";
my $rs=$dbh->selectall_arrayref($getsql);
return $rs;
};
sub inserted{
my $name=shift;
my $insql=qq{INSERT INTO un VALUES("$name");};
$dbh->do("$insql") or warn $dbh->errstr;
say $dbh->trace;
say "$insql has complete.";
return 1;
};
# setup base route
any '/' => sub {
my $self = shift;
$self->stash( rows => getrs() );
$self->render('index');
};
# setup route which receives data and returns to /
any '/insert' => sub {
my $self = shift;
my $name = $self->param('name');
my $rc=inserted($name);
$self->redirect_to('/');
};
app->start;
__DATA__
@@ index.html.ep
<!DOCTYPE html>
<html>
<head><title>People</title></head>
<body>
<form action="<%=url_for('insert')->to_abs%>" method="post">
内容: <input type="text" name="name">
<input type="submit" value="提交">
</form>
<br>
Data: <br>
<table border="1">
<tr>
<th>Name</th>
</tr>
% foreach my $row (@$rows) {
<tr>
% foreach my $text (@$row) {
<td><%= $text %></td>
% }
</tr>
% }
</table>
</body>
</html>
注意:在脚本中,mysql连接选项mysql_enable_utf8=>1和'set names utf8mb4'都是必须的。在mysql中用length函数与在perl中使用length函数取其长度,结果也是不样的(同样也还受制于mysql_enable_utf8参数):
my $getsql="select * from $tab";
my $rs=$dbh->selectcol_arrayref($getsql);
printf "string: %s length: %d\n", $_, gl($_) for @$rs;
sub gl{
#$_[0] =~ tr/ //c;
length join '', split / /, $_[0];
}
在脚本中不强制指定输出为utf8时,还可能报出如下的警告:
Unicode surrogate U+D834 is illegal in UTF-8 at u8m4.len.pl line 24.
Unicode surrogate U+DF06 is illegal in UTF-8 at u8m4.len.pl line 24.
"\x{d834}" does not map to utf8 at u8m4.len.pl line 24.
"\x{df06}" does not map to utf8 at u8m4.len.pl line 24.
下面再来总结utf8 与 utf8mb4 异同
先来看官方手册中的说明:
The character set named utf8 uses a maximum of three bytes per character and contains only BMP characters. The utf8mb4 character set uses a maximum of four bytes per character supports supplementary characters:
- For a BMP character, utf8 and utf8mb4 have identical storage characteristics: same code values, same encoding, same length.
- For a supplementary character, utf8 cannot store the character at all, whereas utf8mb4 requires four bytes to store it. Because utf8 cannot store the character at all, you have no supplementary characters in utf8 columns and need not worry about converting characters or losing data when upgrading utf8 data from older versions of MySQL.
MySQL在 5.5.3 之后增加了 utf8mb4 字符编码,mb4即 most bytes 4。简单说 utf8mb4 是 utf8 的超集并完全兼容utf8,能够用四个字节存储更多的字符。
但抛开数据库,标准的 UTF-8 字符集编码是可以用 1~4 个字节去编码21位字符,这几乎包含了是世界上所有能看见的语言了。然而在MySQL里实现的utf8最长使用3个字节,也就是只支持到了 Unicode 中的 基本多文本平面(U+0000至U+FFFF),包含了控制符、拉丁文,中、日、韩等绝大多数国际字符,但并不是所有,最常见的就算现在手机端常用的表情字符 emoji和一些不常用的汉字,如 "墅" ,这些需要四个字节才能编码出来。
也就是当你的数据库里要求能够存入这些表情或宽字符时,可以把字段定义为 utf8mb4,同时要注意连接字符集也要设置为utf8mb4,否则在严格模式下会出现 Incorrect string value: /xF0/xA1/x8B/xBE/xE5/xA2… for column 'name'这样的错误,非严格模式下此后的数据会被截断。
提示:另外一种能够存储emoji的方式是,不关心数据库表字符集,只要连接字符集使用 latin1,但相信我,你绝对不想这个干,一是这种字符集混用管理极不规范,二是存储空间被放大。
注意:QQ里面的内置的表情不算,它是通过特殊映射到的一个gif图片,一般输入法自带的就是。
utf8mb4_unicode_ci 与 utf8mb4_general_ci 如何选择
字符除了需要存储,还需要排序或比较大小,涉及到与编码字符集对应的 排序字符集(collation)。ut8mb4对应的排序字符集常用的有 utf8mb4_unicode_ci、utf8mb4_general_ci,到底采用哪个在 stackoverflow 上有个讨论,What’s the difference between utf8_general_ci and utf8_unicode_ci
主要从排序准确性和性能两方面看:
准确性
utf8mb4_unicode_ci 是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序
utf8mb4_general_ci 没有实现Unicode排序规则,在遇到某些特殊语言或字符是,排序结果可能不是所期望的。
但是在绝大多数情况下,这种特殊字符的顺序一定要那么精确吗。比如Unicode把ß、Œ当成ss和OE来看;而general会把它们当成s、e,再如ÀÁÅåāă各自都与 A 相等。
性能
utf8mb4_general_ci 在比较和排序的时候更快
utf8mb4_unicode_ci 在特殊情况下,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
但是在绝大多数情况下,不会发生此类复杂比较。general理论上比Unicode可能快些,但相比现在的CPU来说,它远远不足以成为考虑性能的因素,索引涉及、SQL设计才是。 我个人推荐是 utf8mb4_unicode_ci,将来 8.0 里也极有可能使用变为默认的规则。相比选择哪一种collation,使用者应该更关心字符集与排序规则在db里要统一就好。
这也从另一个角度告诉我们,不要可能产生乱码的字段作为主键或唯一索引。
从utf8转换为utf8mb4
1、"伪"转换
如果你的表定义和连接字符集都是utf8,那么直接在你的表上执行:
ALTER TABLE tbl_name CONVERT TO CHARACTER SET utf8mb4;
则能够该表上所有的列的character类型变成 utf8mb4,表定义的默认字符集也会修改。连接的时候需要使用set names utf8mb4便可以插入四字节字符。(如果依然使用 utf8 连接,只要不出现四字节字符则完全没问题)。
上面的 convert 有两个问题,一是它不能ONLINE,也就是执行之后全表禁止修改,有关这方面的讨论见 mysql 5.6 原生Online DDL解析;二是它可能会自动该表字段类型定义,如 VARCHAR 被转成 MEDIUMTEXT,可以通过 MODIFY 指定类型为原类型。
另外 ALTER TABLE tbl_name DEFAULT CHARACTER SET utf8mb4 这样的语句就不要随便执行了,特别是当表原本不是utf8时,除非表是空的或者你确认表里只有拉丁字符,否则正常和乱的就混在一起了。
最重要的是,你连接时使用的latin1字符集写入了历史数据,表定义是latin1或utf8,不要期望通过 ALTER ... CONVERT ... 能够让你达到用utf8读取历史中文数据的目的,没用的,老老实实做逻辑dump。
2、character-set-server
一旦你决定使用utf8mb4,强烈建议你要修改服务端 character-set-server=utf8mb4,不同的语言对它的处理方法不一样,c++, php, python可以设置character-set,但java驱动依赖于 character-set-server 选项,后面有介绍。同时还要谨慎一些特殊选项。个人不建议设置全局 init_connect。
key 768 long 错误
字符集从utf8转到utf8mb4之后,最容易引起的就是索引键超长的问题。
对于表行格式是 COMPACT或 REDUNDANT,InnoDB有单个索引最大字节数 768 的限制,而字段定义的是能存储的字符数,比如 VARCHAR(200) 代表能够存200个汉字,索引定义是字符集类型最大长度算的,即 utf8 maxbytes=3, utf8mb4 maxbytes=4,算下来utf8和utf8mb4两种情况的索引长度分别为600 bytes和800bytes,后者超过了768,导致出错:Error 1071: Specified key was too long; max key length is 767 bytes。
COMPRESSED和DYNAMIC格式不受限制,但也依然不建议索引太长,太浪费空间和cpu搜索资源。
如果已有定义超过这个长度的,可加上前缀索引,如果暂不能加上前缀索引(像唯一索引),可把该字段的字符集改回utf8或latin1。但是要防止出现 Illegal mix of collations (utf8_general_ci,IMPLICIT) and (utf8mb4_general_ci,COERCIBLE) for operation '=' 错误:连接字符集使用utf8mb4,但 SELECT/UPDATE where条件有utf8类型的列,且条件右边存在不属于utf8字符,就会触发该异常。
再多加一个友好提示:EXPLAIN 结果里面的 key_len 指的搜索索引长度,单位是bytes,而且是以字符集支持的单字符最大字节数算的,这也是为什么 INDEX_LENGTH 膨胀厉害的一个原因。
utf8是UTF-8一个简写形式。
为什么需要utf8
在计算机早期,主要使用ASCII编码,只能表示128个字符,汉字完全表示不了。后来,才出现了各种各样的编码方式,比如GB2312、GBK、BIG5,但这些编码只能在特定的环境下使用,不能全球通用。
UTF-8就像一个万能翻译官,它的全称是“Unicode Transformation Format - 8 bit”,注意这里不是说UTF-8只能使用8bit来表示一个字符,实际上UTF-8能表示世界上几乎所有的字符。
它的特点是:
1.变长编码:一个字符可以用1到4个字节表示,英文字符用1个字节(8bit),汉字用3个字节(24bit)。
2.向后兼容ASCII:ASCII的字符在UTF-8中还是一个字节,这样就兼容了老系统。
3.节省空间:对于英文字符,UTF-8比其他多字节编码更省空间。
UTF-8适用于网页、文件系统、数据库等需要全球化支持的场景。
经常接触代码的同学应该还经常能看到 Unicode 这个词,它和编码也有很大的关系,其实Unicode是一个字符集标准,utf8只是它的一种实现方式。Unicode 作为一种字符集标准,为全球各种语言和符号定义了唯一的数字码位(code points)。其它的Unicode实现方式还有UTF-16和UTF-32:
1.UTF-16 使用固定的16位(2字节)或者变长的32位(4字节,不在常用字符之列)来编码 Unicode 字符。
2.UTF-32 每一个字符都直接使用固定长度的32位(4字节)编码,不论字符的实际数值大小。这会消耗更多的存储空间,但是所有字符都可以直接索引访问。
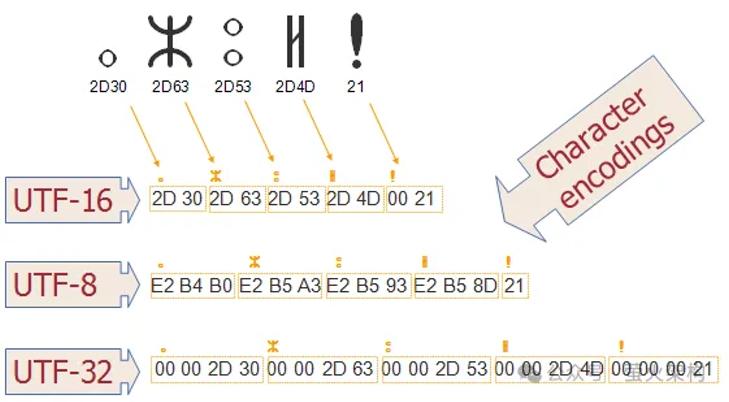
utf8mb4又是什么
utf8mb4并不常见,它是UTF-8的一个扩展版本,专门用于MySQL数据库。MySQL在 5.5.3 之后增加了一个utf8mb4的编码,mb4就是最多4个字节的意思(most bytes 4),它主要解决了UTF-8不能表示一些特殊字符的问题,比如Emoji表情,这在论坛或者留言板中也经常用到。大家使用一些聊天软件时应该见过各种各样的表情符号,其后台也可能使用utf8mb4保存它们。
编码规则和特点:
1.最多4个字节:utf8mb4中的每个字符最多用4个字节表示。
2.支持更多字符:能表示更多的Unicode字符,包括Emoji和其他特殊符号。
utf8和utf8mb4的比较
存储空间
1.数据库:utf8mb4每个字符最多用4个字节,比UTF-8多一个字节,存储空间会增加。
2.文件:类似的,文件用utf8mb4编码也会占用更多的空间。
性能影响
1.数据库:utf8mb4的查询和索引可能稍微慢一些,因为占用更多的空间和内存。
2.网络传输:utf8mb4编码的字符会占用更多的带宽,传输速度可能会稍慢。
不过因为实际场景中使用的utf8mb4的字符也不多,其实对存储空间和性能的影响很小,大家基本没有必要因为多占用了一些空间和流量,而不是用utf8mb4。只是在定义字段长度、规划数据存储空间、网络带宽的时候,要充分考虑4字节带来的影响,预留好足够的空间。
如何选择
在实际开发中,选择编码要根据具体需求来定。如果网站或者应用需要支持大量的特殊字符和Emoji,使用utf8mb4是个不错的选择。如果主要是英文和普通中文文本,utf8足够应付。
注意为了避免乱码问题,前端、后端、数据库都应该使用同一种编码,比如utf8,具体到编码时就是要确保数据库连接、网页头部、文件读写都设置为相同的编码。另外还需要注意Windows和Linux系统中使用UTF-8编码的文件可能是有差别的,Windows中的UTF-8文件可能会携带一个BOM头,方便系统进行识别,但是Linux中不需要这个头,所以如果要跨系统使用这个文件,特别是程序脚本,可能需要在Linux中去掉这个头。
参考来源
How to support full Unicode in MySQL databases
Unicode 8.0 发布
10.1.9.3 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)
10.1.9.8 Converting Between 3-Byte and 4-Byte Unicode Character Sets