理解Redis持久化与事务
 Redis高可用概述
Redis高可用概述在介绍Redis高可用之前,先说明一下在Redis的语境中高可用的含义。在Web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务(99.9%、99.99%、99.999% 等等)。但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服务(如主从分离、快速容灾技术),还需要考虑数据容量的扩展、数据安全不会丢失等。
在Redis中,实现高可用的技术主要包括持久化、复制、哨兵和集群,下面分别说明它们的作用,以及解决了什么样的问题。
持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
复制:复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。哨兵:在复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制。
集群:通过集群Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
Redis持久化概述
持久化的功能:Redis是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。Redis持久化分为RDB持久化和AOF持久化:前者将当前数据保存到硬盘,后者则是将每次执行的写命令保存到硬盘(类似于MySQL的binlog);由于AOF持久化的实时性更好,即当进程意外退出时丢失的数据更少,因此AOF是目前主流的持久化方式,不过RDB持久化仍然有其用武之地。下面依次介绍RDB持久化和AOF持久化;由于Redis各个版本之间存在差异,如无特殊说明,以Redis3.0为准。
RDB持久化
RDB持久化是将当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),保存的文件后缀是rdb;当Redis重新启动时,可以读取快照文件恢复数据。
1. 触发条件
RDB持久化的触发分为手动触发和自动触发两种。
1) 手动触发
save命令和bgsave命令都可以生成RDB文件。
save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求。
而bgsave命令会创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求。
bgsave命令执行过程中,只有fork子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此save已基本被废弃,线上环境要杜绝save的使用;后文中也将只介绍bgsave命令。此外,在自动触发RDB持久化时,Redis也会选择bgsave而不是save来进行持久化;下面介绍自动触发RDB持久化的条件。
2) 自动触发
save m n
自动触发最常见的情况是在配置文件中通过save m n,指定当m秒内发生n次变化时,会触发bgsave。例如,查看redis的默认配置文件(Linux下为redis根目录下的redis.conf),可以看到如下配置信息:
其中save 900 1的含义是:当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave;save 300 10和save 60 10000同理。当三个save条件满足任意一个时,都会引起bgsave的调用。
save m n 实现原理
Redis的save m n,是通过serverCron函数、dirty计数器、和lastsave时间戳来实现的。
serverCron是Redis服务器的周期性操作函数,默认每隔100ms执行一次;该函数对服务器的状态进行维护,其中一项工作就是检查 save m n 配置的条件是否满足,如果满足就执行bgsave。
dirty计数器是Redis服务器维持的一个状态,记录了上一次执行bgsave/save命令后,服务器状态进行了多少次修改(包括增删改);而当save/bgsave执行完成后,会将dirty重新置为0。
例如,如果Redis执行了set mykey helloworld,则dirty值会+1;如果执行了sadd myset v1 v2 v3,则dirty值会+3;注意dirty记录的是服务器进行了多少次修改,而不是客户端执行了多少修改数据的命令。
lastsave时间戳也是Redis服务器维持的一个状态,记录的是上一次成功执行save/bgsave的时间。
save m n的原理如下:每隔100ms,执行serverCron函数;在serverCron函数中,遍历save m n配置的保存条件,只要有一个条件满足,就进行bgsave。对于每一个save m n条件,只有下面两条同时满足时才算满足:
(1)当前时间-lastsave > m
(2)dirty >= n
save m n 执行日志
其他自动触发机制
除了save m n 以外,还有一些其他情况会触发bgsave:
1).在主从复制场景下,如果从节点执行全量复制操作,则主节点会执行bgsave命令,并将rdb文件发送给从节点
2).执行shutdown命令时,自动执行rdb持久化。
2. 执行流程
前面介绍了触发bgsave的条件,下面将说明bgsave命令的执行流程,如下图所示(图片来源):
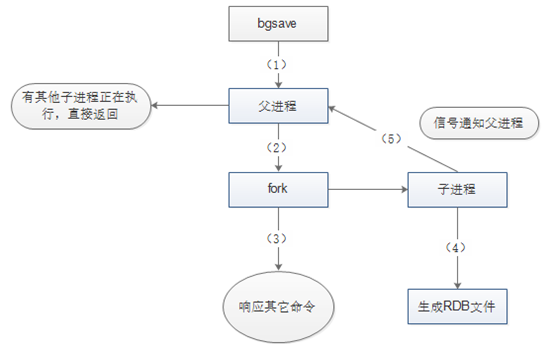
图片中的5个步骤所进行的操作如下:
1) Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof(后面会详细介绍该命令)的子进程,如果在执行则bgsave命令直接返回。bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
2) 父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
3) 父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令
4) 子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换
5) 子进程发送信号给父进程表示完成,父进程更新统计信息
3. RDB文件
RDB文件是经过压缩的二进制文件,下面介绍关于RDB文件的一些细节。
存储路径
RDB文件的存储路径既可以在启动前配置,也可以通过命令动态设定。
配置:dir配置指定目录,dbfilename指定文件名。默认是Redis根目录下的dump.rdb文件。
动态设定:Redis启动后也可以动态修改RDB存储路径,在磁盘损害或空间不足时非常有用;执行命令为config set dir {newdir}和config set dbfilename {newFileName}。如下所示(Windows环境):
RDB文件格式
RDB文件格式如下图所示(图片来源:《Redis设计与实现》):

其中各个字段的含义说明如下:
1).REDIS:常量,保存着”REDIS”5个字符。
2).db_version:RDB文件的版本号,注意不是Redis的版本号。
3).SELECTDB 0 pairs:表示一个完整的数据库(0号数据库),同理SELECTDB 3 pairs表示完整的3号数据库;只有当数据库中有键值对时,RDB文件中才会有该数据库的信息(上图所示的Redis中只有0号和3号数据库有键值对);如果Redis中所有的数据库都没有键值对,则这一部分直接省略。其中:SELECTDB是一个常量,代表后面跟着的是数据库号码;0和3是数据库号码;pairs则存储了具体的键值对信息,包括key、value值,及其数据类型、内部编码、过期时间、压缩信息等等。
4).EOF:常量,标志RDB文件正文内容结束。
5).check_sum:前面所有内容的校验和;Redis在载入RBD文件时,会计算前面的校验和并与check_sum值比较,判断文件是否损坏。
压缩
Redis默认采用LZF算法对RDB文件进行压缩。虽然压缩耗时,但是可以大大减小RDB文件的体积,因此压缩默认开启,可以通过命令关闭:
config set rdbcompression no
需要注意的是,RDB文件的压缩并不是针对整个文件进行的,而是对数据库中的字符串进行的,且只有在字符串达到一定长度(20字节)时才会进行。
4. 启动时加载
RDB文件的载入工作是在服务器启动时自动执行的,并没有专门的命令。但是由于AOF的优先级更高,因此当AOF开启时,Redis会优先载入AOF文件来恢复数据;只有当AOF关闭时,才会在Redis服务器启动时检测RDB文件,并自动载入。服务器载入RDB文件期间处于阻塞状态,直到载入完成为止。
Redis启动日志中可以看到自动载入的执行。载入RDB文件时,会对RDB文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败。
5. RDB常用配置总结
下面是RDB常用的配置项,以及默认值;前面介绍过的这里不再详细介绍。
save m n:bgsave自动触发的条件;如果没有save m n配置,相当于自动的RDB持久化关闭,不过此时仍可以通过其他方式触发
stop-writes-on-bgsave-error yes:当bgsave出现错误时,Redis是否停止执行写命令;设置为yes,则当硬盘出现问题时,可以及时发现,避免数据的大量丢失;设置为no,则Redis无视bgsave的错误继续执行写命令,当对Redis服务器的系统(尤其是硬盘)使用了监控时,该选项考虑设置为no
rdbcompression yes:是否开启RDB文件压缩
rdbchecksum yes:是否开启RDB文件的校验,在写入文件和读取文件时都起作用;关闭checksum在写入文件和启动文件时大约能带来10%的性能提升,但是数据损坏时无法发现
dbfilename dump.rdb:RDB文件名
dir ./:RDB文件和AOF文件所在目录
AOF持久化
RDB持久化是将进程数据写入文件,而AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中(有点像MySQL的binlog);当Redis重启时再次执行AOF文件中的命令来恢复数据。与RDB相比,AOF的实时性更好,因此已成为主流的持久化方案。
1. 开启AOF
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置:
appendonly yes
2. 执行流程
由于需要记录Redis的每条写命令,因此AOF不需要触发,下面介绍AOF的执行流程。
AOF的执行流程包括:
命令追加(append):将Redis的写命令追加到缓冲区aof_buf;
文件写入(write)和文件同步(sync):根据不同的同步策略将aof_buf中的内容同步到硬盘;
文件重写(rewrite):定期重写AOF文件,达到压缩的目的。
1) 命令追加(append)
Redis先将写命令追加到缓冲区,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘IO成为Redis负载的瓶颈。命令追加的格式是Redis命令请求的协议格式,它是一种纯文本格式,具有兼容性好、可读性强、容易处理、操作简单避免二次开销等优点;具体格式略。在AOF文件中,除了用于指定数据库的select命令(如select 0 为选中0号数据库)是由Redis添加的,其他都是客户端发送来的写命令。
2) 文件写入(write)和文件同步(sync)
Redis提供了多种AOF缓存区的同步文件策略,策略涉及到操作系统的write函数和fsync函数,说明如下:
为了提高文件写入效率,在现代操作系统中,当用户调用write函数将数据写入文件时,操作系统通常会将数据暂存到一个内存缓冲区里,当缓冲区被填满或超过了指定时限后,才真正将缓冲区的数据写入到硬盘里。这样的操作虽然提高了效率,但也带来了安全问题:如果计算机停机,内存缓冲区中的数据会丢失;因此系统同时提供了fsync、fdatasync等同步函数,可以强制操作系统立刻将缓冲区中的数据写入到硬盘里,从而确保数据的安全性。
AOF缓存区的同步文件策略由参数appendfsync控制,各个值的含义如下:
1).always:命令写入aof_buf后立即调用系统fsync操作同步到AOF文件,fsync完成后线程返回。这种情况下,每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈,Redis只能支持大约几百TPS写入,严重降低了Redis的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低SSD的寿命。
2).no:命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。
3).everysec:命令写入aof_buf后调用系统write操作,write完成后线程返回;fsync同步文件操作由专门的线程每秒调用一次。everysec是前述两种策略的折中,是性能和数据安全性的平衡,因此是Redis的默认配置,也是我们推荐的配置。
3) 文件重写(rewrite)
随着时间流逝,Redis服务器执行的写命令越来越多,AOF文件也会越来越大;过大的AOF文件不仅会影响服务器的正常运行,也会导致数据恢复需要的时间过长。文件重写是指定期重写AOF文件,减小AOF文件的体积。需要注意的是,AOF重写是把Redis进程内的数据转化为写命令,同步到新的AOF文件;不会对旧的AOF文件进行任何读取、写入操作。重写需要注意的另一点是:对于AOF持久化来说,文件重写虽然是强烈推荐的,但并不是必须的;即使没有文件重写,数据也可以被持久化并在Redis启动的时候导入;因此在一些实现中,会关闭自动的文件重写,然后通过定时任务在每天的某一时刻定时执行。
文件重写之所以能够压缩AOF文件,原因在于:
1).过期的数据不再写入文件
2).无效的命令不再写入文件:如有些数据被重复设值(set mykey v1, set mykey v2)、有些数据被删除了(sadd myset v1, del myset)等等
3).多条命令可以合并为一个:如sadd myset v1, sadd myset v2, sadd myset v3可以合并为sadd myset v1 v2 v3。不过为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset类型的key,并不一定只使用一条命令;而是以某个常量为界将命令拆分为多条。这个常量在redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD中定义,不可更改,3.0版本中值是64。
通过上述内容可以看出,由于重写后AOF执行的命令减少了,文件重写既可以减少文件占用的空间,也可以加快恢复速度。
文件重写的触发
文件重写的触发,分为手动触发和自动触发:
1).手动触发:直接调用bgrewriteaof命令,该命令的执行与bgsave有些类似:都是fork子进程进行具体的工作,且都只有在fork时阻塞。
2).自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数,以及aof_current_size和aof_base_size状态确定触发时机。
auto-aof-rewrite-min-size:执行AOF重写时,文件的最小体积,默认值为64MB。
auto-aof-rewrite-percentage:执行AOF重写时,当前AOF大小(即aof_current_size)和上一次重写时AOF大小(aof_base_size)的比值。
其中,参数可以通过config get命令查看:
config set auto-aof-rewrite-min-size
config set auto-aof-rewrite-percentage
状态可以通过info persistence查看:
aof_current_size:149
aof_base_size:149
只有当auto-aof-rewrite-min-size和auto-aof-rewrite-percentage两个参数同时满足时,才会自动触发AOF重写,即bgrewriteaof操作。
文件重写的流程
文件重写流程如下图所示(图片来源):
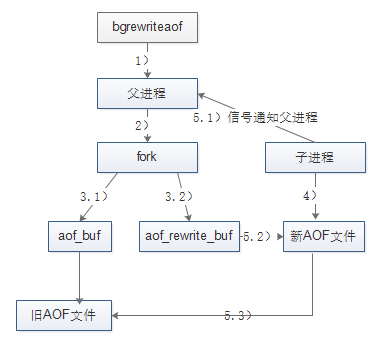
关于文件重写的流程,有两点需要特别注意:(1)重写由父进程fork子进程进行;(2)重写期间Redis执行的写命令,需要追加到新的AOF文件中,为此Redis引入了aof_rewrite_buf缓存。对照上图,文件重写的流程如下:
1).Redis父进程首先判断当前是否存在正在执行 bgsave/bgrewriteaof的子进程,如果存在则bgrewriteaof命令直接返回,如果存在bgsave命令则等bgsave执行完成后再执行。前面曾介绍过,这个主要是基于性能方面的考虑。
2).父进程执行fork操作创建子进程,这个过程中父进程是阻塞的。
3.1).父进程fork后,bgrewriteaof命令返回”Background append only file rewrite started”信息并不再阻塞父进程,并可以响应其他命令。Redis的所有写命令依然写入AOF缓冲区,并根据appendfsync策略同步到硬盘,保证原有AOF机制的正确。
3.2).由于fork操作使用写时复制技术,子进程只能共享fork操作时的内存数据。由于父进程依然在响应命令,因此Redis使用AOF重写缓冲区(图中的aof_rewrite_buf)保存这部分数据,防止新AOF文件生成期间丢失这部分数据。也就是说,bgrewriteaof执行期间,Redis的写命令同时追加到aof_buf和aof_rewirte_buf两个缓冲区。
4).子进程根据内存快照,按照命令合并规则写入到新的AOF文件。
5.1).子进程写完新的AOF文件后,向父进程发信号,父进程更新统计信息,具体可以通过info persistence查看。
5.2).父进程把AOF重写缓冲区的数据写入到新的AOF文件,这样就保证了新AOF文件所保存的数据库状态和服务器当前状态一致。
5.3).使用新的AOF文件替换老文件,完成AOF重写。
3. 启动时加载
前面提到过,当AOF开启时,Redis启动时会优先载入AOF文件来恢复数据;只有当AOF关闭时,才会载入RDB文件恢复数据。当AOF开启,但AOF文件不存在时,即使RDB文件存在也不会加载(更早的一些版本可能会加载,但3.0不会)。
文件校验
与载入RDB文件类似,Redis载入AOF文件时,会对AOF文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败。但如果是AOF文件结尾不完整(机器突然宕机等容易导致文件尾部不完整),且aof-load-truncated参数开启,则日志中会输出警告,Redis忽略掉AOF文件的尾部,启动成功。aof-load-truncated参数默认是开启的。
伪客户端
因为Redis的命令只能在客户端上下文中执行,而载入AOF文件时命令是直接从文件中读取的,并不是由客户端发送;因此Redis服务器在载入AOF文件之前,会创建一个没有网络连接的客户端,之后用它来执行AOF文件中的命令,命令执行的效果与带网络连接的客户端完全一样。
4. AOF常用配置小结
下面是AOF常用的配置项,以及默认值;前面介绍过的这里不再详细介绍:
appendonly no:是否开启AOF
appendfilename "appendonly.aof":AOF文件名
dir ./:RDB文件和AOF文件所在目录
appendfsync everysec:fsync持久化策略
no-appendfsync-on-rewrite no:AOF重写期间是否禁止fsync;如果开启该选项,可以减轻文件重写时CPU和硬盘的负载(尤其是硬盘),但是可能会丢失AOF重写期间的数据;需要在负载和安全性之间进行平衡
auto-aof-rewrite-percentage 100:文件重写触发条件之一
auto-aof-rewrite-min-size 64mb:文件重写触发提交之一
aof-load-truncated yes:如果AOF文件结尾损坏,Redis启动时是否仍载入AOF文件
方案选择与常见问题
前面介绍了RDB和AOF两种持久化方案的细节,下面介绍RDB和AOF的特点、如何选择持久化方案,以及在持久化过程中常遇到的问题等。
1. RDB和AOF的优缺点
RDB持久化
优点:RDB文件紧凑,体积小,网络传输快,适合全量复制;恢复速度比AOF快很多。当然,与AOF相比,RDB最重要的优点之一是对性能的影响相对较小。
缺点:RDB文件的致命缺点在于其数据快照的持久化方式决定了必然做不到实时持久化,而在数据越来越重要的今天,数据的大量丢失很多时候是无法接受的,因此AOF持久化成为主流。此外,RDB文件需要满足特定格式,兼容性差(如老版本的Redis不兼容新版本的RDB文件)。
AOF持久化
与RDB持久化相对应,AOF的优点在于支持秒级持久化、兼容性好,缺点是文件大、恢复速度慢、对性能影响大。
2. 持久化策略选择
在介绍持久化策略之前,首先要明白无论是RDB还是AOF,持久化的开启都是要付出性能方面代价的:对于RDB持久化,一方面是bgsave在进行fork操作时Redis主进程会阻塞,另一方面,子进程向硬盘写数据也会带来IO压力;对于AOF持久化,向硬盘写数据的频率大大提高(everysec策略下为秒级),IO压力更大,甚至可能造成AOF追加阻塞问题。此外,AOF文件的重写与RDB的bgsave类似,会有fork时的阻塞和子进程的IO压力问题。相对来说,由于AOF向硬盘中写数据的频率更高,因此对Redis主进程性能的影响会更大。
在实际生产环境中,根据数据量、应用对数据的安全要求、预算限制等不同情况,会有各种各样的持久化策略;如完全不使用任何持久化、使用RDB或AOF的一种,或同时开启RDB和AOF持久化等。此外,持久化的选择必须与Redis的主从策略一起考虑,因为主从复制与持久化同样具有数据备份的功能,而且主机master和从机slave可以独立的选择持久化方案。下面分场景来讨论持久化策略的选择,下面的讨论也只是作为参考,实际方案可能更复杂更具多样性。
(1)如果Redis中的数据完全丢弃也没有关系(如Redis完全用作DB层数据的cache),那么无论是单机,还是主从架构,都可以不进行任何持久化。
(2)在单机环境下(对于个人开发者,这种情况可能比较常见),如果可以接受十几分钟或更多的数据丢失,选择RDB对Redis的性能更加有利;如果只能接受秒级别的数据丢失,应该选择AOF。
(3)但在多数情况下都会配置主从环境,slave的存在既可以实现数据的热备,也可以进行读写分离分担Redis读请求,以及在master宕掉后继续提供服务。
在这种情况下,一种可行的做法是:
1).master:完全关闭持久化(包括RDB和AOF),这样可以让master的性能达到最好;
2).slave:关闭RDB,开启AOF(如果对数据安全要求不高,开启RDB关闭AOF也可以),并定时对持久化文件进行备份(如备份到其他文件夹,并标记好备份的时间);然后关闭AOF的自动重写,然后添加定时任务,在每天Redis闲时(如凌晨12点)调用bgrewriteaof。
这里需要解释一下,为什么开启了主从复制,可以实现数据的热备份,还需要设置持久化呢?因为在一些特殊情况下,主从复制仍然不足以保证数据的安全,例如:
1).master和slave进程同时停止:考虑这样一种场景,如果master和slave在同一栋大楼或同一个机房,则一次停电事故就可能导致master和slave机器同时关机,Redis进程停止;如果没有持久化,则面临的是数据的完全丢失。
2).master误重启:考虑这样一种场景,master服务因为故障宕掉了,如果系统中有自动拉起机制(即检测到服务停止后重启该服务)将master自动重启,由于没有持久化文件,那么master重启后数据是空的,slave同步数据也变成了空的;如果master和slave都没有持久化,同样会面临数据的完全丢失。需要注意的是,即便是使用了哨兵(关于哨兵后面会有文章介绍)进行自动的主从切换,也有可能在哨兵轮询到master之前,便被自动拉起机制重启了。因此,应尽量避免“自动拉起机制”和“不做持久化”同时出现。
(4)异地灾备:上述讨论的几种持久化策略,针对的都是一般的系统故障,如进程异常退出、宕机、断电等,这些故障不会损坏硬盘。但是对于一些可能导致硬盘损坏的灾难情况,如火灾地震,就需要进行异地灾备。例如对于单机的情形,可以定时将RDB文件或重写后的AOF文件,通过scp拷贝到远程机器,如阿里云、AWS等;对于主从的情形,可以定时在master上执行bgsave,然后将RDB文件拷贝到远程机器,或者在slave上执行bgrewriteaof重写AOF文件后,将AOF文件拷贝到远程机器上。一般来说,由于RDB文件文件小、恢复快,因此灾难恢复常用RDB文件;异地备份的频率根据数据安全性的需要及其他条件来确定,但最好不要低于一天一次。
3. fork阻塞:CPU的阻塞
在Redis的实践中,众多因素限制了Redis单机的内存不能过大,例如:
1).当面对请求的暴增,需要从库扩容时,Redis内存过大会导致扩容时间太长;
2).当主机宕机时,切换主机后需要挂载从库,Redis内存过大导致挂载速度过慢;
3).以及持久化过程中的fork操作,下面详细说明。
首先说明一下fork操作:
父进程通过fork操作可以创建子进程;子进程创建后,父子进程共享代码段,不共享进程的数据空间,但是子进程会获得父进程的数据空间的副本。在操作系统fork的实际实现中,基本都采用了写时复制技术,即在父/子进程试图修改数据空间之前,父子进程实际上共享数据空间;但是当父/子进程的任何一个试图修改数据空间时,操作系统会为修改的那一部分(内存的一页)制作一个副本。
虽然fork时,子进程不会复制父进程的数据空间,但是会复制内存页表(页表相当于内存的索引、目录);父进程的数据空间越大,内存页表越大,fork时复制耗时也会越多。在Redis中,无论是RDB持久化的bgsave,还是AOF重写的bgrewriteaof,都需要fork出子进程来进行操作。如果Redis内存过大,会导致fork操作时复制内存页表耗时过多;而Redis主进程在进行fork时,是完全阻塞的,也就意味着无法响应客户端的请求,会造成请求延迟过大。
对于不同的硬件、不同的操作系统,fork操作的耗时会有所差别,一般来说,如果Redis单机内存达到了10GB,fork时耗时可能会达到百毫秒级别(如果使用Xen虚拟机,这个耗时可能达到秒级别)。因此,一般来说Redis单机内存一般要限制在10GB以内;不过这个数据并不是绝对的,可以通过观察线上环境fork的耗时来进行调整。观察的方法如下:执行命令info stats,查看latest_fork_usec的值,单位为微秒。
为了减轻fork操作带来的阻塞问题,除了控制Redis单机内存的大小以外,还可以适度放宽AOF重写的触发条件、选用物理机或高效支持fork操作的虚拟化技术等,例如使用Vmware或KVM虚拟机,不要使用Xen虚拟机。
4. AOF追加阻塞:硬盘的阻塞
前面提到过,在AOF中,如果AOF缓冲区的文件同步策略为everysec,则:在主线程中,命令写入aof_buf后调用系统write操作,write完成后主线程返回;fsync同步文件操作由专门的文件同步线程每秒调用一次。这种做法的问题在于,如果硬盘负载过高,那么fsync操作可能会超过1s;如果Redis主线程持续高速向aof_buf写入命令,硬盘的负载可能会越来越大,IO资源消耗更快;如果此时Redis进程异常退出,丢失的数据也会越来越多,可能远超过1s。为此,Redis的处理策略是这样的:主线程每次进行AOF会对比上次fsync成功的时间;如果距上次不到2s,主线程直接返回;如果超过2s,则主线程阻塞直到fsync同步完成。因此,如果系统硬盘负载过大导致fsync速度太慢,会导致Redis主线程的阻塞;此外,使用everysec配置,AOF最多可能丢失2s的数据,而不是1s。
AOF追加阻塞问题定位的方法:
(1)监控info Persistence中的aof_delayed_fsync:当AOF追加阻塞发生时(即主线程等待fsync而阻塞),该指标累加。
(2)AOF阻塞时的Redis日志:
Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.
(3)如果AOF追加阻塞频繁发生,说明系统的硬盘负载太大;可以考虑更换IO速度更快的硬盘,或者通过IO监控分析工具对系统的IO负载进行分析,如iostat(系统级io)、iotop(io版的top)、pidstat等。
5. info命令与持久化
前面提到了一些通过info命令查看持久化相关状态的方法,下面来总结一下。
(1)info Persistence
其中比较重要的包括:
rdb_last_bgsave_status:上次bgsave 执行结果,可以用于发现bgsave错误
rdb_last_bgsave_time_sec:上次bgsave执行时间(单位是s),可以用于发现bgsave是否耗时过长
aof_enabled:AOF是否开启
aof_last_rewrite_time_sec: 上次文件重写执行时间(单位是s),可以用于发现文件重写是否耗时过长
aof_last_bgrewrite_status: 上次bgrewrite执行结果,可以用于发现bgrewrite错误
aof_buffer_length和aof_rewrite_buffer_length:aof缓存区大小和aof重写缓冲区大小
aof_delayed_fsync:AOF追加阻塞情况的统计
(2)info stats
其中与持久化关系较大的是:latest_fork_usec,代表上次fork耗时,可以参见前面的讨论。
总结
上文主要内容可以总结如下:
1、持久化在Redis高可用中的作用:数据备份,与主从复制相比强调的是由内存到硬盘的备份。
2、RDB持久化:将数据快照备份到硬盘;介绍了其触发条件(包括手动出发和自动触发)、执行流程、RDB文件等,特别需要注意的是文件保存操作由fork出的子进程来进行。
3、AOF持久化:将执行的写命令备份到硬盘(类似于MySQL的binlog),介绍了其开启方法、执行流程等,特别需要注意的是文件同步策略的选择(everysec)、文件重写的流程。
4、一些现实的问题:包括如何选择持久化策略,以及需要注意的fork阻塞、AOF追加阻塞等。
参考来源:
深入Redis持久化
redis持久化方案rdb和aof
Redis事务概述
Redis 事务包含两种模式 : 事务模式 和 Lua 脚本。其事务模式具备如下特点:
1).保证隔离性;
2).无法保证持久性;
3).具备了一定的原子性,但不支持回滚;
一致性的概念有分歧,假设在一致性的核心是约束的语意下,Redis 的事务可以保证一致性。
但 Lua 脚本更具备实用场景,它是另一种形式的事务,其具备一定的原子性,但当脚本报错的情况下,事务并不会回滚。Lua 脚本可以保证隔离性,而且可以完美的支持后面的步骤依赖前面步骤的结果。Lua 脚本模式的身影几乎无处不在,比如分布式锁、延迟队列、抢红包等场景。
1、事务原理
Redis 的事务包含如下命令:
序号 命令及描述
1 MULTI 标记一个事务块的开始。
2 EXEC 执行所有事务块内的命令。
3 DISCARD 取消事务,放弃执行事务块内的所有命令。
4 WATCH key [key ...] 监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。
5 UNWATCH 取消 WATCH 命令对所有 key 的监视。
事务包含三个阶段:
事务开启,使用 MULTI , 该命令标志着执行该命令的客户端从非事务状态切换至事务状态 ;
命令入队,MULTI 开启事务之后,客户端的命令并不会被立即执行,而是放入一个事务队列 ;
执行事务或者丢弃。如果收到 EXEC 的命令,事务队列里的命令将会被执行 ,如果是 DISCARD 则事务被丢弃。
下面展示一个事务的例子。
redis> MULTI
OK
redis> SET msg "hello world"
QUEUED
redis> GET msg
QUEUED
redis> EXEC
1) OK
1) hello world
这里有一个疑问?在开启事务的时候,Redis key 可以被修改吗?
在事务执行 EXEC 命令之前,Redis key 依然可以被修改。在事务开启之前,我们可以 watch 命令监听 Redis key 。在事务执行之前,我们修改 key 值 ,事务执行失败,返回 nil 。
通过上面的例子,watch 命令可以实现类似乐观锁的效果 。
2、事务的 ACID
2.1.原子性
原子性是指:一个事务中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
第一个例子:
在执行 EXEC 命令前,客户端发送的操作命令错误,比如语法错误或者使用了不存在的命令。
redis> MULTI
OK
redis> SET msg "other msg"
QUEUED
redis> wrongcommand ### 故意写错误的命令
(error) ERR unknown command 'wrongcommand'
redis> EXEC
(error) EXECABORT Transaction discarded because of previous errors.
redis> GET msg
"hello world"
在这个例子中使用了不存在的命令,导致入队失败,整个事务都将无法执行 。
第二个例子:
事务操作入队时,命令和操作的数据类型不匹配 ,入队列正常,但执行 EXEC 命令异常 。
redis> MULTI
OK
redis> SET msg "other msg"
QUEUED
redis> SET mystring "I am a string"
QUEUED
redis> HMSET mystring name "test"
QUEUED
redis> SET msg "after"
QUEUED
redis> EXEC
1) OK
2) OK
3) (error) WRONGTYPE Operation against a key holding the wrong kind of value
4) OK
redis> GET msg
"after"
这个例子里执行 EXEC 命令时,如果出现了错误,Redis 不会终止其它命令的执行,事务也不会因为某个命令执行失败而回滚。
综上对 Redis 事务原子性的理解如下:
命令入队时报错, 会放弃事务执行,保证原子性;
命令入队时正常,执行 EXEC 命令后报错,不保证原子性;
也就是:Redis 事务在特定条件下,才具备一定的原子性 。
2.2.隔离性
数据库的隔离性是指:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别 ,分别是:
未提交读(read uncommitted)
提交读(read committed)
可重复读(repeatable read)
串行化(serializable)
首先要明确一点:Redis 并没有事务隔离级别的概念。这里讨论 Redis 的隔离性是指:并发场景下,事务之间是否可以做到互不干扰。可以将事务执行可以分为 EXEC 命令执行前和 EXEC 命令执行后两个阶段,分开讨论。
EXEC 命令执行前
在事务原理这一小节发现在事务执行之前,Redis key 依然可以被修改。此时可以使用 WATCH 机制来实现乐观锁的效果。
EXEC 命令执行后
因为 Redis 是单线程执行操作命令, EXEC 命令执行后,Redis 会保证命令队列中的所有命令执行完。这样就可以保证事务的隔离性。
2.3.持久性
数据库的持久性是指:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失,本小节在上文有详述。数据是否持久化取决于 Redis 的持久化配置模式:
没有配置 RDB 或者 AOF ,事务的持久性无法保证;
使用了 RDB 模式,在一个事务执行后,下一次的 RDB 快照还未执行前,如果发生了实例宕机,事务的持久性同样无法保证;
使用了 AOF 模式;AOF 模式的三种配置选项 no 、everysec 都会存在数据丢失的情况 。always 可以保证事务的持久性,但因为性能太差,在生产环境一般不推荐使用。
综上,redis 事务的持久性是无法保证的。
2.4.一致性
一致性的概念一直很让人困惑,在我搜寻的资料里,有两类不同的定义。先看下维基百科上一致性的定义:
Consistency ensures that a transaction can only bring the database from one valid state to another, maintaining database invariants: any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is correct. Referential integrity guarantees the primary key – foreign key relationship.
在这段文字里,一致性的核心是 “约束”,“any data written to the database must be valid according to all defined rules ”。
如何理解约束?这里引用知乎问题 如何理解数据库的内部一致性和外部一致性,OceanBase 研发专家韩富晟回答的一段话:“约束”由数据库的使用者告诉数据库,使用者要求数据一定符合这样或者那样的约束。当数据发生修改时,数据库会检查数据是否还符合约束条件,如果约束条件不再被满足,那么修改操作不会发生。
关系数据库最常见的两类约束是“唯一性约束”和“完整性约束”,表格中定义的主键和唯一键都保证了指定的数据项绝不会出现重复,表格之间定义的参照完整性也保证了同一个属性在不同表格中的一致性。
“Consistency in ACID”是如此的好用,以至于已经融化在大部分使用者的血液里了,使用者会在表格设计的时候自觉的加上需要的约束条件,数据库也会严格的执行这个约束条件。所以事务的一致性和预先定义的约束有关,保证了约束即保证了一致性。细品这句话: This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is correct。
写到这里可能大家还是有点模糊,举经典转账的案例:
开启一个事务,张三和李四账号上的初始余额都是 1000 元,并且余额字段没有任何约束。张三给李四转账 1200 元,张三的余额更新为 -200,李四的余额更新为 2200。从应用层面来看,这个事务明显不合法,因为现实场景中,用户余额不可能小于 0,但是它完全遵循数据库的约束,所以从数据库层面来看,这个事务依然保证了一致性。
Redis 的事务一致性是指:Redis 事务在执行过程中符合数据库的约束,没有包含非法或者无效的错误数据。
分三种异常场景分别讨论:
1).执行 EXEC 命令前,客户端发送的操作命令错误,事务终止,数据保持一致性;
2).执行 EXEC 命令后,命令和操作的数据类型不匹配,错误的命令会报错,但事务不会因为错误的命令而终止,而是会继续执行。正确的命令正常执行,错误的命令报错,从这个角度来看,数据也可以保持一致性;
3).执行事务的过程中,Redis 服务宕机,这里需要考虑服务配置的持久化模式。
(1).无持久化的内存模式:服务重启之后,数据库没有保持数据,因此数据都是保持一致性的;
(2).RDB/AOF模式:服务重启后,Redis 通过 RDB/AOF 文件恢复数据,数据库会还原到一致的状态。
综上所述,在一致性的核心是约束的语意下,Redis 的事务可以保证一致性。
《设计数据密集型应用》一书是分布式系统入门的神书,在事务这一章节有一段关于 ACID 的解释:
Atomicity, isolation, and durability are properties of the database, whereas consistency (in the ACID sense) is a property of the application. The application may rely on the database's atomicity and isolation properties in order to achieve consistency, but it's not up to the database alone. Thus, the letter C doesn't really belong in ACID.
原子性,隔离性和持久性是数据库的属性,而一致性(在 ACID 意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此字母 C 不属于 ACID。
很多时候在纠结的一致性,其实就是指符合现实世界的一致性,现实世界的一致性才是事务追求的最终目标。为了实现现实世界的一致性,需要满足如下几点:
1).保证原子性,持久性和隔离性,如果这些特征都无法保证,那么事务的一致性也无法保证;
2).数据库本身的约束,比如字符串长度不能超过列的限制或者唯一性约束;
3).业务层面同样需要进行保障。
2.5.事务特点
通常称 Redis 为内存数据库,不同于传统的关系数据库,为了提供了更高的性能,更快的写入速度,在设计和实现层面做了一些平衡,并不能完全支持事务的 ACID。其事务具备如下特点:
保证隔离性;
无法保证持久性;
具备了一定的原子性,但不支持回滚;
一致性的概念有分歧,假设在一致性的核心是约束的语意下,Redis 的事务可以保证一致性。
从工程角度来看,假设事务操作中每个步骤需要依赖上一个步骤返回的结果,则需要通过 watch 来实现乐观锁。
3、Lua 脚本
3.1.简介
Lua 由标准 C 编写而成,代码简洁优美,几乎在所有操作系统和平台上都可以编译和运行。Lua 脚本可以很容易的被 C/C ++ 代码调用,也可以反过来调用 C/C++ 的函数,这使得 Lua 在应用程序中可以被广泛应用。Lua 脚本在游戏领域大放异彩,后端工程师接触过的 api 网关,比如 Openresty,Kong 都可以看到 Lua 脚本的身影。从 Redis 2.6.0 版本开始,Redis 内置的 Lua 解释器,可以实现在 Redis 中运行 Lua 脚本。使用 Lua 脚本的好处:
减少网络开销。将多个请求通过脚本的形式一次发送,减少网络时延;
原子操作。Redis 会将整个脚本作为一个整体执行,中间不会被其他命令插入;
复用。客户端发送的脚本会永久存在 Redis 中,其他客户端可以复用这一脚本而不需要使用代码完成相同的逻辑。
Redis Lua 脚本常用命令:
序号 命令及描述
1 EVAL script numkeys key [key ...] arg [arg ...] 执行 Lua 脚本。
2 EVALSHA sha1 numkeys key [key ...] arg [arg ...] 执行 Lua 脚本。
3 SCRIPT EXISTS script [script ...] 查看指定的脚本是否已经被保存在缓存当中。
4 SCRIPT FLUSH 从脚本缓存中移除所有脚本。
5 SCRIPT KILL 杀死当前正在运行的 Lua 脚本。
6 SCRIPT LOAD script 将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。
3.2.EVAL 命令
命令格式:
EVAL script numkeys key [key ...] arg [arg ...]
说明:
script 是第一个参数,为 Lua 5.1 脚本;
第二个参数 numkeys 指定后续参数有几个 key;
key [key ...],是要操作的键,可以指定多个,在 Lua 脚本中通过 KEYS[1], KEYS[2] 获取;
arg [arg ...],参数,在 Lua 脚本中通过 ARGV[1], ARGV[2] 获取。
简单实例:
redis> eval "return ARGV[1]" 0 100
"100"
redis> eval "return {ARGV[1],ARGV[2]}" 0 100 101
1) "100"
2) "101"
redis> eval "return {KEYS[1],KEYS[2],ARGV[1]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"
下面演示 Lua 如何调用 Redis 命令,通过 redis.call() 来执行了 Redis 命令。
redis> set mystring 'hello world'
OK
redis> get mystring
"hello world"
redis> EVAL "return redis.call('GET',KEYS[1])" 1 mystring
"hello world"
redis> EVAL "return redis.call('GET','mystring')" 0
"hello world"
3.3.EVALSHA 命令
使用 EVAL 命令每次请求都需要传输 Lua 脚本 ,若 Lua 脚本过长,不仅会消耗网络带宽,而且也会对 Redis 的性能造成一定的影响。解决思路是先将 Lua 脚本先缓存起来,返回给客户端 Lua 脚本的 sha1 摘要。客户端存储脚本的 sha1 摘要 ,每次请求执行 EVALSHA 命令即可。
EVALSHA 命令基本语法如下:
redis> EVALSHA sha1 numkeys key [key ...] arg [arg ...]
实例如下:
redis> SCRIPT LOAD "return 'hello world'"
"5332031c6b470dc5a0dd9b4bf2030dea6d65de91"
redis> EVALSHA 5332031c6b470dc5a0dd9b4bf2030dea6d65de91 0
"hello world"
4、事务 VS Lua 脚本
从定义上来说, Redis 中的脚本本身就是一种事务,所以任何在事务里可以完成的事,在脚本里面也能完成。并且一般来说,使用脚本要来得更简单,并且速度更快。因脚本功能是 Redis 2.6 才引入的, 而事务功能则更早之前就存在了,所以 Redis 才会同时存在两种处理事务的方法。不过我们并不打算在短时间内就移除事务功能, 因为事务提供了一种即使不使用脚本, 也可以避免竞争条件的方法, 而且事务本身的实现并不复杂。
Lua 脚本是另一种形式的事务,其具备一定的原子性,但脚本报错的情况下,事务并不会回滚。Lua 脚本可以保证隔离性,而且可以完美的支持后面的步骤依赖前面步骤的结果。其身影几乎无处不在,比如分布式锁、延迟队列、抢红包等场景。不过在编写 Lua 脚本时,要注意如下两点:
1).为了避免 Redis 阻塞,Lua 脚本业务逻辑不能过于复杂和耗时;
2).仔细检查和测试 Lua 脚本 ,因为执行 Lua 脚本具备一定的原子性,不支持回滚。
基于 Redis 实现分布式锁
Redis 分布式锁原理大致为,当有多个 Set 命令发送到 Redis 时,Redis 会串行处理,最终只有一个 Set 命令执行成功,从而只有一个线程加锁成功。当业务并发量很大时,分布式锁高效的读写性能更能支持高并发。
SetNx 命令加锁
利用 Redis 的 setNx 命令在 Redis 数据库中创建一个 <Key,Value> 记录,这条命令只有当 Redis 中没有这个 Key 的时候才执行成功,当已经有这个 Key 的时候会返回失败。利用 setNx 命令便可以简单的实现加锁功能,当多个线程去执行这个加锁命令时,只有一个线程执行成功,然后执行业务逻辑,其他线程加锁失败返回或者重试。
死锁问题
上面的 setNx 命令实现了基本的加锁功能,但存在一个致命的问题是,当程序在执行业务代码崩溃时,无法再执行到下面的解锁指令,从而导致出现死锁问题。为了解决死锁问题,这里就需要引入过期时间的概念,过期时间是给当前这个 key 设置一定的存活时间,当存活时间到期后,Redis 就会自动删除这个过期的 Key,从而使得程序在崩溃时也能到期自动释放锁使用 Redis 的 expire 命令来为锁设置过期时间,从而实现到期自动解锁的功能,但这里仍然还存在一个问题就是加锁与给锁设置过期时间这两个操作命令并不是原子命令。
考虑这种情况:当程序在加锁完成后,在设置过期时间前崩溃,这时仍然会造成锁无法自动释放,从而产生死锁现象。
使用原子命令
针对上面加锁与设置过期时间不是原子命令的问题,Redis 提供了一个原子命令如下:
通过 SetNx(key,value,timeOut) 这个结合加锁与设置过期时间的原子命令就能完整的实现基于 Redis 的分布式锁的加锁步骤。
解锁原理
解锁原理就是基于 Redis 的 del 删除 key 指令。
错误删除锁问题
上面直接删除 key 来解锁方式会存在一个问题,考虑下面这种情况:
(1)线程 1 执行业务时间过长导致自己加的锁过期
(2)这时线程 2 进来加锁成功
(3)然后线程 1 业务逻辑执行完毕开始执行 del key 命令
(4)这时就会出现错误删除线程 2 加的锁
(5)错误删除线程 2 的锁后,线程 3 又可以加锁成功,导致有两个线程执行业务代码
加入锁标识
为了解决这种错误删除其他线程的锁的问题,在这里需要对加锁命令进行改造,需要在 value 字段里加入当前线程的 id,在这里可以使用 uuid 来实现。线程在删除锁的时候,用自己的 uuid 与 Redis 中锁的 uuid 进行比较,如果是自己的锁就进行删除,否则不删除。
但这里同样存在原子命令问题,比较并删除这个操作并不是原子命令,考虑下面这种情况:
(1)线程 1 获取 uuid 并判断锁是自己的
(2)准备解锁时出现 GC 或者其他原因导致程序卡顿无法立即执行 Del 命令,导致线程 1 的锁过期
(3)线程 2 就会在这个时候加锁成功
(4)线程 1 卡顿结束继续执行解锁指令,就会错误删除线程 2 的锁
这个问题出现的根本原因还是比较并删除这两个操作并不是原子命令,只要两个命令被打断就有可能出现并发问题,如果将两个命令变为原子命令就能解决这个问题。
引入 lua 脚本实现原子删除操作
lua 脚本是一个非常轻量级的脚本语言,Redis 底层原生支持 lua 脚本的执行,一个 lua 脚本中可以包含多条 Redis 命令,Redis 会将整个 lua 脚本当作原子操作来执行,从而实现聚合多条 Redis 指令的原子操作。这里在解锁时,使用 lua 脚本将比较并删除操作变为原子操作。
//lua脚本如下
luaScript = " if redis.call('get',key) == value then
return redis.call('del',key)
else
return 0
end;"
如上面的 lua 脚本所示,Redis 会将整个 lua 脚本当作一个单独的命令执行,从而实现多个命令的原子操作,避免多线程竞争问题,最终结合 lua 脚本实现了一个完整的分布式的加锁和解锁过程,伪代码如下:
uuid = getUUID();
//加锁
lockResut = redisClient.setNx(key,uuid,timeOut);
if(!lockResult){
return;
}
try{
//执行业务逻辑
}finally{
//解锁
redisClient.eval(delLuaScript,keys,values)
}
//解锁的lua脚本
delLuaScript = " if redis.call('get',key) == value then
return redis.call('del',key)
else
return 0
end;"
到此最终实现了一个加锁和解锁功能较为完整的 redis 分布式锁了,当然作为一个锁来说,还有一些其他的功能需要进一步完善,例如考虑锁失效问题,可重入问题等。
自动续期功能
在执行业务代码时,由于业务执行时间长,最终可能导致在业务执行过程中,自己的锁超时,然后锁自动释放了,在这种情况下第二个线程就会加锁成功,从而导致数据不一致的情况发生。对于上述的这种情况,原因是由于设置的过期时间太短或者业务执行时间太长导致锁过期,但是为了避免死锁问题又必须设置过期时间,那这就需要引入自动续期的功能,即在加锁成功时,开启一个定时任务,自动刷新 Redis 加锁 key 的超时时间,从而避免上诉情况发生:
uuid = getUUID();
//加锁
lockResut = redisClient.setNx(key,uuid,timeOut);
if(!lockResult){
return;
}
//开启一个定时任务
new Scheduler(key,time,uuid,scheduleTime)
try{
//执行业务逻辑
}finally{
//删除锁
redisClient.eval(delLuaScript,keys,values)
//取消定时任务
cancelScheduler(uuid);
}
如上述代码所示,在加锁成功后可以启动一个定时任务来对锁进行自动续期,定时任务的执行逻辑是:
(1)判断 Redis 中的锁是否是自己的
(2)如果存在的话就使用 expire 命令重新设置过期时间
这里由于需要两个 Redis 的命令,所以也需要使用 lua 脚本来实现原子操作,代码如下所示:
luaScript = "if redis.call('get',key) == value) then
return redis.call('expire',key,timeOut);
else
return 0;
end;"
可重入锁
对于一个功能完整的锁来说,可重入功能是必不可少的特性,所谓的锁可重入就是同一个线程,第一次加锁成功后,在第二次加锁时,无需进行排队等待,只需要判断是否是自己的锁就行了,可以直接再次获取锁来执行业务逻辑。实现可重入机制的原理就是在加锁的时候记录加锁次数,在释放锁的时候减少加锁次数,这个加锁的次数记录可以存在 Redis 中,加入可重入功能后,加锁的步骤就变为如下步骤:
(1)判断锁是否存在
(2)判断锁是否是自己的
(3)增加加锁的次数
由于增加次数以及减少次数是多个操作,这里需要再次使用 lua 脚本来实现,同时由于这里需要在 Redis 中存入加锁的次数,所以需要使用到 Redis 中的 Map 数据结构 Map(key,uuid,lockCount),加锁 lua 脚本如下:
//锁不存在
if (redis.call('exists', key) == 0) then
redis.call('hset', key, uuid, 1);
redis.call('expire', key, time);
return 1;
end;
//锁存在,判断是否是自己的锁
if (redis.call('hexists', key, uuid) == 1) then
redis.call('hincrby', key, uuid, 1);
redis.call('expire', key, uuid);
return 1;
end;
//锁不是自己的,返回加锁失败
return 0;
加入可重入功能后的解锁逻辑就变为:
(1)判断锁是否是自己的
(2)如果是自己的则减少加锁次数,否则返回解锁失败
//判断锁是否是自己的,不是自己的直接返回错误
if (redis.call('hexists', key,uuid) == 0) then
return 0;
end;
//锁是自己的,则对加锁次数-1
local counter = redis.call('hincrby', key, uuid, -1);
if (counter > 0) then
//剩余加锁次数大于0,则不能释放锁,重新设置过期时间
redis.call('expire', key, uuid);
return 1;
else
//等于0,代表可以释放锁了
redis.call('del', key);
return 1;
end;
到此在实现基本的加锁与解锁的逻辑上,又加入了可重入和自动续期的功能,自此一个完整的 Redis 分布式锁的雏形就实现了,伪代码如下:
uuid = getUUID();
//加锁
lockResut = redisClient.eval(addLockLuaScript,keys,values);
if(!lockResult){
return;
}
//开启一个定时任务
new Scheduler(key,time,uuid,scheduleTime)
try{
//执行业务逻辑
}finally{
//删除锁
redisClient.eval(delLuaScript,keys,values)
//取消定时任务
cancelScheduler(uuid);
}