ZooKeeper原理及其应用
ZooKeeper原理
ZooKeeper在大型分布式系统(Hadoop和HBase)中的应用
获取ZooKeeper的运行状态
XXXX is not executed because it is not in the whitelist
ZooKeeper升级参考
获取ZooKeeper的运行状态
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现。分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
基本概念
本节将介绍ZooKeeper的几个核心概念。这些概念贯穿于之后对ZooKeeper更深入的讲解,因此有必要预先了解这些概念。
集群角色
在ZooKeeper中,有三种角色:Leader、Follower、Observer。
一个ZooKeeper集群同一时刻只会有一个Leader,其他都是Follower或Observer。其配置很简单,每个节点的配置文件(zoo.cfg)都是一样的,只有myid文件不一样。myid的值必须是zoo.cfg中server.{数值}的{数值}部分。
zoo.cfg文件内容示例:
maxClientCnxns=0
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/var/lib/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the directory where the transaction logs are stored.
dataLogDir=/var/lib/zookeeper/logs
server.1=192.168.20.101:2888:3888
server.2=192.168.20.102:2888:3888
server.3=192.168.20.103:2888:3888
server.4=192.168.20.104:2888:3888
server.5=192.168.20.105:2888:3888
minSessionTimeout=4000
maxSessionTimeout=100000
在装有ZooKeeper的机器的终端执行 zookeeper-server status 可以看当前节点的ZooKeeper是什么角色(Leader or Follower)。
[root@node-20-103 ~]# zookeeper-server status
JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
Mode: follower
[root@node-20-104 ~]# zookeeper-server status
JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
Mode: leader
如上,node-20-104是Leader,node-20-103是follower。
ZooKeeper默认只有Leader和Follower两种角色,没有Observer角色。
为了使用Observer模式,在任何想变成Observer的节点的配置文件中加入:peerType=observer
并在所有server的配置文件中,配置成observer模式的server的那行配置追加:observer,例如:
server.1:localhost:2888:3888:observer
ZooKeeper集群的所有机器通过一个Leader选举过程来选定一台被称为『Leader』的机器,Leader服务器为客户端提供读和写服务。
Follower和Observer都能提供读服务,不能提供写服务。两者唯一的区别在于,Observer机器不参与Leader选举过程,也不参与写操作的『过半写成功』策略,因此Observer可以在不影响写性能的情况下提升集群的读性能。
会话(Session)
Session是指客户端会话,在讲解客户端会话之前,我们先来了解下客户端连接。在ZooKeeper中,一个客户端连接是指客户端和ZooKeeper服务器之间的TCP长连接。ZooKeeper对外的服务端口默认是2181,客户端启动时,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期也开始了,通过这个连接,客户端能够通过心跳检测和服务器保持有效的会话,也能够向ZooKeeper服务器发送请求并接受响应,同时还能通过该连接接收来自服务器的Watch事件通知。Session的SessionTimeout值用来设置一个客户端会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在SessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
数据节点(ZNode)
在谈到分布式的时候,一般『节点』指的是组成集群的每一台机器。而ZooKeeper中的数据节点是指数据模型中的数据单元,称为ZNode。ZooKeeper将所有数据存储在内存中,数据模型是一棵树(ZNode Tree),由斜杠(/)进行分割的路径,就是一个ZNode,如/hbase/master,其中hbase和master都是ZNode。每个ZNode上都会保存自己的数据内容,同时会保存一系列属性信息。
注:这里的ZNode可以理解成既是Unix里的文件,又是Unix里的目录。因为每个ZNode不仅本身可以写数据(相当于Unix里的文件),还可以有下一级文件或目录(相当于Unix里的目录)。
在ZooKeeper中,ZNode可以分为持久节点和临时节点两类。
持久节点:所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在ZooKeeper上。
临时节点:临时节点的生命周期跟客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
另外,ZooKeeper还允许用户为每个节点添加一个特殊的属性:SEQUENTIAL。一旦节点被标记上这个属性,那么在这个节点被创建的时候,ZooKeeper就会自动在其节点后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
版本
ZooKeeper的每个ZNode上都会存储数据,对应于每个ZNode,ZooKeeper都会为其维护一个叫作Stat的数据结构,Stat中记录了这个ZNode的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和aversion(当前ZNode的ACL版本)。
状态信息
每个ZNode除了存储数据内容之外,还存储了ZNode本身的一些状态信息。用 get 命令可以同时获得某个ZNode的内容和状态信息。如下:
[zk: localhost:2181(CONNECTED) 23] get /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb
appcluster-yarnrm1
cZxid = 0x1b00133dc0 //Created ZXID,表示该ZNode被创建时的事务ID
ctime = Tue Jan 03 15:44:42 CST 2017 //Created Time,表示该ZNode被创建的时间
mZxid = 0x1d00000063 //Modified ZXID,表示该ZNode最后一次被更新时的事务ID
mtime = Fri Jan 06 08:44:25 CST 2017 //Modified Time,表示该节点最后一次被更新的时间
pZxid = 0x1b00133dc0 //表示该节点的子节点列表最后一次被修改时的事务ID。注意,只有子节点列表变更了才会变更pZxid,子节点内容变更不会影响pZxid。
cversion = 0 //子节点的版本号
dataVersion = 11 //数据节点的版本号
aclVersion = 0 //ACL版本号
ephemeralOwner = 0x0 //创建该节点的会话的seddionID。如果该节点是持久节点,那么这个属性值为0。
dataLength = 22 //数据内容的长度
numChildren = 0 //子节点的个数
在ZooKeeper中,version属性是用来实现乐观锁机制中的『写入校验』的(保证分布式数据原子性操作)。
事务操作
在ZooKeeper中,能改变ZooKeeper服务器状态的操作称为事务操作。一般包括数据节点创建与删除、数据内容更新和客户端会话创建与失效等操作。对应每一个事务请求,ZooKeeper都会为其分配一个全局唯一的事务ID,用ZXID表示,通常是一个64位的数字。每一个ZXID对应一次更新操作,从这些ZXID中可以间接地识别出ZooKeeper处理这些事务操作请求的全局顺序。
Watcher
Watcher(事件监听器),是ZooKeeper中一个很重要的特性。ZooKeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper服务端会将事件通知到感兴趣的客户端上去。该机制是ZooKeeper实现分布式协调服务的重要特性。
ACL
ZooKeeper采用ACL(Access Control Lists)策略来进行权限控制。ZooKeeper定义了如下5种权限。
CREATE: 创建子节点的权限。
READ: 获取节点数据和子节点列表的权限。
WRITE:更新节点数据的权限。
DELETE: 删除子节点的权限。
ADMIN: 设置节点ACL的权限。
注意:CREATE 和 DELETE 都是针对子节点的权限控制。
典型应用场景
ZooKeeper是一个高可用的分布式数据管理与协调框架。基于对ZAB算法的实现,该框架能够很好地保证分布式环境中数据的一致性。也是基于这样的特性,使得ZooKeeper成为了解决分布式一致性问题的利器。
数据发布与订阅(配置中心)
数据发布与订阅,即所谓的配置中心,顾名思义就是发布者将数据发布到ZooKeeper节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和动态更新。
在我们平常的应用系统开发中,经常会碰到这样的需求:系统中需要使用一些通用的配置信息,例如机器列表信息、数据库配置信息等。这些全局配置信息通常具备以下3个特性:
数据量通常比较小、数据内容在运行时动态变化、集群中各机器共享,配置一致。
对于这样的全局配置信息就可以发布到ZooKeeper上,让客户端(集群的机器)去订阅该消息。发布/订阅系统一般有两种设计模式,分别是推(Push)和拉(Pull)模式:
推:服务端主动将数据更新发送给所有订阅的客户端。
拉:客户端主动发起请求来获取最新数据,通常客户端都采用定时轮询拉取的方式。
ZooKeeper采用的是推拉相结合的方式。如下:
客户端想服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据(推拉结合)。
命名服务(Naming Service)
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架(如RPC、RMI)中的服务地址列表。通过在ZooKeepr里创建顺序节点,能够很容易创建一个全局唯一的路径,这个路径就可以作为一个名字。
ZooKeeper的命名服务即生成全局唯一的ID。
分布式协调/通知
ZooKeeper中特有Watcher注册与异步通知机制,能够很好的实现分布式环境下不同机器,甚至不同系统之间的通知与协调,从而实现对数据变更的实时处理。使用方法通常是不同的客户端都对ZK上同一个ZNode进行注册,监听ZNode的变化(包括ZNode本身内容及子节点的),如果ZNode发生了变化,那么所有订阅的客户端都能够接收到相应的Watcher通知,并做出相应的处理。
ZK的分布式协调/通知,是一种通用的分布式系统机器间的通信方式。
心跳检测
机器间的心跳检测机制是指在分布式环境中,不同机器(或进程)之间需要检测到彼此是否在正常运行,例如A机器需要知道B机器是否正常运行。在传统的开发中,我们通常是通过主机直接是否可以相互PING通来判断,更复杂一点的话,则会通过在机器之间建立长连接,通过TCP连接固有的心跳检测机制来实现上层机器的心跳检测,这些都是非常常见的心跳检测方法。下面来看看如何使用ZK来实现分布式机器(进程)间的心跳检测。
基于ZK的临时节点的特性,可以让不同的进程都在ZK的一个指定节点下创建临时子节点,不同的进程直接可以根据这个临时子节点来判断对应的进程是否存活。通过这种方式,检测和被检测系统直接并不需要直接相关联,而是通过ZK上的某个节点进行关联,大大减少了系统耦合。
工作进度汇报
在一个常见的任务分发系统中,通常任务被分发到不同的机器上执行后,需要实时地将自己的任务执行进度汇报给分发系统。这个时候就可以通过ZK来实现。在ZK上选择一个节点,每个任务客户端都在这个节点下面创建临时子节点,这样便可以实现两个功能:
通过判断临时节点是否存在来确定任务机器是否存活。
各个任务机器会实时地将自己的任务执行进度写到这个临时节点上去,以便中心系统能够实时地获取到任务的执行进度。
Master选举
Master选举可以说是ZooKeeper最典型的应用场景了。比如HDFS中Active NameNode的选举、YARN中Active ResourceManager的选举和HBase中Active HMaster的选举等。
针对Master选举的需求,通常情况下,我们可以选择常见的关系型数据库中的主键特性来实现:希望成为Master的机器都向数据库中插入一条相同主键ID的记录,数据库会帮我们进行主键冲突检查,也就是说,只有一台机器能插入成功——那么,我们就认为向数据库中成功插入数据的客户端机器成为Master。依靠关系型数据库的主键特性确实能够很好地保证在集群中选举出唯一的一个Master。但是,如果当前选举出的Master挂了,那么该如何处理?谁来告诉我Master挂了呢?显然,关系型数据库无法通知我们这个事件。但ZooKeeper可以做到!
利用ZooKeepr的强一致性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即ZooKeeper将会保证客户端无法创建一个已经存在的ZNode。也就是说,如果同时有多个客户端请求创建同一个临时节点,那么最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很容易地在分布式环境中进行Master选举了。
成功创建该节点的客户端所在的机器就成为了Master。同时,其他没有成功创建该节点的客户端,都会在该节点上注册一个子节点变更的Watcher,用于监控当前Master机器是否存活,一旦发现当前的Master挂了,那么其他客户端将会重新进行Master选举。这样就实现了Master的动态选举。
分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。其分为排他锁和共享锁两种。
排他锁
排他锁(Exclusive Locks,简称X锁),又称为写锁或独占锁。如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能在对这个数据对象进行任何类型的操作(不能再对该对象加锁),直到T1释放了排他锁。可以看出,排他锁的核心是如何保证当前只有一个事务获得锁,并且锁被释放后,所有正在等待获取锁的事务都能够被通知到。
如何利用ZooKeeper实现排他锁?
定义锁
ZooKeeper上的一个ZNode可以表示一个锁;例如/exclusive_lock/lock节点就可以被定义为一个锁。
获得锁
如上所说,把ZooKeeper上的一个ZNode看作是一个锁,获得锁就通过创建ZNode的方式来实现。所有客户端都去/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。ZooKeeper会保证在所有客户端中,最终只有一个客户端能够创建成功,那么就可以认为该客户端获得了锁。同时,所有没有获取到锁的客户端就需要到/exclusive_lock节点上注册一个子节点变更的Watcher监听,以便实时监听到lock节点的变更情况。
释放锁
因为/exclusive_lock/lock是一个临时节点,因此在以下两种情况下,都有可能释放锁。
当前获得锁的客户端机器发生宕机或重启,那么该临时节点就会被删除,释放锁。
正常执行完业务逻辑后,客户端就会主动将自己创建的临时节点删除,释放锁。
无论在什么情况下移除了lock节点,ZooKeeper都会通知所有在/exclusive_lock节点上注册了节点变更Watcher监听的客户端。这些客户端在接收到通知后,再次重新发起分布式锁获取,即重复『获取锁』过程。
共享锁
共享锁(Shared Locks,简称S锁),又称为读锁。如果事务T1对数据对象O1加上了共享锁,那么T1只能对O1进行读操作,其他事务也能同时对O1加共享锁(不能是排他锁),直到O1上的所有共享锁都释放后O1才能被加排他锁。
总结:可以多个事务同时获得一个对象的共享锁(同时读),有共享锁就不能再加排他锁(因为排他锁是写锁)
在大型分布式系统中的应用
前面已经介绍了ZooKeeper的典型应用场景。本节将以常见的大数据产品Hadoop和HBase为例来介绍ZooKeeper在其中的应用,帮助大家更好地理解其分布式应用场景。
ZooKeeper在Hadoop中的应用
在Hadoop中的ZooKeeper主要用于实现HA(High Availability),包括HDFS的NamaNode和YARN的ResourceManager的HA。同时在YARN中还用来存储应用的运行状态。HDFS的NamaNode和YARN的ResourceManager利用ZooKeepr实现HA的原理是一样的,所以在此以YARN为例来介绍。
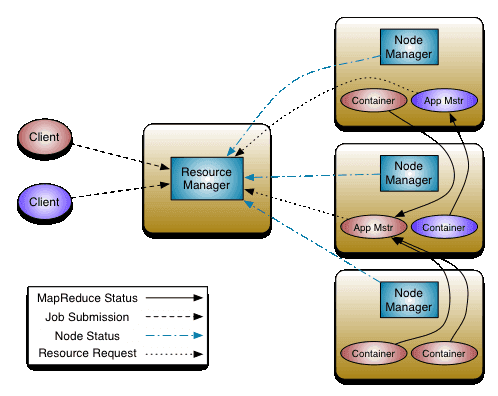
YARN架构体系
从上图可以看出,YARN主要由ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)和Container四部分组成。其中最核心的就是ResourceManager。
ResourceManager负责集群中所有资源的统一管理和分配,同时接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(Application Manager),其内部维护了各个应用程序的ApplicationMaster信息、NodeManager信息以及资源使用信息等。为了实现HA,必须有多个ResourceManager并存(一般就两个),并且只有一个ResourceManager处于Active状态,其他的则处于Standby状态,当Active节点无法正常工作(如机器宕机或重启)时,处于Standby的就会通过竞争选举产生新的Active节点。
主备切换
下面就来看看YARN是如何实现多个ResourceManager之间的主备切换的。
创建锁节点
在ZooKeeper上会有一个/yarn-leader-election/appcluster-yarn的锁节点,所有的ResourceManager在启动的时候,都会去竞争写一个Lock子节点:/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb,该节点是临时节点。ZooKeepr能够为我们保证最终只有一个ResourceManager能够创建成功。创建成功的那个ResourceManager就切换为Active状态,没有成功的那些ResourceManager则切换为Standby状态。
[zk: localhost:2181(CONNECTED) 16] get /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb
appcluster-yarnrm2
cZxid = 0x1b00133dc0
ctime = Tue Jan 03 15:44:42 CST 2017
mZxid = 0x1f00000540
mtime = Sat Jan 07 00:50:20 CST 2017
pZxid = 0x1b00133dc0
cversion = 0
dataVersion = 28
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0
可以看到此时集群中ResourceManager2为Active。
注册Watcher监听
所有Standby状态的ResourceManager都会向/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点注册一个节点变更的Watcher监听,利用临时节点的特性,能够快速感知到Active状态的ResourceManager的运行情况。
主备切换
当Active状态的ResourceManager出现诸如宕机或重启的异常情况时,其在ZooKeeper上连接的客户端会话就会失效,因此/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点就会被删除。此时其余各个Standby状态的ResourceManager就都会接收到来自ZooKeeper服务端的Watcher事件通知,然后会重复进行步骤1的操作。
以上就是利用ZooKeeper来实现ResourceManager的主备切换的过程,实现了ResourceManager的HA。HDFS中NameNode的HA的实现原理跟YARN中ResourceManager的HA的实现原理相同。其锁节点为/hadoop-ha/mycluster/ActiveBreadCrumb。
ResourceManager状态存储
在 ResourceManager 中,RMStateStore 能够存储一些 RM 的内部状态信息,包括 Application 以及它们的 Attempts 信息、Delegation Token 及 Version Information 等。需要注意的是,RMStateStore 中的绝大多数状态信息都是不需要持久化存储的,因为很容易从上下文信息中将其重构出来,如资源的使用情况。在存储的设计方案中,提供了三种可能的实现,分别如下:基于内存实现,一般是用于日常开发测试;基于文件系统的实现,如HDFS;基于ZooKeeper实现。
由于这些状态信息的数据量都不是很大,因此Hadoop官方建议基于ZooKeeper来实现状态信息的存储。在ZooKeepr上,ResourceManager 的状态信息都被存储在/rmstore这个根节点下面。
[zk: localhost:2181(CONNECTED) 28] ls /rmstore/ZKRMStateRoot
[RMAppRoot, AMRMTokenSecretManagerRoot, EpochNode, RMDTSecretManagerRoot, RMVersionNode]
RMAppRoot 节点下存储的是与各个 Application 相关的信息,RMDTSecretManagerRoot 存储的是与安全相关的 Token 等信息。每个 Active 状态的 ResourceManager 在初始化阶段都会从 ZooKeeper 上读取到这些状态信息,并根据这些状态信息继续进行相应的处理。
小结:
ZooKeepr在Hadoop中的应用主要有:
HDFS中NameNode的HA和YARN中ResourceManager的HA。
存储RMStateStore状态信息
ZooKeeper在HBase中的应用
HBase主要用ZooKeeper来实现HMaster选举与主备切换、系统容错、RootRegion管理、Region状态管理和分布式SplitWAL任务管理等。HMaster选举与主备切换的原理和HDFS中NameNode及YARN中ResourceManager的HA原理相同。
系统容错
当HBase启动时,每个RegionServer都会到ZooKeeper的/hbase/rs节点下创建一个信息节点(下文中,我们称该节点为”rs状态节点”),例如/hbase/rs/[Hostname],同时,HMaster会对这个节点注册监听。当某个 RegionServer 挂掉的时候,ZooKeeper会因为在一段时间内无法接受其心跳(即 Session 失效),而删除掉该 RegionServer 服务器对应的 rs 状态节点。与此同时,HMaster 则会接收到 ZooKeeper 的 NodeDelete 通知,从而感知到某个节点断开,并立即开始容错工作。
HBase为什么不直接让HMaster来负责RegionServer的监控呢?如果HMaster直接通过心跳机制等来管理RegionServer的状态,随着集群越来越大,HMaster的管理负担会越来越重,另外它自身也有挂掉的可能,因此数据还需要持久化。在此情况下,ZooKeeper就成了理想的选择。
RootRegion管理
对应HBase集群来说,数据存储的位置信息是记录在元数据region,也就是RootRegion上的。每次客户端发起新的请求,需要知道数据的位置,就会去查询RootRegion,而RootRegion自身位置则是记录在ZooKeeper上的(默认情况下,是记录在ZooKeeper的/hbase/meta-region-server节点中)。当RootRegion发生变化,比如Region的手工移动、重新负载均衡或RootRegion所在服务器发生了故障等是,就能够通过ZooKeeper来感知到这一变化并做出一系列相应的容灾措施,从而保证客户端总是能够拿到正确的RootRegion信息。
Region管理
HBase里的Region会经常发生变更,这些变更的原因来自于系统故障、负载均衡、配置修改、Region分裂与合并等。一旦Region发生移动,它就会经历下线(offline)和重新上线(online)的过程。在下线期间数据是不能被访问的,并且Region的这个状态变化必须让全局知晓,否则可能会出现事务性的异常。对于大的HBase集群来说,Region的数量可能会多达十万级别,甚至更多,这样规模的Region状态管理交给ZooKeeper来做也是一个很好的选择。
分布式SplitWAL任务管理
当某台RegionServer服务器挂掉时,由于总有一部分新写入的数据还没有持久化到HFile中,因此在迁移该RegionServer的服务时,一个重要的工作就是从WAL中恢复这部分还在内存中的数据,而这部分工作最关键的一步就是SplitWAL,即HMaster需要遍历该RegionServer服务器的WAL,并按Region切分成小块移动到新的地址下,并进行日志的回放(replay)。
由于单个RegionServer的日志量相对庞大(可能有上千个Region,上GB的日志),而用户又往往希望系统能够快速完成日志的恢复工作。因此一个可行的方案是将这个处理WAL的任务分给多台RegionServer服务器来共同处理,而这就又需要一个持久化组件来辅助HMaster完成任务的分配。当前的做法是,HMaster会在ZooKeeper上创建一个SplitWAL节点(默认情况下,是/hbase/SplitWAL节点),将“哪个RegionServer处理哪个Region”这样的信息以列表的形式存放到该节点上,然后由各个RegionServer服务器自行到该节点上去领取任务并在任务执行成功或失败后再更新该节点的信息,以通知HMaster继续进行后面的步骤。ZooKeeper在这里担负起了分布式集群中相互通知和信息持久化的角色。
小结:
以上就是一些HBase中依赖ZooKeeper完成分布式协调功能的典型场景。但事实上,HBase对ZooKeepr的依赖还不止这些,比如HMaster还依赖ZooKeeper来完成Table的enable/disable状态记录,以及HBase中几乎所有的元数据存储都是放在其上的。由于ZooKeeper出色的分布式协调能力及良好的通知机制,HBase在各版本的演进过程中越来越多地增加了ZooKeeper的应用场景,从趋势上来看两者的交集越来越多。HBase中所有对ZooKeeper的操作都封装在了org.apache.hadoop.hbase.zookeeper这个包中,感兴趣的同学可以自行研究。
获取ZooKeeper的运行状态
方式一:Tcp服务端口获取
get zookeeper(cluster) status
echo status | nc localhost 2181
该zk的模式
echo stat | nc localhost 2181
...
Mode: leader
...
Mode: follower
如果加了对应的访问控制规则,可能会报:
stat is not executed because it is not in the whitelist.
可在其控制脚本中使用指令来获取部分运行信息
>./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /freeoa/apache-zookeeper-3.8.2-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
更多的信息还要靠指令
echo mntr | nc localhost 2181
The output of which is:
zk_version 3.4.8--1, built on 02/06/2016 03:18 GMT
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 7
zk_packets_sent 6
zk_num_alive_connections 2
zk_outstanding_requests 0
zk_server_state follower
zk_znode_count 357
zk_watch_count 0
zk_ephemerals_count 5
zk_approximate_data_size 846524
zk_open_file_descriptor_count 36
zk_max_file_descriptor_count 4096
If the node is a leader, you will also see:
zk_followers 5
zk_synced_followers 5
zk_pending_syncs 0
The following will not be present on Windows platforms:
zk_open_file_descriptor_count 43
zk_max_file_descriptor_count 4096
综合使用以上信息,可以确定Zookeeper集群的健康状况。
方式二:从HTTP辅助服务获取信息
curl -s http://localhost:8080/commands/envi
{
"zookeeper.version" : "3.8.2-139d619b58292d7734b4fc83a0f44be4e7b0c986, built on 2023-07-05 19:24 UTC",
"host.name" : "zk1.freeoa.net",
"java.version" : "1.8.0_202",
"java.vendor" : "Oracle Corporation",
"java.home" : "/usr/java/jdk1.8.0_202-amd64/jre",
"java.class.path" : "ALL-Jar-Libs",
"java.library.path" : "/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib",
"java.io.tmpdir" : "/tmp",
"java.compiler" : "<NA>",
"os.name" : "Linux",
"os.arch" : "amd64",
"os.version" : "3.10.0-957.el7.x86_64",
"user.name" : "root",
"user.home" : "/root",
"user.dir" : "/freeoa/apache-zookeeper-3.8.2-bin/bin",
"os.memory.free" : "369MB",
"os.memory.max" : "889MB",
"os.memory.total" : "468MB",
"command" : "environment",
"error" : null
}
可参考官方参考文档:zookeeperAdmin.html#sc_adminserver
XXXX is not executed because it is not in the whitelist
这些其实是4字命令(4lw.commands),可在配置文件(推荐)或启动脚本中开启。
1.配置文件(zoo.cfg)
4lw.commands.whitelist=*
保存后重启zookeeper即可。
2.启动脚本(bin/zkServer.sh)
在启动脚本里添加vm环境变量-Dzookeeper.4lw.commands.whitelist=*,便可以把所有指令添加到白名单,在脚本的这个位置:
if [ "x$JMXHOSTNAME" = "x" ]
then
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=$JMXPORT -Dcom.sun.management.jmxremote.authenticate=$JMXAUTH -Dcom.sun.management.jmxremote.ssl=$JMXSSL -Dzookeeper.jmx.log4j.disable=$JMXLOG4J org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
else
echo "JMX disabled by user request" >&2
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
#如果不想在此添加,注意位置和赋值的顺序
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
然后重启就可以了。
手册页中有相关的说明。https://zookeeper.apache.org/doc/r3.8.0/zookeeperAdmin.html
4lw.commands.whitelist : (Java system property: zookeeper.4lw.commands.whitelist) New in 3.5.3: A list of comma separated Four Letter Words commands that user wants to use. A valid Four Letter Words command must be put in this list else ZooKeeper server will not enable the command. By default the whitelist only contains "srvr" command which zkServer.sh uses. The rest of four-letter word commands are disabled by default: attempting to use them will gain a response ".... is not executed because it is not in the whitelist." Here's an example of the configuration that enables stat, ruok, conf, and isro command while disabling the rest of Four Letter Words command:
4lw.commands.whitelist=stat, ruok, conf, isro
If you really need enable all four-letter word commands by default, you can use the asterisk option so you don't have to include every command one by one in the list. As an example, this will enable all four-letter word commands:
4lw.commands.whitelist=*
srvr指令是默认就开启的,无需显式配置开启
echo srvr | nc localhost 2181
Zookeeper version: 3.8.2-139d619b58292d7734b4fc83a0f44be4e7b0c986, built on 2023-07-05 19:24 UTC
Latency min/avg/max: 0/2.8076/22800
Received: 76556
Sent: 76860
Connections: 2
Outstanding: 0
Zxid: 0x3000017ae
Mode: follower
Node count: 1800
wchc查看监听路径信息,更多的4字指令可参考文档:zookeeperAdmin.html#sc_4lw。
ZooKeeper升级参考
对配置文件(conf/zoo.cfg)的备份是必须的,程序采用备份老的程序并部署新版本的代码或直接覆盖。
关闭原来的zk服务
./zkServer.sh stop
启用新的zk服务
./zkServer.sh start
验证:
./zkCli.sh -server {服务器IP}:2181
未授权访问控制:
#ZooKeeper设置ACL权限控制
#ZK的节点有5种操作权限:CREATE、READ、WRITE、DELETE、ADMIN
#也就是增、删、改、查、管理权限,这5种权限简写为crwda(即:每个单词的首字符缩写)
#注:这5种权限中,delete是指对子节点的删除权限,其它4种权限指对自身节点的操作权限。
#身份的认证有4种方式:
#world:默认方式,相当于全世界都能访问
#auth:代表已经认证通过的用户(cli中可以通过addauth digest user:pwd 来添加当前上下文中的授权用户)
#digest:即用户名:密码这种方式认证,这也是业务系统中最常用的
#ip:使用Ip地址认证
#设置访问控制:ls / 根目录下的节点和根目录本身
#方式一:(推荐)
1.增加一个认证用户:addauth digest 用户名:密码明文
#eg. addauth digest user1:password1
addauth digest zk:Passw0rd
2.设置权限:setAcl /path auth:用户名:密码明文:权限
#eg. setAcl /test auth:user1:password1:cdrwa
setAcl /inf-confserver auth:zk:Passw0rd:cdrwa
setAcl /zookeeper auth:zk:Passw0rd:cdrwa
setAcl / auth:zk:Passw0rd:cdrwa
3.查看Acl设置
#getAcl /path
#方式二:
#setAcl /path digest:用户名:密码密文:权限
#注:这里的加密规则是SHA1加密,然后base64编码
#删除权限
#找到zookeeper的日志地址,把日志删除或者 delete /节点
#linux环境下也可以使用此命令查询日志地址:
echo conf | nc 127.0.0.1 2181
在zookeeperTools中有bin目录的控制脚本的说明。
ZooKeeper在大型分布式系统(Hadoop和HBase)中的应用
获取ZooKeeper的运行状态
XXXX is not executed because it is not in the whitelist
ZooKeeper升级参考
获取ZooKeeper的运行状态
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现。分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
基本概念
本节将介绍ZooKeeper的几个核心概念。这些概念贯穿于之后对ZooKeeper更深入的讲解,因此有必要预先了解这些概念。
集群角色
在ZooKeeper中,有三种角色:Leader、Follower、Observer。
一个ZooKeeper集群同一时刻只会有一个Leader,其他都是Follower或Observer。其配置很简单,每个节点的配置文件(zoo.cfg)都是一样的,只有myid文件不一样。myid的值必须是zoo.cfg中server.{数值}的{数值}部分。
zoo.cfg文件内容示例:
maxClientCnxns=0
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/var/lib/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the directory where the transaction logs are stored.
dataLogDir=/var/lib/zookeeper/logs
server.1=192.168.20.101:2888:3888
server.2=192.168.20.102:2888:3888
server.3=192.168.20.103:2888:3888
server.4=192.168.20.104:2888:3888
server.5=192.168.20.105:2888:3888
minSessionTimeout=4000
maxSessionTimeout=100000
在装有ZooKeeper的机器的终端执行 zookeeper-server status 可以看当前节点的ZooKeeper是什么角色(Leader or Follower)。
[root@node-20-103 ~]# zookeeper-server status
JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
Mode: follower
[root@node-20-104 ~]# zookeeper-server status
JMX enabled by default
Using config: /etc/zookeeper/conf/zoo.cfg
Mode: leader
如上,node-20-104是Leader,node-20-103是follower。
ZooKeeper默认只有Leader和Follower两种角色,没有Observer角色。
为了使用Observer模式,在任何想变成Observer的节点的配置文件中加入:peerType=observer
并在所有server的配置文件中,配置成observer模式的server的那行配置追加:observer,例如:
server.1:localhost:2888:3888:observer
ZooKeeper集群的所有机器通过一个Leader选举过程来选定一台被称为『Leader』的机器,Leader服务器为客户端提供读和写服务。
Follower和Observer都能提供读服务,不能提供写服务。两者唯一的区别在于,Observer机器不参与Leader选举过程,也不参与写操作的『过半写成功』策略,因此Observer可以在不影响写性能的情况下提升集群的读性能。
会话(Session)
Session是指客户端会话,在讲解客户端会话之前,我们先来了解下客户端连接。在ZooKeeper中,一个客户端连接是指客户端和ZooKeeper服务器之间的TCP长连接。ZooKeeper对外的服务端口默认是2181,客户端启动时,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期也开始了,通过这个连接,客户端能够通过心跳检测和服务器保持有效的会话,也能够向ZooKeeper服务器发送请求并接受响应,同时还能通过该连接接收来自服务器的Watch事件通知。Session的SessionTimeout值用来设置一个客户端会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在SessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
数据节点(ZNode)
在谈到分布式的时候,一般『节点』指的是组成集群的每一台机器。而ZooKeeper中的数据节点是指数据模型中的数据单元,称为ZNode。ZooKeeper将所有数据存储在内存中,数据模型是一棵树(ZNode Tree),由斜杠(/)进行分割的路径,就是一个ZNode,如/hbase/master,其中hbase和master都是ZNode。每个ZNode上都会保存自己的数据内容,同时会保存一系列属性信息。
注:这里的ZNode可以理解成既是Unix里的文件,又是Unix里的目录。因为每个ZNode不仅本身可以写数据(相当于Unix里的文件),还可以有下一级文件或目录(相当于Unix里的目录)。
在ZooKeeper中,ZNode可以分为持久节点和临时节点两类。
持久节点:所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在ZooKeeper上。
临时节点:临时节点的生命周期跟客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
另外,ZooKeeper还允许用户为每个节点添加一个特殊的属性:SEQUENTIAL。一旦节点被标记上这个属性,那么在这个节点被创建的时候,ZooKeeper就会自动在其节点后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
版本
ZooKeeper的每个ZNode上都会存储数据,对应于每个ZNode,ZooKeeper都会为其维护一个叫作Stat的数据结构,Stat中记录了这个ZNode的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和aversion(当前ZNode的ACL版本)。
状态信息
每个ZNode除了存储数据内容之外,还存储了ZNode本身的一些状态信息。用 get 命令可以同时获得某个ZNode的内容和状态信息。如下:
[zk: localhost:2181(CONNECTED) 23] get /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb
appcluster-yarnrm1
cZxid = 0x1b00133dc0 //Created ZXID,表示该ZNode被创建时的事务ID
ctime = Tue Jan 03 15:44:42 CST 2017 //Created Time,表示该ZNode被创建的时间
mZxid = 0x1d00000063 //Modified ZXID,表示该ZNode最后一次被更新时的事务ID
mtime = Fri Jan 06 08:44:25 CST 2017 //Modified Time,表示该节点最后一次被更新的时间
pZxid = 0x1b00133dc0 //表示该节点的子节点列表最后一次被修改时的事务ID。注意,只有子节点列表变更了才会变更pZxid,子节点内容变更不会影响pZxid。
cversion = 0 //子节点的版本号
dataVersion = 11 //数据节点的版本号
aclVersion = 0 //ACL版本号
ephemeralOwner = 0x0 //创建该节点的会话的seddionID。如果该节点是持久节点,那么这个属性值为0。
dataLength = 22 //数据内容的长度
numChildren = 0 //子节点的个数
在ZooKeeper中,version属性是用来实现乐观锁机制中的『写入校验』的(保证分布式数据原子性操作)。
事务操作
在ZooKeeper中,能改变ZooKeeper服务器状态的操作称为事务操作。一般包括数据节点创建与删除、数据内容更新和客户端会话创建与失效等操作。对应每一个事务请求,ZooKeeper都会为其分配一个全局唯一的事务ID,用ZXID表示,通常是一个64位的数字。每一个ZXID对应一次更新操作,从这些ZXID中可以间接地识别出ZooKeeper处理这些事务操作请求的全局顺序。
Watcher
Watcher(事件监听器),是ZooKeeper中一个很重要的特性。ZooKeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper服务端会将事件通知到感兴趣的客户端上去。该机制是ZooKeeper实现分布式协调服务的重要特性。
ACL
ZooKeeper采用ACL(Access Control Lists)策略来进行权限控制。ZooKeeper定义了如下5种权限。
CREATE: 创建子节点的权限。
READ: 获取节点数据和子节点列表的权限。
WRITE:更新节点数据的权限。
DELETE: 删除子节点的权限。
ADMIN: 设置节点ACL的权限。
注意:CREATE 和 DELETE 都是针对子节点的权限控制。
典型应用场景
ZooKeeper是一个高可用的分布式数据管理与协调框架。基于对ZAB算法的实现,该框架能够很好地保证分布式环境中数据的一致性。也是基于这样的特性,使得ZooKeeper成为了解决分布式一致性问题的利器。
数据发布与订阅(配置中心)
数据发布与订阅,即所谓的配置中心,顾名思义就是发布者将数据发布到ZooKeeper节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和动态更新。
在我们平常的应用系统开发中,经常会碰到这样的需求:系统中需要使用一些通用的配置信息,例如机器列表信息、数据库配置信息等。这些全局配置信息通常具备以下3个特性:
数据量通常比较小、数据内容在运行时动态变化、集群中各机器共享,配置一致。
对于这样的全局配置信息就可以发布到ZooKeeper上,让客户端(集群的机器)去订阅该消息。发布/订阅系统一般有两种设计模式,分别是推(Push)和拉(Pull)模式:
推:服务端主动将数据更新发送给所有订阅的客户端。
拉:客户端主动发起请求来获取最新数据,通常客户端都采用定时轮询拉取的方式。
ZooKeeper采用的是推拉相结合的方式。如下:
客户端想服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据(推拉结合)。
命名服务(Naming Service)
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架(如RPC、RMI)中的服务地址列表。通过在ZooKeepr里创建顺序节点,能够很容易创建一个全局唯一的路径,这个路径就可以作为一个名字。
ZooKeeper的命名服务即生成全局唯一的ID。
分布式协调/通知
ZooKeeper中特有Watcher注册与异步通知机制,能够很好的实现分布式环境下不同机器,甚至不同系统之间的通知与协调,从而实现对数据变更的实时处理。使用方法通常是不同的客户端都对ZK上同一个ZNode进行注册,监听ZNode的变化(包括ZNode本身内容及子节点的),如果ZNode发生了变化,那么所有订阅的客户端都能够接收到相应的Watcher通知,并做出相应的处理。
ZK的分布式协调/通知,是一种通用的分布式系统机器间的通信方式。
心跳检测
机器间的心跳检测机制是指在分布式环境中,不同机器(或进程)之间需要检测到彼此是否在正常运行,例如A机器需要知道B机器是否正常运行。在传统的开发中,我们通常是通过主机直接是否可以相互PING通来判断,更复杂一点的话,则会通过在机器之间建立长连接,通过TCP连接固有的心跳检测机制来实现上层机器的心跳检测,这些都是非常常见的心跳检测方法。下面来看看如何使用ZK来实现分布式机器(进程)间的心跳检测。
基于ZK的临时节点的特性,可以让不同的进程都在ZK的一个指定节点下创建临时子节点,不同的进程直接可以根据这个临时子节点来判断对应的进程是否存活。通过这种方式,检测和被检测系统直接并不需要直接相关联,而是通过ZK上的某个节点进行关联,大大减少了系统耦合。
工作进度汇报
在一个常见的任务分发系统中,通常任务被分发到不同的机器上执行后,需要实时地将自己的任务执行进度汇报给分发系统。这个时候就可以通过ZK来实现。在ZK上选择一个节点,每个任务客户端都在这个节点下面创建临时子节点,这样便可以实现两个功能:
通过判断临时节点是否存在来确定任务机器是否存活。
各个任务机器会实时地将自己的任务执行进度写到这个临时节点上去,以便中心系统能够实时地获取到任务的执行进度。
Master选举
Master选举可以说是ZooKeeper最典型的应用场景了。比如HDFS中Active NameNode的选举、YARN中Active ResourceManager的选举和HBase中Active HMaster的选举等。
针对Master选举的需求,通常情况下,我们可以选择常见的关系型数据库中的主键特性来实现:希望成为Master的机器都向数据库中插入一条相同主键ID的记录,数据库会帮我们进行主键冲突检查,也就是说,只有一台机器能插入成功——那么,我们就认为向数据库中成功插入数据的客户端机器成为Master。依靠关系型数据库的主键特性确实能够很好地保证在集群中选举出唯一的一个Master。但是,如果当前选举出的Master挂了,那么该如何处理?谁来告诉我Master挂了呢?显然,关系型数据库无法通知我们这个事件。但ZooKeeper可以做到!
利用ZooKeepr的强一致性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即ZooKeeper将会保证客户端无法创建一个已经存在的ZNode。也就是说,如果同时有多个客户端请求创建同一个临时节点,那么最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很容易地在分布式环境中进行Master选举了。
成功创建该节点的客户端所在的机器就成为了Master。同时,其他没有成功创建该节点的客户端,都会在该节点上注册一个子节点变更的Watcher,用于监控当前Master机器是否存活,一旦发现当前的Master挂了,那么其他客户端将会重新进行Master选举。这样就实现了Master的动态选举。
分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。其分为排他锁和共享锁两种。
排他锁
排他锁(Exclusive Locks,简称X锁),又称为写锁或独占锁。如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能在对这个数据对象进行任何类型的操作(不能再对该对象加锁),直到T1释放了排他锁。可以看出,排他锁的核心是如何保证当前只有一个事务获得锁,并且锁被释放后,所有正在等待获取锁的事务都能够被通知到。
如何利用ZooKeeper实现排他锁?
定义锁
ZooKeeper上的一个ZNode可以表示一个锁;例如/exclusive_lock/lock节点就可以被定义为一个锁。
获得锁
如上所说,把ZooKeeper上的一个ZNode看作是一个锁,获得锁就通过创建ZNode的方式来实现。所有客户端都去/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。ZooKeeper会保证在所有客户端中,最终只有一个客户端能够创建成功,那么就可以认为该客户端获得了锁。同时,所有没有获取到锁的客户端就需要到/exclusive_lock节点上注册一个子节点变更的Watcher监听,以便实时监听到lock节点的变更情况。
释放锁
因为/exclusive_lock/lock是一个临时节点,因此在以下两种情况下,都有可能释放锁。
当前获得锁的客户端机器发生宕机或重启,那么该临时节点就会被删除,释放锁。
正常执行完业务逻辑后,客户端就会主动将自己创建的临时节点删除,释放锁。
无论在什么情况下移除了lock节点,ZooKeeper都会通知所有在/exclusive_lock节点上注册了节点变更Watcher监听的客户端。这些客户端在接收到通知后,再次重新发起分布式锁获取,即重复『获取锁』过程。
共享锁
共享锁(Shared Locks,简称S锁),又称为读锁。如果事务T1对数据对象O1加上了共享锁,那么T1只能对O1进行读操作,其他事务也能同时对O1加共享锁(不能是排他锁),直到O1上的所有共享锁都释放后O1才能被加排他锁。
总结:可以多个事务同时获得一个对象的共享锁(同时读),有共享锁就不能再加排他锁(因为排他锁是写锁)
在大型分布式系统中的应用
前面已经介绍了ZooKeeper的典型应用场景。本节将以常见的大数据产品Hadoop和HBase为例来介绍ZooKeeper在其中的应用,帮助大家更好地理解其分布式应用场景。
ZooKeeper在Hadoop中的应用
在Hadoop中的ZooKeeper主要用于实现HA(High Availability),包括HDFS的NamaNode和YARN的ResourceManager的HA。同时在YARN中还用来存储应用的运行状态。HDFS的NamaNode和YARN的ResourceManager利用ZooKeepr实现HA的原理是一样的,所以在此以YARN为例来介绍。
YARN架构体系
从上图可以看出,YARN主要由ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)和Container四部分组成。其中最核心的就是ResourceManager。
ResourceManager负责集群中所有资源的统一管理和分配,同时接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(Application Manager),其内部维护了各个应用程序的ApplicationMaster信息、NodeManager信息以及资源使用信息等。为了实现HA,必须有多个ResourceManager并存(一般就两个),并且只有一个ResourceManager处于Active状态,其他的则处于Standby状态,当Active节点无法正常工作(如机器宕机或重启)时,处于Standby的就会通过竞争选举产生新的Active节点。
主备切换
下面就来看看YARN是如何实现多个ResourceManager之间的主备切换的。
创建锁节点
在ZooKeeper上会有一个/yarn-leader-election/appcluster-yarn的锁节点,所有的ResourceManager在启动的时候,都会去竞争写一个Lock子节点:/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb,该节点是临时节点。ZooKeepr能够为我们保证最终只有一个ResourceManager能够创建成功。创建成功的那个ResourceManager就切换为Active状态,没有成功的那些ResourceManager则切换为Standby状态。
[zk: localhost:2181(CONNECTED) 16] get /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb
appcluster-yarnrm2
cZxid = 0x1b00133dc0
ctime = Tue Jan 03 15:44:42 CST 2017
mZxid = 0x1f00000540
mtime = Sat Jan 07 00:50:20 CST 2017
pZxid = 0x1b00133dc0
cversion = 0
dataVersion = 28
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0
可以看到此时集群中ResourceManager2为Active。
注册Watcher监听
所有Standby状态的ResourceManager都会向/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点注册一个节点变更的Watcher监听,利用临时节点的特性,能够快速感知到Active状态的ResourceManager的运行情况。
主备切换
当Active状态的ResourceManager出现诸如宕机或重启的异常情况时,其在ZooKeeper上连接的客户端会话就会失效,因此/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点就会被删除。此时其余各个Standby状态的ResourceManager就都会接收到来自ZooKeeper服务端的Watcher事件通知,然后会重复进行步骤1的操作。
以上就是利用ZooKeeper来实现ResourceManager的主备切换的过程,实现了ResourceManager的HA。HDFS中NameNode的HA的实现原理跟YARN中ResourceManager的HA的实现原理相同。其锁节点为/hadoop-ha/mycluster/ActiveBreadCrumb。
ResourceManager状态存储
在 ResourceManager 中,RMStateStore 能够存储一些 RM 的内部状态信息,包括 Application 以及它们的 Attempts 信息、Delegation Token 及 Version Information 等。需要注意的是,RMStateStore 中的绝大多数状态信息都是不需要持久化存储的,因为很容易从上下文信息中将其重构出来,如资源的使用情况。在存储的设计方案中,提供了三种可能的实现,分别如下:基于内存实现,一般是用于日常开发测试;基于文件系统的实现,如HDFS;基于ZooKeeper实现。
由于这些状态信息的数据量都不是很大,因此Hadoop官方建议基于ZooKeeper来实现状态信息的存储。在ZooKeepr上,ResourceManager 的状态信息都被存储在/rmstore这个根节点下面。
[zk: localhost:2181(CONNECTED) 28] ls /rmstore/ZKRMStateRoot
[RMAppRoot, AMRMTokenSecretManagerRoot, EpochNode, RMDTSecretManagerRoot, RMVersionNode]
RMAppRoot 节点下存储的是与各个 Application 相关的信息,RMDTSecretManagerRoot 存储的是与安全相关的 Token 等信息。每个 Active 状态的 ResourceManager 在初始化阶段都会从 ZooKeeper 上读取到这些状态信息,并根据这些状态信息继续进行相应的处理。
小结:
ZooKeepr在Hadoop中的应用主要有:
HDFS中NameNode的HA和YARN中ResourceManager的HA。
存储RMStateStore状态信息
ZooKeeper在HBase中的应用
HBase主要用ZooKeeper来实现HMaster选举与主备切换、系统容错、RootRegion管理、Region状态管理和分布式SplitWAL任务管理等。HMaster选举与主备切换的原理和HDFS中NameNode及YARN中ResourceManager的HA原理相同。
系统容错
当HBase启动时,每个RegionServer都会到ZooKeeper的/hbase/rs节点下创建一个信息节点(下文中,我们称该节点为”rs状态节点”),例如/hbase/rs/[Hostname],同时,HMaster会对这个节点注册监听。当某个 RegionServer 挂掉的时候,ZooKeeper会因为在一段时间内无法接受其心跳(即 Session 失效),而删除掉该 RegionServer 服务器对应的 rs 状态节点。与此同时,HMaster 则会接收到 ZooKeeper 的 NodeDelete 通知,从而感知到某个节点断开,并立即开始容错工作。
HBase为什么不直接让HMaster来负责RegionServer的监控呢?如果HMaster直接通过心跳机制等来管理RegionServer的状态,随着集群越来越大,HMaster的管理负担会越来越重,另外它自身也有挂掉的可能,因此数据还需要持久化。在此情况下,ZooKeeper就成了理想的选择。
RootRegion管理
对应HBase集群来说,数据存储的位置信息是记录在元数据region,也就是RootRegion上的。每次客户端发起新的请求,需要知道数据的位置,就会去查询RootRegion,而RootRegion自身位置则是记录在ZooKeeper上的(默认情况下,是记录在ZooKeeper的/hbase/meta-region-server节点中)。当RootRegion发生变化,比如Region的手工移动、重新负载均衡或RootRegion所在服务器发生了故障等是,就能够通过ZooKeeper来感知到这一变化并做出一系列相应的容灾措施,从而保证客户端总是能够拿到正确的RootRegion信息。
Region管理
HBase里的Region会经常发生变更,这些变更的原因来自于系统故障、负载均衡、配置修改、Region分裂与合并等。一旦Region发生移动,它就会经历下线(offline)和重新上线(online)的过程。在下线期间数据是不能被访问的,并且Region的这个状态变化必须让全局知晓,否则可能会出现事务性的异常。对于大的HBase集群来说,Region的数量可能会多达十万级别,甚至更多,这样规模的Region状态管理交给ZooKeeper来做也是一个很好的选择。
分布式SplitWAL任务管理
当某台RegionServer服务器挂掉时,由于总有一部分新写入的数据还没有持久化到HFile中,因此在迁移该RegionServer的服务时,一个重要的工作就是从WAL中恢复这部分还在内存中的数据,而这部分工作最关键的一步就是SplitWAL,即HMaster需要遍历该RegionServer服务器的WAL,并按Region切分成小块移动到新的地址下,并进行日志的回放(replay)。
由于单个RegionServer的日志量相对庞大(可能有上千个Region,上GB的日志),而用户又往往希望系统能够快速完成日志的恢复工作。因此一个可行的方案是将这个处理WAL的任务分给多台RegionServer服务器来共同处理,而这就又需要一个持久化组件来辅助HMaster完成任务的分配。当前的做法是,HMaster会在ZooKeeper上创建一个SplitWAL节点(默认情况下,是/hbase/SplitWAL节点),将“哪个RegionServer处理哪个Region”这样的信息以列表的形式存放到该节点上,然后由各个RegionServer服务器自行到该节点上去领取任务并在任务执行成功或失败后再更新该节点的信息,以通知HMaster继续进行后面的步骤。ZooKeeper在这里担负起了分布式集群中相互通知和信息持久化的角色。
小结:
以上就是一些HBase中依赖ZooKeeper完成分布式协调功能的典型场景。但事实上,HBase对ZooKeepr的依赖还不止这些,比如HMaster还依赖ZooKeeper来完成Table的enable/disable状态记录,以及HBase中几乎所有的元数据存储都是放在其上的。由于ZooKeeper出色的分布式协调能力及良好的通知机制,HBase在各版本的演进过程中越来越多地增加了ZooKeeper的应用场景,从趋势上来看两者的交集越来越多。HBase中所有对ZooKeeper的操作都封装在了org.apache.hadoop.hbase.zookeeper这个包中,感兴趣的同学可以自行研究。
获取ZooKeeper的运行状态
方式一:Tcp服务端口获取
get zookeeper(cluster) status
echo status | nc localhost 2181
该zk的模式
echo stat | nc localhost 2181
...
Mode: leader
...
Mode: follower
如果加了对应的访问控制规则,可能会报:
stat is not executed because it is not in the whitelist.
可在其控制脚本中使用指令来获取部分运行信息
>./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /freeoa/apache-zookeeper-3.8.2-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
更多的信息还要靠指令
echo mntr | nc localhost 2181
The output of which is:
zk_version 3.4.8--1, built on 02/06/2016 03:18 GMT
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 7
zk_packets_sent 6
zk_num_alive_connections 2
zk_outstanding_requests 0
zk_server_state follower
zk_znode_count 357
zk_watch_count 0
zk_ephemerals_count 5
zk_approximate_data_size 846524
zk_open_file_descriptor_count 36
zk_max_file_descriptor_count 4096
If the node is a leader, you will also see:
zk_followers 5
zk_synced_followers 5
zk_pending_syncs 0
The following will not be present on Windows platforms:
zk_open_file_descriptor_count 43
zk_max_file_descriptor_count 4096
综合使用以上信息,可以确定Zookeeper集群的健康状况。
方式二:从HTTP辅助服务获取信息
curl -s http://localhost:8080/commands/envi
{
"zookeeper.version" : "3.8.2-139d619b58292d7734b4fc83a0f44be4e7b0c986, built on 2023-07-05 19:24 UTC",
"host.name" : "zk1.freeoa.net",
"java.version" : "1.8.0_202",
"java.vendor" : "Oracle Corporation",
"java.home" : "/usr/java/jdk1.8.0_202-amd64/jre",
"java.class.path" : "ALL-Jar-Libs",
"java.library.path" : "/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib",
"java.io.tmpdir" : "/tmp",
"java.compiler" : "<NA>",
"os.name" : "Linux",
"os.arch" : "amd64",
"os.version" : "3.10.0-957.el7.x86_64",
"user.name" : "root",
"user.home" : "/root",
"user.dir" : "/freeoa/apache-zookeeper-3.8.2-bin/bin",
"os.memory.free" : "369MB",
"os.memory.max" : "889MB",
"os.memory.total" : "468MB",
"command" : "environment",
"error" : null
}
可参考官方参考文档:zookeeperAdmin.html#sc_adminserver
XXXX is not executed because it is not in the whitelist
这些其实是4字命令(4lw.commands),可在配置文件(推荐)或启动脚本中开启。
1.配置文件(zoo.cfg)
4lw.commands.whitelist=*
保存后重启zookeeper即可。
2.启动脚本(bin/zkServer.sh)
在启动脚本里添加vm环境变量-Dzookeeper.4lw.commands.whitelist=*,便可以把所有指令添加到白名单,在脚本的这个位置:
if [ "x$JMXHOSTNAME" = "x" ]
then
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=$JMXPORT -Dcom.sun.management.jmxremote.authenticate=$JMXAUTH -Dcom.sun.management.jmxremote.ssl=$JMXSSL -Dzookeeper.jmx.log4j.disable=$JMXLOG4J org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
else
echo "JMX disabled by user request" >&2
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
#如果不想在此添加,注意位置和赋值的顺序
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
然后重启就可以了。
手册页中有相关的说明。https://zookeeper.apache.org/doc/r3.8.0/zookeeperAdmin.html
4lw.commands.whitelist : (Java system property: zookeeper.4lw.commands.whitelist) New in 3.5.3: A list of comma separated Four Letter Words commands that user wants to use. A valid Four Letter Words command must be put in this list else ZooKeeper server will not enable the command. By default the whitelist only contains "srvr" command which zkServer.sh uses. The rest of four-letter word commands are disabled by default: attempting to use them will gain a response ".... is not executed because it is not in the whitelist." Here's an example of the configuration that enables stat, ruok, conf, and isro command while disabling the rest of Four Letter Words command:
4lw.commands.whitelist=stat, ruok, conf, isro
If you really need enable all four-letter word commands by default, you can use the asterisk option so you don't have to include every command one by one in the list. As an example, this will enable all four-letter word commands:
4lw.commands.whitelist=*
srvr指令是默认就开启的,无需显式配置开启
echo srvr | nc localhost 2181
Zookeeper version: 3.8.2-139d619b58292d7734b4fc83a0f44be4e7b0c986, built on 2023-07-05 19:24 UTC
Latency min/avg/max: 0/2.8076/22800
Received: 76556
Sent: 76860
Connections: 2
Outstanding: 0
Zxid: 0x3000017ae
Mode: follower
Node count: 1800
wchc查看监听路径信息,更多的4字指令可参考文档:zookeeperAdmin.html#sc_4lw。
ZooKeeper升级参考
对配置文件(conf/zoo.cfg)的备份是必须的,程序采用备份老的程序并部署新版本的代码或直接覆盖。
关闭原来的zk服务
./zkServer.sh stop
启用新的zk服务
./zkServer.sh start
验证:
./zkCli.sh -server {服务器IP}:2181
未授权访问控制:
#ZooKeeper设置ACL权限控制
#ZK的节点有5种操作权限:CREATE、READ、WRITE、DELETE、ADMIN
#也就是增、删、改、查、管理权限,这5种权限简写为crwda(即:每个单词的首字符缩写)
#注:这5种权限中,delete是指对子节点的删除权限,其它4种权限指对自身节点的操作权限。
#身份的认证有4种方式:
#world:默认方式,相当于全世界都能访问
#auth:代表已经认证通过的用户(cli中可以通过addauth digest user:pwd 来添加当前上下文中的授权用户)
#digest:即用户名:密码这种方式认证,这也是业务系统中最常用的
#ip:使用Ip地址认证
#设置访问控制:ls / 根目录下的节点和根目录本身
#方式一:(推荐)
1.增加一个认证用户:addauth digest 用户名:密码明文
#eg. addauth digest user1:password1
addauth digest zk:Passw0rd
2.设置权限:setAcl /path auth:用户名:密码明文:权限
#eg. setAcl /test auth:user1:password1:cdrwa
setAcl /inf-confserver auth:zk:Passw0rd:cdrwa
setAcl /zookeeper auth:zk:Passw0rd:cdrwa
setAcl / auth:zk:Passw0rd:cdrwa
3.查看Acl设置
#getAcl /path
#方式二:
#setAcl /path digest:用户名:密码密文:权限
#注:这里的加密规则是SHA1加密,然后base64编码
#删除权限
#找到zookeeper的日志地址,把日志删除或者 delete /节点
#linux环境下也可以使用此命令查询日志地址:
echo conf | nc 127.0.0.1 2181
在zookeeperTools中有bin目录的控制脚本的说明。