LVS 使用过程中的问题集
 一、Socket连接消耗过度导致服务终止
一、Socket连接消耗过度导致服务终止二、调整timestamp解决TIME_WAIT过多问题
一、Socket连接消耗过度导致服务终止
遇到一个socket连接No buffer space available的问题,导致接口大面积用户http请求失败的问题,重启服务器后又恢复了正常。基本可以把问题锁定在:系统并发过大,连接数过多,部分socket连接无法释放关闭,而持续请求又导致无法释放的socket连接不断积压,最终导致No buffer space available问题而服务中止。
虽然重启服务器能最快的将socket连接释放,但是问题很容易复现,很明显这不是问题的根本解决方式。通过netstat -an,发现存在大量处于TIME_WAIT状态的TCP连接,也就是之前提到的未释放的socket连接,并且server端口在不断变化。
现在来分析解决这个问题。
TIME_WAIT状态的由来
我们知道TCP关闭连接需要经过四次握手,为什么是四次握手,而不是像建立连接那样三次握手,看看下面三次握手和四次握手的流程图。
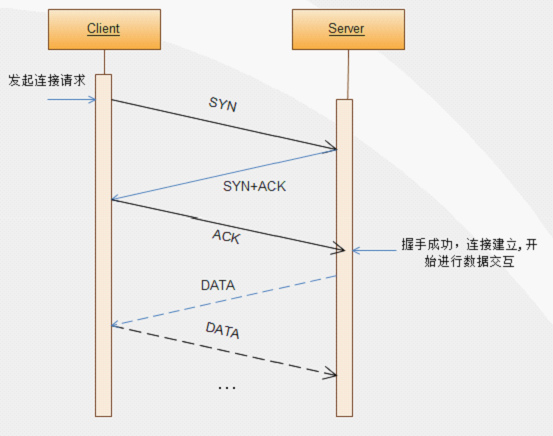
三次握手建立连接示意图
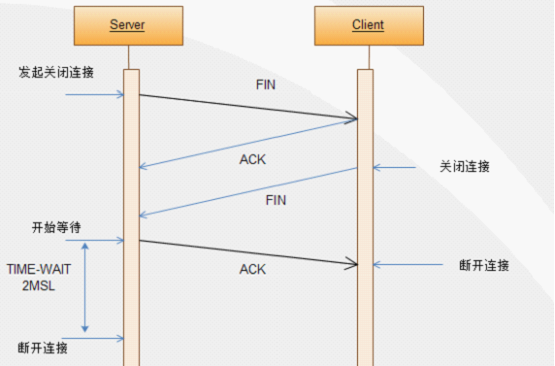
四次握手关闭连接示意图
从上面的三次握手建立连接示意图中可以知道,只要client端和server端都接收到了对方发送的ACK应答之后,双方就可以建立连接,之后就可以进行数据交互了,这个过程需要三步。
而四次握手关闭连接示意图中,TCP协议中,关闭TCP连接的是Server端(当然,关闭都可以由任意一方发起),当Server端发起关闭连接请求时,向Client端发送一个FIN报文,Client端收到FIN报文时,很可能还有数据需要发送,所以并不会立即关闭SOCKET,所以先回复一个ACK报文,告诉Server端,“你发的FIN报文我收到了”。当Client端的所有报文都发送完毕之后,Client端向Server端发送一个FIN报文,此时Client端进入关闭状态,不在发送数据。
Server端收到FIN报文后,就知道可以关闭连接了,但是网络是不可靠的,Client端并不知道Server端要关闭,所以Server端发送ACK后进入TIME_WAIT状态,如果Client端没有收到ACK则Server段可以重新发送。Client端收到ACK后,就知道可以断开连接了。Server端等待了2MSL(Max Segment Lifetime,最大报文生存时间)后依然没有收到回复,则证明Client端已正常断开,此时Server端也可以断开连接了。2MSL的TIME_WAIT等待时间就是由此而来。
知道了TIME_WAIT的由来,TIME_WAIT 状态最大保持时间是2*MSL,在1-4分钟之间,所以当系统并发过大,Client-Server连接数过多,Server端会在1-4分钟之内积累大量处于TIME_WAIT状态的无法释放的socket连接,导致服务器效率急剧下降,甚至耗完服务器的所有资源,最终导致No buffer space available (maximum connections reached): connect问题的发生。
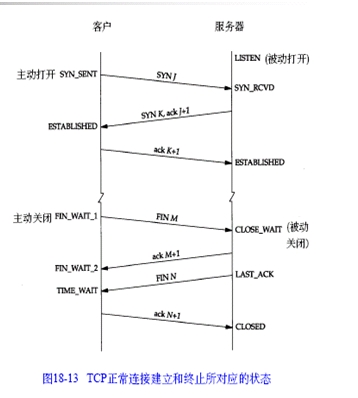
建立连接-三次握手
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据,以上称为三次握手。
关闭连接-四次握手
连接双方任何一方调用close()后,连接的两个传输方向都关闭,不能再发送数据了。如果一方调用shutdown()则连接处于半关闭状态,仍可接收对方发来的数据。
如果出现半关闭,例如客户->服务器方向关闭。则服务器还可以发,客户端还可以收。协议规定主动关闭一方,进入FIN_WAIT_2->TIME_WAIT,必须等待2MSL(MSL为最大报文段生存时间,LWIP为1分钟,windows为2分钟)时间然后才进入CLOSED,删除TCP控制块。在2MSL等待时间内迟到的报文段将被抛弃。
如果我们在客户端关闭一个连接然后又立刻建立连接(使用同一端口号),2MSL时间内之前连接的端口号不能使用,即使调用bind函数也将返回-1(绑定失败),内核将自动分配一个新的端口号使用。通常情况下这个我们并不关心,因为客户端的端口号我们并不关心,只要能用就可以。但是如果是服务器就不一样了,服务器的端口一般是固定的,客户端必须知道服务器的端口号才能建立连接,所以如果服务器端主动断开连接时,就需要注意,或者做一些处理:不让它等待2MSL后才可以使用,具体做法:使能SO_REUSEPORT(允许重用本地地址),可以通过调用setsockopt函数来使能。
2MSL等待的原因:报文段有生存时间,当连接关闭时,有可能收到迟到的报文段。这时若立马就建立新的连接(同一端口),那么新的连接就会接收迟到的报文,误以为是发给自己的。另一个原因是可靠的实现全双工连接的终止。
在FIN_WAIT_2状态我们已经发出了FIN,并且另一端也已对它进行确认。除非我们在实行半关闭,否则将等待另一端的应用层意识到它已收到一个文件结束符说明,并向我们发一个FIN来关闭另一方向的连接。只有当另一端的进程完成这个关闭,我们这端才会从FIN_WAIT_2状态进入TIME_WAIT状态。这意味着我们这端可能永远保持这个状态(FIN_WAIT_2,如果对方不发送FIN包)。另一端也将处于CLOSE_WAIT状态,并一直保持这个状态直到应用层决定进行关闭(调用close然后进入LAST_ACK)。
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭 。
TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送。
服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
服务器关闭客户端的连接,发送一个FIN给客户端。
客户端发回ACK报文确认,并将确认序号设置为收到序号加1。
TIME_WAIT状态也成为2MSL等待状态,每个TCP实现必须选择一个报文段最大生存时间MSL(Maximum Segment Lifetime)。它是任何报文段被丢弃前在网络内的最长时间。RFC中之处MSL为2分钟,然后现实中常用值是30秒,1分钟或者2分钟。
对于一个具体实现所给定的MSL值,处理原则是:当TCP执行一个主动关闭,并发回最后一个ACK,该链接必须在TIME_WAIT状态停留的时间为2倍的MSL。这样可让TCP再次发送最后的ACK以防止这个ACK丢失。
这种2MSL等待的另一个结果就是这个TCP连接在2MSL等待时间,这个连接的socket不能再被使用,只能在2MSL结束之后才能再被使用。在连接处于2MSL等待时,任何迟到的报文段将被丢弃,因为处于2MSL等待的,有该插口对(socket pair)定义的链接在这段时间内不能再被使用。
TCP为什么有三次握手(建立连接)和四次挥手(关闭连接)
原因有二:
一、保证TCP协议的全双工连接能够可靠关闭
二、保证这次连接的重复数据段从网络中消失
先说第一点,如果Client直接CLOSED了,那么由于IP协议的不可靠性或者是其它网络原因,导致Server没有收到Client最后回复的ACK。那么Server就会在超时之后继续发送FIN,此时由于Client已经CLOSED了,就找不到与重发的FIN对应的连接,最后Server就会收到RST而不是ACK,Server就会以为是连接错误把问题报告给高层。这样的情况虽然不会造成数据丢失,但是却导致TCP协议不符合可靠连接的要求。所以,Client不是直接进入CLOSED,而是要保持TIME_WAIT,当再次收到FIN的时候,能够保证对方收到ACK,最后正确的关闭连接。
再说第二点,如果Client直接CLOSED,然后又再向Server发起一个新连接,我们不能保证这个新连接与刚关闭的连接的端口号是不同的。也就是说有可能新连接和老连接的端口号是相同的。一般来说不会发生什么问题,但是还是有特殊情况出现:假设新连接和已经关闭的老连接端口号是一样的,如果前一次连接的某些数据仍然滞留在网络中,这些延迟数据在建立新连接之后才到达Server,由于新连接和老连接的端口号是一样的,又因为TCP协议判断不同连接的依据是socket pair,于是,TCP协议就认为那个延迟的数据是属于新连接的,这样就和真正的新连接的数据包发生混淆了。所以TCP连接还要在TIME_WAIT状态等待2倍MSL,这样可以保证本次连接的所有数据都从网络中消失。
端口变化由来
对于大型的应用,访问量较高,一台Server往往不能满足服务需求,这时就需要多台Server共同对外提供服务。如何充分、最大的利用多台Server的资源处理请求,这时就需要请求调度,将请求合理均匀的分配到各台Server。
什么是2MSL
MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为tcp报文(segment)是ip数据报(datagram)的数据部分,具体称谓请参见《数据在网络各层中的称呼》一文,而ip头中有一个TTL域,TTL是time to live的缩写,中文可以译为“生存时间”,这个生存时间是由源主机设置初始值但不是存的具体时间,而是存储了一个ip数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减1,当此值为0则数据报将被丢弃,同时发送ICMP报文通知源主机。RFC 793中规定MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟等。
2MSL即两倍的MSL,TCP的TIME_WAIT状态也称为2MSL等待状态,当TCP的一端发起主动关闭,在发出最后一个ACK包后,即第3次握手完成后发送了第四次握手的ACK包后就进入了TIME_WAIT状态,必须在此状态上停留两倍的MSL时间,等待2MSL时间主要目的是怕最后一个ACK包对方没收到,那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的FIN包后可以再发一个ACK应答包。在TIME_WAIT状态时两端的端口不能使用,要等到2MSL时间结束才可继续使用。当连接处于2MSL等待阶段时任何迟到的报文段都将被丢弃。不过在实际应用中可以通过设置SO_REUSEADDR选项达到不必等待2MSL时间结束再使用此端口。
TTL与MSL是有关系的但不是简单的相等的关系,MSL要大于等于TTL。
最大报文长度
当建立一个连接时,每一方都有用于通告它期望接收的MSS选项(MSS只能出现在SYN报文段中)。如果一方不接收来自另一方的MSS值,则MSS就定为默认的536字节。
一般来说,如果没有分段发生,MSS还是越大越好。报文段越大允许每个报文段传送的数据就越多,相对IP和TCP首部有更高的网络利用率。当TCP发送一个SYN时,或者因为一个本地应用进程想发起一个连接,或者是因为另一端的主机收到了一个连接请求,它能将MSS值设置为外出口的MTU长度减去IP首部和TCP首部,对于一个以太网,MSS值可达到1460字节。
为什么TCP的TIME_WAIT状态要保持2MSL
TIME_WAIT状态也称为2MSL等待状态。每个具体TCP实现必须选择一个报文段最大生存时间MSL(Maximum Segment Lifetime),它是任何报文段被丢弃前在网络内的最长时间。我们知道这个时间是有限的,因为TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生存时间的TTL字段。
RFC 793 [Postel 1981c] 指出MSL为2分钟。然而,实现中的常用值是30秒,1分钟,或2分钟。
在实际应用中,对IP数据报TTL的限制是基于跳数,而不是定时器。
对一个具体实现所给定的MSL值,处理的原则是:当TCP执行一个主动关闭,并发回最后一个ACK,该连接必须在TIMEWAIT状态停留的时间为2倍的MSL。
这样可让TCP再次发送最后的ACK以防这个ACK丢失(另一端超时并重发最后的FIN)。这种2MSL等待的另一个结果是这个TCP连接在2MSL等待期间,定义这个连接的插口(客户的IP地址和端口号,服务器的IP地址和端口号)不能再被使用。这个连接只能在2MSL结束后才能再被使用。
遗憾的是,大多数TCP实现(如伯克利版)强加了更为严格的限制。在2MSL等待期间,插口中使用的本地端口在默认情况下不能再被使用。某些实现和API提供了一种避开这个限制的方法。使用插口API时,可说明其中的SOREUSEADDR选项,它将让调用者对处于2MSL等待的本地端口进行赋值。但我们将看到TCP原则上仍将避免使用仍处于2MSL连接中的端口。
在连接处于2MSL等待时,任何迟到的报文段将被丢弃。因为处于2MSL等待的、由该插口对(socket pair)定义的连接在这段时间内不能被再用,因此当要建立一个有效的连接时,来自该连接的一个较早替身(incarnation)的迟到报文段作为新连接的一部分不可能不被曲解(一个连接由一个插口对来定义。一个连接的新的实例(instance)称为该连接的替身)。
LVS (Linux Virtual Server)集群(Cluster)技术就是实现这一需求的方式之一。采用IP负载均衡技术和基于内容请求分发技术,调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。
LVS集群采用三层结构,其主要组成部分为:
l 负载均衡调度器(load balancer),它是整个集群对外面的前端机,负责将客户的请求发送到一组服务器上执行,而客户认为服务是来自一个IP地址(我们可称之为虚拟IP地址)上的。
l 服务器池(server pool),是一组真正执行客户请求的服务器,执行的服务有WEB、MAIL、FTP和DNS等。
l 共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,提供相同的服务。
其结构如下图所示:
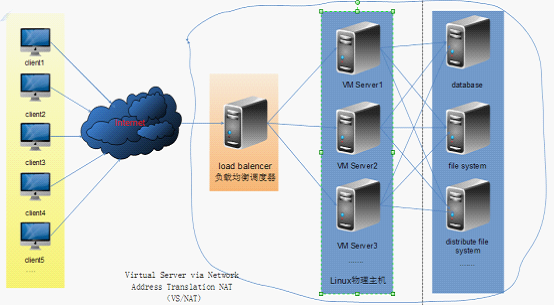
LVS结构示意图
从LVS结构示意图中可以看出,Load Balancer到后端Server的IP的数据包的 源IP地址都是一样(Load Balancer的IP地址和Server 的IP地址属于同一网段),而客户端认为服务是来自一个IP地址(实际上就是Load Balancer的IP),频繁的TCP连接建立和关闭,使得Load Balancer到后端Server的TCP连接会受到限制,导致在server上留下很多处于TIME_WAIT状态的连接,而且这些状态对应的远程IP地址都是Load Balancer的。Load Balancer的端口最多也就60000多个(2^16=65536,1~1023是保留端口,还有一些其他端口缺省也不会用),每个Load Balancer上的端口一旦进入 Server的TIME_WAIT黑名单,就有240秒不能再用来建立和Server的连接,这样Load Balancer和Server的连接就很有限。所以我们看到了使用netstat -an命令查看网络连接状况时同一个 remote IP会有很多端口。
可行的解决办法
从上面的分析来看,导致出现No buffer space available这一问题的原因是多方面的,原因以及解决办法如下:
从webservice或httpclient调用未进行连接释放,导致资源无法回收。
从系统层面上看,系统socket连接数设置不合理,socket连接数过小,易达到上限;其次是2MSL设置过长,容易积压TIME_WAIT状态的TCP连接。
解决办法是修改Linux内核参数
修改系统socket最大连接数,在文件/etc/security/limits.conf最后加入下面两行:
* soft nofile 32768
* hard nofile 32768
或者缩小2MSL的时长、允许重用处于TIME_WAIT状态的TCP连接、快速回收处于TIME_WAIT状态的TCP连接,修改/etc/sysctl.conf,添加如下几行:
#改系統默认的TIMEOUT时间
net.ipv4.tcp_fin_timeout=2
#启重用,允许将TIME_WAIT sockets重新用于新的TCP连接 默认为0表示关闭
net.ipv4.tcp_tw_reuse=1
#开启TCP连接中TIME_WAIT sockets的快速回收 默认为0 表示关闭
net.ipv4.tcp_tw_recycle=1
上面这些参数根据实际情况进行配置,下面给一个在实际情况下的较为优化的配置:
# 是否开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭。
net.ipv4.tcp_tw_reuse = 1
# 是否开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_tw_recycle = 1
# 修改tcp会话进去fin状态后的等待时间,超时则关闭会话,默认为2分钟。
net.ipv4.tcp_fin_timeout = 30
# 处于TIME_WAIT最大的socket数量,默认为180 000,超过此数目的socket立即被清除。
net.ipv4.tcp_max_tw_buckets=20000
# tcp缓存时间戳,在RFC1323中有描述,系统缓存每个ip最新的时间戳,后续请求中该ip的tcp包中的时间戳如果小于缓存的时间戳(即非最新的数据包),即视为无效,相应的数据包会被丢弃,而且是无声的丢弃。在默认情况下,此机制不会有问题,但在nat模式时,不同的ip被转换成同一个ip再去请求真正的server端,在server端看来,源ip都是相同的,且此时包的时间戳顺序可能不一定保持递增,由此会出现丢包的现象;因此,如果主机是位于Nat模式之后(没有直接配置公网IP就在nat模式下),建议关闭此选项。
net.ipv4.tcp_timestamps = 0
从LVS 层面上看,调度算法不合理,导致请求过多分配到某一台服务器上。
解决办法:根据实际情况指定合理的负载均衡解决方案。
-----------------------------------------
再来复习一下tcp连接的过程吧
TCP 提供面向连接、可靠的字节流服务,面向连接意味着两个使用TCP的应用在彼此交换数据前先建立一个TCP连接。
TCP通过下列方式提供可靠性:
1.应用数据被分割成TCP认为最合适发送的数据块(一般情况下,TCP的包不会超过1500,因为TCP会在三次握手时候协商最大传输单元)
2.当TCP发送一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。(发一个包,等待确认,如果不对这个包进行确认,会在一定时间内进行重发)
3.当TCP收到发自TCP连接另一端的数据,它将发送一个确认,这个确认不是立即发送,通常将推迟几分之一秒。(收到包之后,不会立即确认,会等待几分之一秒之后)
4.TCP将保持它首部和数据的校验和(计算校验和时需要加入伪首部进行验证校验和)
5.既然TCP报文段作为IP数据报来传输,而IP数据报的到达可能会失序,因此TCP报文段的到达也可能会失序。如果必要,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层。
6.既然IP数据报发生重复,TCP的接收端必须丢弃重复的数据。
7.TCP还能提供流量控制,TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据,这将防止较快主机致使较慢主机的缓冲区溢出(缓存溢出或者缓存不够,会通知发起方,发起方就不会再继续发送)。
每个TCP段都包含源端口和目的端口号,用于寻找发端和接受端应用进程。这两个值加上IP首部中的源IP地址和目的IP地址唯一确定一个TCP连接。一个IP地址和一个端口号也成为一个插口(socket),插口对(socketpair)(包含客户IP地址、客户端口号、服务器IP地址和服务器端口号的四元组)可唯一确定互联网络中每个TCP连接的双方。
序号用来标识从TCP发送端向TCP发送端发送的数据字节流,它标识在这个报文段中的第一个数字字节。如果将字节流看做在两个应用程序间的单向流动,则TCP用序号对每个字节进行计数。序号是32bit的无符号数,序号到达23^2-1后从0开始。SYN标志消耗了一个序号,算一个字节,同样FIN也算一个字节,其他ACK,RST均不算。
确认序号应当是上次已经成功收到数据字节序号加1.只有ACK标志为1时确认序号字段才有效。
发送ACK无需任何代价,因为32bit的确认序号字段和ACK标志一样,总是TCP首部的一部分。因此,我们看到一旦一个连接建立起来,这个字段总是被设置,ACK标志也总是被设置为1。
TCP为应用层提供全双工服务。这意味数据能在两个方向上独立地进行传输。因此,连接的每一端必须保持每个方向上的传输数据序号。
TCP首部最多有60字节的首部,没有任何选项字段,正常长度都是20字节。
TCP的流量控制由连接的每一端通过声明的窗口大小来提供。窗口大小为字节数,起始于确认序号字段指明的值,这个值是接收端正期望接收的字节。窗口大小是一个16bit字段,因而窗口大小最大为65535字节。
检验和覆盖整个的TCP报文段:TCP首部和TCP数据。这是一个强制性的字段,一定是由发起段计算和存储,并有接收端进行验证。TCP检验和的计算和UDP的计算相似。
只有当URG标志置为1时紧急指针才有效。紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。TCP的紧急方式是发送端向另一端发送紧急数据的一种方式。
最常见的可选字段是最长报文大小,又称为MSS(Maximum SegmentSize)。每个链接方通常都在通信的第一个报文段(为建立连接而设置SYN标志的那个段)中指明这个选项。它表明本端所能接收最大长度的报文段。
TCP报文段的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有TCP首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超市的许多情况中,也会发送不带任何数据的报文段。
二、调整timestamp解决TIME_WAIT过多问题
现象
第一个现象:机器A通过NAT网关访问服务S成功,而机器B通过NAT网关访问服务S经常性出现connect失败,抓包发现:服务S端已经收到了syn包,但没有回复synack;另外机器A关闭了tcp timestamp,而机器B开启了tcp timestamp;
第二个现象:不同主机上的应用C(开启timestamp),通过NAT网关(同一个出口ip)访问同一服务S,主机C1 connect成功,而主机C2 connect失败;
查看一下当前的网络连接情况,结果发现TIME_WAIT数非常大:
shell> ss -ant | awk ' {++s[$1]} END {for(k in s) print k,s[k]}'
重复了几次测试,结果每次出问题的时候,TIME_WAIT都等于28233,实际原因很简单,它取决于一个内核参数net.ipv4.ip_local_port_range:
shell> sysctl -a | grep port
net.ipv4.ip_local_port_range = 32768 61000
因为端口范围是一个闭区间,所以实际可用的端口数量是:
61000-32768+1
28233
问题分析到这里基本就清晰了,解决方向也明确了,要从系统方面来阐述如何解决问题,无非就是以下两个方面:
首先是增加本地可用端口数量,可以用以下命令来实现:
shell> sysctl net.ipv4.ip_local_port_range="10240 61000"
其次是减少TIME_WAIT连接状态。网络上已经有不少相关的介绍,大多是建议:
shell> sysctl net.ipv4.tcp_tw_reuse=1
shell> sysctl net.ipv4.tcp_tw_recycle=1
注:通过sysctl命令修改内核参数,重启后会还原,要想持久化可以参考前面的方法。
这两个选项在降低TIME_WAIT数量方面可以说是立竿见影,不过如果你觉得问题已经完美搞定那就错了,实际上这样可能会引入一个更复杂的网络故障。关于内核参数的详细介绍,可以参考官方文档。这里简要说明一下tcp_tw_recycle参数。它用来快速回收TIME_WAIT连接,不过如果在NAT环境下会引发问题。
RFC1323中有如下一段描述:
An additional mechanism could be added to the TCP, a per-host cache of the last timestamp received from any connection. This value could then be used in the PAWS mechanism to reject old duplicate segments from earlier incarnations of the connection, if the timestamp clock can be guaranteed to have ticked at least once since the old connection was open. This would require that the TIME-WAIT delay plus the RTT together must be at least one tick of the sender’s timestamp clock. Such an extension is not part of the proposal of this RFC.
大概意思是说TCP有一种行为,可以缓存每个主机最新的时间戳,后续请求中如果时间戳小于缓存的时间戳,即视为无效,相应的数据包会被丢弃,而且是无声的丢弃。
Linux是否启用这种行为取决于tcp_timestamps和tcp_tw_recycle,因为tcp_timestamps缺省就是开启的,所以当tcp_tw_recycle被开启后,实际上这种行为就被激活了,当客户端或服务端以NAT方式构建的时候就可能出现问题,下面以客户端NAT为例来说明:
当多个客户端通过NAT方式联网并与服务端交互时,服务端看到的是同一个IP,也就是说对服务端而言这些客户端实际上等同于一个,可惜由于这些客户端的时间戳可能存在差异,于是乎从服务端的视角看,便可能出现时间戳错乱的现象,进而直接导致时间戳小的数据包被丢弃。如果发生了此类问题,具体的表现通常是是客户端明明发送的SYN,但服务端就是不响应ACK,我们可以通过下面命令来确认数据包不断被丢弃的现象:
shell> netstat -s | grep timestamp
timestamp request: 224
timestamp replies: 224
924995 packets rejects in established connections because of timestamp
安全起见,通常要禁止tcp_tw_recycle。说到这里,大家可能会想到另一种解决方案:把tcp_timestamps设置为0,tcp_tw_recycle设置为1,这样不就可以鱼与熊掌兼得了么?可惜一旦关闭了tcp_timestamps,那么即便打开了tcp_tw_recycle,也没有效果。
好在我们还有另一个内核参数tcp_max_tw_buckets(一般缺省是180000)可用:
shell> sysctl net.ipv4.tcp_max_tw_buckets=100000
通过设置它,系统会将多余的TIME_WAIT删除掉,此时系统日志里可能会显示:「TCP: time wait bucket table overflow」,不过除非不得已,否则不要轻易使用。
在 LVS下, 对于后端RealServer来说,他看到的请求报文IP地址都是公网的客户端IP,而不是Load Balancer的。比如LVS-TUN模式就是将客户端的ip包重新用IPIP协议打包后,转发到RealServer,RealServer解包后处理后,就可以直接将回复返回给公网的客户端(此时RealServer和LoadBalancer会共享同一个公网IP,因此可以直接回包),实际上就LVS相当于将客户端与Load Balancer之间的TCP链接迁移到了LB选择的RealServer 。具体可以参考:http://www.linuxvirtualserver.org/zh/lvs3.html
如果是使用nginx这种应用层负载均衡的话,后端的处理server看到的报文的请求IP就是Nginx本身的IP。
限于实际的网络情况,很多用户的客户端没有公网IP,只能依赖于NAT分享同一个公网IP,这样由于同一NAT下的不同机器的时间戳不一定保证同步,所以就导致同一个NAT过来的数据包的时间戳不能保证单调递增。这样就打破了RFC1323中PAWS方法依赖于对端时间戳单调递增的要求。所以就表现为时间戳错乱,导致丢弃时间戳较小的数据包,表现为packets rejects in established connections because of timestamp的数据不断增加。所以在LVS中的机器需要关闭tcp_tw_recycle。
根据现象上述问题明显和tcp timestmap有关;查看linux 2.6.32内核源码,发现tcp_tw_recycle/tcp_timestamps都开启的条件下,60s(timewai时间)内同一源ip主机的socket connect请求中的timestamp必须是递增的。
源码函数:tcp_v4_conn_request(),该函数是tcp层三次握手syn包的处理函数(服务端);
源码片段:
if (tmp_opt.saw_tstamp &&
tcp_death_row.sysctl_tw_recycle &&
(dst = inet_csk_route_req(sk, req)) != NULL &&
(peer = rt_get_peer((struct rtable *)dst)) != NULL &&
peer->v4daddr == saddr) {
if (get_seconds() < peer->tcp_ts_stamp + TCP_PAWS_MSL &&
(s32)(peer->tcp_ts - req->ts_recent) > TCP_PAWS_WINDOW) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED);
goto drop_and_release;
}
}
tmp_opt.saw_tstamp:该socket支持tcp_timestamp
sysctl_tw_recycle:本机系统开启tcp_tw_recycle选项
TCP_PAWS_MSL:60s,该条件判断表示该源ip的上次tcp通讯发生在60s内
TCP_PAWS_WINDOW:1,该条件判断表示该源ip的上次tcp通讯的timestamp 大于 本次tcp
分析:主机client1和client2通过NAT网关(1个ip地址)访问serverN,由于timestamp时间为系统启动到当前的时间,因此client1和client2的timestamp不相同;根据上述syn包处理源码,在tcp_tw_recycle和tcp_timestamps同时开启的条件下,timestamp大的主机访问serverN成功,而timestmap小的主机访问失败。
参数:
/proc/sys/net/ipv4/tcp_timestamps - 控制timestamp选项开启/关闭
/proc/sys/net/ipv4/tcp_tw_recycle - 减少timewait socket释放的超时时间
验证
server端当tcp_tw_recycle和tcp_timestamps都是1的时候,会检查收到数据包TCP选项字段中的的timestamp(TS Value),当来自同一个IP地址(任意源端口号)后来的数据包中TCP选项字段如果有timestamp且比前面的数据包中的timestamp小,则server不做ACK响应。
建议解决方法:
1.服务器端不要将tcp_tw_recycle字段和tcp_timestamps字段同时设为1
2.客户端把tcp_timestamps字段设0,这样不会发送TCP选项字段中的timestamps选项,对于服务提供方1较适合
个人建议关闭tcp_tw_recycle选项,而不是timestamp;因为 在tcp timestamp关闭的条件下,开启tcp_tw_recycle是不起作用的;而tcp timestamp可以独立开启并起作用。timestamp和tw_recycle同时开启的条件下,timewait状态socket释放的超时时间和rto相关;否则超时时间为TCP_TIMEWAIT_LEN,即60s;
内核说明文档 对该参数的介绍如下:
tcp_tw_recycle - BOOLEAN
Enable fast recycling TIME-WAIT sockets. Default value is 0.It should not be changed without advice/request of technical experts.
下面这三个参数一起解释:
tcp_tw_recycle
tcp_tw_reuse
tcp_timestamps
其中 tcp_tw_recycle/tcp_tw_reuse 这两个官方的建议保持默认为0,而 tcp_timestamps 这个参数在特定的情况开启会引起很严重的问题。基本的情况就是,你的客户或者你的服务器在一个 NAT 后面,如果开启这个参数,会导致服务器能收到三次握手的 SYN 但是不会返回任何的 SYN+ACK,其结果是客户无法访问你的网站。可以通过 tcpdump 或者下面的这个查看:
shell> netstat -s | grep timestamp
tcp_timestamps 是 tcp 协议中的一个扩展项,通过时间戳的方式来检测过来的包以防止 PAWS(Protect Against Wrapped Sequence numbers),可以提高 tcp 的性能,2.6 的内核默认是打开的。只要 client/server/nat/loadbalancer 不同时打开该选项就不会出现上面的问题。与之相关的包括 tcp_tw_recycle,如果 tcp_timestamps 和 tcp_tw_recycle 同时开启,就会开启时间戳选项,导致上面的问题。如果有上述的网络结构,比较合理的方式是禁用 tcp_tw_recyle 而开启 tcp_timestamps。禁用了 tcp_tw_recycle 其 TIME_OUT sockets 回收功能就没了,可以配合 tcp_tw_reuse 让 TIME_WAIT 降下来。
关于RFC1323
这是一篇介绍针对High-bandwidth, Long delay链路设计的一些TCP扩展选项的资料。强烈推荐阅读!但这篇RFC其实已经被RFC7323所取代,不过RFC1323对于了解timestamp相关的基本概念来说还是足够了的。
tcp_timestamps 的设计
tcp_timestamps 的本质是记录数据包的发送时间。基本的步骤如下:
1. 发送方在发送数据时,将一个timestamp(表示发送时间)放在包里面
2. 接收方在收到数据包后,在对应的ACK包中将收到的timestamp返回给发送方(echo back)
3. 发送发收到ACK包后,用当前时刻now - ACK包中的timestamp就能得到准确的RTT
当然实际运用中要考虑到RTT的波动,因此有了后续的(Round-Trip Time Measurement)RTTM机制,TCP Timestamps Option (TSopt)具体设计如下:
Kind: 8 // 标记唯一的选项类型,比如window scale是3
Length: 10 bytes // 标记Timestamps选项的字节数
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| Kind=8 | Length=10 | TS Value (TSval) | TS ECho Reply (TSecr) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
1 1 4 4
timestamps一个双向的选项,当一方不开启时,两方都将停用timestamps。
比如client端发送的SYN包中带有timestamp选项,但server端并没有开启该选项。
则回复的SYN-ACK将不带timestamp选项,同时client后续回复的ACK也不会带有timestamp选项。
当然,如果client发送的SYN包中就不带timestamp,双向都将停用timestamp。
为什么需要timestamp
如果没有timestamp,RTT的计算会怎样?
1. TCP层在发送出一个SKB时,使用skb->when记录发送出去的时间
2. TCP层在收到SKB数据包的确认时,使用now - skb->when来计算RTT
但上面的机制在丢包发生时会有问题,比如
1. TCP层第一次发送SKB的时间是send_time1, TCP层重传一个数据包的时间是send_time2
2. 当TCP层收到SKB的确认包的时间是recv_time
但是RTT应该是 (recv_time - send_time1)呢,还是(recv_time - send_time2)呢?
以上两种方式都不可取!因为无法判断出recv_time对应的ACK是确认第一次数据包的发送还是确认重传数据包。因此TCP协议栈只能选择非重传数据包进行RTT采样。但是当出现严重丢包(比如整个窗口全部丢失)时,就完全没有数据包可以用于RTT采样。这样后续计算SRTT和RTO就会出现较大的偏差。
timestamp选项很好的解决了上述问题,因为ACK包里面带的TSecr值,一定是触发这个ACK的数据包在发送端发送的时间。不管数据包是否重传都能准确的计算RTT(前提是TSecr遵循RTTM中的计算原则)。
当然timestamp不仅解决了RTT计算的问题,还很好的为PAWS机制提供的信息依据。
开启timestamp会有什么负面影响?
这部分内容以后会根据更多的实际经验来补充。目前列举一些找到的分析。
1. 10字节的TCP header开销
2. The TCP Timestamp when enabled will allow you to guess the uptime of a target system (nmap v -O . Knowing how long a system has been up will enable you to determine whether security patches that require reboot has been applied or not.
什么是RTTM
RTTM规定了一些使用TSecr计算RTT的原则,具体如下:
1. A TSecr value received in a segment is used to update the averaged RTT measurement only if the segment acknowledges some new data
2. The data-sender TCP must measure the effective RTT, including the additional time due to delayed ACKs. Thus, when delayed ACKs are in use, the receiver should reply with the TSval field from the earliest
3. An ACK for an out-of-order segment should therefore contain the timestamp from the most recent segment that advanced the window
4. The timestamp from the latest segment (which filled the hole) must be echoed
在ACK被重传的数据时,应该使用重传数据包中的TSval进行回复
什么是PAWS
PAWS — Protect Againest Wrapped Sequence numbers
目的是解决在高带宽下,TCP序号可能被重复使用而带来的问题。
PAWS同样依赖于timestamp,并且假设在一个TCP流中,按序收到的所有TCP包的timestamp值都是线性递增的。而在正常情况下,每条TCP流按序发送的数据包所带的timestamp值也确实是线性增加的。
timestamp为TCP/IP协议栈提供了两个功能:
1. 更加准确的RTT测量数据,尤其是有丢包时 -- RTTM
2. 保证了在极端情况下,TCP的可靠性 -- PAWS
再发一个因开启tcp_timestamps导致主机通但服务端口不通的实例
发现内网机器 ping 某个hostname(公网ip)能通,而使用 curl 测试不通,telnet 80端口也不通。内网其它机器却可以,因使用的是keepalived+nginx的方式,访问服务与vip同在机器就是不行。通过网关上分析,那些不能打开或间歇性的不能打开的机器上的nat连接中它们是最多的。
curl -vv 180.100.200.190
* About to connect() to 180.100.200.190 port 80 (#0)
* Trying 180.100.200.190... Connection timed out
* couldn't connect to host
* Closing connection #0
telnet 180.100.200.190 80
Trying 180.100.200.190...
telnet: connect to address 180.100.200.190: Connection timed out
原来是 net.ipv4.tcp_timestamps 设置了为 1 ,即启用时间戳。
more /proc/sys/net/ipv4/tcp_timestamps
将其关闭
修改 /etc/sysctl.conf 中
net.ipv4.tcp_timestamps = 0
执行'sysctl -p'立即生效。
问题出在了 tcp 三次握手,ping icmp ok ,http ssh mysql 都不行(但内网其它机器却可以),可初步定位问题出在tcp连接层上。
经过nat之后,如果前面相同的端口被使用过,且时间戳大于这个链接发出的syn中的时间戳,服务器上就会忽略掉这个syn,不返会syn-ack消息,表现为用户无法正常完成tcp3次握手,从而不能打开页面。在服务器空闲时,如果用户nat的端口没有被使用过时,就可以正常打开;业务繁忙时,nat端口重复使用的频率高,很难分到没有被使用的端口,从而产生此类问题。
另外只有客户端和服务端都开启时间戳的情况下,才会出现能ping通但不能建立tcp三次握手的情况。
而rp_filter这一内核参数也可能导致丢包这一问题,来看一下官方关于该参数的解释:
rp_filter - INTEGER
0 - No source validation.
1 - Strict mode as defined in RFC3704 Strict Reverse Path Each incoming packet is tested against the FIB and if the interface is not the best reverse path the packet check will fail. By default failed packets are discarded.
2 - Loose mode as defined in RFC3704 Loose Reverse Path Each incoming packet's source address is also tested against the FIB and if the source address is not reachable via any interface the packet check will fail.
Current recommended practice in RFC3704 is to enable strict mode to prevent IP spoofing from DDos attacks. If using asymmetric routing or other complicated routing, then loose mode is recommended.
The max value from conf/{all,interface}/rp_filter is used when doing source validation on the {interface}.
Default value is 0. Note that some distributions enable it in startup scripts.
简述一下:
0:表示不开启源检测
1:严格模式,根据数据包的源,通过查FIB表(Forward Information Table,可以理解为路由表),检查数据包进入端口是同时也是出端口,以视为最佳路径,如果不符合最佳路径,则丢弃数据包。
2:松散模式,检查数据包的来源,查FIB表,如果通过任意端口都无法到达此源,则丢包。
结合使用场景来说:
在LVS(nat)的工作场景下,LVS Server送往Real Server的包可能走的tunnel接口,而Real Server通过tunnel接口收到包后,查路由表发现回包要走物理eth/bond之类接口,如果rp_filter开启了严格模式,会导致网络异常状况。
centos7默认开启了rp_filter,因此建议关闭此功能。
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.YOUR-INTERFACE.rp_filter = 0
因误设ip_local_port_range导致的'Cannot assign requested address'
"Failed to connect to IP: Cannot assign requested address"
执行Perl脚本时的报错
Could not connect to Redis server at 172.18.10.19:9997: Cannot assign requested address at script/freeoa.pl line 253.
发现主机是可以ping通的,难道是端口不通?安装一个telnet测试一下呢
Downloading packages:
telnet-0.17-65.el7_8.x86_64.rp FAILED
http://172.18.10.17:81/updates/Packages/telnet-0.17-65.el7_8.x86_64.rpm: [Errno 14] curl#7 - "Failed to connect to 172.18.10.17: Cannot assign requested address"]
Trying other mirror.
是连接数不够了,但从监控中看才几十个连接。很可能是调整了系统层级的什么网络连接参数导致的,查一下呢
# sysctl -a|grep port
...
net.ipv4.ip_local_port_range = 65000 65000
net.ipv4.ip_local_reserved_ports =
...
sunrpc.max_resvport = 1023
sunrpc.min_resvport = 665
原来是有人不小心写错了ip_local_port_range的范围值
如果是连接数量太多或类CC攻击,导致TIME_WAIT数量非常之大,可以适当地调整如下的几个参数(上文有所涉及,在此重提):
//Open for indication SYN Cookies. When there is a SYN Waiting for the queue to overflow , Enable cookies To deal with it ,
//Preventable small amount SYN attack , The default is 0, Means closing ;
net.ipv4.tcp_syncookies = 1
//Represents open reuse . Allows you to TIME-WAIT sockets Reapply to new TCP Connect , The default is 0, Means closing ;
net.ipv4.tcp_tw_reuse = 1
//Open for indication TCP Connecting TIME-WAIT sockets Rapid recycling of , The default is 0, Means closing .
net.ipv4.tcp_tw_recycle = 1
//The modification is the default TIMEOUT Time , The default is 60s
net.ipv4.tcp_fin_timeout = 30
//Indicates the range of ports used for outbound connections . Set to 1024 To 65535.
net.ipv4.ip_local_port_range = 1024 65535
参考来源
TCP timestamp
部分网络内核参数说明
该文章最后由 阿炯 于 2022-05-01 17:16:16 更新,目前是第 2 版。