kafka使用入门
 kafka实现了生产者和消费者之间的无缝连接。kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速、可扩展、可持久化的特点。它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/spark流式处理引擎。Kafka由LinkedIn于2011年创建,并在Confluent的支持下得到了广泛的传播。Confluent已向开源社区发布了许多新功能和附加组件,例如用于模式演化的Schema Registry,用于从其他数据源轻松流式传输的Kafka Connect等。数据库到Kafka,Kafka Streams进行分布式流处理,可使用KSQL对Kafka主题执行类似SQL的查询等等。
kafka实现了生产者和消费者之间的无缝连接。kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速、可扩展、可持久化的特点。它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/spark流式处理引擎。Kafka由LinkedIn于2011年创建,并在Confluent的支持下得到了广泛的传播。Confluent已向开源社区发布了许多新功能和附加组件,例如用于模式演化的Schema Registry,用于从其他数据源轻松流式传输的Kafka Connect等。数据库到Kafka,Kafka Streams进行分布式流处理,可使用KSQL对Kafka主题执行类似SQL的查询等等。名词解释
producer:生产者。
consumer:消费者。
topic:消息以topic为类别记录,Kafka将消息种子(Feed)分门别类,每一类的消息称之为一个主题(Topic)。
broker:以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker;消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
每个消息(也叫作record记录,也被称为消息)是由一个key,一个value和时间戳构成。
基本原理
通常来讲,消息模型可以分为两种:队列和发布-订阅式。队列的处理方式是一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组(consumer group)。消费者用一个消费者组名标记自己。
一个发布在Topic上消息被分发给此消费者组中的一个消费者。假如所有的消费者都在一个组中,那么这就变成了queue模型。假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。更通用的, 我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者,一个组内多个消费者可以用来扩展性能和容错。
并且,kafka能够保证生产者发送到一个特定的Topic的分区上,消息将会按照它们发送的顺序依次加入,也就是说,如果一个消息M1和M2使用相同的producer发送,M1先发送,那么M1将比M2的offset低,并且优先的出现在日志中。消费者收到的消息也是此顺序。如果一个Topic配置了复制因子(replication facto)为N,那么可以允许N-1服务器宕机而不丢失任何已经提交(committed)的消息。此特性说明kafka有比传统的消息系统更强的顺序保证。但是,相同的消费者组中不能有比分区更多的消费者,否则多出的消费者一直处于空等待,不会收到消息。
应用场景
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和storm。
设计思想
Consumergroup:各个consumer可以组成一个组,每个消息只能被组中的一个consumer消费,如果一个消息可以被多个consumer消费的话,那么这些consumer必须在不同的组。
消息状态:在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
消息持久化:Kafka中会把消息持久化到本地文件系统中,并且保持极高的效率。
消息有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
push-and-pull : Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
Kafka集群中broker之间的关系:不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
负载均衡方面: Kafka提供了一个 metadata API来管理broker之间的负载(对Kafka0.8.x而言,对于0.7.x主要靠zookeeper来实现负载均衡)。
同步异步:Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。
分区机制partition:Kafka的broker端支持消息分区,Producer可以决定把消息发到哪个分区,在一个分区中消息的顺序就是Producer发送消息的顺序,一个主题中可以有多个分区,具体分区的数量是可配置的。分区的意义很重大,后面的内容会逐渐体现。
离线数据装载:Kafka由于对可拓展的数据持久化的支持,它也非常适合向Hadoop或者数据仓库中进行数据装载。
插件支持:现在不少活跃的社区已经开发出不少插件来拓展Kafka的功能,如用来配合Storm、Hadoop、flume相关的插件。
四个核心的API
1.ProducerAPI:允许一个应用向一个或多个topic里发布记录流;
2.ConsumerAPI:允许一个应用订阅一个或多个topics,处理topic里的数据流,就相当于消费;
3.StreamAPI:允许应用扮演流处理的作用,从一个或多个topic里消费数据流,然后产生输出流数据到其他一个或多个topic里,对输入流数据有效传输到输出口;
4.ConnectorAPI:允许运行和构建一个可重复利用的生产者和消费者,能将kafka的topic与其他存在的应用和数据库设备相连接,比如链接一个实时数据库,可以捕捉到每张表的变化。
基本机制
消息传输流程
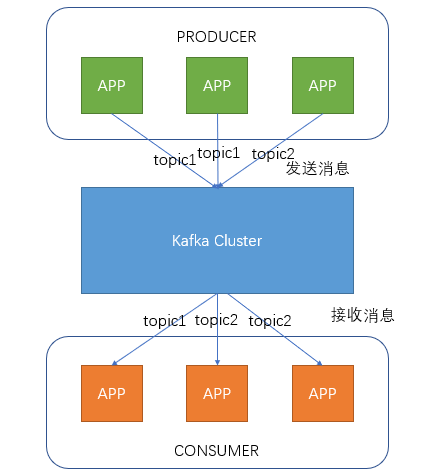
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
从上图中就可以看出同一个Topic下的消费者和生产者的数量并不是对应的。
kafka服务器消息存储策略
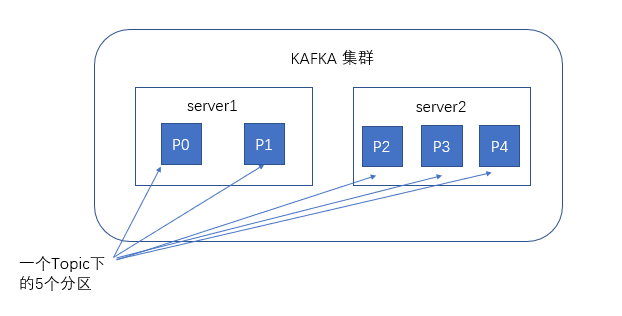
谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
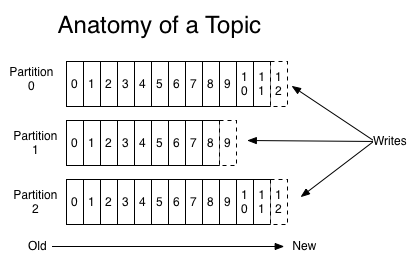
在每个分区中,消息以顺序存储,最晚接收的的消息会最后被消费。
与生产者的交互
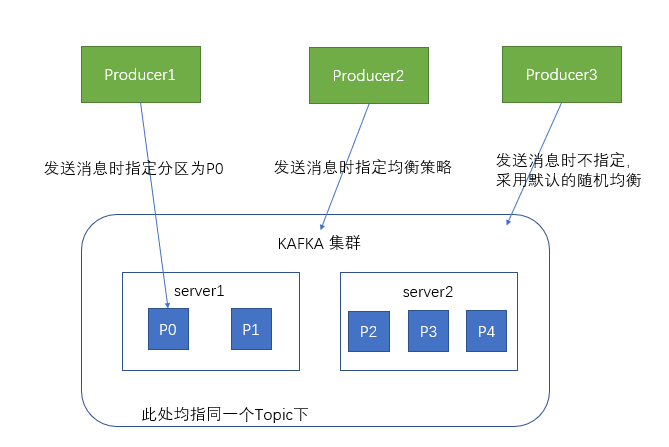
生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中
也可以通过指定均衡策略来将消息发送到不同的分区中
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
与消费者的交互
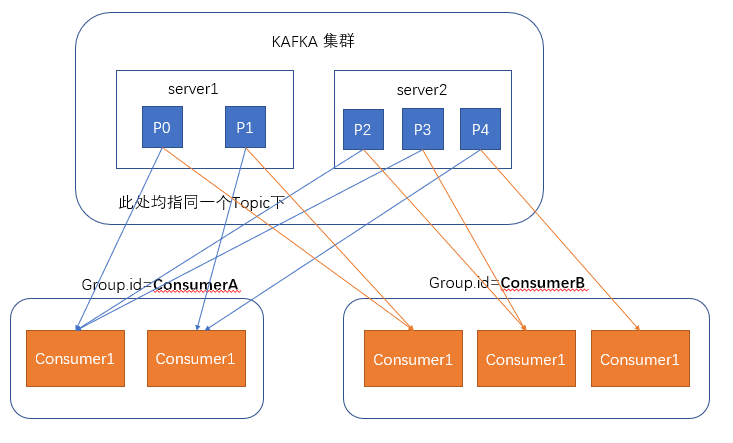
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不相同,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
基本交互原理
每个Topic被创建后,在zookeeper上存放有其metadata,包含其分区信息、replica信息、LogAndOffset等。默认路径/brokers/topics/<topic_id>/partitions/<partition_index>/state
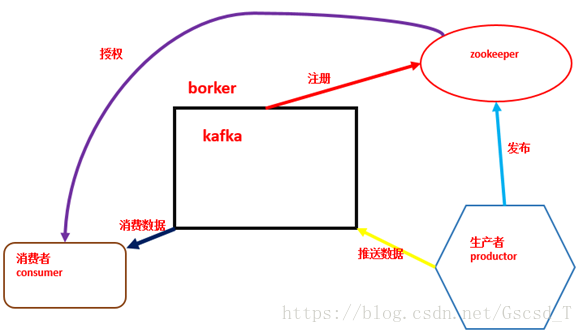
Producer可以通过zookeeper获得topic的broker信息,从而得知需要往哪写数据。
Consumer也从zookeeper上获得该信息,从而得知要监听哪个partition。
基本组件
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
topic:消息存放的目录即主题
Producer:生产消息到topic的一方
Consumer:订阅topic消费消息的一方
Broker:Kafka的服务实例就是一个broker
Kafka Topic&Partition
消息发送时都被发送到一个topic,其本质就是一个目录,而topic由是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:
我们可以看到,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。Kafka集群会保存所有的消息,不管消息有没有被消费;我们可以设定消息的过期时间,只有过期的数据才会被自动清除以释放磁盘空间。如果设置消息过期时间为2天,那么这2天内的所有消息都会被保存到集群中,数据只有超过了两天才会被清除。
Kafka需要维持的元数据只有一个–消费消息在Partition中的offset值,Consumer每消费一个消息,offset就会加1。其实消息的状态完全是由Consumer控制的,Consumer可以跟踪和重设这个offset值,这样的话Consumer就可以读取任意位置的消息。
把消息日志以Partition的形式存放有多重考虑,第一,方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;第二就是可以提高并发,因为可以以Partition为单位读写了。
主题和日志(Topic和Log)
每一个分区(partition)都是一个顺序的、不可变的消息队列,并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。Kafka集群保持所有的消息,直到它们过期,无论消息是否被消费了。实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。可以看到这种设计对消费者来说操作自如,一个消费者的操作不会影响其它消费者对此log的处理。再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元。
分布式(Distribution)
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。根据配置每个分区还可以复制到其它服务器作为备份容错。每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。一台服务器可能同时是一个分区的leader,另一个分区的follower。这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
核心组件
1).Replications、Partitions 和Leaders
通过上面介绍的我们可以知道,kafka中的数据是持久化的并且能够容错的。Kafka允许用户为每个topic设置副本数量,副本数量决定了有几个broker来存放写入的数据。如果你的副本数量设置为3,那么一份数据就会被存放在3台不同的机器上,那么就允许有2个机器失败。一般推荐副本数量至少为2,这样就可以保证增减、重启机器时不会影响到数据消费。如果对数据持久化有更高的要求,可以把副本数量设置为3或者更多。
Kafka中的topic是以partition的形式存放的,每一个topic都可以设置它的partition数量,Partition的数量决定了组成topic的log的数量。Producer在生产数据时,会按照一定规则(这个规则是可以自定义的)把消息发布到topic的各个partition中。上面将的副本都是以partition为单位的,不过只有一个partition的副本会被选举成leader作为读写用。
关于如何设置partition值需要考虑的因素。一个partition只能被一个消费者消费(一个消费者可以同时消费多个partition),因此,如果设置的partition的数量小于consumer的数量,就会有消费者消费不到数据。所以,推荐partition的数量一定要大于同时运行的consumer的数量。另外一方面,建议partition的数量大于集群broker的数量,这样leader partition就可以均匀的分布在各个broker中,最终使得集群负载均衡。在Cloudera,每个topic都有上百个partition。需要注意的是,kafka需要为每个partition分配一些内存来缓存消息数据,如果partition数量越大,就要为kafka分配更大的heap space。
2). Producers
Producers直接发送消息到broker上的leader partition,不需要经过任何中介一系列的路由转发。为了实现这个特性,kafka集群中的每个broker都可以响应producer的请求,并返回topic的一些元信息,这些元信息包括哪些机器是存活的,topic的leader partition都在哪,现阶段哪些leader partition是可以直接被访问的。
Producer客户端自己控制着消息被推送到哪些partition。实现的方式可以是随机分配、实现一类随机负载均衡算法,或者指定一些分区算法。Kafka提供了接口供用户实现自定义的分区,用户可以为每个消息指定一个partitionKey,通过这个key来实现一些hash分区算法。比如,把userid作为partitionkey的话,相同userid的消息将会被推送到同一个分区。
以Batch的方式推送数据可以极大的提高处理效率,kafka Producer 可以将消息在内存中累计到一定数量后作为一个batch发送请求。Batch的数量大小可以通过Producer的参数控制,参数值可以设置为累计的消息的数量(如500条)、累计的时间间隔(如100ms)或者累计的数据大小(64KB)。通过增加batch的大小,可以减少网络请求和磁盘IO的次数,当然具体参数设置需要在效率和时效性方面做一个权衡。
Producers可以异步的并行的向kafka发送消息,但是通常producer在发送完消息之后会得到一个future响应,返回的是offset值或者发送过程中遇到的错误。这其中有个非常重要的参数"acks",这个参数决定了producer要求leader partition 收到确认的副本个数,如果acks设置数量为0,表示producer不会等待broker的响应,所以producer无法知道消息是否发送成功,这样有可能会导致数据丢失,但同时,acks值为0会得到最大的系统吞吐量。
若acks设置为1,表示producer会在leader partition收到消息时得到broker的一个确认,这样会有更好的可靠性,因为客户端会等待直到broker确认收到消息。若设置为-1,producer会在所有备份的partition收到消息时得到broker的确认,这个设置可以得到最高的可靠性保证。
Kafka 消息有一个定长的header和变长的字节数组组成。因为kafka消息支持字节数组,也就使得kafka可以支持任何用户自定义的序列号格式或者其它已有的格式如Apache Avro、protobuf等。Kafka没有限定单个消息的大小,但我们推荐消息大小不要超过1MB,通常一般消息大小都在1~10kB之前。
3).Consumers
Kafka提供了两套consumer api:high-level api和sample-api。
Sample-api 是一个底层的API,它维持了一个和单一broker的连接,并且这个API是完全无状态的,每次请求都需要指定offset值,因此这套API也是最灵活的。
在kafka中,当前读到消息的offset值是由consumer来维护的,因此,consumer可以自己决定如何读取kafka中的数据。比如consumer可以通过重设offset值来重新消费已消费过的数据。不管有没有被消费,kafka会保存数据一段时间,这个时间周期是可配置的,只有到了过期时间,kafka才会删除这些数据。
High-level API封装了对集群中一系列broker的访问,可以透明的消费一个topic。它自己维持了已消费消息的状态,即每次消费的都是下一个消息。
High-level API还支持以组的形式消费topic,如果consumers有同一个组名,那么kafka就相当于一个队列消息服务,而各个consumer均衡的消费相应partition中的数据。若consumers有不同的组名,那么此时kafka就相当与一个广播服务,会把topic中的所有消息广播到每个consumer。
Kafka快速,易于安装,非常受欢迎,可用于广泛的范围或用例。 从开发人员的角度来看,尽管Apache Kafka一直很友好,但在操作上却有些糟。因此让我们回顾一下Kafka的一些痛点。
Kafka的问题
扩展Kafka十分棘手,这是由于代理还存储数据的耦合体系结构所致。 剥离另一个代理意味着它必须复制主题分区和副本,这非常耗时。
没有与租户完全隔离的本地多租户。
存储可能会变得非常昂贵,尽管可以长时间存储数据,但是由于成本问题,很少使用它。
万一副本不同步,有可能丢失消息。
必须提前计划和计算代理,主题,分区和副本的数量(以适应计划的未来使用量增长),以避免扩展问题,这非常困难。
如果仅需要消息传递系统,则使用偏移量可能会很复杂。
集群重新平衡会影响相连的生产者和消费者的性能。
MirrorMaker Geo复制机制存在问题。像Uber这样的公司已经创建了自己的解决方案来克服这些问题。
如上所见,大多数问题与操作方面有关;尽管安装起来相对容易,但Kafka难以管理和调整。而且它还没有像它可能的那样灵活和有弹性。
基本CLI操作
1. 创建Topic
bin/kafka-create-topic.sh --zookeeper zkserv:2181 --replica 2 --partition 3 --topic test
2. 查看Topic信息
bin/kafka-list-topic.sh --topic test --zookeeper 10.1.110.24:2181
3. 增加Partition
bin/kafka-add-partitions.sh --partition 4 --topic test --zookeeper 10.1.110.24:2181
更多命令参见这里。
创建一个Producer
Kafka提供了java api,Producer特别的简单。更具体的参见这里。
创建一个Consumer
Kafka提供了两种java的Consumer API:High Level Consumer和Simple Consumer。
具体例子就不写了,参见
High Level Consumer
Simple Consumer
kafka 安装与使用
kafka 选择 Binary downloads 下载。kafka依赖java环境,需要提前安装好jdk,使用自己安装的zookeeper(也可以使用kafka自带的zk)。
目录简介
bin:启动、停止等脚本命令
config:配置文件
libs:依赖的类库
主要的配置文件
server.propeties
broker.id=0 # broker唯一标识,依次累加
delete.topic.enable=true
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://IP:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=logs # 存放日志和消息的目录
num.partitions=1 # 主题默认的分区数
num.recovery.threads.per.data.dir=1
log.retention.hours=168 # 日志的过期时间,超过会被删除
log.segment.bytes=1073741824 # 日志文件的最大体积,超过会新建
log.retention.check.interval.ms=300000
zookeeper.connect=ip0:2181,ip1:2181,ip2:2181 # zk的连接配置
zookeeper.connection.timeout.ms=6000
consumer.properties
zookeeper.connect=192.168.0.10:2181,192.168.0.11:2181,192.168.0.12:2181
zookeeper.connection.timeout.ms=6000
producer.properties
bootstrap.servers=192.168.0.10:9092,192.168.0.11:9092,192.168.0.12:9092
compression.type=none
启动(需要先启动zk)
bin/kafka-server-start.sh -daemon config/server.properties
备注:如果使用kafka自带的zk,zk的配置文件为zookeeper.properties,启动脚本为bin/zookeeper-server-start.sh。
按如下顺序启动
启动Zookeeper server(如果你使用kafka内置的zk的话)
bin/zookeeper-server-start.sh config/zookeeper.properties &
启动Kafka server
bin/kafka-server-start.sh config/server.properties
#更好的启动放入后台
bin/kafka-server-start.sh -daemon config/server.properties
停止
按如下顺序来停止
停止Kafka server
bin/kafka-server-stop.sh
然后是Zookeeper server(内置的)
bin/zookeeper-server-stop.sh
查看主题及相关信息
查看所有的主题
kafka-topics.sh --zookeeper zk_host:port --list
查看主题描述
kafka-topics.sh --zookeeper zk_host:port --describe --topic my_topic_freeoa
查看消费者
kafka-consumer-groups.sh --new-consumer --bootstrap-server kfk_host:port --list
通过ZooKeeper进行查询
kafka-consumer-groups.sh --zookeeper zk_host:port --list
查看消费者信息和offset lag
kafka-consumer-groups.sh --new-consumer --bootstrap-server kfk_host:port --group test_group --describe
通过ZooKeeper进行查询
kafka-consumer-groups.sh --zookeeper zk_host:port --group test-group --describe
重新分配主题分区个数
每个主题默认一个分区:num.partitions=1
将主题my_topic_freeoa分区扩展到3个
kafka-topics.sh --zookeeper zk_host:port --alter --topic my_topic_freeoa --partitions 3
测试一
1.producer
bin/kafka-console-producer.sh --broker-list kfkserv:9092 --topic test
2.consumer
bin/kafka-console-consumer.sh --zookeeper zkserv:2181 --topic test --from-beginning
以上 需要2个shell窗口,在producer 端输入字符串并回车,在consumer端就会显示刚输入的数据。
创建删除查看topic
1.创建
方法一:自动创建
bin/kafka-console-producer.sh --broker-list kfkserv:9092 --topic test
方法二:
创建一个拥有3个副本,1个分区的topic
bin/kafka-topics.sh --create --zookeeper zkserv:2181 --replication-factor 3 --partitions 1 --topic freeoa
2.删除
bin/kafka-topics.sh --delete --zookeeper zkserv:2181 --topic test
删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关topic目录删除zookeeper "/brokers/topics/"目录下相关topic节点,这个默认的设定有点麻烦,后方有对应的解决之道。
3.查看统计
bin/kafka-topics.sh --describe --zookeeper zkserv:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
leader:负责处理消息的读和写,leader是从所有节点中随机选择的
replicas:列出了所有的副本节点,不管节点是否在服务中
isr:是正在服务中的节点
测试二
创建一个名为"test"的Topic,只有一个分区和备份(2181是zookeeper的默认端口)
bin/kafka-topics.sh --create --zookeeper zkserv:2181 --config max.message.bytes=12800000 --config flush.messages=1 --replication-factor 1 --partitions 1 --topic test
命令解析:
--create:指定创建topic动作
--topic:指定新建topic的名称
--zookeeper:指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
--config:指定当前topic上有效的参数值,参数列表参考文档为: http://kafka.apache.org/082/documentation.html#brokerconfigs
--partitions:指定当前创建的kafka分区数量,默认为1个
--replication-factor:指定每个分区的复制因子个数,默认1个
创建好之后,可以通过运行以下命令,查看已创建的topic信息:
bin/kafka-topics.sh --list --zookeeper zkserv:2181
test
或者除了手工创建topic外,你也可以配置你的broker,当发布一个不存在的topic时自动创建topic。
查看对应topic的描述信息
bin/kafka-topics.sh --describe --zookeeper zkserv:2181 --topic freeoa
命令解析:
--describe:指定是展示详细信息命令
--zookeeper:指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
--topic:指定需要展示数据的topic名称
Topic信息修改
bin/kafka-topics.sh --zookeeper zkserv:2181 --alter --topic freeoa --config max.message.bytes=128000
bin/kafka-topics.sh --zookeeper zkserv:2181 --alter --topic freeoa --delete-config max.message.bytes
bin/kafka-topics.sh --zookeeper zkserv:2181 --alter --topic freeoa --partitions 10
bin/kafka-topics.sh --zookeeper zkserv:2181 --alter --topic freeoa --partitions 3 #Kafka分区数量只允许增加,不允许减少
Topic删除
默认情况下Kafka的Topic是没法直接删除的,需要进行相关参数配置。
bin/kafka-topics.sh --delete --topic freeoa --zookeeper zkserv:2181
Note: This will have no impact if delete.topic.enable is not set to true.## 默认情况下,删除是标记删除,没有实际删除这个Topic;如果运行删除Topic,两种方式:
方式一:通过delete命令删除后,手动将本地磁盘以及zk上的相关topic的信息删除即可
方式二:配置server.properties文件,给定参数delete.topic.enable=true,重启kafka服务,此时执行delete命令表示允许进行Topic的删除
发送消息:Kafka提供了一个命令行的工具,可以从输入文件或者命令行中读取消息并发送给Kafka集群,每一行是一条消息。运行producer(生产者),然后在控制台输入几条消息到服务器。
备注:这里的kfkserv:9092不是固定的,需要根据server.properties中配置的地址来写这里的地址。
bin/kafka-console-producer.sh --broker-list kfkserv:9092 --topic test
>this is a message
>this is another message
//按Ctrl+C终止输入
消费消息
Kafka也提供了一个消费消息的命令行工具,将存储的信息输出出来。
备注:这里的kfkserv:9092不是固定的,需要根据server.properties中配置的地址来写这里的地址。
bin/kafka-console-consumer.sh --bootstrap-server kfkserv:9092 --topic test --from-beginning
this is a message
this is another message
//按Ctrl+C终止读取消息
如果你有2台不同的终端上运行上述命令,那么当你在运行生产者时,消费者就能消费到生产者发送的消息。
设置多个broker集群(单机伪集群的配置)
到目前只是单一的运行一个broker。对于Kafka,一个broker仅仅只是一个集群的大小,所有让我们多设几个broker。首先为每个broker创建一个配置文件:
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
现在编辑这些新建的文件,设置以下属性:
vim config/server.properties
config/server1.properties: broker.id=0 listeners=PLAINTEXT://kfkserv:9092 log.dirs=kafka-logs zookeeper.connect=zkserv:2181
config/server-1.properties: broker.id=1 listeners=PLAINTEXT://kfkserv:9093 log.dirs=kafka-logs-1 zookeeper.connect=zkserv:2181
config/server-2.properties: broker.id=2 listeners=PLAINTEXT://kfkserv:9094 log.dirs=kafka-logs-2 zookeeper.connect=zkserv:2181
备注:listeners一定要配置成为IP地址;如果配置为localhost或服务器的hostname,在使用java发送数据时就会抛出异常:org.apache.kafka.common.errors.TimeoutException: Batch Expired 。因为在没有配置advertised.host.name 的情况下,Kafka并没有像官方文档宣称的那样改为广播我们配置的host.name,而是广播了主机配置的hostname。远端的客户端并没有配置 hosts,所以自然是连接不上这个hostname的。当使用java客户端访问远程的kafka时,一定要把集群中所有的端口打开,否则会连接超时。
broker.id是集群中每个节点的唯一且永久的名称,我们修改端口和日志目录是因为我们现在在同一台机器上运行,我们要防止broker在同一端口上注册和覆盖对方的数据。我们已经运行了zookeeper和刚才的一个kafka节点,所有我们只需要再启动2个新的kafka节点。
我们创建一个新topic,把备份设置为:3
bin/kafka-topics.sh --create --zookeeper zkserv:2181 --replication-factor 3 --partitions 1 --topic my-replic
我们怎么知道每个集群在做什么呢?运行命令"describe topics"
bin/kafka-topics.sh --describe --zookeeper zkserv:2181 --topic my-replicated-topic
所有分区的摘要
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
提供一个分区信息,因为我们只有一个分区,所以只有一行。
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
"leader":该节点负责该分区的所有的读和写,每个节点的leader都是随机选择的。
"replicas":备份的节点列表,无论该节点是否是leader或者目前是否还活着,只是显示。
"isr":"同步备份"的节点列表,也就是活着的节点并且正在同步leader。
其中Replicas和Isr中的1,2,0就对应着3个broker他们的broker.id属性!我们运行这个命令,看看一开始我们创建的那个节点:
kafka-topics.sh --describe --zookeeper zkserv:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
这并不奇怪,刚才创建的主题没有Replicas,并且在服务器"0"上,我们创建它的时候,集群中只有一个服务器,所以是"0"。
测试集群的容错能力
发布消息到集群
bin/kafka-console-producer.sh --broker-list kfkserv:9092 --topic my-replicated-topic
>cluster message 1
>cluster message 2
//Ctrl+C终止产生消息
从集群收取消息
bin/kafka-console-consumer.sh --bootstrap-server kfkserv:9093 --from-beginning --topic my-replicated-topic
cluster message 1
cluster message 2
//Ctrl+C终止消费消息
处理掉leader,测试集群容错
首先查询谁是leader
bin/kafka-topics.sh --describe --zookeeper zkserv:2181 --topic my-replicated-topic
//所有分区的摘要
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
//提供一个分区信息,因为我们只有一个分区,所以只有一行。
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
可以看到Leader的broker.id为1,找到对应的Broker。
jps -m
5130 Kafka ../config/server.properties
4861 QuorumPeerMain ../config/zookeeper.properties
1231 Bootstrap start start
7420 Kafka ../config/server-2.properties
7111 Kafka ../config/server-1.properties
9139 Jps -m
通过以上查询到Leader的PID(Kafka ../config/server-1.properties)为7111,杀掉该进程。
//杀掉该进程
kill -9 7111
//再查询一下,确认新的Leader已经产生,新的Leader为broker.id=0。
bin/kafka-topics.sh --describe --zookeeper zkserv:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
//备份节点之一成为新的leader,而broker1已经不在同步备份集合里了
Topic: my-replicated-topic Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0,2
再次消费消息,确认消息没有丢失
bin/kafka-console-consumer.sh --zookeeper zkserv:2181 --from-beginning --topic my-replicated-topic
cluster message 1
cluster message 2
消息依然存在,故障转移成功!
测试三
51,52,55三台机器,zk是使用的独立使用的,均为3个。
创建
bin/kafka-topics.sh --create --zookeeper 10.10.23.51:2181,10.10.23.52:2181,10.10.23.55:2181 --config max.message.bytes=12800000 --config flush.messages=1 --replication-factor 1 --partitions 1 --topic test
查看列出
bin/kafka-topics.sh --zookeeper 10.10.23.51:2181,10.10.23.52:2181,10.10.23.55:2181 --list
查看详情
bin/kafka-topics.sh --describe --zookeeper 10.10.23.51:2181,10.10.23.52:2181,10.10.23.55:2181 --topic test
删除
bin/kafka-topics.sh --delete --topic test --zookeeper 10.10.23.51:2181,10.10.23.52:2181,10.10.23.55:2181
bin/kafka-topics.sh --create --zookeeper 10.10.23.51:2181,10.10.23.52:2181,10.10.23.55:2181 --config flush.messages=1 --replication-factor 1 --partitions 3 --topic freeoa
bin/kafka-console-producer.sh --broker-list 10.10.23.51:9092 --topic freeoa
bin/kafka-console-consumer.sh --bootstrap-server 10.10.23.55:9092 --topic freeoa --from-beginning
可能存在的问题
x.1 Error: Could not find or load main class config.zookeeper.properties
原因:下载的是源码,需要编译后才可以安装使用。
解决:下载已编译的程序进行安装
测试四
Kafka是用Scala写的,所以只要安装了JRE环境,运行非常简单;直接下载官方编译好的包,解压配置一下就可以直接运行了。
4.1、kafka配置
配置文件在config目录下的server.properties,关键配置如下(有些属性配置文件中默认没有,需自己添加):
broker.id:Kafka集群中每台机器(称为broker)需要独立不重的id
port:监听端口
delete.topic.enable:设为true则允许删除topic,否则不允许
message.max.bytes:允许的最大消息大小,默认是1000012(1M),建议调到到10000012(10M)。
replica.fetch.max.bytes: 同上,默认是1048576,建议调到到10048576。
log.dirs:Kafka数据文件的存放目录,注意不是日志文件。
可以配置为:/home/freeoa/kafka/data/kafka-logs
log.cleanup.policy:过期数据清除策略,默认为delete,还可设为compact
log.retention.hours:数据过期时间(小时数),默认是1073741824,即一周。
过期数据用log.cleanup.policy的规则清除。
可以用log.retention.minutes配置到分钟级别。
log.segment.bytes:数据文件切分大小,默认是1073741824(1G)。
retention.check.interval.ms:清理线程检查数据是否过期的间隔,单位为ms,默认是300000,即5分钟。
zookeeper.connect:负责管理Kafka的zookeeper集群的机器名:端口号,多个用逗号分隔
提示:发送和接收大消息需要修改如下参数:
broker:message.max.bytes & replica.fetch.max.bytes
consumer:fetch.message.max.bytes
更多参数的详细说明见官方文档。
4.2、ZK配置和启动
然后先确保ZK已经正确配置和启动了。Kafka自带ZK服务,配置文件在config/zookeeper.properties文件,关键配置如下:
dataDir=/home/freeoa/kafka/data/zookeeper
clientPort=2181
maxClientCnxns=0
tickTime=2000
initLimit=10
syncLimit=5
server.1=nj03-01.nj03:2888:3888
server.2=nj03-02.nj03:2888:3888
server.3=nj03-03.nj03:2888:3888
Zookeeper的集群部署要做两件事情:
分配serverId: 在dataDir目录下创建一个myid文件,文件中只包含一个1到255的数字,这就是ZK的serverId。
配置集群:格式为server.{id}={host}:{port}:{port},其中{id}就是上面提到的ZK的serverId。
然后启动:bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
4.3、启动kafka
然后可以启动Kafka:JMX_PORT=8999 bin/kafka-server-start.sh -daemon config/server.properties,非常简单。
提示:我们在启动命令中增加了JMX_PORT=8999环境变量,这样可以暴露JMX监控项,方便监控。
4.4、Kafka监控和管理
不像RabbitMQ,或者ActiveMQ,Kafka默认并没有web管理界面,只有命令行语句,不是很方便,不过可以安装一个,比如Yahoo的 Kafka Manager: A tool for managing Apache Kafka。它支持很多功能,安装过程也简单,但要下载很多依赖,用时会很久。
需要注意的是,Kafka Manager的conf/application.conf配置文件里面配置的kafka-manager.zkhosts是为了它自身的高可用,而不是指向要管理的Kafka集群指向的zkhosts。所以不要忘记了手动配置要管理的Kafka集群信息(主要是配置名称,和zk地址)。
Kafka Manager主要是提供管理界面,监控的话还要依赖于其他的应用,比如:
Burrow: Kafka Consumer Lag Checking. Linkedin开源的cusumer log监控,go语言编写,貌似没有界面,只有HTTP API,可以配置邮件报警。
Kafka Offset Monitor: A little app to monitor the progress of kafka consumers and their lag wrt the queue.
这两个应用的目的都是监控Kafka的offset。
4.5、删除主题
删除Kafka主题,一般有如下两种方式:
1、手动删除各个节点${log.dir}目录下该主题分区文件夹,同时登陆ZK客户端删除待删除主题对应的节点,主题元数据保存在/brokers/topics和/config/topics节点下。
2、执行kafka-topics.sh脚本执行删除,若希望通过该脚本彻底删除主题,则需要保证在启动Kafka时加载的server.properties文件中配置 delete.topic.enable=true,该配置项默认为false。否则执行该脚本并未真正删除topic,而是在ZK的/admin/delete_topics目录下创建一个与该待删除主题同名的topic,将该主题标记为删除状态而已。
kafka-topic –delete –zookeeper server-1:2181,server-2:2181 –topic test
执行结果:
Topic test is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
此时若希望能够彻底删除topic,则需要通过手动删除相应文件及节点。当该配置项为true时,则会将该主题对应的所有文件目录以及元数据信息删除。
4.6、过期数据自动清除
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略去删除旧数据。一是基于时间,二是基于partition文件大小。可以通过配置$KAFKA_HOME/config/server.properties ,让Kafka删除一周前的数据,也可通过配置让Kafka在partition文件超过1GB时删除旧数据:
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
# By default the log cleaner is disabled and the log retention policy will default to
# just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs
# can then be marked for log compaction.
log.cleaner.enable=false
这里要注意,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除文件与Kafka性能无关,选择怎样的删除策略只与磁盘以及具体的需求有关。
4.7、Kafka的一些问题
1)、只保证单个主题单个分区内的消息有序,但是不能保证单个主题所有分区消息有序。如果应用严格要求消息有序,那么kafka可能不大合适。
2)、消费偏移量由消费者跟踪和提交,但是消费者并不会经常把这个偏移量写会kafka,因为broker维护这些更新的代价很大,这会导致异常情况下消息可能会被多次消费或者没有消费。具体分析如下:消息可能已经被消费了,但是消费者还没有像broker提交偏移量(commit offset)确认该消息已经被消费就挂掉了,接着另一个消费者又开始处理同一个分区,那么它会从上一个已提交偏移量开始,导致有些消息被重复消费。但是反过来,如果消费者在批处理消息之前就先提交偏移量,但是在处理消息的时候挂掉了,那么这部分消息就相当于『丢失』了。通常来说,处理消息和提交偏移量很难构成一个原子性操作,因此无法总是保证所有消息都刚好只被处理一次。
3)、主题和分区的数目有限
Kafka集群能够处理的主题数目是有限的,达到1000个主题左右时,性能就开始下降。这些问题基本上都跟Kafka的基本实现决策有关。特别是,随着主题数目增加,broker上的随机IO量急剧增加,因为每个主题分区的写操作实际上都是一个单独的文件追加(append)操作。随着分区数目增加,问题越来越严重。如果Kafka不接管IO调度,问题就很难解决。当然,一般的应用都不会有这么大的主题数和分区数要求。但是如果将单个Kafka集群作为多租户资源,这个时候这个问题就会暴露出来。
4)、手动均衡分区负载
Kafka的模型非常简单,一个主题分区全部保存在一个broker上,可能还有若干个broker作为该分区的副本(replica)。同一分区不在多台机器之间分割存储。随着分区不断增加,集群中有的机器运气不好,会正好被分配几个大分区。Kafka没有自动迁移这些分区的机制,因此你不得不自己来。监控磁盘空间,诊断引起问题的是哪个分区,然后确定一个合适的地方迁移分区,这些都是手动管理型任务,在Kafka集群环境中不容忽视。如果集群规模比较小,数据所需的空间较小,这种管理方式还勉强奏效。但是,如果流量迅速增加或者没有一流的系统管理员,那么情况就完全无法控制。
注意:如果向集群添加新的节点,也必须手动将数据迁移到这些新的节点上,Kafka不会自动迁移分区以平衡负载量或存储空间的。
5)、follow副本(replica)只充当冷备(解决HA问题),无法提供读服务
不像ES,replica shard是同时提供读服务,以缓解master的读压力。kafka因为读服务是有状态的(要维护commited offset),所以follow副本并没有参与到读写服务中。只是作为一个冷备,解决单点问题。
6)、只能顺序消费消息,不能随机定位消息,出问题的时候不方便快速定位问题。这其实是所有以消息系统作为异步RPC的通用问题。假设发送方发了一条消息,但是消费者说我没有收到,那么怎么排查呢?消息队列缺少随机访问消息的机制,如根据消息的key获取消息。这就导致排查这种问题不大容易。
Kafka FAQ
消息队列模型简述,kafka是怎么做到支持这两种模型的?
对于传统的消息队列系统支持两个模型:
1.点对点:也就是消息只能被一个消费者消费,消费完后消息删除
2.发布订阅:相当于广播模式,消息可以被所有消费者消费
上面也说到过,kafka其实就是通过Consumer Group同时支持了这两个模型。
如果说所有消费者都属于一个Group,消息只能被同一个Group内的一个消费者消费,那就是点对点模式。
如果每个消费者都是一个单独的Group,那么就是发布订阅模式。
实际上,Kafka通过消费者分组的方式灵活的支持了这两个模型。
能说说kafka通信过程原理吗?
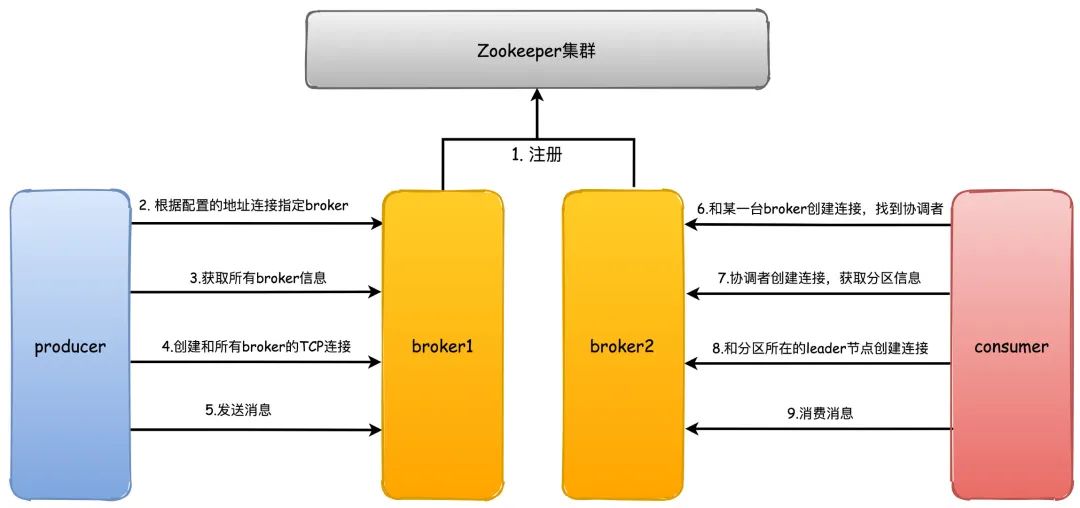
首先kafka broker启动的时候,会去向Zookeeper注册自己的ID(创建临时节点),这个ID可以配置也可以自动生成,同时会去订阅Zookeeper的brokers/ids路径,当有新的broker加入或者退出时,可以得到当前所有broker信息
生产者启动的时候会指定bootstrap.servers,通过指定的broker地址,Kafka就会和这些broker创建TCP连接(通常我们不用配置所有的broker服务器地址,否则kafka会和配置的所有broker都建立TCP连接)
随便连接到任何一台broker之后,然后再发送请求获取元数据信息(包含有哪些主题、主题都有哪些分区、分区有哪些副本,分区的Leader副本等信息)
接着就会创建和所有broker的TCP连接
之后就是发送消息的过程
消费者和生产者一样,也会指定bootstrap.servers属性,然后选择一台broker创建TCP连接,发送请求找到协调者所在的broker
然后再和协调者broker创建TCP连接,获取元数据
根据分区Leader节点所在的broker节点,和这些broker分别创建连接
最后开始消费消息
那么发送消息时如何选择分区的?
主要有两种方式:
1.轮询,按照顺序消息依次发送到不同的分区
2.随机,随机发送到某个分区
如果消息指定key,那么会根据消息的key进行hash,然后对partition分区数量取模,决定落在哪个分区上,所以,对于相同key的消息来说,总是会发送到同一个分区上,也是我们常说的消息分区有序性。
很常见的场景就是我们希望下单、支付消息有顺序,这样以订单ID作为key发送消息就达到了分区有序性的目的。
如果没有指定key,会执行默认的轮询负载均衡策略,比如第一条消息落在P0,第二条消息落在P1,然后第三条又在P1。
除此之外,对于一些特定的业务场景和需求,还可以通过实现Partitioner接口,重写configure和partition方法来达到自定义分区的效果。
那你觉得为什么需要分区?有什么好处?
这个问题很简单,如果说不分区的话,我们发消息写数据都只能保存到一个节点上,这样的话就算这个服务器节点性能再好最终也支撑不住。
实际上分布式系统都面临这个问题,要么收到消息之后进行数据切分,要么提前切分,kafka正是选择了前者,通过分区可以把数据均匀地分布到不同的节点。
分区带来了负载均衡和横向扩展的能力。
发送消息时可以根据分区的数量落在不同的Kafka服务器节点上,提升了并发写消息的性能,消费消息的时候又和消费者绑定了关系,可以从不同节点的不同分区消费消息,提高了读消息的能力。
另外一个就是分区又引入了副本,冗余的副本保证了Kafka的高可用和高持久性。
详细说说消费者组和消费者重平衡?
Kafka中的消费者组订阅topic主题的消息,一般来说消费者的数量最好要和所有主题分区的数量保持一致最好(举例子用一个主题,实际上当然是可以订阅多个主题)。
当消费者数量小于分区数量的时候,那么必然会有一个消费者消费多个分区的消息。
而消费者数量超过分区的数量的时候,那么必然会有消费者没有分区可以消费。
所以,消费者组的好处一方面在上面说到过,可以支持多种消息模型,另外的话根据消费者和分区的消费关系,支撑横向扩容伸缩。
当我们知道消费者如何消费分区的时候,就显然会有一个问题出现了,消费者消费的分区是怎么分配的,有先加入的消费者时候怎么办?
旧版本的重平衡过程主要通过ZK监听器的方式来触发,每个消费者客户端自己去执行分区分配算法。
新版本则是通过协调者来完成,每一次新的消费者加入都会发送请求给协调者去获取分区的分配,这个分区分配的算法逻辑由协调者来完成。
而重平衡Rebalance就是指的有新消费者加入的情况,比如刚开始我们只有消费者A在消费消息,过了一段时间消费者B和C加入了,这时候分区就需要重新分配,这就是重平衡,也可以叫做再平衡,但是重平衡的过程和我们的GC时候STW很像,会导致整个消费群组停止工作,重平衡期间都无法消息消息。
另外,发生重平衡并不是只有这一种情况,因为消费者和分区总数是存在绑定关系的,上面也说了,消费者数量最好和所有主题的分区总数一样。
那只要消费者数量、主题数量(比如用的正则订阅的主题)、分区数量任何一个发生改变,都会触发重平衡。
下面说说重平衡的过程。
重平衡的机制依赖消费者和协调者之间的心跳来维持,消费者会有一个独立的线程去定时发送心跳给协调者,这个可以通过参数heartbeat.interval.ms来控制发送心跳的间隔时间。
1.每个消费者第一次加入组的时候都会向协调者发送JoinGroup请求,第一个发送这个请求的消费者会成为“群主”,协调者会返回组成员列表给群主
2.群主执行分区分配策略,然后把分配结果通过SyncGroup请求发送给协调者,协调者收到分区分配结果
3.其他组内成员也向协调者发送SyncGroup,协调者把每个消费者的分区分配分别响应给他们
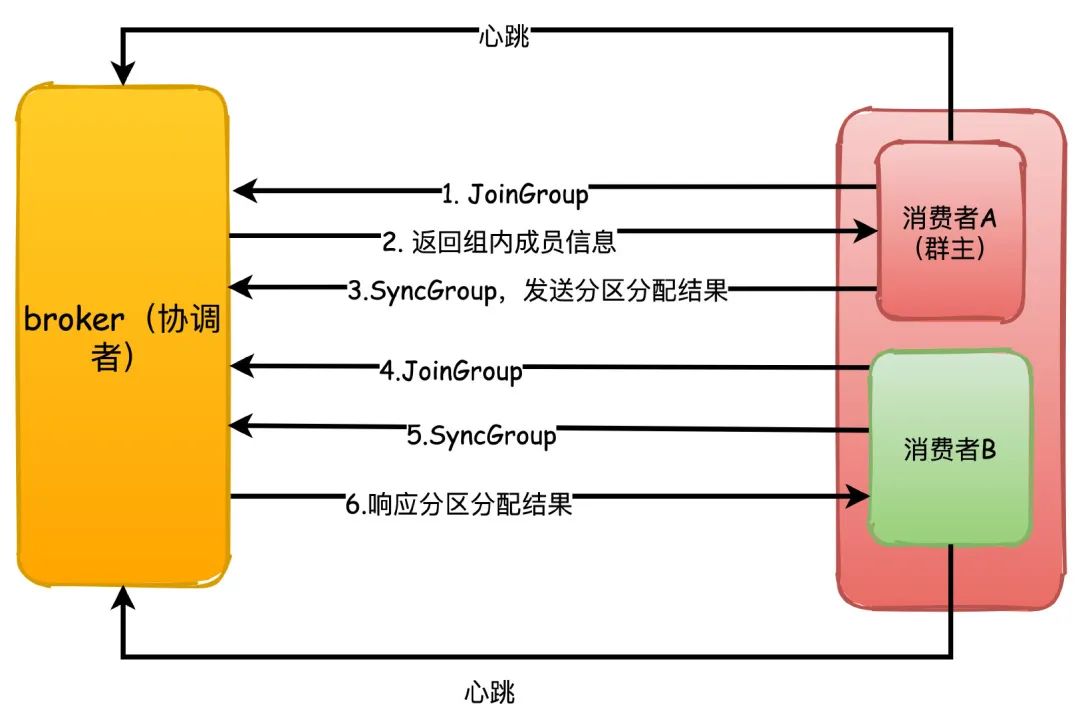
那再具体讲讲分区分配策略?
主要有3种分配策略:
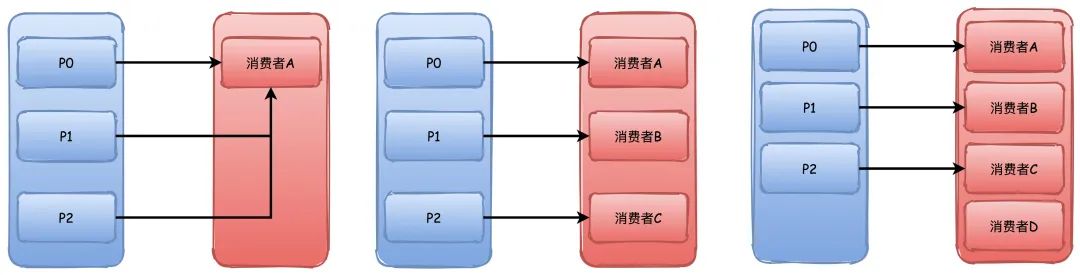
Range
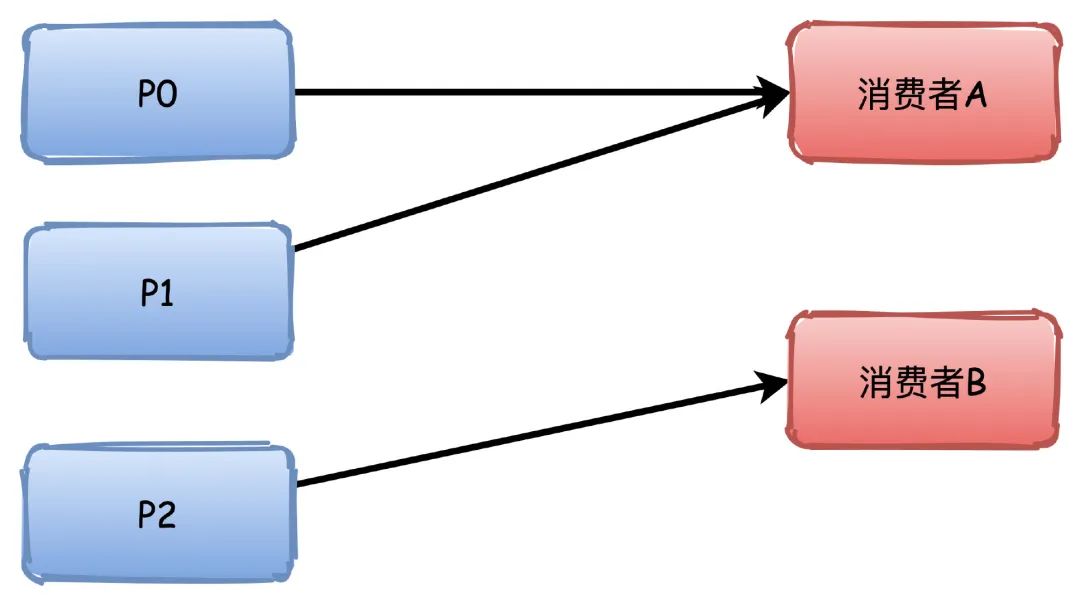
不知道咋翻译,这个是默认的策略。大概意思就是对分区进行排序,排序越靠前的分区能够分配到更多的分区。
比如有3个分区,消费者A排序更靠前,所以能够分配到P0\P1两个分区,消费者B就只能分配到一个P2。
如果是4个分区的话,那么他们会刚好都是分配到2个。
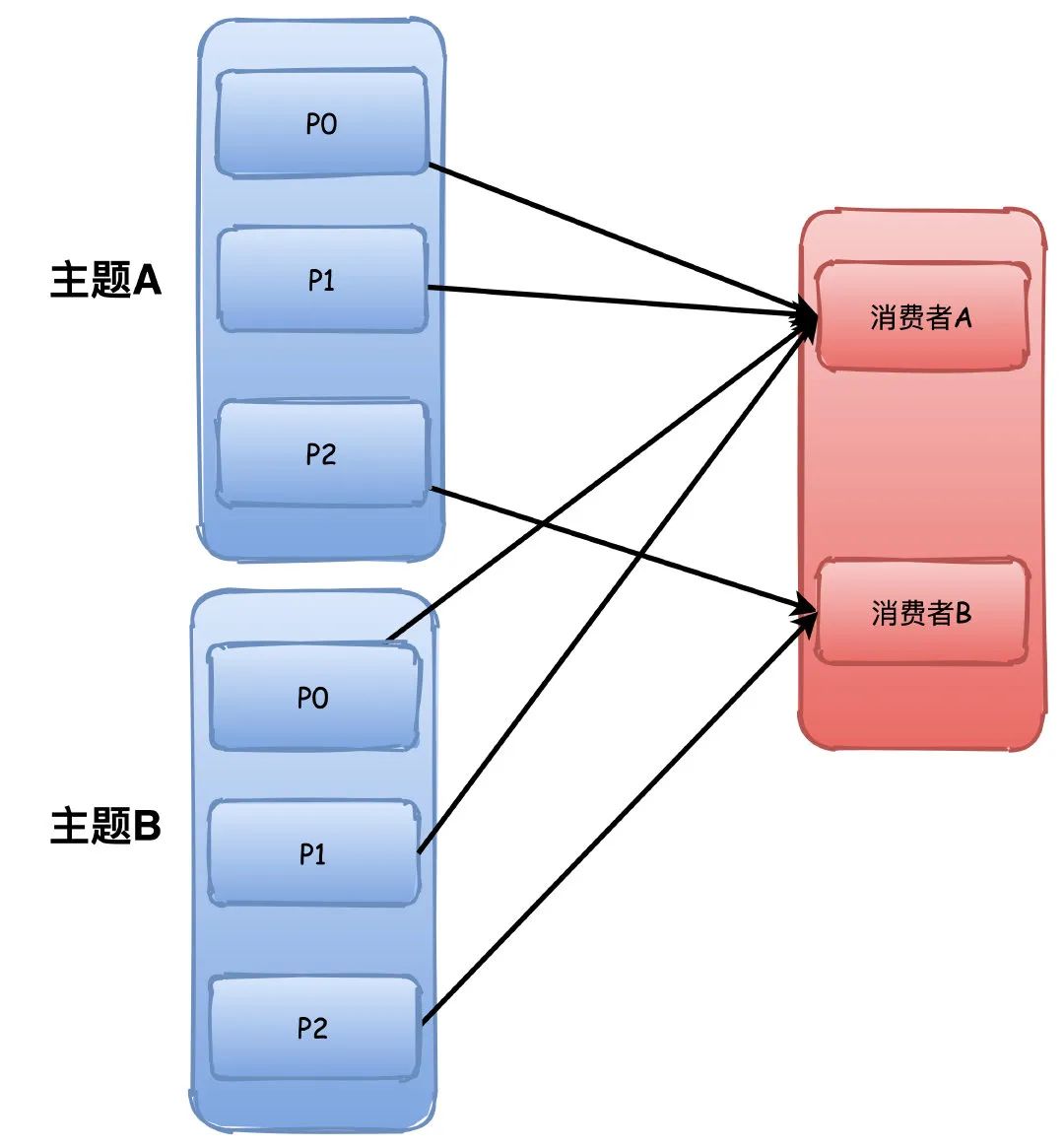
但是这个分配策略会有点小问题,他是根据主题进行分配,所以如果消费者组订阅了多个主题,那就有可能导致分区分配不均衡。
比如下图中两个主题的P0\P1都被分配给了A,这样A有4个分区,而B只有2个,如果这样的主题数量越多,那么不均衡就越严重。
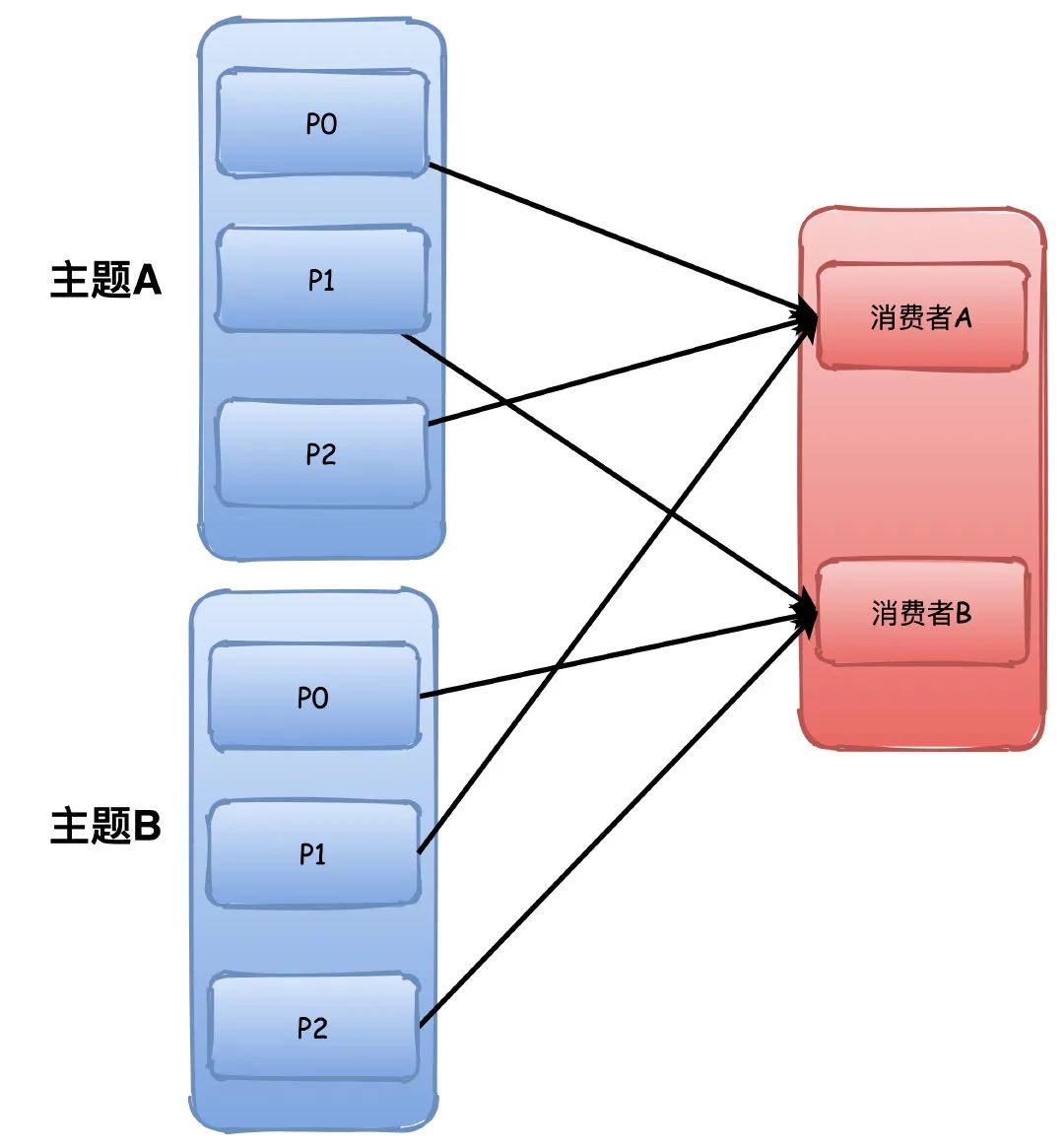
RoundRobin
也就是我们常说的轮询了,这个就比较简单了,不画图你也能很容易理解。
这个会根据所有的主题进行轮询分配,不会出现Range那种主题越多可能导致分区分配不均衡的问题。
P0->A,P1->B,P1->A。。。以此类推
Sticky
这个从字面看来意思就是粘性策略,大概是这个意思。主要考虑的是在分配均衡的前提下,让分区的分配更小的改动。
比如之前P0\P1分配给消费者A,那么下一次尽量还是分配给A。
这样的好处就是连接可以复用,要消费消息总是要和broker去连接的,如果能够保持上一次分配的分区的话,那么就不用频繁的销毁创建连接了。
如何保证消息可靠性?
消息可靠性的保证基本上我们都要从3个方面来阐述(这样才比较全面,无懈可击)
生产者发送消息丢失
kafka支持3种方式发送消息,这也是常规的3种方式,发送后不管结果、同步发送、异步发送,基本上所有的消息队列都是这样玩的。
1.发送并忘记,直接调用发送send方法,不管结果,虽然可以开启自动重试,但是肯定会有消息丢失的可能
2.同步发送,同步发送返回Future对象,我们可以知道发送结果,然后进行处理
3.异步发送,发送消息,同时指定一个回调函数,根据结果进行相应的处理
为了保险起见,一般我们都会使用异步发送带有回调的方式进行发送消息,再设置参数为发送消息失败不停地重试。
acks=all,这个参数有可以配置0|1|all。
0表示生产者写入消息不管服务器的响应,可能消息还在网络缓冲区,服务器根本没有收到消息,当然会丢失消息。
1表示至少有一个副本收到消息才认为成功,一个副本那肯定就是集群的Leader副本了,但是如果刚好Leader副本所在的节点挂了,Follower没有同步这条消息,消息仍然丢失了。
配置all的话表示所有ISR都写入成功才算成功,那除非所有ISR里的副本全挂了,消息才会丢失。
retries=N,设置一个非常大的值,可以让生产者发送消息失败后不停重试
kafka自身消息丢失
kafka因为消息写入是通过PageCache异步写入磁盘的,因此仍然存在丢失消息的可能。
因此针对kafka自身丢失的可能设置参数:
replication.factor=N,设置一个比较大的值,保证至少有2个或者以上的副本。
min.insync.replicas=N,代表消息如何才能被认为是写入成功,设置大于1的数,保证至少写入1个或者以上的副本才算写入消息成功。
unclean.leader.election.enable=false,这个设置意味着没有完全同步的分区副本不能成为Leader副本,如果是true的话,那些没有完全同步Leader的副本成为Leader之后,就会有消息丢失的风险。
消费者消息丢失
消费者丢失的可能就比较简单,关闭自动提交位移即可,改为业务处理成功手动提交。
因为重平衡发生的时候,消费者会去读取上一次提交的偏移量,自动提交默认是每5秒一次,这会导致重复消费或者丢失消息。
enable.auto.commit=false,设置为手动提交。
还有一个参数我们可能也需要考虑进去的:
auto.offset.reset=earliest,这个参数代表没有偏移量可以提交或者broker上不存在偏移量的时候,消费者如何处理。earliest代表从分区的开始位置读取,可能会重复读取消息,但是不会丢失,消费方一般我们肯定要自己保证幂等,另外一种latest表示从分区末尾读取,那就会有概率丢失消息。
综合这几个参数设置,我们就能保证消息不会丢失,保证了可靠性。
说说副本和它的同步原理吧?
Kafka副本的之前提到过,分为Leader副本和Follower副本,也就是主副本和从副本,和其他的比如Mysql不一样的是,Kafka中只有Leader副本会对外提供服务,Follower副本只是单纯地和Leader保持数据同步,作为数据冗余容灾的作用。
在Kafka中我们把所有副本的集合统称为AR(Assigned Replicas),和Leader副本保持同步的副本集合称为ISR(InSyncReplicas)。
ISR是一个动态的集合,维持这个集合会通过replica.lag.time.max.ms参数来控制,这个代表落后Leader副本的最长时间,默认值10秒,所以只要Follower副本没有落后Leader副本超过10秒以上,就可以认为是和Leader同步的(简单可以认为就是同步时间差)。
另外还有两个关键的概念用于副本之间的同步:
HW(High Watermark):高水位,也叫做复制点,表示副本间同步的位置。如下图所示,0~4绿色表示已经提交的消息,这些消息已经在副本之间进行同步,消费者可以看见这些消息并且进行消费,4~6黄色的则是表示未提交的消息,可能还没有在副本间同步,这些消息对于消费者是不可见的。
LEO(Log End Offset):下一条待写入消息的位移
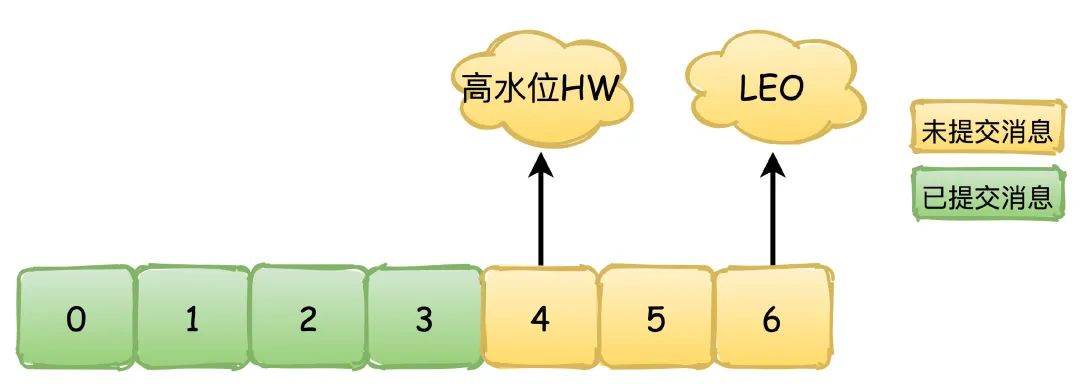
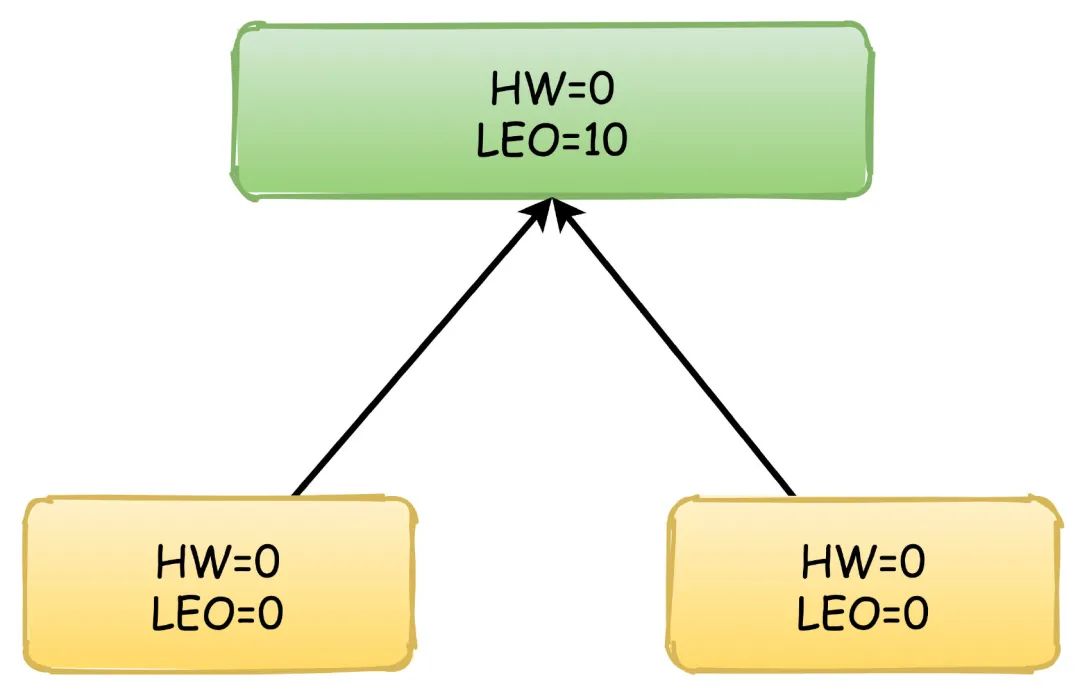
副本间同步的过程依赖的就是HW和LEO的更新,以他们的值变化来演示副本同步消息的过程,绿色表示Leader副本,黄色表示Follower副本。
首先,生产者不停地向Leader写入数据,这时候Leader的LEO可能已经达到了10,但是HW依然是0,两个Follower向Leader请求同步数据,他们的值都是0。
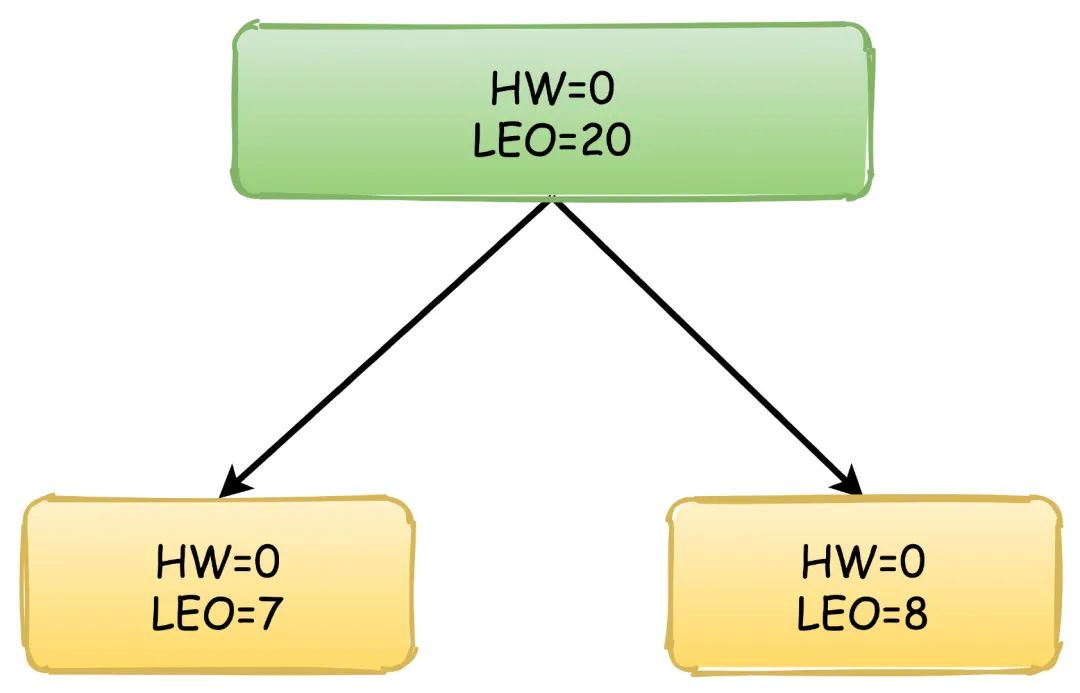
然后,消息还在继续写入,Leader的LEO值又发生了变化,两个Follower也各自拉取到了自己的消息,于是更新自己的LEO值,但是这时候Leader的HW依然没有改变。
此时,Follower再次向Leader拉取数据,这时候Leader会更新自己的HW值,取Follower中的最小的LEO值来更新。
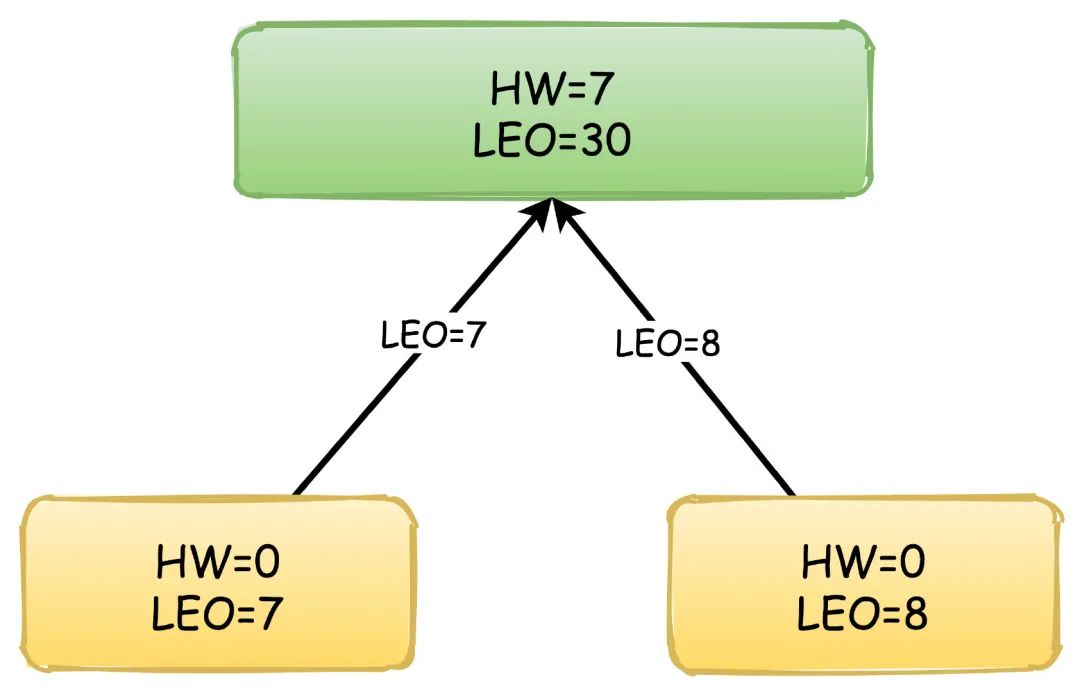
之后,Leader响应自己的HW给Follower,Follower更新自己的HW值,因为又拉取到了消息,所以再次更新LEO,流程以此类推。
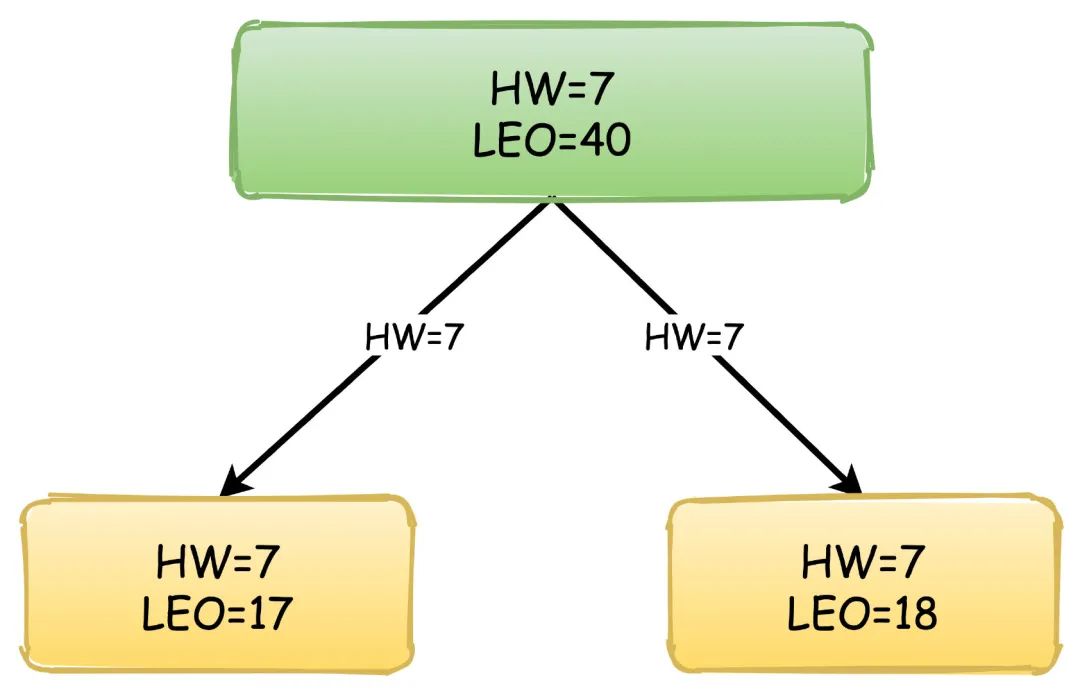
新版本Kafka为什么抛弃了Zookeeper吗?
我认为可以从两个个方面来回答这个问题:
首先,从运维的复杂度来看,Kafka本身是一个分布式系统,他的运维就已经很复杂了,那除此之外,还需要重度依赖另外一个ZK,这对成本和复杂度来说都是一个很大的工作量。其次,应该是考虑到性能方面的问题,比如之前的提交位移的操作都是保存在ZK里面的,但是ZK实际上不适合这种高频的读写更新操作,这样的话会严重影响ZK集群的性能,这一方面后来新版本中Kafka也把提交和保存位移用消息的方式来处理了。
另外Kafka严重依赖ZK来实现元数据的管理和集群的协调工作,如果集群规模庞大,主题和分区数量很多,会导致ZK集群的元数据过多,集群压力过大,直接影响到很多Watch的延时或者丢失。
最后一个大家都问的问题,Kafka为什么快?
主要是3个方面:
顺序IO
kafka写消息到分区采用追加的方式,也就是顺序写入磁盘,不是随机写入,这个速度比普通的随机IO快非常多,几乎可以和网络IO的速度相媲美。
Page Cache和零拷贝
kafka在写入消息数据的时候通过mmap内存映射的方式,不是真正立刻写入磁盘,而是利用操作系统的文件缓存PageCache异步写入,提高了写入消息的性能,另外在消费消息的时候又通过sendfile实现了零拷贝。
批量处理和压缩
Kafka在发送消息的时候不是一条条的发送的,而是会把多条消息合并成一个批次进行处理发送,消费消息也是一个道理,一次拉取一批次的消息进行消费。
并且Producer、Broker、Consumer都使用了优化后的压缩算法,发送和消息消息使用压缩节省了网络传输的开销,Broker存储使用压缩则降低了磁盘存储的空间。
参考链接
本文有参考互联网上众多文章,感谢诸位网友。
kafka实战
为什么Kafka那么快
kafka入门:简介、使用场景、设计原理、主要配置及集群搭建