维基百科全书 Wikipedia 20 周岁记
 Wikipedia 20 周岁了。2001 年 1 月 15 日 Jimmy Wales 与 Larry Sanger 上线 Wikipedia 项目,Larry 正式提出“Wikipedia”一词,昨天正是它的 20 周岁生日。
Wikipedia 20 周岁了。2001 年 1 月 15 日 Jimmy Wales 与 Larry Sanger 上线 Wikipedia 项目,Larry 正式提出“Wikipedia”一词,昨天正是它的 20 周岁生日。
Wikipedia,中文名“维基百科”,它的 slogan 是“自由的百科全书”,它是一部基于互联网、内容开放的全球多语言百科全书,也是目前世界上最大的百科全书,基于 wiki 技术,其支持多语言全球协作。Wikipedia 由非营利性组织 Wikimedia Foundation 运营。同时,它也是第 15 名最受欢迎的网站,提供 300 多种语言提供,并由志愿者编辑社区维护。
在过去的 1 年中,每月有超过 28 万人编辑维基百科,就在写这篇文章的同时,来自世界各地的志愿者们仍在贡献他们的力量。
对于这些志愿者来说,参与维基百科的编辑工作,不仅是为他人提供有价值的信息,同样也是在扩宽自己的知识边界。在参与维基媒体运动的同时,分享和宣传自己的学识也会让人充满成就感。
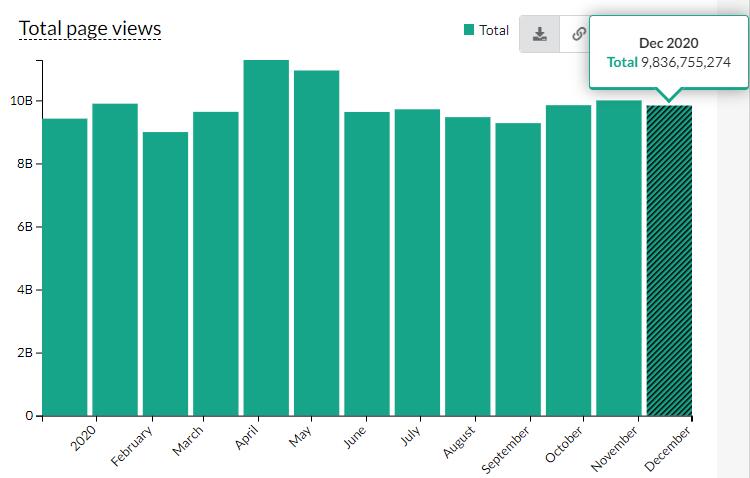
2020年,维基百科的总浏览量达到了 1185 亿次。随着数据智能、AI 技术的崛起,维基百科还产生出了一种更间接的经济效益 —— 作为大量机器学习数据集的原始文本,“喂料” 给各种各样的自然语言处理模型。亚马逊和苹果训练 Alexa 和 Siri 根据维基百科回答事实问题;谷歌用它来填充 "fact boxes(事实框)",应用到有关事实问题的搜索场景。
在这里,从学生到政治家再到新闻记者,每个人都在这里寻求有关任何主题的快速简报,尽管甚至维基百科都说不应将其用作信息的主要来源。而且,维基百科也有不足,比如广为人知的作者多样性问题。有研究发现,在维基百科上撰写内容的人,大部分是居住在北半球发达国家、擅长科技产品的男性白领。他们所撰写的往往是自己感兴趣的信息。这变相造成了一种 “幸存者偏差”:在维基百科中,关于《指环王》中角色的条目就有超过 150 条,而关于越南战争的内容却少于 10 条。
参考链接
维基百科生日活动
维基百科电子礼物包
维基百科 20 周年官方公告
维基百科因 AI 聊天机器人流量下降
维基百科运营方维基媒体基金会在2025年10月表示,由于越来越多用户通过 AI 聊天机器人和搜索引擎直接获取维基百科上的信息,导致其人类访问流量显著下降。这一现象引发了基金会对维基百科未来可持续发展的担忧。维基媒体基金会的高级总监 Marshall Miller 在官方博客中指出,虽然人们以新的方式获取知识是受欢迎的,但 AI 工具和社交平台在使用维基百科内容时,应该鼓励用户访问维基百科本身。他强调,维基百科的流量减少将导致志愿者减少,内容生产与扩充受到影响,甚至可能导致个人捐赠的减少,这将直接威胁到维基百科的正常运营。
有趣的是,尽管 AI 和搜索引擎使维基百科的直接流量减少,但维基百科的数据对这些平台而言愈发重要。许多大型语言模型都使用维基百科作为核心数据集,而 Google 等平台长期依赖维基百科的文章来生成摘要和知识面板,这也进一步分流了维基百科的访问量。Miller 还提到,维基百科在 2025 年 5 月观察到源自巴西的 “人类访问流量” 异常高。经过调查后,基金会调整了自动检测系统,发现最近的人类页面浏览量同比下降约 8%。这一趋势反映出 AI 和社交媒体改变了用户获取信息的方式,搜索引擎越来越多地直接返回基于维基百科内容的答案,让用户无需访问原始页面。
为了应对 AI 带来的挑战,维基百科正在加强政策和技术能力,规范第三方平台对其内容的使用,并与主要内容再利用方合作。此外,基金会还计划通过 YouTube、TikTok、Roblox 和 Instagram 等平台,向年轻用户推广维基内容。Miller 呼吁用户在进行网络搜索时,关注原始出处和引用,主动点击链接访问来源,帮助维护知识的完整性和原创性。面对 AI 带来的流量冲击,维基百科的未来发展值得持续关注。
公开 “AI 写作识别指南”
维基百科编辑团队于2025年11月公开其内部使用的《AI 写作识别指南》,首次系统性揭示大语言模型(LLM)在行文中的 “行为指纹”,为公众提供了一套可操作、有据可依的 AI 文本鉴别方法。
自 2023 年启动 “AI 清理计划”(Project AI Cleanup)以来,维基百科编辑们每天面对数百万条编辑提交,积累了海量 AI 写作样本。他们发现,自动化检测工具基本无效,而真正可靠的判断,来自对语言习惯与叙事逻辑的深度观察。
1.空洞的重要性强调 AI 热衷用泛泛之词标榜主题价值,如 “这是一个关键时刻”“体现了广泛影响”,却缺乏具体事实支撑 —— 这种 “重要性焦虑” 在人类撰写的百科条目中极为罕见。
2.堆砌低价值媒体报道 为证明人物或事件 “值得收录”,AI 常罗列大量边缘媒体曝光(如某博客采访、地方电台片段),模仿个人简历写法,而非引用权威、独立信源。
3.“现在分词” 滥用式总结 频繁使用 “强调…… 的重要性”“反映…… 的持续相关性” 等模糊尾随句式(语法上称为 “现在分词短语”),制造一种 “深度分析” 的假象,实则内容空洞。维基编辑称:“一旦你注意到这种套路,就会发现它无处不在。”
4.广告式形容词泛滥 AI 偏爱使用 “风景如画”“视野壮丽”“干净现代” 等营销话术,行文 “听起来像电视广告脚本”,缺乏客观、克制的百科语感。
5.过度结构化但缺乏洞见 段落看似逻辑清晰、层层递进,实则重复同义表述,缺乏人类作者的批判性思维或独特视角。
维基团队指出,这些 “语言指纹” 深植于 AI 的训练逻辑:模型通过海量网络文本学习 “如何像人一样写作”,而互联网充斥着自我推销、SEO 优化与内容农场式文本。因此,AI 自然继承了这些 “数字时代写作病”—— 即便技术再进化,只要训练数据不变,这些习惯就难以彻底清除。
微软等向维基百科付费获取企业级数据访问权
在维基百科庆祝其 25 周年的2026年1月中旬之际,全球多家科技巨头正竞相为其 “企业级” 数据访问权买单。继谷歌之后,微软、Meta、亚马逊以及 AI 新秀 Perplexity 和 Mistral AI 均已正式加入 Wikimedia Enterprise 计划。
这项由维基媒体基金会(Wikimedia Foundation)于 2021 年推出的付费计划,旨在为大型商业公司提供定制化的 API 接口。据该基金会收入高级总监透露,该服务会根据 AI 公司的特定需求,对维基百科海量的文章数据进行重新 “调校” 和结构化处理,使其更易于模型训练和商业用途。虽然 Meta 和亚马逊此前已在合作名单中,但此次是首次公开披露。
维基媒体基金会表示,这笔收入将直接用于支持该非营利组织的长期运营。在 AI 时代,高质量的语料库已成为核心资产,这种合作不仅能为维基百科提供更可持续的商业模式,也是确保 AI 公司获得可靠数据源的关键平衡点。