简析英特尔Lunar Lake处理器-内存塞进CPU和取消超线程
 2024年6月上旬消息,英特尔自从第12代酷睿处理器发布后,在13代、14代产品上只是调整核心规格、频率,对核心微架构进行小改动,整体来看并未大幅度改动整个处理器的架构。虽然凭借着强悍的性能、极高的频率以及优秀的整体表现,英特尔酷睿i系列处理器依旧在市场上呼风唤雨,但是随着AI技术的兴起以及整个行业形势发展,英特尔如果要持续保持领先地位、引领行业发展的话,还是需要做出更多的变化。2024年6月5日,英特尔公开了新一代代号Lunar Lake的处理器产品,带来了全新的P核、E核、GPU、NPU以及SoC设计,全面革新了整个处理器的方方面面,更好的应对AI时代的计算需求,同时也维持了极高的传统计算能力,让我们一起来看一下它的主要变化。
2024年6月上旬消息,英特尔自从第12代酷睿处理器发布后,在13代、14代产品上只是调整核心规格、频率,对核心微架构进行小改动,整体来看并未大幅度改动整个处理器的架构。虽然凭借着强悍的性能、极高的频率以及优秀的整体表现,英特尔酷睿i系列处理器依旧在市场上呼风唤雨,但是随着AI技术的兴起以及整个行业形势发展,英特尔如果要持续保持领先地位、引领行业发展的话,还是需要做出更多的变化。2024年6月5日,英特尔公开了新一代代号Lunar Lake的处理器产品,带来了全新的P核、E核、GPU、NPU以及SoC设计,全面革新了整个处理器的方方面面,更好的应对AI时代的计算需求,同时也维持了极高的传统计算能力,让我们一起来看一下它的主要变化。延续模块化策略、内存首次和处理器封装在一起
英特尔在Meteor Lake上首次采用了Chiplet设计,让不同的核心比如计算核心、GPU核心、IO核心以及SoC核心采用不同的工艺制造,并通过高级封装技术将其整合在一起。这种工艺和核心解耦、各自采用更合适工艺制造的方式,带来了处理器设计上的重大变革。在Lunar Lake上,英特尔维持了这样的技术,但是创新性地加入了内存的封装,带来了集成度更高的产品,进一步提高了性能、能耗比以及应用体验。

从整体架构角度来看,内存的封装将带来整个系统级的效能提升。因为主板厂商不需要在PCB上布置单独的内存供电和数据传输线路,这些功能全部转移到处理器的PCB基板上,同时由高频率内存带来的信号线布置、抗干扰设计等都可以全部取消。对英特尔来说,内存转移到处理器基板上,还获得了更稳定的性能和更高的能耗比,以及最重要的移动设备内部面积节省。

英特尔数据显示将内存转移到处理器基板后,带来了40%物理功耗降低、250平方毫米面积的节省以及每个芯片8.5GT/s的传输带宽速率,容量方面也可以达到32GB。这对笔记本电脑产品来说是足够用的。
性能核和能效核全面进化、IPC大幅度提升
Lunar Lake在核心微架构上相对于Meteor Lake的另一个重大改进在于整个处理器最关键的微架构得到了更新。Lunar Lake的性能核也就是P核的微架构进化至Lion Cove,E核微架构进化至Skymont,带来了相对上一代微架构性能的大幅度提升。

宏观特点来看,Lion Cove主要是增大规模、提高内部执行能力、增加更多执行端口并针对缓存进行大规模革新,英特尔认为Lion Cove在性能和面积效率方面进行了改进,同时更加符合现代化的需求。

更具体来看的话,性能核心的核心改进,主要在于几点:整个分支预测宽度增加至之前的8倍、VEC和INT的乱序执行部分进行分离调度,此外还带来了更宽的调度单元、增强的内存子系统,加入了L0级别缓存以及彻底改动了内存子系统等。在性能功耗方面,带来了基于AI的电源管理以及针对核心面积和性能的优化。
如果说上述改进大家感知不明显的话,那么Lion Cove取消了超线程技术以及相关的晶体管资源,应该是本次最重要的变化了。英特尔认为,目前E核心在很大程度上起到了超线程技术的作用,同时超线程技术也需要耗费大量的晶体管资源,因此本代处理器干脆彻底取消,以获得更好的面积性能比,同时也可以降低核心面积、功耗以及成本。
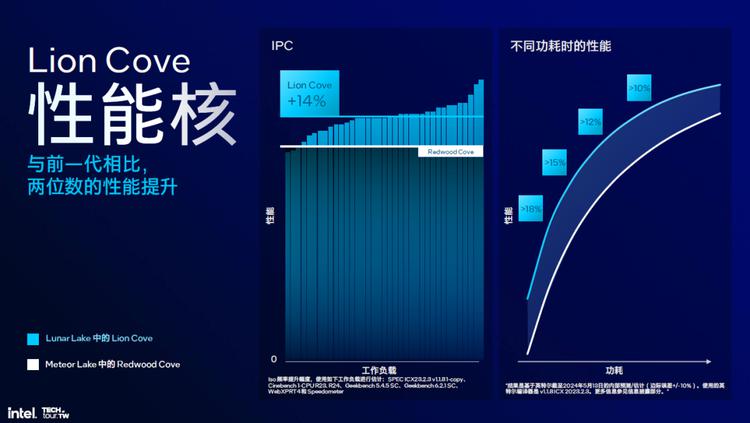
性能方面,性能核心相比上代产品,平均提升了14%的IPC,低功耗下更明显一些,高功耗下提升依旧可以大于10%。如果再算上更高的频率的话,效能提升就更为可观了。

性能核心的改进如果说是显著提高的话,那么能效核心的改进就可以说是翻天覆地了。Skymont的能效核心改进主要是整体IPC的提高、能效核心现在也能在更高的工作负载范围内输出性能了,此外还带来了增强的矢量计算和AI计算等。

整体来看,能效核心分支预测大幅度加强,前端指令解码来到了3×3也就是9宽度设计,同时整个架构规模、调度端口、缓存以及队列深度等都进行了极大幅度的扩充。在矢量计算方面,SIMD增加到4×128位,这意味着吞吐能力相比上代产品翻倍,对VNNI指令的支持也更为出色了。简单总结的话,就是能效核心现在变得不像人们印象中的就是为节能而设计的核心了,在规模大幅度扩大后,它相应地迎来了更高的性能,完全可以当做主核心来使用了。
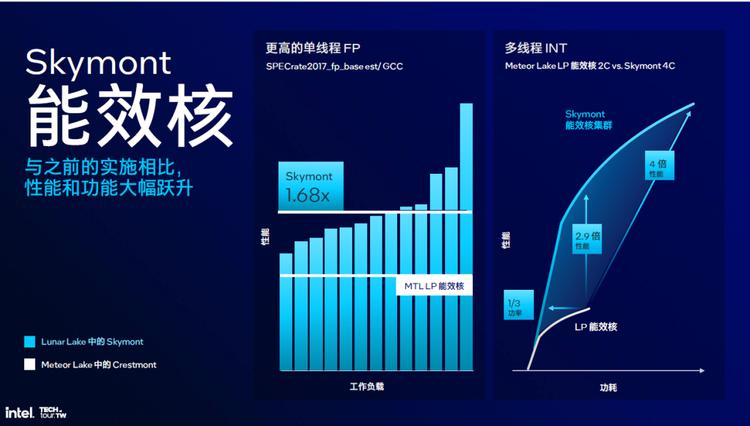
性能方面,Skymont相比上代产品,单线程浮点能力提升到1.68倍,多线程整数能力最高提升4倍(由于功耗范围扩展),或者只有前代1/3的功耗。由于前代Crestmont的整体性能已经超过英特尔之前使用的Skylake以及各种“+++”版本的性能,在如此大改后,甚至可以认为Skymont在微架构IPC方面可能距离Lion Cove差距不大,但是拥有更好的能效比表现,这可能是英特尔未来发展重要变化之一。
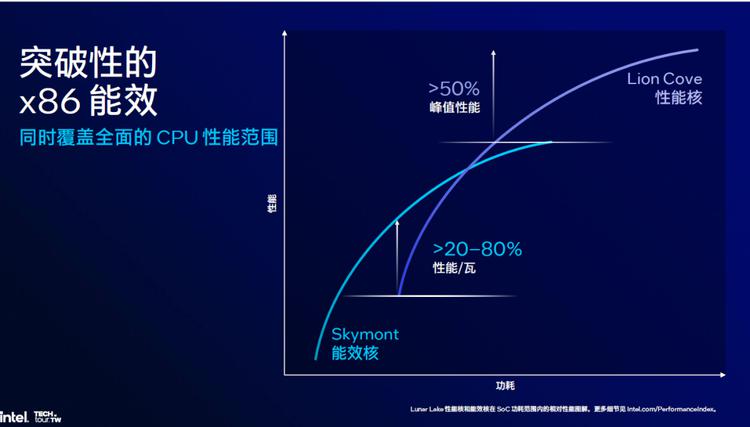
在整个集群性能调度方面,Lunar Lake调度更为成熟。由于全新的工艺、更优秀的P、E核心以及更高性能功耗比的设计,Skymont和Lion Cove在性能、功耗的交叉点上移了不少,现在更多的任务可以交给Skymont进行操作,Lion Cove只在更高性能需求的时候登场,这无疑带来了更好的性能功耗比表现。

由于大小核心的存在,英特尔还是延续了硬件线程调度器的做法,但是做出了更多改进,比如更好的OS分区设置、更好的电源集成管理以及整体算法的优化、AI判断的加入、更精细的调控等,都带来了整体线程调度效率的提高。
Lunar Lake的整个调度目前更为动态、更为自主。P核心和E核心的调度优先级方面更偏向于能耗比提高,但也同时针对性能需求做了很好的优化。由于E核心现在更强大、覆盖最佳性能功耗比区间更广阔,因此转移至P核心的概率也更低,只有突发重载的情况,P核心才会火力全开。
GPU和NPU加强,AI计算大提升级
英特尔在自研GPU上进展相当不错,其产品凭借高性价比得到了很多消费者的青睐。在Lunar Lake上,英特尔引入了第二代Xe GPU架构,带来了新的矢量引擎,整体性能、效率也显著提升。

第二代Xe GPU的重要改进在于规模更大,光线追踪和AI性能更强。比如8个Xe核心、8个更强的光追单元以及增强的XeSS内核等。规模大意味着性能强,这在GPU上是百试不爽的灵药,Lunar Lake的GPU性能是上代产品的1.5倍,能够更好地满足用户针对图形方面的需求。

在AI计算方面,新的Xe GPU集成了新的矢量引擎,同样是带来了更大的规模,比如原生支持SIMD16,支持的精度更多,包括INT2、INT4、INT8、INT16以及BF16和FP16等,针对AI模型计算整体无论是效率还是功能方面都会有更好的提升。

媒体引擎方面,本代英特尔启用了全新设计的媒体引擎,带来了AV1编解码和VVC编解码支持。主要的特性包含针对eDP 1.5的节能功能,包括可以降低画面抖动的显示帧率和媒体帧率的自适应适配、节约CPU能耗的内容排队序列、降低整体显示功耗的选择性显示内容(Early Transport)等。规格方面主要是加入了H.266也就是VVC的解码支持,H.266相比目前的AV1文件大小继续缩小大约10%,此外还有自适应编码、屏幕内容编码流SSC等特性。显示方面支持3个显示通道、支持DP 2.1、HDMI 2.1等。

总的来说,整个Lunar Lake的图形性能是大幅度提升的,英特尔数据是提升了大概50%,并且AI性能高达67TOPS,更多新特性的支持等。由于GPU的升级,更多的用户可以直接选择集成显卡配置的机型,也能得到不错的图形计算应用体验,这是很令人满意的。

在NPU方面,Lunar Lake的NPU由于AI应用的发展,也得到了大幅度提升和加强。NPU的整体算力高达48 TOPS,虽然看起来比GPU低,但是NPU整体计算效率是更高、更节约能耗的,因此更多的AI计算任务可以直接在NPU上完成而不需要动用CPU和GPU。NPU的变化主要是带来了新的功能,比如支持原生激活功能和数据转换、支持大语言模型的嵌入标记化等。架构方面,本代也就是第4代NPU的规模更大,包括12个增强的Shave DSP以及6个神经网络引擎,带宽翻倍,MAC架构优化等,带来了整体性能的大幅度提升。

英特尔总结到,Lunar Lake目前最高可以提供120TOPS的算力,可以完成大量AI计算,包括文生图、大模型本地化运行等。在越来越多的软件内置AI功能的现在,本地AI计算依旧是非常重要的,这一点英特尔也是顺应时代进行的操作。
超高能效比的新一代高性能AI移动处理器
由于文章篇幅有限,在本文中简单总结一下Lunar Lake的特性,给大家展示了相关的重点。如果各位想对Lunar Lake有更深入的认识和了解的话,请关注《微型计算机》2024年7月上刊,其中将详细地为大家介绍Lunar Lake的技术架构细节。

最后,还是针对Lunar Lake的发布以及附于其上的技术应用进行一些小结。Lunar Lake是英特尔在进入Chiplet时代后的一次全面革新,整个Lunar Lake无论是P核心还是E核心,包括GPU、NPU以及互联性能等都进行了全面变化和提升,带来了大量的全新技术,支持更多的新规格。毫不夸张的说,本次Lunar Lake新技术应用之多、之复杂远超之前任何一款产品。英特尔近几年在技术演进上的进展还是极为激进的,无论是上一代Meteor Lake还是本代Lunar Lake,在架构设计、技术应用以及整体规格上正在全面转向,Lunar Lake实际产品也就是酷睿Ultra 200系列上市后的表现令人期待。
Panther Lake 处理器架构细节
英特尔在2025年10月中旬公布了代号 Panther Lake 的新一代客户端处理器英特尔酷睿 Ultra 处理器(第三代)的架构细节,该产品预计将于2025年晚些时候开始出货。Panther Lake 是英特尔首款基于 Intel 18A 制程工艺打造的产品,这一制程是英特尔研发并制造的最先进的半导体工艺。另外还预览了英特尔至强 6+(代号 Clearwater Forest),其首款基于 Intel 18A 的服务器处理器,预计将于 2026 年上半年推出。Panther Lake 和 Clearwater Forest,以及基于 Intel 18A 制程的多代产品,正在位于亚利桑那州钱德勒市的英特尔全新尖端工厂 Fab 52 进行生产。
英特尔酷睿 Ultra 处理器(第三代)是首款基于 Intel 18A 制程工艺打造的客户端系统级芯片(SoC),将为广泛的消费级与商用 AI PC、游戏设备以及边缘计算解决方案提供算力支持。Panther Lake 引入了可扩展的多芯粒(multi-chiplet)架构,将在不同外形规格、市场细分和价格区间,为合作伙伴提供前所未有的灵活性。
亮点包括:
具备 Lunar Lake 级别的能效与 Arrow Lake 级别的性能。
最多配备 16 个全新性能核(P-core)与能效核(E-core),相比上一代 CPU 性能提升超过 50%。
全新英特尔锐炫 GPU,最多配备 12 个 Xe 核心,图形性能相比上一代提升超过 50%。
均衡的 XPU 设计以实现全新水平的 AI 加速,平台 AI 性能最高可达 180 TOPS(每秒万亿次运算)。
除了 PC 领域,Panther Lake 还将扩展至包括机器人在内的边缘应用。Panther Lake 将于今年开始进入大规模量产,首款 SKU 预计在年底前出货,并于 2026 年 1 月实现广泛的市场供应。
Clearwater Forest 是英特尔下一代能效核处理器,即英特尔至强 6+。这款处理器基于 Intel 18A 制程工艺,是现阶段英特尔效率超高的服务器处理器。英特尔计划在 2026 年上半年推出至强 6+。产品亮点如下:
最多可配备 288 个能效核。
相比上一代,每周期指令数(IPC)提升 17%。
在密度、吞吐量和能效方面实现显著提升。
Clearwater Forest 专为超大规模数据中心、云服务提供商和电信运营商打造,帮助企业扩展工作负载、降低能源成本,并驱动更智能的服务。
Intel 18A 是英特尔开发和制造的首个 2 纳米级别制程节点,与 Intel 3 制程工艺 5 相比,其每瓦性能提升高达 15%,芯片密度提升约 30%。该节点在英特尔位于俄勒冈州的基地完成研发、制造验证并进入早期生产阶段,目前正加速在亚利桑那州实现大规模量产。Intel 18A 的关键创新包括:
RibbonFET:这是英特尔十多年来推出的首个全新晶体管架构,能够实现更大规模与更高效的开关控制,从而显著提升性能并改善能效。
PowerVia:突破性的背面供电系统,优化电力传输与信号传递。
此外,英特尔的先进封装与 3D 芯片堆叠技术 Foveros,可将多个芯粒(chiplet)堆叠并集成到先进的 SoC 设计中,在系统层面提供灵活性、可扩展性与性能优势。
公告还称 Intel 18A 制程将作为核心技术平台,支撑英特尔未来至少三代客户端与服务器产品的研发与生产。