 本文是从Go的产品主页分离出来的,专门用于该软件的更新记录,截止到2029年12月31日。Go语言起源于2007年的Google;创始人有三位,分别是Ken Thompson、Rob Pike、Robert Griesemer;他们可谓是大佬中的大佬。最初的构想是新语言能够匹配未来硬件发展趋势、适合开发大规模网络服务程序、程序员能够更加专注业务逻辑的开发。Ian Lance Tyalor 和 Russ Cox是Go核心开发团队的第四、五位成员。于2009年正式对外公布,2012年1.0版本正式发布。2012年到2015年是Go语言的筑底成长期;从实现自引导的Go1.5版本开始,到Go 1.9版本,业界对Go的期望先是提升到峰值接着又开始跌落;随着Go 1.11版本引入Go Module,包依赖问题得到很好的解决,Go进入稳步爬升阶段。
本文是从Go的产品主页分离出来的,专门用于该软件的更新记录,截止到2029年12月31日。Go语言起源于2007年的Google;创始人有三位,分别是Ken Thompson、Rob Pike、Robert Griesemer;他们可谓是大佬中的大佬。最初的构想是新语言能够匹配未来硬件发展趋势、适合开发大规模网络服务程序、程序员能够更加专注业务逻辑的开发。Ian Lance Tyalor 和 Russ Cox是Go核心开发团队的第四、五位成员。于2009年正式对外公布,2012年1.0版本正式发布。2012年到2015年是Go语言的筑底成长期;从实现自引导的Go1.5版本开始,到Go 1.9版本,业界对Go的期望先是提升到峰值接着又开始跌落;随着Go 1.11版本引入Go Module,包依赖问题得到很好的解决,Go进入稳步爬升阶段。《版本发布历史》
一. Go 语言的发展
1.1 Go 语言是如何诞生的
Go 语言的创始人有三位,分别是图灵奖获得者、C 语法联合发明人、Unix 之父肯·汤普森(Ken Thompson),Plan 9 操作系统领导者、UTF-8 编码的最初设计者罗伯·派克(Rob Pike),以及 Java 的 HotSpot 虚拟机和 Chrome 浏览器的 JavaScript V8 引擎的设计者之一罗伯特·格瑞史莫(Robert Griesemer)。
他们可能都没有想到,他们三个人在2007年9月20日下午的一次普通讨论,就这么成为了计算机编程语言领域的一次著名历史事件,开启了一个新编程语言的历史。

那天下午,在谷歌山景城总部的那间办公室里,罗伯·派克启动了一个 C++ 工程的编译构建。按照以往的经验判断,这次构建大约需要一个小时。利用这段时间,罗伯·派克和罗伯特·格瑞史莫、肯·汤普森坐在一处,交换了关于设计一门新编程语言的想法。
之所以有这种想法,是因为当时的谷歌内部主要使用 C++ 语言构建各种系统,但 C++ 的巨大复杂性、编译构建速度慢以及在编写服务端程序时对并发支持的不足,让三位大佬觉得十分不便,他们就想着设计一门新的语言。在他们的初步构想中,这门新语言应该是能够给程序员带来快乐、匹配未来硬件发展趋势并适合用来开发谷歌内部大规模网络服务程序的。
在第一天的简短讨论后,第二天这三位大佬又在谷歌总部的“雅温得(Yaounde)”会议室里具体讨论了这门新语言的设计。会后罗伯特·格瑞史莫发出了一封题为“prog lang discussion”的电邮,对这门新编程语言的功能特性做了初步的归纳总结:
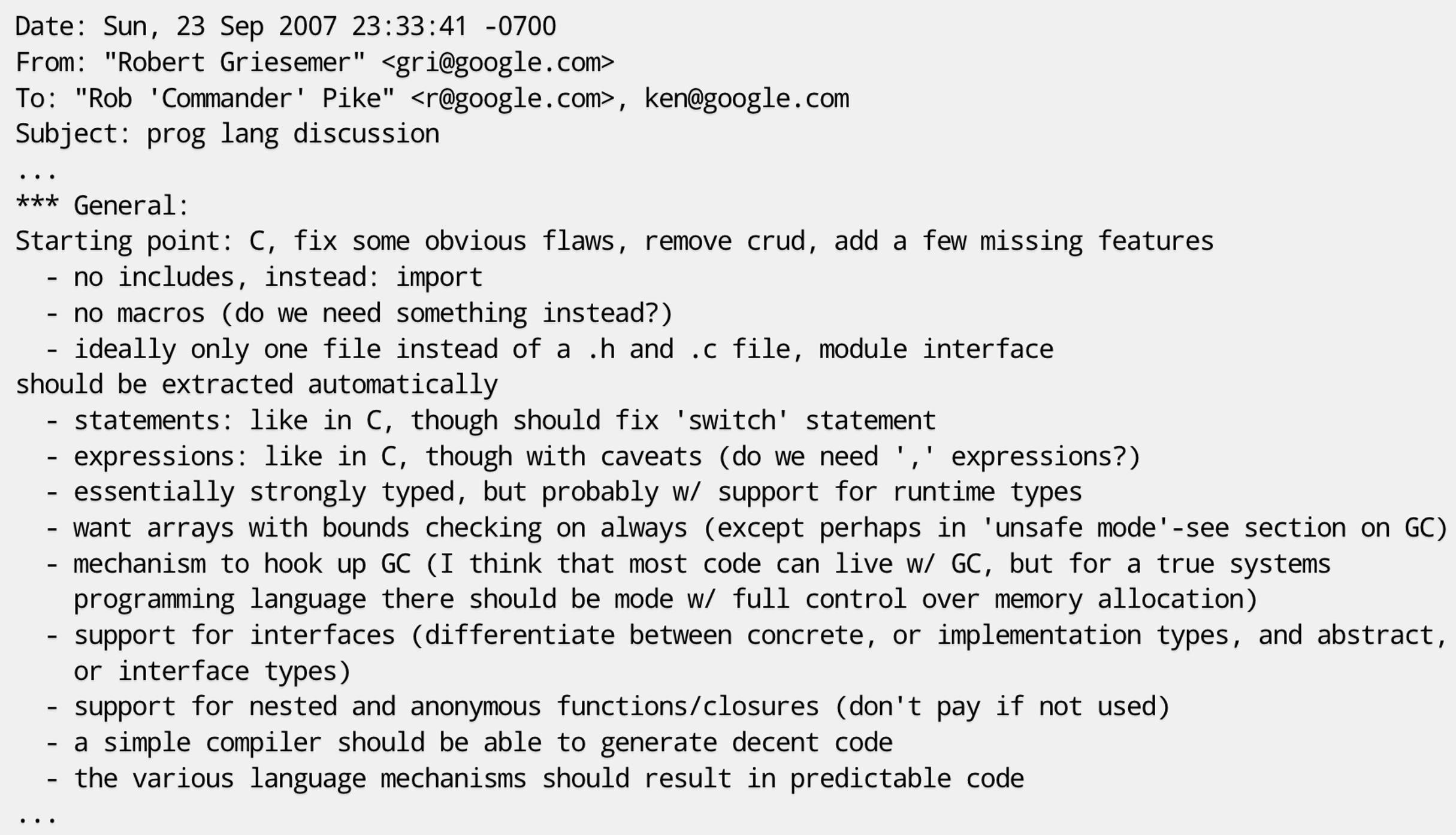
这封电邮对这门新编程语言的功能特性做了归纳总结。主要思路是,在 C 语言的基础上,修正一些明显的缺陷,删除一些被诟病较多的特性,增加一些缺失的功能,比如:
使用import替代include。
去掉宏(macro)。
理想情况是用一个源文件替代.h和.c文件,模块的接口应该被自动提取出来(而无须手动在.h文件中声明)。
语句像C语言一样,但需要修正switch语句的缺陷。
表达式像C语言一样,但有一些注意事项(比如是否需要逗号表达式)。
基本上是强类型的,但可能需要支持运行时类型。
数组应该总是有边界检查。
具备垃圾回收的机制。
支持接口(interface)。
支持嵌套和匿名函数/闭包。
一个简单的编译器。
各种语言机制应该能产生可预测的代码。
这封电邮成为了这门新语言的第一版特性设计稿,三位大佬在这门语言的一些基础语法特性上达成了初步一致。2007年 9 月 25 日,罗伯·派克在一封回复电邮中把这门新编程语言命名为“go”。
在罗伯·派克的心目中,“go”这个单词短小、容易输入并且在组合其他字母后便可以用来命名 Go 相关的工具,比如编译器(goc)、汇编器(goa)、链接器(gol)等(go 的早期版本曾如此命名 go 工具链,但后续版本撤销了这种命名方式,仅保留 go 这一统一的工具链名称 )。
这里有个误区,很多 Go 语言初学者经常称这门语言为 Golang,其实这是不对的:“Golang”仅应用于命名 Go 语言官方网站,而且当时没有用 go.com 纯粹是这个域名被迪士尼公司占用了而已。
1.2 Go语言的早期团队和演进历程
经过早期讨论,Go语言的三位作者在语言设计上达成初步一致,之后便开启了Go语言迭代设计和实现的过程。2008年年初,Unix之父Ken Thompson实现了第一版Go编译器,用于验证之前的设计。这个编译器先将Go代码转换为C代码,再由C编译器编译成二进制文件。到2008年年中,Go的第一版设计基本结束了。这时,同样在谷歌工作的Ian Lance Taylor为Go语言实现了一个GCC的前端,这也是Go语言的第二个编译器。Ian Lance Taylor的这一成果让三位作者十分喜悦,也很震惊。因为这对Go项目来说不仅仅是鼓励,更是一种对语言可行性的证明。Go语言的这第二个实现对确定语言规范和标准库是至关重要的。
随后,Ian Lance Taylor以第四位成员的身份正式加入Go语言开发团队,并在后面的Go语言发展进程中成为Go语言及工具设计和实现的核心人物之一。Russ Cox也是在2008年加入刚成立不久的Go语言开发团队的,他是Go核心开发团队的第五位成员,他的一些天赋随即在Go语言设计和实现中展现出来。Russ Cox利用函数类型也可以拥有自己的方法这个特性巧妙设计出了http包的HandlerFunc类型,这样通过显式转型即可让一个普通函数成为满足http.Handler接口的类型。Russ Cox还在当时设计的基础上提出了一些更通用的想法,比如奠定了Go语言I/O结构模型的io.Reader和io.Writer接口。在Ken Thompson和Rob Pike先后淡出Go语言核心决策层后,Russ Cox正式接过两位大佬的衣钵,成为Go核心技术团队的负责人。到这里,Go 最初的核心团队形成,Go 语言迈上了稳定演化的道路。
1.3 Go语言正式发布并开源
2009年10月30日,罗伯·派克在 Google Techtalk 上做了一次有关 Go 语言的演讲“The Go Programming Language”,这也是 Go 语言第一次公之于众。十天后的2009年11月10日,谷歌官方宣布 Go 语言项目开源,之后这一天也被 Go 官方确定为 Go 语言的诞生日。
Go语言项目的主代码仓库位于go.googlesource.com/go。最初Go语言项目在code.google.com上建立了镜像仓库,几年后镜像仓库迁移到了GitHub上。
开源后的Go语言吸引了全世界开发者的目光。再加上Go的三位作者在业界的影响力以及谷歌的加持,越来越多有才华的程序员加入Go开发团队,越来越多贡献者开始为Go语言项目添砖加瓦。于是,Go在发布的当年(2009年)就成为著名编程语言排行榜TIOBE的年度最佳编程语言。
在Go开源后,一些技术公司,尤其是云计算领域的大厂以及初创公司,成为Go语言的早期接纳者。经过若干年的磨合,在这些公司中诞生了众多“杀手级”或示范性项目,如容器引擎Docker、云原生事实标准平台Kubernetes、服务网格Istio、区块链公链以太坊(Ethereum)、联盟链超级账本(Hyperledger Fabric)、分布式关系型数据库TiDB和CockroachDB、云原生监控系统Prometheus等。这些项目也让Go被誉为“云计算基础设施编程语言”。Go在近些年云原生领域的广泛应用也让其跻身云原生时代的头部编程语言。
在 Go 语言项目开源后,Go 语言也迎来了自己的“吉祥物”,是一只由罗伯·派克夫人芮妮·弗伦奇(Renee French)设计的地鼠,从此地鼠(gopher)也就成为了世界各地 Go 程序员的象征,Go 程序员也被昵称为 Gopher。

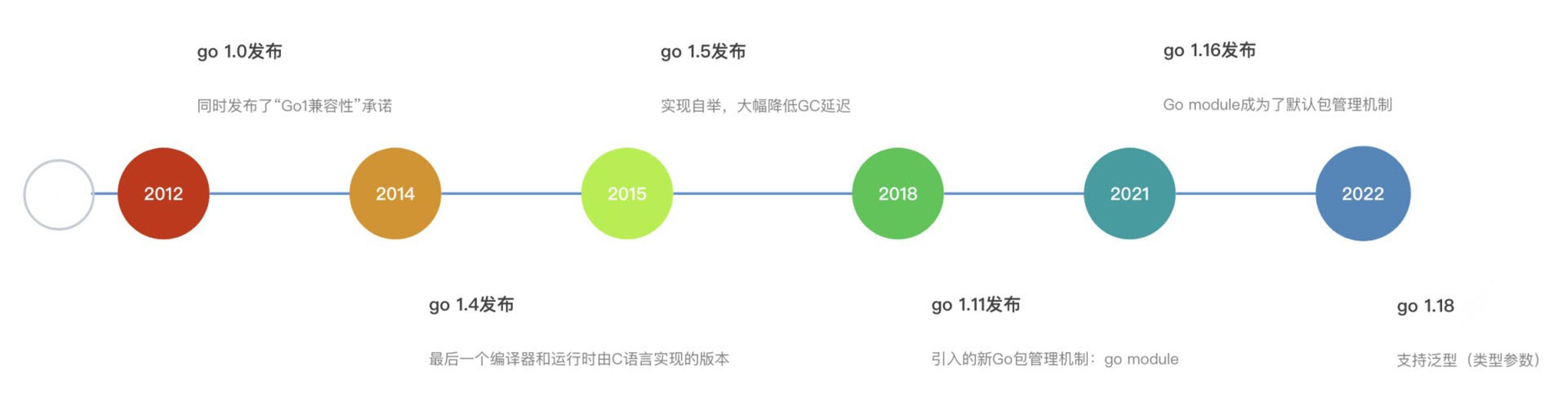
1.4 Go 语言的版本发展历史
2012年3月28日,Go 1.0 版本正式发布,同时 Go 官方发布了“Go 1 兼容性”承诺:只要符合 Go 1 语言规范的源代码,Go 编译器将保证向后兼容(backwards compatible),也就是说我们使用新版编译器也可以正确编译用老版本语法编写的代码。
2009年11月10日,Go语言正式对外发布并开源。之后Go语言在一段时间内采用了Weekly Release的模式,即每周发布一个版本。目前我们在Go语言的GitHub官方仓库中仍能找到早期的Weekly Release版本,比如weekly.2009-11-06。Go语言的版本发布历史如下。
从2011年3月7日开始,除了Weekly Release,Go项目还会每月发布一次,即Monthly Release,比如release.r56,这种情况一直延续到Go 1.0版本发布之前。2012年3月28日,Go 1.0正式发布。同时Go官方发布了“Go1兼容性”承诺:只要符合Go1语言规范的源代码,Go编译器将保证向后兼容(backwards compatible),即使用新版编译器可以正确编译使用老版本语法编写的代码。
2013年5月13日,Go 1.1版本发布,其主要的变动点如下:
新增method value语法:允许将方法绑定到一个特定的方法接收者(receiver)实例上,从而形成一个函数(function)。引入“终止语句”(terminating statement)的概念。将int类型在64位平台上的内部表示的字节数升为8字节,即64比特。更为精确的堆垃圾回收器(Heap GC),尤其是针对32位平台。
2013年12月1日,Go 1.2版本发布。从Go 1.2开始,Go开发组启动了以每6个月为一个发布周期的发布计划。Go 1.2版本的主要变动点包括:增加全切片表达式(Full slice expression):a[low: high: max];实现了在部分场景下支持抢占的goroutine调度器(利用在函数入口插入的调度器代码);go test新增-cover标志,用于计算测试覆盖率。
2014年6月18日,Go 1.3版本发布,其主要的变动点包括:支持更多平台,如Solaris、Dragonfly、Plan 9和NaCl等;goroutine的栈模型从分段栈(segmented stack)改为了连续栈(contiguous stack),改善Hot stack split问题;更为精确的栈垃圾回收器(Stack GC)。
2014年12月10日,Go 1.4版本发布。Go 1.4也是最后一个编译器和运行时由C语言实现的版本。其主要的变动点包括:新增for range x {…}形式的for-range语法;使用Go语言替换运行时的部分C语言实现,这使GC变得全面精确;由于连续栈的应用,goroutine的默认栈大小从8kB减小为2kB;增加internal package机制;增加canonical import path机制;新增go generate子命令,用于辅助实现代码生成;删除Go源码树中的src/pkg/xxx中的pkg这一级别,直接使用src/xxx。
2015年8月19日,Go 1.5版本发布。v1.5是Go语言历史上的一个具有里程碑意义的重要版本。因为从这个版本开始,Go实现了自举,即无须再依赖C编译器。然而Go编译器的性能比Go 1.4的C实现有了较大幅度的下降。其主要的变动点包括:Go编译器和运行时全部使用Go重写,原先的C代码实现被彻底移除;跨平台编译Go程序更为简洁,只需设置两个环境变量——GOARCH和GOOS即可;支持map类型字面量(literal);GOMAXPROCS的初始默认值由1改为运行环境的CPU核数;大幅度优化GC延迟,在多数情况下GC停止世界(Stop The World)的时间短于10ms;增加vendor机制,改善Go包依赖管理;增加go tool trace子命令;go build增加-buildmode命令选项,支持将Go代码编译为共享库(shared library)的形式。
2016年2月17日,Go 1.6版本发布,其主要的变动点包括:进一步优化GC延迟,实现Go程序在占用大内存的情况下,其GC延迟时间仍短于10ms;自动支持HTTP/2;定义了在C代码中共享Go指针的规则。
2016年8月15日,Go 1.7版本发布,其主要的变动点包括:针对x86-64实现了SSA后端,使得编译出的二进制文件大小减小20%~30%,而运行效率提升5%~35%;Go编译器的性能比Go 1.6版本提升近一倍;go test支持subtests和sub-benchmarks;标准库新增context包。
2017年2月16日,Go 1.8版本发布,其主要的变动点包括:支持在仅tags不同的两个struct之间进行显式类型转换;标准库增加sort.Slice函数;支持HTTP/2 Push机制;支持HTTP Server优雅退出;增加了对Mutex和RWMutex的profiling(剖析)支持;支持Go plugins,增加plugin包;支持默认的GOPATH路径($HOME/go),无须再显式设置;进一步优化SSA后端代码,程序平均性能提升10%左右;Go编译器性能进一步提升,平均编译链接的性能提升幅度在15%左右;GC的延迟进一步降低,GC停止世界(Stop The World)的时间通常不超过100μs,甚至不超过10μs;优化defer的实现,使得其性能损耗降低了一半。
2017年8月25日,Go 1.9版本发布,其主要的变动点包括:新增了type alias语法;在原来支持包级别的并发编译的基础上实现了包函数级别的并发编译,使得Go编译性能有10%左右的提升;大内存对象分配性能得到显著提升;增加了对单调时钟(monotonic clock)的支持;提供了一个支持并发的Map类型——sync.Map;增加math/bits包,将高性能位操作实现收入标准库。
2018年2月17日,Go 1.10版本发布,其主要的变动点包括:支持默认GOROOT,开发者无须显式设置GOROOT环境变量;增加GOTMPDIR环境变量;通过cache大幅提升构建和go test执行的性能,并基于源文件内容是否变化判定是否使用cache中的结果;支持Unicode 10.0版本。
2018年8月25日,Go 1.11版本发布。Go 1.11是Russ Cox在GopherCon 2017大会上发表题为“Toward Go 2”的演讲之后的第一个Go版本,它与Go 1.5版本一样也是具有里程碑意义的版本,因为它引入了新的Go包管理机制:Go module。Go module在Go 1.11中的落地为后续Go 2相关提议的渐进落地奠定了良好的基础。该版本主要的变动点包括:引入Go module,为Go包依赖管理提供了创新性的解决方案;引入对WebAssembly的支持,让Gopher可以使用Go语言来开发Web应用;为调试器增加了一个新的实验功能——允许在调试过程中动态调用Go函数。
2019年2月25日,Go 1.12版本发布,其主要的变动点包括:对Go 1.11版本中增加的Go module机制做了进一步优化;增加对TLS 1.3的支持;优化了存在大量堆内存(heap)时GC清理环节(sweep)的性能,使得一次GC后的内存分配延迟得以改善;运行时更加积极地将释放的内存归还给操作系统,以应对大块内存分配无法重用已存在堆空间的问题;该版本中Build cache默认开启并成为必需功能。
2019年9月4日,Go 1.13版本发布,其主要的变动点包括:增加以0b或0B开头的二进制数字字面量形式(如0b111)。增加以0o或0O开头的八进制数字字面量形式(如0o700)。增加以0x或0X开头的十六进制浮点数字面量形式(如0x123.86p+2)。支持在数字字面量中通过数字分隔符“_”提高可读性(如a := 5_3_7)。取消了移位操作(>>和<<)的右操作数只能是无符号数的限制。继续对Go module机制进行优化,包括:当GO111MODULE=auto时,无论是在 G O P A T H / s r c 下还是 GOPATH/src下还是 GOPATH/src下还是GOPATH之外的仓库中,只要目录下有go.mod,Go编译器就会使用Go module来管理依赖;GOPROXY支持配置多个代理,默认值为https://proxy.golang.org,direct;提供了GOPRIVATE变量,用于指示哪些仓库下的module是私有的,即既不需要通过GOPROXY下载,也不需要通过GOSUMDB去验证其校验和。Go错误处理改善:在标准库中增加errors.Is和errors.As函数来解决错误值(error value)的比较判定问题,增加errors.Unwrap函数来解决error的展开(unwrap)问题。defer性能提升30%。支持的Unicode标准从10.0版本升级到Unicode 11.0版本。
2020年2月26日,Go 1.14版本发布,其主要的变动点包括:嵌入接口的方法集可重叠;基于系统信号机制实现了异步抢占式的goroutine调度;defer性能得以继续优化,理论上有30%的性能提升;Go module已经生产就绪,并支持subversion源码仓库;重新实现了运行时的timer;testing包的T和B类型都增加了自己的Cleanup方法。
2020年8月12日,Go 1.15版本发布,其主要的变动点包括:GOPROXY环境变量支持以管道符为分隔符的代理值列表;module的本地缓存路径可通过GOMODCACHE环境变量配置;运行时优化,将小整数([0, 255])转换为interface类型值时将不会额外分配内存;支持更为现代化的新版链接器,在Go 1.15版本中,新版链接器的性能相比老版本可提高20%,内存占用减少30%;增加tzdata包,可以用于操作附加到二进制文件中的时区信息。
2021年2月18日,Go 1.16版本发布,其主要的变动点包括:支持苹果的M1芯片(通过darwin/arm64组合);Go module-aware模式成为默认构建模式,即GO111MODULE值默认为on;go build/run命令不再自动更新go.mod和go.sum文件;go.mod中增加retract指示符以支持指示作废module的某个特定版本;引入GOVCS环境变量,控制获取module源码所使用的版本控制工具;GODEBUG环境变量支持跟踪包init函数的消耗;Go链接器得到进一步的现代化改造,相比于Go 1.15版本的链接器,新链接器的性能有20%25%的提升,资源占用下降5%15%,更为直观的是,编译出的二进制文件大小下降10%以上;新增io/fs包,建立Go原生文件系统抽象;新增embed包,作为在二进制文件中嵌入静态资源文件的官方方案。
2022年8月17日,Go 1.17版本发布,其主要的变动点包括:增加了slice对象直接强制类型转换为数组指针的能力;在unsafe包中新增Add和Slice函数。
2022年2月25日,Go 1.18版本发布,其主要的变动点包括:支持泛型;引入泛型后,容器(containers)包被拆分为sync、container/list等多个包;编译器和运行时改进,提升性能;crypto/tls支持TLS 1.3;net/http Client和Server实现HTTP/2和HTTP/3;新增net/http/httptrace标准化追踪HTTP请求。
2022年8月11日,Go 1.19版本发布,其主要的变动点包括:增强错误处理,通过error unwrapping等方式改善错误传递;crypto/rsa新增PSS padding模式;testing包新增测试步骤(T.Step);运行时优化,缩减程序大小;调度器优化,提升性能;支持在iOS和Android上交叉编译;各方面细节改进和bug修复。
2023年2月1日,Go 1.20版本发布,其主要的四个变化包括:支持直接切片转换成数组,增加转换的便利性;comparable约束放宽,允许更灵活的接口类型作为泛型参数;unsafe包新增语法糖函数,处理底层指针更便利;工具链优化升级,编译器引入PGO技术,安装包瘦身等。
2023年8月8日,Go 1.21版本发布,其主要的变动点包括:新增min、max、clear等内置函数,增强语言表达能力;改进了类型推断,增强了泛型支持;工具链增强了兼容性支持;标准库新增slices、maps、slog等包;保持与旧版本的高度兼容性。
总之,Go 语言发展得非常迅猛,从正式开源到现在,十二年的时间过去了,Go 语言发布了多个大版本更新,逐渐成熟。这里梳理了迄今为止 Go 语言的重大版本更新,希望能帮助你快速了解 Go 语言的演化历史。
Go开发团队发布的Go语言稳定版本的平均质量一直是很高的,少有影响使用的重大bug。Go开发团队一直建议大家使用最新的发布版。
二. GO语言介绍
2.0 Go 语言原则
Go语言在设计之初就确定了三大原则:

简洁性(Simplicity):Go语言的语法简单直白,结构清晰。语法规则少,容易学习和使用。同时去掉了C++中未使用的复杂功能,就是让你用Python代码的开发效率编写C语言程序代码。
可读性(Readability):Go语言追求代码的简洁和可读性。通过格式化标准,命名规范等使代码易于阅读和理解。
功能性(Usability):Go语言注重软件工程中的可用性。内置并发、垃圾回收等功能让开发者可以高效编写软件。还提供了完善的标准库和工具。
2.1 为什么需要 Go 语言?
Go语言的设计目标之一是解决以下这些问题,提供更好的解决方案。以下是一些其他编程语言常见的弊端:
性能问题:一些高级编程语言可能在性能方面受到限制,因为它们的抽象层次较高,导致运行时性能不如低级语言。Go通过编译型语言的特性和并发性能优势来解决这个问题。
依赖管理:一些编程语言,尤其是C和C++,在管理依赖关系和外部库时可能面临复杂性。Go引入了Go module机制,用于更有效地管理依赖关系,解决了这个问题。
笨重:某些编程语言可能过于复杂,有大量的语法和特性,这可能使学习和使用变得困难。Go的设计目标之一是保持简洁和清晰,降低学习曲线。
垃圾回收和并行计算:对于一些系统编程语言,如C和C++,垃圾回收和并行计算等基础功能可能缺乏内置支持,需要开发者手动处理。Go通过内置垃圾回收和goroutine等机制来简化这些任务。
多核支持:在多核计算机上利用所有核心的能力是一项挑战。Go的goroutine和channel机制使并发编程变得更加容易,允许开发者有效地利用多核处理器。
2.2 Go 设计哲学
Go 语言的设计者们在语言设计之初,就拒绝了走语言特性融合的道路,选择了“做减法”并致力于打造一门简单的编程语言。
2.2.1 简单
Go 语法层面上呈现了这样的状态:
仅有 25 个关键字,主流编程语言最少;
内置垃圾收集,降低开发人员内存管理的心智负担;
首字母大小写决定可见性,无需通过额外关键字修饰;
变量初始为类型零值,避免以随机值作为初值的问题;
内置数组边界检查,极大减少越界访问带来的安全隐患;
内置并发支持,简化并发程序设计;
内置接口类型,为组合的设计哲学奠定基础;
原生提供完善的工具链,开箱即用;
Go 不会像 C++、Java 那样将其他编程语言的新特性兼蓄并收,所以你在 Go 语言中看不到传统的面向对象的类、构造函数与继承,看不到结构化的异常处理,也看不到本属于函数编程范式的语法元素。
2.2.2 显式
在 Go 语言中,不同类型变量是不能在一起进行混合计算的,这是因为 Go 希望开发人员明确知道自己在做什么,因此你需要以显式的方式通过转型统一参与计算各个变量的类型。
变量 a、b 和 c 的类型均不相同,使用Go编译程序会得到什么呢?
package main
import "fmt"
func main() {
var a int16 = 5
var b int = 8
var c int64
c = a + b
fmt.Printf("%d\n", c)
}
如果我们编译这段程序,将得到类似这样的编译器错误:“invalid operation: a + b (mismatched types int16 and int)”。
除此之外,Go 设计者所崇尚的显式哲学还直接决定了 Go 语言错误处理的形态:Go 语言采用了显式的基于值比较的错误处理方案,函数/方法中的错误都会通过 return 语句显式地返回,并且通常调用者不能忽略对返回的错误的处理。
这种有悖于“主流语言潮流”的错误处理机制还一度让开发者诟病,社区也提出了多个新错误处理方案,但或多或少都包含隐式的成分,都被 Go 开发团队一一否决了,这也与显式的设计哲学不无关系。
2.2.3 组合
在 Go 语言设计层面,Go 设计者为开发者们提供了正交的语法元素,以供后续组合使用,包括:
语言无类型层次体系,各类型之间是相互独立的,没有子类型的概念;
每个类型都可以有自己的方法集合,类型定义与方法实现是正交独立的;
实现某个接口时,无需像 Java 那样采用特定关键字修饰;
包之间是相对独立的,没有子包的概念。
无论是包、接口还是一个个具体的类型定义,Go 语言其实是为我们呈现了这样的一幅图景:一座座没有关联的“孤岛”,但每个岛内又都很精彩。那么现在摆在面前的工作,就是在这些孤岛之间以最适当的方式建立关联,并形成一个整体。而 Go 选择采用的组合方式,也是最主要的方式。
Go 语言为支撑组合的设计提供了类型嵌入(Type Embedding)。通过类型嵌入,我们可以将已经实现的功能嵌入到新类型中,以快速满足新类型的功能需求,这种方式有些类似经典面向对象语言中的“继承”机制,但在原理上却与面向对象中的继承完全不同,这是一种 Go 设计者们精心设计的“语法糖”。
被嵌入的类型和新类型两者之间没有任何关系,甚至相互完全不知道对方的存在,更没有经典面向对象语言中的那种父类、子类的关系,以及向上、向下转型(Type Casting)。通过新类型实例调用方法时,方法的匹配主要取决于方法名字,而不是类型。这种组合方式,我称之为垂直组合,即通过类型嵌入,快速让一个新类型“复用”其他类型已经实现的能力,实现功能的垂直扩展。
比如下面这个 Go 标准库中的一段使用类型嵌入的组合方式的代码段:
// $GOROOT/src/sync/pool.go
type poolLocal struct {
private interface{}
shared []interface{}
Mutex
pad [128]byte
}
在代码段中,在 poolLocal 这个结构体类型中嵌入了类型 Mutex,这就使得 poolLocal 这个类型具有了互斥同步的能力,可以通过 poolLocal 类型的变量,直接调用Mutex类型的方法 Lock 或 Unlock。另外在标准库中还会经常看到类似如下定义接口类型的代码段:
// $GOROOT/src/io/io.go
type ReadWriter interface {
Reader
Writer
}
这里,标准库通过嵌入接口类型的方式来实现接口行为的聚合,组成大接口,这种方式在标准库中尤为常用,并且已经成为了 Go 语言的一种惯用法。
垂直组合本质上是一种“能力继承”,采用嵌入方式定义的新类型继承了嵌入类型的能力。Go 还有一种常见的组合方式,叫水平组合。和垂直组合的能力继承不同,水平组合是一种能力委托(Delegate),我们通常使用接口类型来实现水平组合。
Go语言中的接口是一个创新设计,它只是方法集合,并且它与实现者之间的关系无需通过显式关键字修饰,它让程序内部各部分之间的耦合降至最低,同时它也是连接程序各个部分之间“纽带”。
水平组合的模式有很多,比如一种常见方法就是,通过接受接口类型参数的普通函数进行组合,如以下代码段所示
// $GOROOT/src/io/ioutil/ioutil.go
func ReadAll(r io.Reader)([]byte, error)
// $GOROOT/src/io/io.go
func Copy(dst Writer, src Reader)(written int64, err error)
也就是说,函数 ReadAll 通过 io.Reader 这个接口,将 io.Reader 的实现与 ReadAll 所在的包低耦合地水平组合在一起了,从而达到从任意实现 io.Reader 的数据源读取所有数据的目的。类似的水平组合“模式”还有点缀器、中间件等,这里我就不展开了,在后面讲到接口类型时再详细叙述。
此外还可以将 Go 语言内置的并发能力进行灵活组合以实现,比如通过 goroutine+channel 的组合,可以实现类似 Unix Pipe 的能力。
总之,组合原则的应用实质上是塑造了 Go 程序的骨架结构。类型嵌入为类型提供了垂直扩展能力,而接口是水平组合的关键,它好比程序肌体上的“关节”,给予连接“关节”的两个部分各自“自由活动”的能力,而整体上又实现了某种功能。并且,组合也让遵循“简单”原则的 Go 语言,在表现力上丝毫不逊色于其他复杂的主流编程语言。
2.2.4 并发
“并发”这个设计哲学的出现有它的背景,你也知道 CPU 都是靠提高主频来改进性能的,但是现在这个做法已经遇到了瓶颈。主频提高导致 CPU 的功耗和发热量剧增,反过来制约了 CPU 性能的进一步提高。2007 年开始,处理器厂商的竞争焦点从主频转向了多核。
在这种大背景下,Go 的设计者在决定去创建一门新语言的时候,果断将面向多核、原生支持并发作为了新语言的设计原则之一。并且,Go 放弃了传统的基于操作系统线程的并发模型,而采用了用户层轻量级线程,Go 将之称为 goroutine。
goroutine 占用的资源非常小,Go 运行时默认为每个 goroutine 分配的栈空间仅 2KB。其调度的切换也不用陷入(trap)操作系统内核层完成,代价很低。因此,一个 Go 程序中可以创建成千上万个并发的 goroutine。而且,所有的 Go 代码都在 goroutine 中执行,哪怕是 go 运行时的代码也不例外。
在提供了开销较低的 goroutine 的同时,Go 还在语言层面内置了辅助并发设计的原语:channel 和 select。开发者可以通过语言内置的 channel 传递消息或实现同步,并通过 select 实现多路 channel 的并发控制。相较于传统复杂的线程并发模型,Go 对并发的原生支持将大大降低开发人员在开发并发程序时的心智负担。
此外,并发的设计哲学不仅仅让 Go 在语法层面提供了并发原语支持,其对 Go 应用程序设计的影响更为重要。并发是一种程序结构设计的方法,它使得并行成为可能。
采用并发方案设计的程序在单核处理器上也是可以正常运行的,也许在单核上的处理性能可能不如非并发方案。但随着处理器核数的增多,并发方案可以自然地提高处理性能。
而且,并发与组合的哲学是一脉相承的,并发是一个更大的组合的概念,它在程序设计的全局层面对程序进行拆解组合,再映射到程序执行层面上:goroutines 各自执行特定的工作,通过 channel+select 将 goroutines 组合连接起来。并发的存在鼓励程序员在程序设计时进行独立计算的分解,而对并发的原生支持让 Go 语言也更适应现代计算环境。
2.2.5 面向工程
Go 语言设计的初衷,就是面向解决真实世界中 Google 内部大规模软件开发存在的各种问题,为这些问题提供答案,这些问题包括:程序构建慢、依赖管理失控、代码难于理解、跨语言构建难等。
很多编程语言设计者和他们的粉丝们认为这些问题并不是一门编程语言应该去解决的,但 Go 语言的设计者并不这么看,他们在 Go 语言最初设计阶段就将解决工程问题作为 Go 的设计原则之一去考虑 Go 语法、工具链与标准库的设计,这也是 Go 与其他偏学院派、偏研究型的编程语言在设计思路上的一个重大差异。
语法是编程语言的用户接口,它直接影响开发人员对于这门语言的使用体验。在面向工程设计哲学的驱使下,Go 在语法设计细节上做了精心的打磨。比如:
重新设计编译单元和目标文件格式,实现 Go 源码快速构建,让大工程的构建时间缩短到类似动态语言的交互式解释的编译速度;
如果源文件导入它不使用的包,则程序将无法编译。这可以充分保证任何 Go 程序的依赖树是精确的。这也可以保证在构建程序时不会编译额外的代码,从而最大限度地缩短编译时间;
去除包的循环依赖,循环依赖会在大规模的代码中引发问题,因为它们要求编译器同时处理更大的源文件集,这会减慢增量构建;
包路径是唯一的,而包名不必唯一的。导入路径必须唯一标识要导入的包,而名称只是包的使用者如何引用其内容的约定。“包名称不必是唯一的”这个约定,大大降低了开发人员给包起唯一名字的心智负担;
故意不支持默认函数参数。因为在规模工程中,很多开发者利用默认函数参数机制,向函数添加过多的参数以弥补函数 API 的设计缺陷,这会导致函数拥有太多的参数,降低清晰度和可读性;
增加类型别名(type alias),支持大规模代码库的重构。
在标准库方面,Go 被称为“自带电池”的编程语言。如果说一门编程语言是“自带电池”,则说明这门语言标准库功能丰富,多数功能不需要依赖外部的第三方包或库,Go 语言恰恰就是这类编程语言。
由于诞生年代较晚,而且目标比较明确,Go 在标准库中提供了各类高质量且性能优良的功能包,其中的 net/http、crypto、encoding 等包充分迎合了云原生时代的关于 API/RPC Web 服务的构建需求,Go 开发者可以直接基于标准库提供的这些包实现一个满足生产要求的 API 服务,从而减少对外部第三方包或库的依赖,降低工程代码依赖管理的复杂性,也降低了开发人员学习第三方库的心理负担。
而且,开发人员在工程过程中肯定是需要使用工具的,Go 语言就提供了足以让所有其它主流语言开发人员羡慕的工具链,工具链涵盖了编译构建、代码格式化、包依赖管理、静态代码检查、测试、文档生成与查看、性能剖析、语言服务器、运行时程序跟踪等方方面面。
这里值得重点介绍的是 gofmt ,它统一了 Go 语言的代码风格,在其他语言开发者还在为代码风格争论不休的时候,Go 开发者可以更加专注于领域业务中。同时,相同的代码风格让以往困扰开发者的代码阅读、理解和评审工作变得容易了很多,至少 Go 开发者再也不会有那种因代码风格的不同而产生的陌生感。Go 的这种统一代码风格思路也在开始影响着后续新编程语言的设计,并且一些现有的主流编程语言也在借鉴 Go 的一些设计。
在提供丰富的工具链的同时,Go 在标准库中提供了官方的词法分析器、语法解析器和类型检查器相关包,开发者可以基于这些包快速构建并扩展 Go 工具链。
三. Go 语言的特性
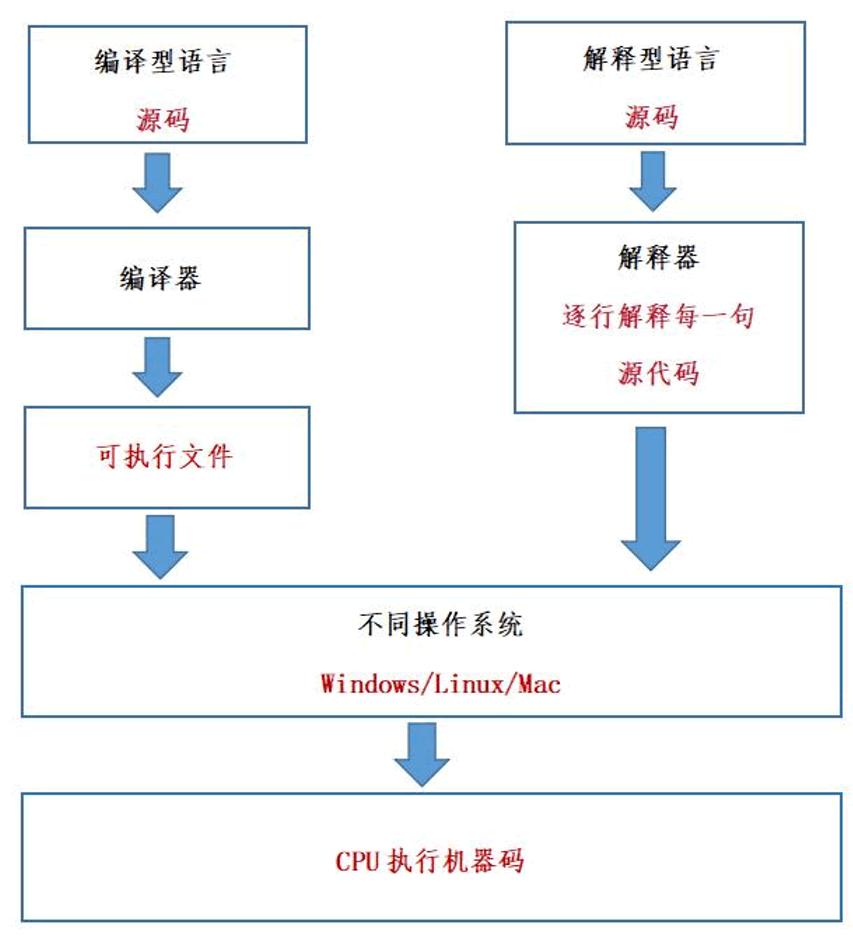
3.1 编译型语言和解释型语言
编译型语言:
编译过程:在编译型语言中,源代码在运行之前必须通过编译器转换为机器码或虚拟机字节码。编译过程将整个程序翻译成一个可执行文件,该文件可以在目标计算机上独立运行。
执行速度:由于编译型语言的代码在运行前已经经过编译,因此它们通常具有很高的执行速度,因为机器可以直接执行编译后的代码,而无需解释。
开发迭代:在编译型语言中,如果需要对程序进行更改,通常需要重新编译整个程序,这可能会导致开发迭代速度较慢。
示例语言:C、C++、Go、Rust等都是编译型语言的示例。
解释型语言:
解释过程:在解释型语言中,源代码由解释器逐行解释执行,而不是先编译成机器码。解释器读取源代码的一行,执行它,然后再读取下一行。
执行速度:解释型语言通常比编译型语言执行速度较慢,因为代码需要在运行时逐行解释,而不是直接执行编译后的机器码。
开发迭代:解释型语言通常具有更快的开发迭代速度,因为开发者可以更轻松地修改和测试代码,无需重新编译整个程序。
示例语言:Python、JavaScript、Ruby、PHP等都是解释型语言的示例。
解释型语言和编译型语言
3.2 优点
Go 语言是一个可以编译高效,支持高并发的,面向垃圾回收的跨平台编译型全新语言。
秒级完成大型程序的单节点编译。
依赖管理清晰。
不支持继承,程序员无需花费精力定义不同类型之间的关系。
支持垃圾回收,支持并发执行,支持多线程通讯。
对多核计算机支持友好。
3.3 缺点:Go 语言不支持的特性
不支持函数重载和操作符重载
为了避免在 C/C++ 开发中的一些 Bug 和混乱,不支持隐式转换
支持接口抽象,支持面向对象和面向过程的编程模式,不支持继承
不支持动态加载代码
不支持动态链接库
通过 recover 和 panic 来替代异常机制
不支持断言
不支持静态变量
静态强类型语言:Go是一门静态类型语言,这意味着变量的类型在编译时已经确定,开发者需要在声明变量时指定其类型,且不允许在运行时将不同类型的值直接进行运算。这提供了类型安全性和代码可维护性,可以捕获潜在的类型错误。
编译型语言:Go是一门编译型语言,它的源代码需要通过编译器转换为机器码或虚拟机字节码,然后才能在目标平台上执行。这使得Go程序在运行时能够获得较高的性能,因为它不需要在每次运行时解释源代码。
3.4 Go语言为并发而生
硬件制造商正在为处理器添加越来越多的内核以提高性能。所有数据中心都在这些处理器上运行,更重要的是,今天的应用程序使用多个微服务来维护数据库连接,消息队列和维护缓存。因此,开发的软件和编程语言应该可以轻松地支持并发性,并且应该能够随着CPU核心数量的增加而可扩展。
但大多数现代编程语言(如Java,Python等)都来自90年代的单线程环境。虽然一些编程语言的框架在不断地提高多核资源使用效率,例如 Java 的 Netty 等,但仍然需要开发人员花费大量的时间和精力搞懂这些框架的运行原理后才能熟练掌握。
Go于2009年发布,当时多核处理器已经上市。Go语言在多核并发上拥有原生的设计优势,Go语言从底层原生支持并发,无须第三方库、开发者的编程技巧和开发经验。很多公司,特别是中国的互联网公司,即将或者已经完成了使用 Go 语言改造旧系统的过程。经过 Go 语言重构的系统能使用更少的硬件资源获得更高的并发和I/O吞吐表现。充分挖掘硬件设备的潜力也满足当前精细化运营的市场大环境。
Go语言的并发是基于 goroutine 的,其类似于线程,但并非线程。可以将 goroutine 理解为一种虚拟线程。Go 语言运行时会参与调度 goroutine,并将它合理地分配到每个 CPU 中,最大限度地使用CPU性能。开启一个goroutine的消耗非常小(大约2KB的内存),可以轻松创建数百万个goroutine。
goroutine的特点:
具有可增长的分段堆栈,只在需要时才会使用更多内存。
启动时间比线程快。
原生支持利用channel安全地进行通信。
共享数据结构时无需使用互斥锁。
3.5 Go性能强悍
与其他现代高级语言(如Java/Python)相比,使用C,C++的最大好处是它们的性能。因为C/C++是编译型语言而不是解释的语言。处理器只能理解二进制文件,Java和Python这种高级语言在运行的时候需要先将人类可读的代码翻译成字节码,然后由专门的解释器再转变成处理器可以理解的二进制文件。

同C/C++一样,Go语言也是编译型的语言,它直接将人类可读的代码编译成了处理器可以直接运行的二进制文件,执行效率更高,性能更好。
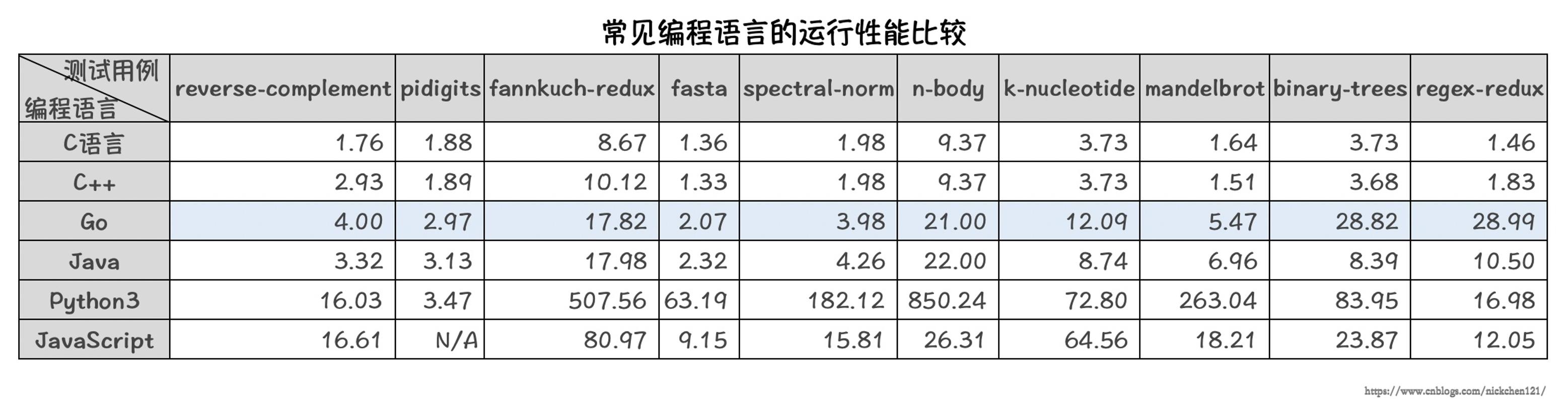
数据来源benchmarksgame。
可以看出,Go 语言在性能上更接近于 Java 语言,虽然在某些测试用例上不如经过多年优化的 Java 语言,但毕竟 Java 语言已经经历了多年的积累和优化。Go 语言在未来的版本中会通过不断的版本优化提高单核运行性能。
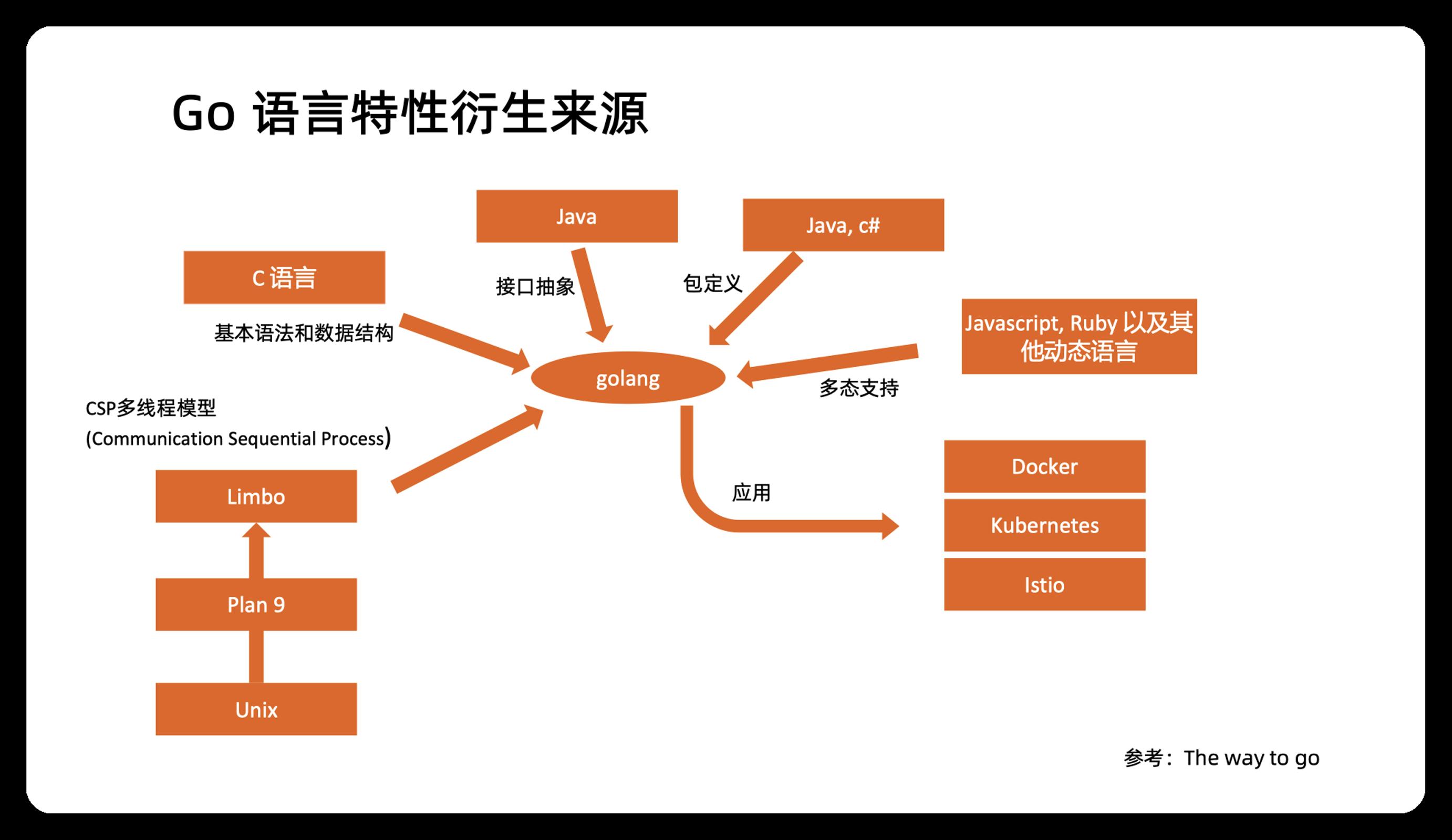
3.6 Go 语言特性衍生来源
3.7 Go语言命名
命名规则
Go的函数、变量、常量、自定义类型、包(package)的命名方式遵循以下规则:
首字符可以是任意的Unicode字符或者下划线
剩余字符可以是Unicode字符、下划线、数字
字符长度不限
Go 只有25个关键字
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
Go 还有37个保留字
Constants: true false iota nil
Types: int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
Functions: make len cap new append copy close delete
complex real imag panic recover
可见性:
声明在函数内部,是函数的本地值,类似private
声明在函数外部,是对当前包可见(包内所有.go文件都可见)的全局值,类似protect
声明在函数外部且首字母大写是所有包可见的全局值,类似public
最新版本:1.5
和很多主流语言一样,Go语言编译器最初都是由C语言和汇编语言实现的。C语言和汇编实现的Go编译器(记作A)用来编译Go源文件。那么是否可以用Go语言自身实现一个Go编译器B,用编译器A来编译Go编译器B工程的源码并链接成最终的Go编译器B呢?这就是Go核心团队在Go 1.5版本时做的事情。
他们将绝大多数原来用C和汇编编写的Go编译器以及运行时实现改为使用Go语言编写,并用Go 1.4.x编译器(C与汇编实现的,相当于A)编译出Go 1.5编译器。这样自Go 1.5版本开始,Go编译器就是用Go语言实现的了,这就是所谓的自举。即用要编译的目标编程 语言(Go语言)编写其(Go)编译器。
这之后,Go核心团队基本就告别C代码了,可以专心写Go代码了。这可以让Go核心团队积累更为丰富的Go语言编码经验;同时Go语言自身就是站在C语言等的肩膀上,修正了C语言等的缺陷并加入创新机制而形成的,用Go编码效率高,还可 避面C语言的很多坑。 在这个基础上,使用Go语言实现编译器和runtime还利于Go编译器以及运行时的优化,Go 1.5及后续版本GC延迟大幅降低以及性能的大幅提升都说明了这一点。这就是自举的重要之处。
最新版本:1.6
该版本在语言本身层面并没有任何变化,主要改进包括:
默认使用 cgo 外部 C 编译器
支持 HTTP/2 协议
增加对 64 位 MIPS 的体验支持(Linux)
增加对 32 位 x86 上的 Android 的体验支持
在 FreeBSD 上 go 1.6 默认使用 clang 而不是 gcc 作为外部 C 编译器
在 64 位 PowerPC 上 支持 cgo
NaCI 上 GO 1.5 要求 SDK 版本是 pepper-41,而 Go 1.6 可以使用最新的 SDK 版本
在 32 位 x86 系统中使用 --dynlink 或者 --shared 编译模式,寄存器 CX 被特定内存引用覆盖,可通过编写汇编指令来更改这个行为。
Go 1.6 的改进非常多,详细介绍请看此处。
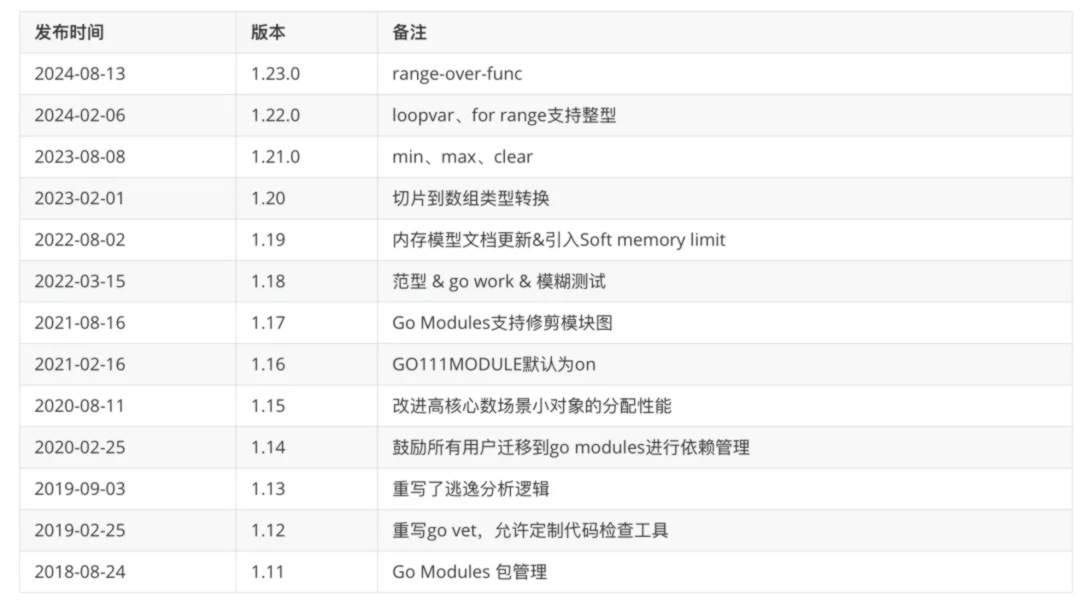
Go语言每年发布两次升级版本,二月和八月。1.11版本之后Go发布的版本如下:
Go1.13 数字表示法
二进制整数:前缀 0b 或 0B 表示二进制整数文字,例如 0b1011。
八进制整数:前缀 0o 或 0O 表示八进制整数文字,例如 0o660。 由前导 0 后跟八进制数字表示的现有八进制表示法仍然有效。
十六进制浮点值:前缀 0x 或 0X 现在可用于表示十六进制格式的浮点数的尾数,例如 0x1.0p-1021。 十六进制浮点数必须始终有一个指数,写为字母 p 或 P 后跟一个十进制指数。
虚数文字:虚数后缀 i 现在可以与任何(二进制、十进制、十六进制)整数或浮点数文字一起使用。
数字分隔符:现在可以使用下划线分隔(分组)任何数字文字的数字,例如 1_000_000、0b_1010_0110 或 3.1415_9265。 下划线可以出现在任何两个数字之间或文字前缀和第一个数字之间。
Go 1.13 移除了计数必须是无符号的限制。此更改消除了许多在使用<< 和 >> 运算符时需要额外转换成uint的必要。
Go1.14 允许嵌入具有重叠方法集的接口
这个迭代可以简单说是实现了方法的重写(C++/Java中的说法)能力。
Go1.15 增加包time/tzdata
1.15 包含一个新包 time/tzdata,它允许将时区数据库嵌入到程序中。导入此包(如 import _ "time/tzdata")允许程序查找时区信息,即使时区数据库在本地系统上不可用。还可以通过使用 -tags timetzdata 构建来嵌入时区数据库。
Go1.16 支持二进制嵌入文件
go 命令现在支持使用新的 //go:embed 指令将静态文件和文件树作为最终可执行文件的一部分。它可以将文件嵌入 Go 代码中,从而方便地在程序中访问这些文件。
Go1.17 允许切片转为数组指针
从切片到数组指针的转换:[]T 类型的表达式 s 现在可以转换为数组指针类型 *[N]T, 假设 a 是转换的结果,如果 len(s) 小于 N。则在范围内的相应索引会引用到相同的底层元素:for 0 <= i < N &a[i] == &s[i] 。如果切片的长度小于数组的长度,就会发生运行时panic。
事实证明在切片元素增加后,对转换后的元素无影响。在开发中,如果我们是切片类型数据,在调用函数需要使用固定长度的数组或数组指针,可以使用这个特性进行转换,以避免在转换过程中发生数据复制,从而提高了程序的性能。此外,将切片转换为数组或数组指针还可以使代码更加简洁和易于理解。1.17版本语言特性除了以上所述,还有其他几点:
unsafe.Add:unsafe.Add(ptr, len) 将 len 添加到 ptr 并返回更新后的指针 unsafe.Pointer(uintptr(ptr) + uintptr(len))。
unsafe.Slice:对于 *T 类型的表达式 ptr,unsafe.Slice(ptr, len) 返回一个 []T 类型的切片,其底层数组从 ptr 开始,长度和容量为 len。
最新版本:1.18
距离 Go 1.17 发布七个月后,Go 1.18 正式于2022年3月中旬正式发布,1.18 是一个包含大量新功能的版本,包括对语言本身做了有史以来最大的改变(泛型)、工具链的实现、运行时和库的更改,还改善了性能。与往常一样,该版本保持了 Go 1的兼容性承诺:几乎所有 Go 程序都能像以前一样继续编译和运行。下面来看一下新版本的一些重大特性:
泛型
以下是关于 Go 1.18 泛型的最明显变化的列表,如需更全面的概述请参阅泛型提案,更详细信息请参阅语言规范。
函数和类型声明的语法,现在接受类型参数。
参数化函数和类型可以通过在方括号中列出类型参数来实例化。
新标记~已添加到操作符和标点符号中。
接口类型的语法现在允许嵌入任意类型(不仅仅是接口的类型名称)以及 union 和 ~T 类型元素。,这样的接口只能用作类型约束。
新的预声明标识符 any是空接口的别名,可以用来代替 interface{}。
新的预声明标识符 comparable是一个接口,表示可以使用==或者 != 比较的所有类型的集合,它只能用作(或嵌入)类型约束。
有三个使用泛型的实验包可能有用,这些包在 x/exp 存储库中;但它们的 API 不在 Go 1 兼容性承诺的保证范围内:
golang.org/x/exp/constraints:对通用代码有用的约束,例如 constraints.Ordered.
golang.org/x/exp/slices:对任何元素类型的切片进行操作的通用函数集合。
golang.org/x/exp/maps:对任何键或元素类型的映射进行操作的通用函数集合。
当前的泛型实现具有以下已知限制:
Go 编译器无法处理泛型函数或方法中的类型声明,计划在 Go 1.19 中取消这个限制。
Go 编译器不接受具有预声明函数 real、imag 和 complex 的参数类型的参数,计划在 Go 1.19 中取消这个限制。
如果 m 由 P 的约束接口显式声明,Go 编译器仅支持在类型参数类型 P 的值 x 上调用方法 m。 类似地,方法值 x.m 和方法表达式 P.m 也仅在 m 由 P 显式声明时才受支持,即使 m 可能在 P 的方法集中,因为 P 中的所有类型都实现了 m,计划在 Go 1.19 中取消这个限制。
Go 编译器不支持访问结构字段 x.f,其中 x 是类型参数类型,即使类型参数的类型集中的所有类型都具有字段 f,计划在 Go 1.19 中取消这个限制。
不允许将类型参数或指向类型参数的指针作为结构类型中的未命名字段嵌入,同样地,也不允许在接口类型中嵌入类型参数。
具有多个 term 的 union 元素可能不包含具有非空方法集的接口类型。
泛型代表 Go 生态系统的巨大变化,虽然官方更新了几个支持泛型的核心工具,但还有很多工作要做。剩余的工具、文档和库需要一些时间才能赶上这些语言变化。此外在官方公告中还有这么一段话:可能会有一些使用泛型的代码可以在 1.18 版本中使用,但在以后的版本中会中断。不计划或期望做出任何此类更改,但由于我们今天无法预见的原因,可能需要在未来版本中破坏 1.18 的程序。鼓励在有意义的地方使用泛型,但在生产环境中部署泛型代码时,请谨慎行事(虽然泛型是搞出来了,但很可能有 Bug,不建议在生产中使用)。
模糊测试:Go 1.18 包括 fuzzing(模糊测试) 的实现,如 fuzzing 提案所述,详情请参阅 fuzzing 教程以开始使用。注意,模糊测试会消耗大量内存,并且可能会影响机器运行时的性能。另请注意,模糊引擎在运行时会将扩展测试覆盖率的值写入模糊缓存目录 $GOCACHE/fuzz。目前对可以写入模糊缓存的文件数量或总字节数没有限制,因此可能会占用大量存储空间(可能为 GB 级别)。
编译器:现在编译器可以内联包含范围循环或标记为循环的函数。类型检查器被完全替换以支持泛型,一些错误消息可能使用与以前不同的措辞(提供更多详细信息,或以更有用的方式表述)。由于与支持泛型相关的编译器的更改,Go 1.18 的编译速度可能比 Go 1.17 的编译速度慢大约 15%,代码的执行时间不受影响,目前计划在 Go 1.19 中提高编译器的速度。
错误修正:Go 1.18 编译器可以正确地报告在函数文本中设置但从未使用过的变量的错误(已声明但未使用),解决了一个老问题 issue #8560 。现在在将如 '1' << 32 之类的符文常量表达式作为参数传递给预声明函数 print 和 println 时会报告溢出。
Ports
AMD64:Go 1.18 引入了新的GOAMD64环境变量,它在编译时选择 AMD64 架构的最低目标版本,允许的值为v1、 v2、v3或v4,默认是v1。
RISC-V:Linux 上的 64 位 RISC-V 架构(linux/riscv64 端口)现在支持 c-archive 和 c-shared 构建模式。
Linux:Go 1.18 需要 Linux 内核版本 2.6.32 或更高版本。
Windows:windows/arm 和 windows/arm64 端在支持非合作抢占,有希望解决在调用 Win32 函数时遇到的一些细微的 bug,这些bug在很长一段时间内会阻塞。
iOS:在 iOS(ios/arm64 端口)和在基于 AMD64 的 macOS(ios/amd64 端口)上运行的 iOS 模拟器上,Go 1.18 现在需要 iOS 12 或更高版本; 已停止支持以前的版本。
FreeBSD:Go 1.18 是支持 FreeBSD 11.x 的最后一个版本,Go 1.19 需要 FreeBSD 12.2+ 或 FreeBSD 13.0+。
性能提升:由于 Go1.17 中寄存器 ABI 调用约定扩展到了 RM64 / Apple M1 / PowerPC 64 架构,因此 Go1.18 对这几个架构包含了高达 20% 的 CPU 性能提升。
Go 1.18 版本还包含其他大量更新项,完整更新列表请在发行公告中查看。
Go1.19 内存模型和atomic包
Go 的内存模型现在明确定义了 sync/atomic 包的行为。 happens-before 关系的正式定义已经过修改,以与 C、C++、Java、JavaScript、Rust 和 Swift 使用的内存模型保持一致。现有程序不受影响,随着内存模型的更新,sync/atomic 包中有新的类型,例如 atomic.Int64 和 atomic.Pointer[T],可以更轻松地使用原子值。
新的atomic类型
sync/atomic 包定义了新的原子类型 Bool、Int32、Int64、Uint32、Uint64、Uintptr 和 Pointer。这些类型隐藏了底层值,因此所有访问都被迫使用原子 API。Pointer 还避免了在调用站点转换为 unsafe.Pointer 的需要。Int64 和 Uint64 自动对齐到结构和分配数据中的 64 位边界,即使在 32 位系统上也是如此。1.19版本在语言特性上变更比较少,更多的是在内存模型和GC上,在内存模型和GC上有很大的优化。
最新版本:1.20
继 Go 1.19 发布6个月之后,Go 1.20 已于2023年2月上旬正式发布,该版本的大部分更改都集中在在工具链、运行时和库的实现中。1.20 是最后一个可以在任何版本的 Windows 7、8、Server 2008 和 Server 2012 上运行的版本,Go 1.21 将至少需要 Windows 10 或 Server 2016。且 Go 1.20 是最后一个支持在 macOS 10.13 High Sierra 或 10.14 Mojave 上运行的版本,Go 1.21 将需要 macOS 10.15 Catalina 或更高版本。此外,Go 1.20 还添加了对 RISC-V 上的 FreeBSD (GOOS=freebsd, GOARCH=riscv64) 的实验性支持。在语法方面包含了 4 项变化:
1.Go 1.7 增加了从 slice (切片)到数组指针转换的功能,Go 1.20 对该功能进行了扩展 —— 可直接从 slice 转换成数组。比如给定一个 slicex,[4]byte(x) 可以写成 *(*[4]byte)(x)。
2.标准库 unsafe 包定义了 3 个新函数:SliceData,String 和 StringData。与 Go 1.17 的 Slice 一起,这些函数现在提供了构建和解构 slice 和字符串值的完整功能,而不依赖于它们的精确表示。
3.Go 语言规范进行了更新,定义结构体变量的值每次只比较一个字段,字段比较的顺序和字段在结构体里定义的顺序保持一致。一旦某个字段的值比较出现不一致,就会马上停止比较。
4.Comparable 类型(例如普通接口 ordinary interfaces)现在可以满足 comparable 约束,即便类型实参 (type argument) 不是严格可比较类型。
一些其他更新内容还包括:
$GOROOT/pkg 目录不再存储标准存档的预编译包存档,以减少 Go 发行版的大小。
go 命令现在定义架构功能 build flags,如 amd64.V2,以允许根据特定 CPU 架构功能的存在或不存在来选择包实现文件。这对于 x86_64 微架构特性级别的工作来说是个好消息。
go build 和 go install 以及其他与构建相关的命令现在支持 “-cover” flag,用于启用带有 code coverage instrumentation 的构建。
由于在垃圾收集器上的工作,内存开销减少和 CPU 性能提高高达 2%。
对 Profile Guided Optimizations (PGO) 的预览支持。
在 Linux 上,linker 现在在链接时为 glibc 或 musl 选择动态解释器。
一个新的 crypto/ecdh 包,为 NIST curves 和 Curve25519 上的 Elliptic Curve Diffie-Hellman 密钥交换提供明确支持。
更多详情可查看官方公告。1.20版本在语言特性上变更也比较少,更多的是在编译器和链接器的优化。Go 1.18 和 1.19 的构建速度有所下降,这主要是由于增加了对泛型的支持和后续工作。1.20 将构建速度提高了 10%,使其与 Go 1.17 保持一致;相对于 Go 1.19,生成的代码性能也普遍略有提升。
最新版本:1.21
Go 1.21版本大部分变化集中在工具链、运行时和库的实现。该版本保持了 Go 1 的兼容性承诺并有所改进。开发团队希望几乎所有 Go 程序都能像以前一样继续编译和运行。此外对版本编号进行了一个小更改。过去使用 Go 1.N 来指代整个 Go 语言版本和版本系列,以及该系列中的第一个版本。从 Go 1.21 开始,第一个版本现在是 Go 1.N.0。2023年8月上旬发布的是 Go 1.21 语言及其初始实现 Go 1.21.0 release。像 go version 这样的工具会将版本号显示为 "go1.21.0"。有关新版本编号的详细信息,请参阅"Go Toolchains" 文档中的 "Go versions"。
改进工具链
配置文件引导优化 (PGO) 功能正式 GA。在 1.20 中处于预览阶段的启用配置文件引导优化 (PGO) 功能现已正式 GA。如果主软件包目录中存在名为 default.pgo 的文件,go 命令将使用它来启用 PGO 构建。Profile-guided optimization (PGO) 是计算机编程中的一种编译器优化技术,翻译过来是使用配置文件引导的优化。PGO 也被称为:
Profile-directed feedback (PDF)
Feedback-directed optimization (FDO)
其原理是编译器使用程序的运行时 profiling 信息,生成更高质量的代码,从而提高程序的性能。PGO 作为一项通用的编译器优化技术,不局限于某一门语言。比如 Rust 编译器也在探索使用 PGO,微软则采用 LTO+PGO 来优化 Linux 内核。在 Go 语言中,最初关于 PGO 的提案是建议向 Go GC 工具链增加对配置文件引导优化 (PGO) 的支持,以便工具链能根据运行时信息执行特定于应用程序和工作负载的优化。开发团队测试了 PGO 对多种 Go 程序的影响,发现性能提高了 2-7%。更多详细信息查看 PGO 文档。
语言变更
添加新的内置函数:min, max 和 clear
对泛型函数的类型推断进行了多项改进,包括扩展和解释清楚规范中类型推断的描述
在未来版本中,开发团队计划解决 Go 编程中最常见的问题之一:循环变量捕获 (loop variable capture)。1.21 附带了此功能的预览版,目前可以使用环境变量在代码中启用该功能。
添加新的标准库
log/slog 包:用于结构化日志记录
slices 包:增用于对任何元素类型的切片进行常见操作,这个包比 sort 包更快、更符合人体工程学
maps 包:用于对任何类型 key-value 进行常见操作
cmp 包:用于比较有序值 (ordered values)
优化性能
除了启用 PGO 时的性能改进之外:Go 编译器本身已经在 1.21 中启用 PGO 进行了重建,因此它构建 Go 程序的速度提高了 2-4%,具体取决于主机架构
由于垃圾收集器的调整,某些应用程序的尾部延迟可能会减少高达 40%
现在使用 runtime/trace 收集跟踪在 amd64 和 arm64 上产生的 CPU 开销要小得多
支持 WASI
Go 1.21 已实验性支持 WebAssembly System Interface (WASI), Preview 1 (GOOS=wasip1,GOARCH=wasm)。为了方便编写更通用的 WebAssembly (WASM) 代码,编译器还支持从 WASM 主机导入函数的新指令:go:wasmimport。
更多详情查看发行说明。
最新版本:1.22
1.22于2024年2月发布。
语言变化
长期存在的 "for" 循环在迭代之间意外共享循环变量的问题现已得到解决。从 1.22 开始,以下代码将按一定顺序打印 "a"、"b" 和 "c":
func main() {
done := make(chan bool)
values := []string{"a", "b", "c"}
for _, v := range values {
go func() {
fmt.Println(v)
done <- true
}()
}
// wait for all goroutines to complete before exiting
for _ = range values {
<-done
}
}
有关这一变更以及有助于防止代码意外中断的工具的更多信息,请参阅之前的《Fixing For Loops in Go 1.22》。第二个语言变化是支持整数范围:
package main
import "fmt"
func main() {
for i := range 10 {
fmt.Println(10 - i)
}
fmt.Println("go1.22 has lift-off!")
}
第二个语言变化是支持整数范围:a 在这个倒计时程序中,i 的取值范围为 0 至 9(含 9)。
性能提高:Go 运行时中的内存优化可将 CPU 性能提高 1-3%,同时还可将大多数 Go 程序的内存开销减少约 1%。在v1.21中,官方为 Go 编译器提供了配置文件引导优化 (PGO),而且这一功能还在不断改进。v1.22 中新增的优化之一是改进了虚拟化,允许静态调度更多的接口方法调用。启用 PGO 后,大多数程序的性能将提高 2% 至 14%。
标准库变动
新的 math/rand/v2 软件包提供了更简洁、更一致的应用程序接口,并使用了质量更高、速度更快的伪随机生成算法。
net/http.ServeMux 使用的模式现在可接受方法和通配符。例如:路由器接受 GET /task/{id}/ 这样的模式,该模式只匹配 GET 请求,并在一个可通过 Request 值访问的映射中捕获 {id} 段的值。
database/sql 包中新增了 Null [T] 类型,为扫描可为空的列提供了一种方法。
在 slices 包中添加了 Concat 函数,用于连接任意类型的多个片段。
v1.22是2024年的第一个版本。主要变化分布在工具链、运行时以及标准库,坚持“Go 1兼容性”承诺:只要符合Go 1语言规范的代码,Go编译器保证向前兼容。
语言改进
1.循环变量不再共享
Go v1.22 之前版本 for 循环声明的变量只创建一次,并在每次迭代中进行更新,这会导致遍历时访问 value 时实际上都是访问的同一个地址的值。循环体内编写并行代码容易踩坑。比如:
v1.22 之前版本的踩坑代码
// Go1.22之前版本的踩坑代码,Go1.22版本可以正常运行。
package main
import (
"fmt"
"sync"
)
func main() {
group := sync.WaitGroup{}
list := []string{"a", "b", "c", "d"}
for i, s := range list {
group.Add(1)
go func() {
defer group.Done()
fmt.Println(i, s) // 这里访问的都是同一个地址
}()
}
group.Wait()
}
v1.22之前版本的运行结果如下所示,不符合预期:
// Go1.22之前版本的运行结果,不符合预期
3 d
3 d
3 d
3 d
可以看到,上面代码输出都是同样。为了避免Go1.22之前版本的这个坑点,需要每次重新给for变量赋值,比如下面两种解决方法:
● 方法一:
// Go1.22之前版本的解决方法一
package main
import (
"fmt"
"sync"
)
func main() {
group := sync.WaitGroup{}
list := []string{"a", "b", "c", "d"}
for i, s := range list {
group.Add(1)
i, s := i, s // 重新赋值
go func() {
defer group.Done()
fmt.Println(i, s)
}()
}
group.Wait()
}
● 方法二:
// Go1.22之前版本的解决方法二
package main
import (
"fmt"
"sync"
)
func main() {
group := sync.WaitGroup{}
list := []string{"a", "b", "c", "d"}
for i, s := range list {
group.Add(1)
go func(i int, s string) {
defer group.Done()
fmt.Println(i, s)
}(i, s) // 作为参数传入
}
group.Wait()
}
这两种方式本质都是对 for 循环变量重新赋值。
而对于 v1.22 及之后的版本,for循环的每次迭代都会创建新变量,每次循环迭代各自的变量。从此再也不用担心循环内并发导致的问题。对于最初的踩坑代码,在 Go1.22 及之后版本运行的结果如下:
// Go1.22版本的运行结果
3 d
1 b
0 a
2 c
2.支持对整数进行循环迭代
在 Go v1.22 之前版本,for range 仅支持对 array、slice、string、map、以及 channel 类型进行迭代。如果希望循环 N 次执行,可能需要如下编写代码:
for i := 0; i < 10; i++ {
// do something
}
Go1.22 及之后版本,新增了对整数类型的迭代。如下示例,代码写起来更简洁。这里需要注意的是 range 的范围前闭后开 [0, N)。
for i := range 10 {
// do something
}
3.支持函数类型范围遍历
在 for range 支持整型表达式的时候,Go团队也考虑了增加函数迭代器(iterator),不过前者语义清晰,实现简单。后者展现形式、语义和实现都非常复杂,于是在 Go1.22 中,函数迭代器以试验特性提供,通过 GOEXPERIMENT=rangefunc 可以体验该功能特性。而在最新的 Go 1.23 版本中,已经正式支持此功能。目前支持的函数类型为:
type Seq[V any] func(yield func(V) bool)
type Seq2[K, V any] func(yield func(K, V) bool)
在我们开发代码过程中,经常会对自定义的 container 进行变量,比如下面的 Set:
// Set 保存一组元素。
type Set[E comparable] struct {
m map[E]struct{}
}
而在 Go1.22 之前的版本,我们要对 Set 中元素就行某种操作时,可能需要写如下函数:
func (s *Set[E]) Handle(f func(E) bool) {
for v := range s.m {
if !f(v) {
return
}
}
}
当需要打印 Set 中所有元素时,可能需要如下调用 Handle 函数:
s := Set[int]{m: make(map[int]struct{})}
s.Handle(func(e int) bool {
fmt.Println(e)
return true
})
而在 Go1.22 打开实验特性及 Go1.23 版本,可以支持如下写法:
s := Set[int]{m: make(map[int]struct{})}
for e := range s.Handle {
fmt.Println(e)
}
从实现层面看,其实 range func 是一个语法糖。对于新版的 Go,for range的迭代体在编译的时候会被改写成 func(e int) bool 形式,同时在函数的最后一行返回 true。
标准库
1.第一个v2标准库:math/rand/v2
变动原因:
● 标准库里math/rand存在较多的问题,包括:生成器版本过旧、算法性能不高,以及与 crypto/rand.Read 存在冲突等问题;
● Go 1要求保障兼容性,要解决上述问题无法直接对原库进行变更,需要把标准库升级到v2版本;
● 通过用 math/rand试水,为标准库升级到V2积累经验,例如:解决工具生态的问题(gopls、goimports 等工具对 v2 包的支持), 后续再对风险更高的包(如:sync/v2 或 encoding/json/v2)进行新版本迭代;
重要变更:
● 删除 Rand.Read 和顶层的 Read: 原因是由于math库和crypto的Read相近,导致本来该使用crypto/rand.Read的地方被误用了math/rand.Read,引入安全问题;
● 移除 Source.Seed、Rand.Seed 和顶层 Seed:它们假设底层随机数生成器(Source)采用 int64作为种子,这个假设不具有普适性,不适合定义为一个通用接口;
● 随机数生成器接口增加Uint64方法,替换Int63方法,这个变更更符合新的随机数生成器, 同时移除顶层Source64函数,原因是随机数生成器提供了Uint64方法;
● Float32和 Float64使用了更直接的实现方式:以 Float64 为例,之前版本的实现是 float64(r.Int63()) / (1<<63),它偶尔会出现四舍五入到 1.0的问题,现在的实现改成了 float64(r.Int63n(1<<53)) / (1<<53)来解决上面的问题;
● 使用 Rand.Shuffle 实现 Rand.Perm。Shuffle实现效率更高,这样可以确保只有一个实现;
● 将 Int31、Int31n、Int63、Int64n 函数更名为 Int32、Int32n、Int64、Int64n;
● 新增Uint32、Uint32N、Uint64、Uint64N、Uint、UintN顶层函数以及Rand方法;
● 在 N、IntN、UintN 等中使用 Lemire 算法。初步基准测试显示,与 v1 Int31n 相比节省了 40%,与 v1 Int63n 相比节省了 75%。
● 新增 PCG-DXSM(Permuted Congruential Generator) 和 ChaCha8 两种随机数生成器。删除 Mitchell & Reeds LFSR 生成器。
示例:
// 列举了部分math/rand库的使用
package main
import (
"fmt"
"math/rand/v2"
"os"
"strings"
"text/tabwriter"
"time"
)
func main() {
// 创建并设置生成器的种子。
// 通常应使用非固定的种子,例如 Uint64(), Uint64()。
// 使用固定种子会在每次运行时产生相同的输出。
r := rand.New(rand.NewPCG(rand.Uint64(), rand.Uint64()))
// Float32 和 Float64 的值在 [0, 1) 范围内。
w := tabwriter.NewWriter(os.Stdout, 1, 1, 1, ' ', 0)
defer w.Flush()
show := func(name string, v1, v2, v3 any) {
fmt.Fprintf(w, "%s\t%v\t%v\t%v\n", name, v1, v2, v3)
}
// Float32 和 Float64 的值在 [0, 1) 范围内。
show("Float32", r.Float32(), r.Float32(), r.Float32())
show("Float64", r.Float64(), r.Float64(), r.Float64())
// ExpFloat64 值的平均值为 1,但呈指数衰减。
show("ExpFloat64", r.ExpFloat64(), r.ExpFloat64(), r.ExpFloat64())
// NormFloat64 值的平均值为 0,标准差为 1。
show("NormFloat64", r.NormFloat64(), r.NormFloat64(), r.NormFloat64())
// Int32、Int64 和 Uint32 生成给定宽度的值。
show("Int32", r.Int32(), r.Int32(), r.Int32())
show("Int64", r.Int64(), r.Int64(), r.Int64())
show("Uint32", r.Uint32(), r.Uint32(), r.Uint32())
// IntN、Int32N 和 Int64N 将它们的输出限制为 < n。
// 它们比使用 r.Int()%n 更加小心。
show("IntN(10)", r.IntN(10), r.IntN(10), r.IntN(10))
show("Int32N(10)", r.Int32N(10), r.Int32N(10), r.Int32N(10))
show("Int64N(10)", r.Int64N(10), r.Int64N(10), r.Int64N(10))
// Perm 生成 [0, n) 范围内的随机排列。
show("Perm", r.Perm(5), r.Perm(5), r.Perm(5))
// 打印一个位于半开区间 [0, 100) 内的 int64。
fmt.Println("rand.N(): ", rand.N(int64(100)))
// 打印一个位于半开区间 [0, 100) 内的 uint32
fmt.Println("rand.N(): ", rand.N(uint32(100)))
// 睡眠一个在 0 到 100 毫秒之间的随机时间。
time.Sleep(rand.N(100 * time.Millisecond))
// Shuffle 使用默认的随机源对元素的顺序进行伪随机化
words := strings.Fields("ink runs from the corners of my mouth")
rand.Shuffle(len(words), func(i, j int) {
words[i], words[j] = words[j], words[i]
})
fmt.Println(words)
}
2.增强http.ServerMux路由能力
现有的多路复用器(http.ServeMux)只能提供基本的路径匹配,很多时候要借助于第三方库来完成实际需求的功能。Go 1.22基于提案《net/http: enhanced ServeMux routing》,增强了 http.ServerMux 的路由匹配能力,增加了对模式匹配、路径变量的支持。
●匹配方法
模式匹配将支持以 HTTP 方法开头,后跟空格,如 GET /eddycjy 或 GET eddycjy.com/ 中。带有方法的模式仅用于匹配具有该方法的请求。对照到代码中,也就是 Go1.22 起,代码可以这么写:
mux.HandleFunc("POST /eddycjy/create", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "hello world")
})
mux.HandleFunc("GET /eddycjy/update", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, "hello world")
})
●通配符
模式匹配将支持 {name} 或 {name...},例如:/b/{bucket}/o/{objectname...}。该名称必须是有效的 Go 标识符和符合完整路径元素的标准。它们前面必须有斜杠,后面必须有斜杠或字符串末尾。例如:/b_{bucket} 不是有效的通配模式。Go1.22 起,http.ServeMux 可以这么写:
mux.HandleFunc("/items/{id}", func(w http.ResponseWriter, r *http.Request) {
id := r.PathValue("id")
fmt.Fprintf(w, "id 值为 %s", id)
})
mux.HandleFunc("/items/{path...}", func(w http.ResponseWriter, r *http.Request) {
path := r.PathValue("path")
fmt.Fprintf(w, "path 值为 %s", path)
})
通常,通配符仅匹配单个路径元素,以请求URL中的下一个斜杠结束。如果...存在,则通配符与URL路径的其余部分匹配,包括斜杠。
○ /items/{id}: 正常情况下一个通配符只匹配一个路径段,比如匹配/items/123,但是不匹配/items/123/456。
○ /items/{path...}: 但是如果通配符后面跟着...,那么它就会匹配多个路径段,比如/items/123、/items/123/456都会匹配这个模式。
○ /items/{$}: 正常情况下以/结尾的模式会匹配所有以它为前缀的路径,比如/items/、/items/123、/items/123/456都会匹配这个模式, 但是如果以/{$}为后缀,那么表示严格匹配路径,不会匹配带后缀的路径,比如这个例子只会匹配/items/,不会匹配/items/123、/items/123/456。
●优先级
单一的优先规则:
○ 如果两个模式重叠(有一些共同的请求),那么更具体的模式优先:如果 P1 符合 P2 请求的一个(严格)子集,也就是说:如果 P2 符合 P1 的所有请求及更多请求,那么 P1 就比 P2 更具体
○ 如果两者都不更具体,那么模式就会发生冲突。 这条规则有一个例外:如果两个模式发生冲突,而其中一个有 HOST ,另一个没有,那么有 HOST 的模式优先
具体的例子:
example.com/ 比 / 更具体,因为第一个仅匹配主机 example.com 的请求,而第二个匹配任何请求。
GET / 比 / 更具体,因为第一个仅匹配 GET 和 HEAD 请求,而第二个匹配任何请求。
/b/{bucket}/o/default 比 /b/{bucket}/o/{noun} 更具体,因为第一个仅匹配第四个元素是文字 “default” 的路径,而在第二个中,第四个元素可以是任何内容。
3.新增go/version库
新增go/version库用于识别、校验go version的正确性,以及比较版本大小。功能比较简单,可直接参考函数签名:
// 返回 version x的go语言版本,比如x=go1.21rc2返回go版本为go1.21
func Lang(x string) string
// 校验版本的正确性
func IsValid(x string) bool
// 比较版本的大小: -1,0,1 分别代表 x < y, x == y, or x > y
// x,y必须是已go为前缀,比如go1.22,不能使用1.22
func Compare(x, y string) int
4.其他小变化
1.22中还包含了许多小更新,此处列举其中一些(小标题是库名)
archive/tar、archive/zip
两个库都新增了Writer.AddFS函数,允许将fs.FS对象打包,内部会对fs.FS进行遍历,打包时保持树状结构不变。
bufio
Scanner的SplitFunc函数在返回err为ErrFinalToken时,如果token为nil,之前会返回最后一个空的token再结束,现在会直接结束。如果需要返回空token再结束可以在返回ErrFinalToken时同时返回[]byte{}数组,而不是nil。举个例子:
package main
import (
"bufio"
"bytes"
"fmt"
)
// 自定义的SplitFunc函数,按空格分割输入,并在遇到"STOP"时停止扫描; 另外,为了和标准库函数对齐,采用了命名返回值
func splitBySpaceAndStop(data []byte, atEOF bool) (advance int, token []byte, err error) {
if i := bytes.IndexByte(data, ' '); i >= 0 {
// 找到空格,返回前面的数据作为token
token = data[:i]
advance = i + 1
// 如果token是"STOP",返回ErrFinalToken
if string(token) == "STOP" {
return 0, nil, bufio.ErrFinalToken
}
return advance, token, nil
}
// 如果到达输入末尾且有剩余数据,返回剩余数据作为token
if atEOF && len(data) > 0 {
return len(data), data, nil
}
return 0, nil, nil
}
func main() {
input := "apple banana cherry STOP date"
scanner := bufio.NewScanner(bytes.NewReader([]byte(input)))
scanner.Split(splitBySpaceAndStop) // 设置自定义的SplitFunc
// 扫描并打印每个token
for scanner.Scan() {
fmt.Printf("Token: %s\n", scanner.Text())
}
// 1.22以前会打印以下4个token,其中第4个为空字符串。而1.22则只会打印前3个token,如果也想打印4个token,则把return 0, nil, bufio.ErrFinalToken改为return 0, []byte{}, bufio.ErrFinalToken即可
// Token: apple
// Token: banana
// Token: cherry
// Token:
}
cmp
新增了Or函数,入参是comparable类型的一组参数,返回第一个非零值,如果入参全部是零值则返回零值。这个函数可以简化一些写法,例如:
xxxConfigValue := cmp.Or(remoteConfig.Get("config_key"), "default_config_value")
Or函数源码如下:
// Or returns the first of its arguments that is not equal to the zero value.
// If no argument is non-zero, it returns the zero value.
func Or[T comparable](vals ...T) T {
var zero T
for _, val := range vals {
if val != zero {
return val
}
}
return zero
}
database/sql
在支持泛型之前,sql库定义了NullInt64、NullBool、NullString等结构体用于表示各种类型的null值。在泛型得到支持后,Null[T]也就应运而生了,不过目前原有的各NullXxx结构体还没有标为deprecated。
encoding
在base32、base64、hex包里,原有的Encode和Decode函数在使用时需要提前初始化适当长度的dst数组,如下:
src := []byte("abc")
dst := make([]byte, base64.StdEncoding.EncodedLen(len(src)))
base64.StdEncoding.Encode(dst, src)
fmt.Printf("dst:%s\n", string(dst))
现在新增了AppendEncode和AppendDecode函数,可将dst追加到给定数组之后,给定数组无需提前初始化,也可以方便地进行拼接:
src := []byte("abc")
dst := base64.StdEncoding.AppendEncode([]byte{}, src)
fmt.Printf("dst:%s\n", string(dst))
go/types
新增了Alias类型,用于表示类型别名。之前类型别名并不会有单独的类型,它本质上还是对应的原类型,只是代码看起来会有些差异,在运行期类型别名信息其实是不存在的。新增了Alias类型后,在错误上报时,我们可以看到别名信息而不是原类型,有助于我们定位问题。
但Alias类型可能会破坏已有的类型判断代码,所以在GODEBUG环境变量下新增了一个参数gotypesalias用于开启或关闭Alias类型。默认情况下是不开启的,以兼容旧代码。但在未来可能会默认为开启,所以我们已有的类型判断相关代码建议还是考虑到类型别名的情况,否则将来升级更新的Go版本可能会出现问题。举个例子:
package main
import (
"fmt"
"go/ast"
"go/parser"
"go/token"
"go/types"
)
func main() {
// 要解析和检查的Go代码
src := `
package main
type intAlias = int
func main() {
var x intAlias
println(x)
}
`
// 创建文件集
fset := token.NewFileSet()
// 解析Go代码
file, err := parser.ParseFile(fset, "example.go", src, 0)
if err != nil {
fmt.Println("解析错误:", err)
return
}
// 创建类型检查器
conf := types.Config{Importer: nil}
info := &types.Info{
Types: make(map[ast.Expr]types.TypeAndValue),
Defs: make(map[*ast.Ident]types.Object),
}
// 进行类型检查
_, err = conf.Check("example", fset, []*ast.File{file}, info)
if err != nil {
fmt.Println("类型检查错误:", err)
return
}
// 打印变量x的类型
for ident, obj := range info.Defs {
if ident.Name == "x" {
// 如果环境变量配置为GODEBUG=gotypesalias=0,则这里打印的类型是int,和1.22以前的版本一样,目前gotypesalias=0是默认值
// 如果环境变量配置为GODEBUG=gotypesalias=1,则这里打印的类型是example.intAlias,未来gotypesalias=1可能会变成默认值,因此判断类型别名的类型时需要额外注意
fmt.Printf("变量x的类型是: %s\n", obj.Type())
}
}
}
net
Go DNS解析器在使用“-tags=netgo”构建时,会先在windows的hosts文件中先查找是否匹配,即%SystemRoot%\System32\drivers\etc\hosts文件。
net/http
请求或响应头中如果包含空的Content-Length头,则HTTP server和client会拒绝请求或响应。GODEBUG的httplaxcontentlength参数设置为1可关闭这一特性,即不拒绝请求或响应。
net/netip
增加了AddrPort.Compare函数用于对比两个AddrPorts。
reflect
● Value.IsZero方法现在对于浮点零和复数零都会返回true,如果结构体的空字段(即_命名的字段)有非零值,Value.IsZero方法也会返回true。这些改动使得IsZero和==比较符在判零方面表现一致。
● PtrTo函数标为deprecated,应该改用PointerTo。
● 增加了新函数TypeFor用于获取类型,之前获取反射类型通常是reflect.TypeOf((*T)(nil)).Elem(),比较麻烦,现在直接调用TypeFor就可以了,其实内部实现还是一样的:
// TypeFor returns the [Type] that represents the type argument T.
func TypeFor[T any]() Type {
return TypeOf((*T)(nil)).Elem()
}
runtime/metrics
● 新增了四个关于stop-the-world(下称stw)的histogram metrics:
○ /sched/pauses/stopping/gc:seconds
○ /sched/pauses/stopping/other:seconds
○ /sched/pauses/total/gc:seconds
○ /sched/pauses/total/other:seconds
其中前两个用于上报从决定stw到所有协程全部停止的时间,后两个用于上报从决定stw到协程恢复运行的时间。
● /gc/pauses:seconds标记为deprecated,被/sched/pauses/total/gc:second取代了。
● /sync/mutex/wait/total:seconds之前仅包含sync.Mutex和sync.RWMutex的竞争时间,现在还包含了runtime-internal锁的竞争时间。
runtime/pprof
● mutex的profile现在会根据阻塞的协程数来计算竞争情况,更容易找出瓶颈mutex了。举个例子,有100个协程在一个mutex上阻塞了10毫秒,那这个mutex的profile会显示有1s延迟,以前是显示10毫秒延迟。
● mutex的profile除了包含sync.Mutex和sync.RWMutex的竞争时间,现在也会包含runtime-internal锁的竞争时间。
● 在Darwin系统上,CPU的profile现在会包含进程的内存映射,使得在pprof中可以启用反汇编视图。
runtime/trace
1.22的trace改动很大,详细内容可参考官方的blog:More powerful Go execution traces
slices
● 新增了Concat函数,可将多个slice连接成一个。在此之前需要多次append实现同样的效果,性能也差一些。
array1 := []int{1, 2, 3}
array2 := []int{4, 5, 6}
array3 := []int{7, 8, 9}
fmt.Println(append(append(array1, array2...), array3...)) // 1.22之前的写法,要拼接的slice越多写起来越麻烦,可能还需要for循环
fmt.Println(slices.Concat(array1, array2, array3)) // 1.22新增的Concat函数,使用起来更便利,性能也更好
● 会减少slice长度的函数会将新长度和原长度之间的元素值置为零值,包括Delete、DeleteFunc、Compact、CompactFunc、Replace,来看个例子:
array1 := []int{1, 2, 3}
array2 := slices.Delete(array1, 1, 2) // 移除[1, 2)区间的元素,即元素2,slice内还剩下元素1和3
fmt.Println(array1) // 以前是[1 3 3],现在是[1 3 0]
fmt.Println(array2) // 始终是[1 3]
● Insert函数以前如果插入的位置超出slice范围但没有真的插入任何值的时候不会panic,现在会panic了,也就是无论如何不能传入越界的插入位置。
array := []int{1, 2, 3}
slices.Insert(array, 100, 3) // 向下标100的位置插入元素3,因为越界,任何版本都会panic
slices.Insert(array, 100) // 向下标100的位置宣称要插入但没有传待插入的元素参数。在1.22版本之前因为没有实际插入任何元素所以没有问题,从1.22版本开始这样做会被认为是越界而导致panic
编译器
Go 在1.20版本中,首次引入了PGO。Go 1.22对这一特性进行了优化,支持将更多的接口方法转换为直接调用,从而提高性能。大多数启用 PGO 的程序将会有2-14%的性能提升。我们以一个示例说明优化算法原理:
type Animal interface {
Speak() string
}
type Dog struct{}
func (d Dog) Speak() string {
return "Woof!"
}
func main() {
var a Animal = Dog{}
fmt.Println(a.Speak())
}
在这个例子中,a.Speak() 是一个接口方法调用,Go 运行时需要查找 Dog 类型的 Speak 方法并调用它。通过开启 PGO 编译优化,编译器可以在某些情况下将这种动态调用转换为直接调用,从而减少运行时的开销,提高性能。
此外,1.22 版本还添加了一个编译器的内联算法优化,当前为预览版本,需要在编译时通过 GOEXPERIMENT=newinliner 参数来启用。内联是编译器优化的一种技术,它将函数调用展开为函数体,从而消除函数调用的开销,提高性能。具体优化点是,在重要调用点(比如循环场景)通过启发式算法提高内联能力,同时在不重要(比如,panic调用链)的调用点上不阻止内联。
链接器
Go 在1.22 中的改进点主要如下:
1. 改进 -s 和 -w 标志:
● -w 标志:抑制 DWARF 调试信息的生成。
● -s 标志:抑制符号表的生成,并且隐含 -w 标志(即同时抑制 DWARF 调试信息的生成)。
● -w=0:可以用来取消 -s 标志隐含的 -w 标志。例如,-s -w=0 将生成一个包含 DWARF 调试信息但没有符号表的二进制文件。
2. 新增 ELF 平台上的 -B 标志:
-B gobuildid:链接器将生成一个基于 Go build ID 的 GNU build ID(ELF NT_GNU_BUILD_ID 注释)。这意味着最终的 ELF 文件将包含一个基于 Go build ID 的 GNU build ID(存储在 ELF 文件的 .note.gnu.build-id 部分中)。
3. 改进 Windows 平台上的 -linkmode=internal 标志:
当使用 -linkmode=internal 构建时,链接器现在会保留 C 对象文件中的 SEH(结构化异常处理)信息,通过将 .pdata 和 .xdata 部分复制到最终的二进制文件中。这有助于使用本地工具(如 WinDbg)进行调试和分析。
需要留意的是,在 Go1.22 以前,C 函数的 SEH 异常不会被 go 程序处理。所以,升级新版本后可能因为错误被正确处理而导致程序出现一些与之前不同的行为。
总结来说,这些改进使得链接器在不同平台上的行为更加一致,并且在 Windows 平台上改进了程序调试和分析能力。
工具链
1.Go command
Go 1.22 版本对 Go command 工具链进行了一些改造升级,包括 go work vendor、go mod init、go test 覆盖率汇总等,总体上通过 go work vendor 功能完善了对 go work 的支持,而 go mod init 与 go get 等工具上的调整则逐渐停止了对 GOPATH 模式的支持,符合工具的迭代变化演进规律。
● 新增 go work vendor 功能
我们都知道 go module 是 Go 1.11 版本之后官方推出的版本管理工具,并且从 Go 1.13 版本开始,go module 是 Go 语言默认的依赖管理工具,但是当本地有很多 module,且这些 module 存在相互依赖,本地开发就会存在诸多不便,因此 Go 1.18 引入了 workspace工作区模式,可以让开发者不用修改 go module 的 go.mod,就能同时对多个有依赖的 go module 进行本地开发。不过当时可能为了简化 workspace 模式的实现,并没有支持 vendor 模式,而 vendor 模式对于需要依赖隔离、离线部署、可重复等场景还是很有必要。
因而 Go 1.22 版本,支持了 go work vendor 功能,可以将 workspace 模式中的依赖放到 vendor ⽬录下,使用方法上与 go mod vendor 一致,只是将 vendor 能力支持到了 workspace 工作区模式下,详情可通过 go help work vendor 查看帮忙文档。
● go test 调整了单测覆盖率摘要展示
Go 1.22 版本之前,当某个包下没有单测时,显示如下:
? mymod/mypack [no test files]
Go 1.22 版本调整了单测覆盖率摘要展示,当某个包下没有单测时,会被当作是无覆盖:
mymod/mypack coverage: 0.0% of statements
● 其它一些变化
在传统的 GOPATH 模式下(即 GO111MODULE=off 时),不再支持在 Go Module 之外使用 go get。不过其它的构建编译命令,例如:go build 和 go test,则可以继续适用于传统的 GOPATH 程序。
此外,初始化命令 go mod init 将不再尝试从其他依赖工具(如 Gopkg.lock)的配置文件中导入模块依赖,从中也可以看出,GOPATH 时代的工具正逐渐退出并成为历史。
2.Trace
Go 1.5 版本推出了 trace 工具,用于支持对整个周期内发生的事件进行性能分析,在之后的几个版本中逐渐完善成熟,不过也一直存在追踪的开销很大及追踪的扩展性不强等问题。
Go 1.21 版本 runtime/trace 基于 Frame Pointer Unwinding 技术大幅降低了收集运行时 trace 的 CPU 开销,需要注意的是,目前该项技术仅在 GOARCH 架构为 amd64 和 arm64 时生效,在 1.21 版本之前,许多应用开销大约在 10-20% 的 CPU 之间,而该版本只需要 1-2%。
得益于 1.21 版本中 runtime/trace 收集效率的大幅改进,Go 1.22 版本中的 trace 工具也进行了适应性地调整以支持新的 trace 收集工具,解决了一些问题并且提高了各个子页面的可读性,以进一步提升开发者们基于 trace 定位问题的效率与便捷性,如下基于 trace 报告中的 goroutines 追踪页面可以感受到可读性上的变化,随着 trace 收集开销的大幅降低,trace 工具的应用场景可能也会越来越广,催生更多的生态工具,例如 Flight recording,值得有兴趣的同学进一步关注。
3.Vet
go vet 工具是 Go 代码静态诊断器,可以用于检查代码中可能存在的各种问题,例如无法访问的代码、错误的锁使用、不必要的赋值、布尔运算错误等。工具检查选择的规则集主要考量正确性、频率和准确性等:
● 正确性:工具定位于检查代码潜在的编译或执行问题,而不是代码风格问题
● 频率:工具定位于希望开发人员频繁地执行,因此纳入的检查规则是需要能真正发现问题的规则
● 准确性:工具定位于极高的准确性,尽可能地不漏报也不错报,因此纳入的检查规则需要极高的准确性
因此建议未使用的开发人员安排上该工具,纳入日常 CI 流程或者 precommit 时进行检查,详情可以通过 go tool vet help 查看已注册的检查器及其用法。v1.22 版本的 go vet 工具,总的来说延续既有风格,并未做出特别大的调整,主要是基于 v1.22 自身语言的一些变化,适应性地调整了对相应问题的检查:
● 增加了对 slice 进行 append 操作却未追加额外值时的告警
示例:
// 错误代码
func testAppend() {
var s []string
s = append(s)
}
当使用 go vet 检查时,将会报告类似如下告警:
# [command-line-arguments]
./main.go:3:6: append with no values
● 增加了当对 time.Since 进行错误 defer 时的告警
示例:
func testTimeSince() {
t := time.Now()
defer log.Println(time.Since(t)) // non-deferred call to time.Since
tmp := time.Since(t)
defer log.Println(tmp) // equivalent to the previous defer
defer func() {
log.Println(time.Since(t)) // a correctly deferred call to time.Since
}()
}
当使用 go vet 检查时,将会报告类似如下告警:
# [command-line-arguments]
./main.go:3:20: call to time.Since is not deferred
● 增加了当使用 slog 打印日志却未正确传入键值对时的告警
func testSlog() {
slog.Info("hello", 3, 3)
}
当使用 go vet 检查时,将会报告类似如下告警:
./main.go:2:21: slog.Info arg "3" should be a string or a slog.Attr (possible missing key or value)
运行时
运行时的变化主要在 GC 算法。在 Go v1.22 中,运行时会将基于类型的垃圾回收元数据保持在每个堆对象附近,从而可以将 Go 程序的 CPU 性能提升1~3%。此外,通过减少重复的元数据信息,大多数程序的内存开销也会下降约1%。
这一改进涉及到对象地址对齐问题,以前部分对象的地址是按16(甚至更大)字节边界对齐,现在只与8字节对齐。内存的分配更为精细化,大多数应用程序的内存开销也因此而变小。但是,如果某些对象的大小刚好在新的大小类边界上,那么这些对象可能会被移动到更大的内存块中,这些对象可能会占用更多的内存。由于这种应用程序占比较少,总体而言,内存开销是有小幅优化下降的。
此外,一些使用汇编指令的程序,由于要求内存地址对齐超过8字节,且依赖之前内存分配器的地址对齐功能,可能会在这个版本遇到兼容性问题。Go 团队给出了构建参数 GOEXPERIMENT=noallocheaders ,通过这个参数可以关闭新变化,回退到之前版本的对齐特性。这个参数仅用于临时过渡,后续 Go 版本会将其移除,因此如果有依赖的话需要尽快兼容适配。
Go v1.22版本对语言、编译器、工具连、运行时、标准库都有一定程度的优化。既有代码通过本版本重新编译后性能上能有一定的提升。
最新版本:1.23
2024年8月中旬发布的v1.23版本带来了众多改进和新特性,下面简单看看主要亮点:
1、语言特性更新
新的迭代器语法:在 "for-range" 循环中,现在可以使用迭代器函数作为 range 表达式,如 func (func (K) bool)。这支持用户自定义任意序列的迭代器。标准库的 slices 和 maps 包也添加了支持迭代器的新功能。
泛型类型别名预览: Go 1.23 包含了对泛型类型别名的预览支持。
2、工具链改进
Go 遥测系统:引入了一个 opt-in 的遥测系统,收集使用情况和错误统计,以帮助理解 Go 工具链的使用情况和效果,默认不开启。
go 命令新功能:
go env -changed: 显示与默认值不同的设置。
go mod tidy -diff: 预览必要的 go.mod 和 go.sum 文件更改,而不实际修改文件。
go vet 增强:现在可以报告对于目标 Go 版本来说过新的符号。
3、标准库更新
新包引入:
iter: 支持迭代器相关功能。
structs: 定义用于修改结构体属性的标记类型(marker type)。
unique: 提供用于 interning 可比较值的工具。
time 包优化:改进了 time.Timer 和 time.Ticker 的实现。
GODEBUG 设置:支持在 go.mod 和 go.work 文件中使用新的 godebug 指令
更多变化查看发行说明。
Go 语言 15 周年记
2024-11-10,生日快乐,Go!周日,我们庆祝了 Go 开源发布 15 周年!
自 Go 诞生 10 周年以来,其本身和世界都发生了巨大变化;在其他方面,很多东西保持不变:Go 仍然致力于稳定性、安全性以及支持大规模软件工程和生产。Go 正在强势发展!其用户群在过去五年中增长了两倍多,使其成为增长最快的语言之一。从十五年前诞生之初,Go 已成为十大语言之一,也是现代云语言。
随着 Go 1.22 在二月发布和 Go 1.23 在八月发布,这一年是 for 循环的一年。Go 1.22 使得由 for 循环引入的变量每次迭代时作用域独立,而不是整个循环,解决了一个长期存在的语言 “陷阱”。十多年前,在 Go 1 发布之前,Go 团队对几个语言细节做出了决定;其中包括是否应该在每次迭代中创建新的循环变量。有趣的是,这个讨论相当简短且明显没有意见。Rob Pike 以他一贯的风格用一个字结束了这个讨论:“stet”(保持原样)。于是事情就这样定下来了。虽然当时看似微不足道,但多年的生产经验突显了这一决策的影响。然而,在这段时间里,我们也建立了强大的工具来理解对 Go 更改的影响 —— 特别是在整个 Google 代码库中的生态系统范围分析和测试 —— 并建立了与社区合作和获取反馈的流程。在经过广泛测试、分析和社区讨论后,我们推出了这一变化,并配备了一种哈希二分工具,以帮助开发者大规模定位受该变化影响的代码。
对 for 循环的更改是五年逐步变化的一部分。如果没有在 Go 1.21 中引入的向前语言兼容性,这一切都不可能实现。这又建立在四年半前在 Go 1.14 中引入的 Go 模块所奠定的基础之上。
Go 1.23 在此基础上进一步引入了迭代器和用户定义的 for-range 循环。结合在两年半前推出的泛型(Go 1.18),这为自定义集合和许多其他编程模式创造了一个强大而人性化的基础。
这些版本还带来了生产就绪性的许多改进,包括备受期待的标准库 HTTP 路由器增强、执行跟踪的大规模重构,以及所有 Go 应用程序更强大的随机性。此外,我们首个 v2 标准库包的推出为未来库的发展和现代化建立了模板。过去一年中,也谨慎地推出了可选参与的数据收集系统,用于 Go 工具。该系统将为 Go 开发者提供数据,以便做出更好的决策,同时保持完全开放和匿名。Go 数据收集首次出现在 gopls,即 Go 语言服务器,已经导致了一系列改进。这项工作为使使用 Go 编程成为每个人更加美好的体验铺平了道路。
展望未来,我们正在发展 Go,以更好地利用当前和未来硬件的能力。在过去 15 年中,硬件发生了很大变化。为了确保 Go 在接下来的 15 年内继续支持高性能、大规模的生产工作负载,我们需要适应大型多核、先进指令集以及在日益非均匀的内存层次结构中局部性的重要性不断增长。这些改进中的一些将是透明的。Go 1.24 将在底层实现一个全新的映射,实现对现代 CPU 的更高效支持。同时,我们正在原型设计围绕现代硬件能力和限制的新垃圾回收算法。一些改进将以新 API 和工具的形式出现,以便 Go 开发者能够更好地利用现代硬件。我们正在研究如何支持最新的向量和矩阵硬件指令,以及应用程序构建 CPU 和内存局部性的多种方式。指导我们努力的一项核心原则是可组合优化:优化对代码库的影响应该尽可能局部化,确保不会妨碍其余代码库开发的便利性。
将继续确保 Go 的标准库默认安全且设计上安全。这包括持续努力纳入内置、本地支持 FIPS 认证加密,因此对于需要它的应用程序来说,FIPS 加密只需简单切换标志。此外,我们还将在可以做到的地方逐步演变 Go 的标准库包,并借鉴 math/rand/v2 的例子,考虑在哪里新增 API 可以显著提高编写安全可靠 Go 代码的便利性。
我们致力于通过增强 AI 基础设施、应用程序和开发者辅助功能,使 Go 更适合 AI,同时使 AI 更适合 Go。Go 是构建生产系统的一种优秀语言,我们希望它也能成为构建生产 AI 系统的一种优秀语言。作为云基础设施语言,Go 的可靠性使其自然成为 LLM 基础设施选择之一。在 AI 应用方面,我们将继续为流行 AI SDK(包括 LangChainGo 和 Genkit)提供一流支持。从一开始,Go 就旨在改善端到端的软件工程过程,因此自然而然地,我们正着眼于引入来自 AI 的最新工具和技术,以减少开发人员繁琐工作,从而留出更多时间用于有趣内容 —— 例如实际编程!
鸣谢:这一切之所以成为可能,是因为 Go 拥有令人难以置信的贡献者和蓬勃发展的社区。十五年前只能梦想 Go 取得的成功以及围绕 Go 发展的社区。感谢所有参与其中的人,无论参与深浅。我们祝愿大家在新的一年里一切顺利。
Austin Clements, for the Go team.
最新版本:1.24
v1.24 已于2025年2月中旬正式发布,它在 v1.23 的基础上带来了许多改进。以下是一些显著的变更。
语言变更:v1.24 现在完全支持 generic type aliases:类型别名可以被参数化,就像定义的类型一样。有关详细信息,请参阅语言规范。
性能改进:运行时的一些性能改进使得在一系列代表性基准测试中平均降低了 2-3% 的 CPU 负载。这些改进包括基于 Swiss Tables 的新内置 map 实现、更高效的内存分配(针对小对象)以及新的运行时内部互斥锁实现。
go 命令现在提供了一种跟踪模块工具依赖的机制。使用 go get-tool 向当前模块添加 tool 指令。使用 go tool [工具名称] 来运行使用 tool 指令声明的工具。有关 go 命令的更多信息请参阅发布说明。go vet 子命令中的新 test 分析器报告了测试包中测试、模糊测试、基准测试和示例声明的常见错误。有关 vet 的更多信息请参阅发布说明。
标准库新增内容:标准库现在包括一套新的机制,以促进 FIPS 140-3 合规性。FIPS 140-3 合规性 的应用程序无需对源代码进行任何更改即可使用新的机制来使用批准的算法。有关 FIPS 140-3 合规性 的更多信息,请参阅发布说明。除了 FIPS 140 之外,之前位于 x/crypto 模块中的几个包现在也包含在标准库中。
基准测试现在可以使用更快且更少出错的 [testing.B.Loop](about:blank) 方法来执行基准迭代,例如用 for b.Loop() { ... } 代替典型的涉及 b.N 的循环结构,如 for range b.N。有关新基准函数的更多信息,请参阅发布说明。
新的 [os.Root](about:blank) 类型提供了在特定目录下执行文件系统操作的能力。有关文件系统访问的更多信息请参阅发布说明。
运行时提供了一种新的最终化机制 [runtime.AddCleanup](about:blank),它比 [runtime.SetFinalizer](about:blank) 更灵活、更高效且更少出错。有关清理操作的更多信息请参阅发布说明。
改进的 WebAssembly 支持:v1.24 增加了一个新的 go:wasmexport 指令,允许 Go 程序将函数导出到 WebAssembly 主机,并支持将 Go 程序构建为 WASI reactor/library。在发布说明中了解更多关于 WebAssembly 的信息。
更多信息可查看完整更新日志,请参考发行说明。
最新版本:1.25
2025年年中发布的v1.25 标志着 Go 语言向前迈出了重要一步,其核心在于提升性能、优化开发者体验以及增强云原生就绪能力。此次发布在工具链、运行时、编译器和标准库等多个方面引入了一系列增强功能,旨在使 Go 应用程序更快、更高效,并更易于开发和部署,尤其是在容器化环境中。它还凸显了对安全性的承诺以及语言规范的持续完善。本次更新主要聚焦于性能优化、开发体验提升以及云原生与容器化场景的适配,具体亮点包括:
核心运行时与性能改进
GC(垃圾回收)性能大幅提升:暂停时间进一步缩短至亚毫秒级。
GOMAXPROCS 自动调整:在容器(如 Kubernetes)中运行时,Go 会自动根据容器实际分配的 CPU 核心数调整 GOMAXPROCS,避免传统方式带来的性能损耗。
工具链与模块管理增强
支持 Git 子目录作为模块根路径:解决了长久以来单仓库多模块(monorepo)结构中的模块导入难题。
go.mod 新增 ignore 指令:可忽略构建时不需要的目录(如前端构建产物),减少干扰。
Go 命令增强:如新增的 work 包模式、构建信息 JSON 输出等,提升 CI/CD 集成效率。
标准库与语言规范更新
实验性 JSON v2 包引入:通过 GOEXPERIMENT=jsonv2 可启用,解码性能显著提升。
testing/synctest 新包:用于测试并发代码,支持模拟时间与 goroutine 行为。
语言规范 “大扫除”:移除 “核心类型(core types)” 概念,简化泛型规范,为未来泛型演进铺路。
安全性与并发编程增强
sync.WaitGroup.Go 方法:简化并发任务管理,减少手动计数错误。
CSRF 防护机制增强:标准库中引入更完善的 Web 安全支持。
加密算法扩展:新增 ChaCha20-Poly1305 与 Ed25519 支持。
更多详情查看 Go-v1.25 新功能。此次发布围绕以下关键主题展开:性能优化、增强型开发者工具、云原生就绪、安全强化以及语言成熟度。以下表格概述了v1.25 的主要亮点,为繁忙的专业人士提供了快速参考,以便立即了解最关键的变更。
类别 | 特性/变更 | 简要描述 | 影响/益处 |
|---|---|---|---|
性能优化 | 实验性垃圾回收器 (greenteagc) | 标记和扫描小对象性能提升,预计减少 0-40% GC 开销 | 降低运营成本,提升应用吞吐量和降低延迟 |
工具增强 | go vet 新分析器 | 新增 | 提升代码质量,帮助发现常见并发和网络地址构建错误 |
并发/测试 | testing/synctest 包 | 提供测试并发代码的支持,包括伪造时钟和 goroutine 等待机制 | 编写更可靠、确定性的并发应用测试 |
云原生 | 容器感知 | 在 Linux 上自动根据 cgroup CPU 限制调整 | 优化容器资源利用,减少 CPU 节流,提升云环境性能 |
安全强化 | TLS SHA-1 禁用 | TLS.2 握手默认禁用 SHA-1 签名算法 | 增强默认安全态势,符合行业最佳实践 |
语言/运行时精炼 | DWARF v5 调试信息 | 编译器和链接器生成 DWARF v5 调试信息 | 减少调试信息大小,缩短大型二进制文件的链接时间 |
平台 | macOS2+ 要求 | Go.25 要求 macOS2 Monterey 或更高版本 | Darwin 用户需要升级操作系统才能使用 Go.25 |
v1.25 是 Go 编程语言即将发布的版本,于 2025 年 8 月推出。此次发布延续了 Go 的演进,在先前版本的基础上,着重于核心组件的精炼和开发者体验的提升。它表明 Go 语言已趋于成熟,并积极应对当代软件开发中的挑战,尤其是在性能敏感和云原生领域。本次发布展现了一种平衡的方法,既引入了重要的新功能(如实验性垃圾回收器和 JSON v2),又完善了现有功能(工具、运行时优化、标准库改进)。明确呼吁社区对实验性功能提供反馈,这突显了 Go 协作的开发模式。
语言变更
v1.25 并没有对 Go 语言本身进行任何会影响现有 Go 程序的更改。然而语言规范中 “核心类型” 的概念已被移除。
这一变化虽然不会影响现有的 Go 程序,但它反映了对语言规范本身的微妙而重要的完善。这表明 Go 团队持续致力于澄清和简化 Go 的正式定义,使其对语言实现者和高级用户来说更加精确和不含糊。语言规范对于编译器之间的一致性以及对语言的精确理解至关重要。移除一个概念并用更清晰的散文取代它,暗示了之前的定义可能存在模糊、混淆或不够精确的问题。这关乎于 “精炼语言的定义”,而非其在实践中的语法或语义。这种做法表明,即使是基础文档也在不断改进,以提高清晰度和严谨性。这确保了语言在演进过程中保持良好定义,避免了因不够精确的规范而可能出现的未来歧义或不一致性。这最终使编译器开发者、语言研究人员以及任何需要深入理解 Go 正式结构的人受益。
工具增强
v1.25 在其工具链中引入了多项显著增强,旨在提升开发者效率、代码质量和项目管理能力。
Go 命令更新
go 命令获得了多项新功能和行为调整:
go build -asan 内存泄漏检测:go build -asan 选项现在默认在程序退出时执行内存泄漏检测。如果 C 分配的内存未被释放且未被其他 C 或 Go 分配的内存引用,它将报告错误。此功能可以通过设置ASAN_OPTIONS=detect_leaks=0 来禁用。这对调试 Go 程序中 C/C++ 互操作性问题(特别是使用cgo 的程序)来说是一个重要的增强。C 语言分配的内存泄漏通常难以追踪。
减少预构建工具二进制文件: Go 发行版将包含更少的预构建工具二进制文件。核心工具链二进制文件(编译器、链接器)仍将包含在内,但其他工具将由go tool 在需要时构建和运行。此项更改旨在减小 Go 发行版的大小,可能导致更快的下载速度和更小的安装占用空间。它将不常用工具的构建负担转移到按需进行。
go.mod ignore 指令: 新增的 go.mod ignore 指令允许指定 go 命令在匹配 all 或 ./... 等包模式时忽略的目录。这些被忽略的文件仍将包含在模块 zip 文件中。这提供了对go 命令如何解释包模式的更细粒度控制,在大型仓库或单体仓库中尤其有用,因为某些子目录可能包含非 Go 代码或不打算用于通用包模式匹配的实验性模块。
go doc -http 选项: 新的 go doc -http 选项将为请求的对象启动一个文档服务器并在浏览器中打开。这极大地提升了开发者的体验,使得无需离开终端即可更快、更方便地浏览本地 Go 文档。
go version -m -json 选项: 此选项将打印 Go 二进制文件中嵌入的 runtime/debug.BuildInfo 结构的 JSON 编码。它提供了一种以编程方式从已编译二进制文件中提取构建信息(如模块版本、Go 版本、构建标志)的方法,这对于自动化、CI/CD 流水线以及审计已部署应用程序而言具有不可估量的价值。
子目录模块根支持:go 命令现在支持使用 <meta name="go-import" content="root-path vcs repo-url subdir"> 语法解析模块路径时,将仓库的子目录作为模块根。这增强了 Go 模块托管的灵活性,允许单个仓库包含多个模块,或模块位于大型项目的特定子目录中,这与常见的单体仓库模式相符。
work 包模式: 新的 work 包模式匹配工作模块中的所有包(模块模式下的单个工作模块,或工作区模式下的工作区模块)。这简化了跨 Go 工作区中所有模块的操作,简化了诸如go test./work... 或 go build./work... 等命令。
不再添加工具链行: 当更新 go.mod 或 go.work 文件中的 go 行时,go 命令将不再添加指定其当前版本的工具链行。这减少了go.mod 和 go.work 文件中的噪音和不必要的修改,简化了版本控制,并可能避免在升级 Go 版本时出现虚假差异。
下表总结了 v1.25 中引入的新 go 命令选项及其典型用例:
选项 | 描述 | 用例/益处 |
|---|---|---|
go build -asan | 程序退出时默认执行内存泄漏检测 | 调试 CGo 内存泄漏,确保 C 分配内存的正确释放 |
go.mod ignore | 允许指定 | 管理大型单体仓库或包含非 Go 代码的复杂项目结构 |
go doc -http | 启动请求对象的文档服务器并在浏览器中打开 | 快速本地文档查找,提升开发效率 |
go version -m -json | 以 JSON 格式打印 Go 二进制文件中嵌入的 | 自动化构建信息提取,方便 CI/CD 流水线和部署审计 |
work 包模式 | 匹配工作区中所有模块的包 | 简化工作区操作,如 |
Vet 分析器
go vet 命令包含了两个新的分析器,进一步提升了代码质量检查能力:
waitgroup 分析器: 报告对 sync.WaitGroup.Add 的错误调用位置。sync.WaitGroup 是常见的并发 bug 来源,如果 Add 在 Wait 之后或在可能在 Wait 之后启动的 goroutine 中调用,就可能导致微妙的错误。此分析器有助于及早捕获此类错误。
hostport 分析器: 报告使用 fmt.Sprintf("%s:%d", host, port) 构造 net.Dial 地址(不适用于 IPv6)的情况,并建议改用 net.JoinHostPort。此分析器推广网络地址构造的最佳实践,确保 IPv6 兼容性并防止处理主机和端口组合时常见的错误。
go vet 分析器和 go 命令新功能的持续增加,例如 go.mod ignore 和 work 模式,表明 Go 团队对开发者生产力、代码质量以及支持日益复杂的项目结构(如单体仓库、微服务)的战略性投入。这些新工具直接为开发者提供了更强大的构建、调试和管理 Go 项目的能力。例如,waitgroup 和 hostport 分析器直接针对常见的陷阱和最佳实践,从而带来更健壮和安全的应用程序。这反映了一种主动预防常见错误的方法。同时,go doc -http 和 go version -m -json 简化了日常任务,减少了摩擦并提高了效率。此外,go.mod ignore、子目录模块根和 work 模式明确解决了大型复杂项目和单体仓库中面临的挑战。这表明 Go 作为一种适用于企业级开发的语言正在走向成熟。这些发展趋势表明,Go 不仅在语言功能上取得进展,还在提供一个更全面、更具指导性且高度集成的开发环境,引导开发者采用惯用且健壮的解决方案,尤其是在项目规模和复杂性增长时。这有助于减轻开发者的认知负担,并提高整个生态系统的整体代码质量。
运行时改进
v1.25 在运行时方面进行了多项关键改进,旨在优化资源管理、提升性能以及增强调试能力。
容器感知 GOMAXPROCS
GOMAXPROCS 的默认行为发生了变化。在 Linux 上,运行时现在会考虑包含进程的 cgroup 的 CPU 带宽限制。如果此限制低于逻辑 CPU 数量,GOMAXPROCS 将默认为较低的限制。这与 Kubernetes 的 “CPU 限制” 选项相对应,而非 “CPU 请求”。在所有操作系统上,如果逻辑 CPU 数量或 cgroup CPU 带宽限制发生变化,运行时将定期更新GOMAXPROCS。如果手动设置GOMAXPROCS 或通过 GODEBUG 设置 containermaxprocs=0 和 updatemaxprocs=0 明确禁用,这些行为将自动禁用。运行时将为 cgroup 文件保持缓存的文件描述符,以支持读取更新的限制。这是在容器化环境(尤其是 Kubernetes)中运行 Go 应用程序的关键增强。它防止 Go 运行时在超出分配的 CPU 资源的情况下过度调度 goroutine,这可能导致 CPU 节流和性能下降。
新的实验性垃圾回收器 (greenteagc)
v1.25 引入了一个实验性垃圾回收器,其设计目标是通过更好的局部性和 CPU 可伸缩性来提高小对象标记和扫描的性能。预计它将使实际程序中的垃圾回收开销减少 0-40%。通过在构建时设置GOEXPERIMENT=greenteagc 可以启用此实验性 GC。鼓励用户尝试并就 GitHub 问题提供反馈。这代表了 Go 应用程序潜在的显著性能飞跃,特别是对于高对象分配率的应用程序。其 “实验性” 标签表明在广泛采用之前需要谨慎推出,并寻求社区验证。
未处理的 Panic 输出变更
对于已恢复并重新 panic 的未处理 panic,其消息将不再重复 panic 值文本。例如,panic: PANIC [recovered]\n panic: PANIC 现在将打印 panic: PANIC [recovered, repanicked]。这是一个虽小但有用的调试改进,使 panic 消息更清晰,减少冗余,特别是在复杂的错误恢复场景中。
Linux 上的 VMA 名称
在支持 CONFIG_ANON_VMA_NAME 内核的 Linux 系统上,Go 运行时将使用上下文(例如 [anon: Go: heap])注释匿名内存映射。此功能可以通过GODEBUG=decoratemappings=0 禁用。此项功能通过在pmap 或 /proc/<pid>/maps 等工具中提供更多上下文,增强了 Linux 上的调试和分析能力,从而更容易理解 Go 如何管理内存。
运行时方面的变化,特别是容器感知的 GOMAXPROCS 和实验性的 greenteagc,凸显了 Go 对优化现代部署环境和突破其性能极限的战略重点。这表明 Go 积极响应了云原生计算和高性能应用程序的需求。GOMAXPROCS 的变化直接承认了 Go 在 Kubernetes 等容器编排平台中的广泛使用。此前,Go 应用程序在受限容器中可能会过度利用 CPU,导致性能下降。这一变化 “自动化” 了最佳资源利用,减少了开发者或平台工程师手动调整 GOMAXPROCS 的需求。这是 Go 应用程序向 “Kubernetes 原生” 迈出的重要一步。实验性垃圾回收器则展示了 Go 对其核心性能特征的持续投入。垃圾回收是影响延迟和吞吐量的关键组件。将开销减少 0-40% 是一个显著的进步,可能使 Go 对延迟敏感或高吞吐量的工作负载更具吸引力。其 “实验性” 性质以及呼吁反馈的做法,表明 Go 团队在引入可能具有颠覆性但极具益处的更改时采取了务实的方法,并依赖社区验证。这些运行时改进共同使 Go 在构建现代云基础设施中高性能、可伸缩和成本效益高的服务方面更具竞争力。它们解决了实际操作挑战,并为未来的性能提升铺平了道路。
编译器创新
v1.25 的编译器引入了多项改进,旨在提升调试体验、强制代码正确性以及优化运行时性能。
DWARF 版本 5 调试信息
编译器和链接器现在使用 DWARF 版本 5 生成调试信息。这减少了调试信息的空间占用并缩短了链接时间,尤其对于大型二进制文件而言。通过设置GOEXPERIMENT=nodwarf5 可以禁用 DWARF 5 的生成。这对开发者而言是一项技术性但影响深远的改进,特别是对于处理大型 Go 项目或调试复杂问题的开发者,它能带来更快的构建时间和更小的可调试二进制文件。
Nil 指针检查修复
编译器修复确保了 nil 指针检查能够及时执行。以前能够成功运行但却在检查错误之前使用了os.Open 结果的程序,现在将会 panic。解决方案是在生成错误语句后立即检查非 nil 错误。这对于 “编写不正确” 的 Go 代码来说是一个破坏性变更。它强制执行了 Go 惯用的错误处理模式,通过防止因未处理错误而导致的静默失败或意外行为,使应用程序更加健壮。
切片的栈分配
编译器现在可以在更多情况下为切片在栈上分配底层存储,从而提高性能。这可能会放大不正确使用unsafe.Pointer 所带来的问题。
bisect tool 配合 -compile=variablemake 可以帮助追踪这些问题,并且可以通过 -gcflags=all=-d=variablemakehash=n 关闭新的栈分配。这是一项性能优化,它利用栈分配来处理瞬时数据,从而减少堆压力和 GC 开销。然而,它也强调了不当使用unsafe.Pointer 所固有的危险。
编译器方面的变化,特别是 nil 指针检查修复和切片栈分配的扩展,表明 Go 团队同时致力于性能优化和代码正确性 / 安全性,即使这意味着为非惯用代码引入潜在的破坏性变更。nil 指针修复明确表明 Go 优先考虑正确和安全的代码,而不是对 “有缺陷” 代码的向后兼容性。它强化了立即进行错误检查的重要性,这是 Go 错误处理理念的基石。这最终会带来更可靠的应用程序。切片的栈分配是一项激进的优化。关于 unsafe.Pointer 的警告至关重要;它强调了虽然 Go 追求性能,但它不会为了 “安全” 的 Go 代码而损害其内存安全保证。它隐式地不鼓励随意使用 unsafe.Pointer,并提供了调试工具以解决必须使用它的情况。这些变化表明 Go 正在通过强化其核心和优化其执行模型而走向成熟。这些变化表明 Go 语言在自信地演进,愿意为了长期稳定性和性能而强制执行更严格的正确性,即使这要求开发者调整其(可能存在缺陷的)现有实践。为栈分配问题提供调试工具也表明了在这些过渡期间支持开发者的承诺。
链接器更新
链接器现在接受一个 -funcalign=N 命令行选项,用于指定函数入口对齐。默认值是平台相关的,并且没有改变。这是一项低级优化,主要与特定性能关键场景或平台特定要求相关,允许对二进制文件布局进行微调。
标准库新增与修改
v1.25 对标准库进行了广泛的更新,引入了新包、增强了现有功能并改进了安全性。
新增 testing/synctest 包
testing/synctest 包提供了测试并发代码的支持。其核心功能包括Test 函数,它在一个独立的 “气泡” 中运行测试,并为 time 包函数提供一个伪造的时钟。此外,Wait 函数会等待当前气泡中的所有 goroutine 阻塞。这是 Go 开发者的一项重大新增功能,解决了长期以来测试并发逻辑的挑战。伪造时钟和 goroutine 等待机制使得对时间敏感和并发操作进行确定性测试成为可能,从而显著提高了并发 Go 应用程序的质量和可靠性。
新的实验性 encoding/json/v2 包
Go1.25 引入了一个实验性 JSON 实现,通过在构建时设置 GOEXPERIMENT=jsonv2 启用。它包含了encoding/json/v2(encoding/json 的主要修订版)和 encoding/json/jsontext(更底层的 JSON 语法处理)。启用后,encoding/json 将使用新的实现,其编组 / 解组行为保持不变,但错误文本可能有所改变。
encoding/json 还获得了配置编组器 / 解组器的新选项。新的实现提供了显著的性能改进,尤其是在解码方面。更多细节可在 github.com/go-json-experiment/jsonbench 仓库中找到。鼓励用户使用GOEXPERIMENT=jsonv2 测试其程序以检测兼容性问题,并就提案问题提供反馈。这对于 Go 中的 JSON 处理来说可能是一项变革性的改变,有望带来显著的性能提升。其实验性性质允许社区在完全集成之前提供反馈,以确保广泛的兼容性。
库的次要变更(按包分类)
标准库的许多现有包也得到了更新和增强。下表总结了标准库中按包分类的主要变更:
包 | 变更描述 | 变更类型 | 影响/益处 |
|---|---|---|---|
archive/tar | Writer.AddFS 支持符号链接 | 增强 | 更好地处理文件系统中的符号链接 |
crypto | 引入 | 新功能 | 统一签名接口,提升加密操作的灵活性 |
crypto/ecdsa | 新增低级编码函数和方法 | 增强 | 简化 ECDSA 密钥的低级操作,减少对 |
crypto/tls | SHA-1 签名算法在 TLS.2 握手默认禁用;新增 | 安全/增强 | 提升 TLS 安全性,提供更多连接状态信息 |
crypto/x509 | CreateCertificate 等函数接受 | 安全/增强 | 提升证书创建的灵活性和安全性 |
go/ast | 部分函数和类型被弃用;新增 | 弃用/新功能 | 现代化 AST 和解析器 API,提供更强大的语法树遍历能力 |
go/parser | ParseDir 函数被弃用 | 弃用 | 现代化解析器 API |
go/token | 新增 | 增强 | 方便向 |
go/types | Var 新增 | 增强 | 提升类型检查和变量分类能力 |
hash | 新增 | 新功能/增强 | 支持可扩展输出函数,方便哈希状态的复制 |
io/fs | 新增 | 新功能 | 统一文件系统接口,支持符号链接读取 |
log/slog | GroupAttrs 创建组 | 增强 | 提升结构化日志的灵活性和信息丰富度 |
net/http | 新增 | 安全 | 利用现代浏览器 Fetch 元数据增强 CSRF 防护 |
os | Windows 异步 I/O 支持; | 增强 | 提升 Windows 文件 I/O 性能;增强文件系统操作的灵活性和一致性 |
reflect | 新增 | 增强 | 减少类型断言时的内存分配,提升性能 |
runtime | 清理函数并发执行; | 增强/调试 | 提升清理效率;更方便地设置 |
runtime/trace | 新增 | 调试/诊断 | 提供轻量级执行跟踪能力,方便捕获近期执行情况 |
sync | 新增 | 新功能 | 简化 goroutine 的创建和计数管理 |
testing | 新增 | 增强/行为变更 | 提升测试日志的可读性;提供更受控的测试输出;避免并发测试中的不确定性 |
unicode | 新增 | 增强 | 提升 Unicode 字符分类的灵活性和完整性 |
unique | 更积极、高效、并行地回收 interned 值 | 性能 | 减少内存膨胀,提升内存回收效率 |
标准库的广泛更新,特别是 testing/synctest 和实验性的 encoding/json/v2 包,以及 crypto/tls 和 crypto/x509 中的安全强化,表明 Go 团队持续致力于为常见编程任务提供一流、经过实战检验的原语,同时积极解决性能瓶颈和安全漏洞。testing/synctest 直接回应了可靠测试并发代码的难题,而这正是 Go 中常见的错误来源。这表明 Go 致力于改善其核心并发模型的 “开发者体验”。json/v2 的实验性引入表明,即使是标准库中成熟且高度优化的部分,如果能够实现显著的性能提升,也可能进行基础性的重新架构。这显示了一种务实的持续优化方法。在 TLS.2 中禁用 SHA-1 是一项主动的安全措施,符合行业最佳实践。这确保了 Go 应用程序默认是安全的,推动整个生态系统采用更强的加密卫生。无数的次要更改(例如 io/fs.ReadLinkFS、os.Root 方法、sync.WaitGroup.Go、reflect.TypeAssert)反映了持续完善 API、添加便利函数以及适应现代范式(如 io/fs 用于文件系统抽象)的过程。这确保了标准库保持最新、符合人体工程学且全面。标准库仍然是 Go 吸引力的基石。这些更新强化了其作为构建各种应用程序的健壮、高性能和安全基础的作用,并明确关注满足开发者需求和适应不断变化的技术格局。json/v2 的实验性也突显了 Go 开放和迭代的开发过程,邀请社区参与核心组件的塑造。
端口和平台特定性
v1.25 在平台支持方面进行了调整,以适应不断变化的操作系统和硬件生态系统。
Darwin: v1.25 要求 macOS2 Monterey 或更高版本;对先前版本的支持已停止。这对使用旧版 macOS 的开发者来说是一个破坏性变更,需要升级操作系统才能使用。这与 Apple 快速的操作系统更新周期保持一致。
Windows: v1.25 是最后一个包含 32 位 windows/arm 端口(GOOS=windows GOARCH=arm)的版本,该端口将在 v1.26 中移除。这标志着一个使用较少的端口被弃用并最终移除,从而使 Go 团队能够将资源集中在更广泛采用的平台上。
RISC-V: linux/riscv64 端口现在支持 plugin 构建模式。GORISCV64 环境变量接受 rva23u64 来选择 RVA23U64 用户模式应用程序配置文件。这表明 RISC-V 架构的持续成熟和更广泛的支持,特别是在动态加载场景和特定应用程序配置文件方面。
下表总结了 v1.25 中与平台相关的变更和弃用:
平台 | 变更 | 影响/含义 |
|---|---|---|
Darwin | Go1.25 要求 macOS2 Monterey 或更高版本 | macOS 用户需要升级操作系统才能使用 Go1.25 |
Windows | Go1.25 是最后一个包含 32 位 windows/arm 端口的版本,Go1.26 将移除 | 使用 32 位 Windows ARM 的开发者需规划迁移 |
RISC-V | linux/riscv64 端口支持 | 增强 RISC-V 架构支持,特别是动态加载和特定应用配置文件 |
平台特定的变化反映了 Go 对支持不断发展的硬件和操作系统生态系统的务实方法:优先支持广泛采用和现代的平台,同时战略性地淘汰使用较少或遗留的平台,并积极投资于 RISC-V 等新兴架构。macOS 的要求是软件开发中的常见模式,与操作系统供应商的支持周期保持一致。放弃 32 位 Windows ARM 是一个战略决策,旨在将开发资源从维护一个利基平台中解放出来,从而能够专注于更具影响力的领域。这表明 Go 在平台支持方面采取了精益高效的方法。对 RISC-V 的持续投入,特别是添加 plugin 支持(动态链接),是一个重要的信号。RISC-V 是一种新兴架构,在各个领域(嵌入式、数据中心)的应用日益增多。Go 对其早期而强大的支持使该语言在未来的硬件趋势中处于有利地位。Go 的平台策略是动态且响应迅速的。它平衡了广泛兼容性的需求与将资源集中在主要和新兴平台上的效率。这确保了 Go 在最重要的计算环境中保持相关性和高性能,同时也就支持遗留或利用较少的平台做出了务实决策。
v1.25 是一次全面的发布,显著提升了 Go 语言在性能、工具和运行时方面的能力。它巩固了 Go 作为一种健壮、高效且对开发者友好的语言的地位,尤其适用于现代云原生应用程序和高性能服务。此次发布展现了对持续改进、安全性和社区驱动演进的明确承诺。对于 Go 开发者,以下是建议:
审查代码以应对 Nil 指针修复: 立即检查 os.Open 和类似返回错误的函数,确保正确的错误处理,以避免程序 panic。
探索实验性功能: 在非生产环境中积极测试 GOEXPERIMENT=greenteagc 和 GOEXPERIMENT=jsonv2,并提供反馈。这些功能可能在未来带来重大变革。
利用新工具: 将新的 go 命令功能(go.mod ignore、go doc -http、work 模式)和 vet 分析器(waitgroup、hostport)集成到开发工作流程中,以提高生产力并改善代码质量。
适应平台变更: 注意 macOS 版本要求以及 32 位 Windows ARM 即将弃用的情况。
利用 testing/synctest: 对于包含并发代码的项目,采用 testing/synctest 来编写更可靠和确定性的测试。
遵循安全最佳实践: 注意 TLS.2 中默认禁用 SHA-1,并确保您的应用程序遵循现代加密标准。
v1.25 强化了 Go 语言在更高性能、增强开发者体验以及与云基础设施更深度集成方面的发展轨迹。对实验性功能和社区反馈的重视表明,Go 将在实际使用和性能需求的驱动下继续快速发展,同时保持其简洁和高效的核心原则。
Go 团队于2026年1月下旬发布了一份 2025 年 Go 开发者调查报告,基于来自 Go 开发人员的 5,379 条回复。这是继本年度 Go 生态系统:框架、工具与开发者做法的主要趋势调查后又一调研。三大主要发现为:
1、总的来说,Go 开发者们希望获得帮助,以识别和应用最佳实践,充分利用标准库,并使用更现代的功能扩展语言和内置工具。
2、现在大多数 Go 开发者在寻求信息(例如,学习如何使用模块)或处理繁琐任务(例如,编写重复的类似代码块)时都会使用 AI 驱动的开发工具,但他们对这些工具的满意度一般,部分原因是质量问题。
3、相当高比例的受访者表示他们经常需要查看 corego 子命令的文档,包括 go build、go run 和 go mod,这表明 go 命令的帮助系统有很大的改进空间 。
具体而言,大多数受访者自认为是专业开发人员(87%),并且主要工作使用 Go 语言(82%)。绝大多数受访者也使用 Go 进行个人项目或开源项目(72%)。大多数受访者年龄在 25 至 45 岁之间(68%),拥有至少六年的专业开发经验(75%)。
调查发现 ,81% 的受访者表示他们的专业开发经验多于 Go 语言的开发经验,这有力地证明了 Go 通常不是开发人员接触的第一门语言。事实上,今年调查分析中反复出现的主题之一似乎就源于此:当 Go 语言中完成任务的方式与更熟悉的语言截然不同时,开发人员首先需要学习新的(对他们而言)惯用的 Go 语言模式,然后在继续使用多种语言时,还要始终牢记这些差异,这会带来一定的阻力。
受访者中最常见的行业是 “科技”(46%),但大多数受访者并非从事科技行业(54%)。表示自己使用 Go 语言时间不长(不足一年)的受访者比例有所下降(13%,而 2024 年为 21%)。研究人员推测这与整个行业入门级软件工程师职位数量的减少有关;经常听到人们说他们学习 Go 是为了某个特定的工作,因此招聘人数的下降预计会减少当年学习 Go 的开发人员数量。研究结果也进一步支持了这一假设,超过 80% 的受访者是在开始职业生涯后才学习 Go 的。
绝大多数受访者(91%)表示在使用 Go 语言时感到满意。近三分之二的受访者表示 “非常满意”,这两个指标自 2019 年以来一直保持着稳定。
受访者满意的原因在于他们认为 Go 作为一个整体平台具有巨大的价值。这并不意味着它对所有编程领域的支持都同样出色(当然并非如此),而是意味着开发者们非常看重它通过标准库和内置工具对某些领域提供的良好支持。
就其他编程语言而言。受访者表示,除了 Go 之外还喜欢使用 Python、Rust 和 TypeScript 等多种语言。这些语言的一些共同特点与 Go 开发者反映的常见痛点相吻合,例如错误处理、枚举和面向对象设计模式等方面。
大多数受访者表示,他们目前并未在自己开发的 Go 软件中构建 AI 功能(78%),其中三分之二的受访者表示他们的软件完全不使用 AI 功能(66%)。这似乎表明,与生产相关的 AI 使用率逐年下降;到 2024 年,59% 的受访者表示没有参与 AI 功能开发,而 39% 的受访者表示有一定程度的参与。
在构建基于人工智能或语言学习管理(LLM)功能的受访者中,最常见的用例是创建现有内容的摘要(45%)。然而,总体而言,大多数用途之间的差异不大,28% 至 33% 的受访者添加了人工智能功能,以支持分类、生成、解决方案识别、聊天机器人和软件开发。
53% 的受访者表示他们每天都使用人工智能驱动的开发工具,而 29% 的受访者则完全不使用此类工具,或在过去一个月中仅使用过几次。报告还指出,最常用的 AI 编码助手分别是 ChatGPT(45%)、GitHub Copilot(31%)、Claude Code(25%)、Claude(23%)和 Gemini(20%)。一些其他发现还包括:
1、命令行工具(74%)和 API/RPC 服务(73%)是受访者使用 Go 语言构建项目的前两大类型。库或框架(49%)位列第三。
2、开发者在使用 Go 进行开发时遇到的三大难题分别是 “确保我们的 Go 代码遵循最佳实践 / Go 惯用法”(33%)、“我重视的其他语言中的某个功能在 Go 中没有体现”(28%)以及 “找到值得信赖的 Go 模块和包”(26%)。
3、大多数受访者在 macOS (60%) 或 Linux (58%) 上进行开发,并部署到基于 Linux 的系统 (96%)。
4、Visual Studio Code 是最受欢迎的代码编辑器(37%),其次是 GoLand/IntelliJ(28%)和 Vim/NeoVim(19%)。
5、Go 最常见的部署环境是 Amazon Web Services (46%)、公司自有服务器 (44%) 和 Google Cloud Platform (26%)。
每六个月一次的例行更新的本版本不仅秉承了 Go 注重实用性和稳定性的传统,还在泛型支持、性能优化和标准库增强方面做出了显著改进。接下来总结了解 v1.25 的亮点,并回顾 v1.20 以来的关键更新。
通用优化和性能革命
通用基础的重构:删除“核心类型”概念
v1.25 通过完全删除 v1.18 中引入的“核心类型”概念,对其泛型系统进行了重大增强——这是自泛型添加到语言以来最具影响力的语法调整之一。以前核心类型概念带来了诸多限制:当一个类型集包含具有不同底层类型的类型时(例如~[]byte | ~string),即使某些操作(例如切片s[i:j])对集合中的所有类型都有效,由于缺乏通用的核心类型,这些操作也会被禁止。
这不仅限制了泛型的灵活性,还增加了学习曲线,并引入了规则的不一致性。
v1.25 通过重构语言规范解决了这些问题:
非通用代码直接基于具体类型定义规则,与通用概念脱钩。通用代码统一使用类型集检查来对类型参数的操作进行检查,以验证操作是否对类型集中的所有类型有效。这一改变使得泛型代码更加灵活和强大,同时降低了理解难度,标志着Go泛型发展的一个重要里程碑。
智能调度和 GC “革命”
v1.25 在运行时级别带来了两项重大改进:
1、Cgroup 感知的 GOMAXPROCS
这一功能解决了容器化环境中长期存在的 CPU 资源限制问题。此前,Go 运行时不考虑 CPU 配额——即使在受限容器中,CPU 配额GOMAXPROCS仍会被设置为主机上的逻辑 CPU 数量,从而导致不必要的上下文切换。
新版本会定期检查 Cgroup 限制(间隔 10 秒)并进行动态调整GOMAXPROCS,从而显著减少资源争用和上下文切换开销。
2、实验型垃圾收集器:“greentea” GC
一个通过实验启用的全新垃圾收集器 GOEXPERIMENT=greenteagc,专门针对小对象密集型应用进行了优化。它通过基于大小的对象分类、增量标记优化和批量内存块扫描等技术,其实现了:
内存局部性显著改善
标记阶段的并行性增强
增强扫描效率,减少缓存未命中
总体 GC 开销减少约 40%
这对于内存敏感型服务来说是一大福音。但需要注意的是,这仍然是一个实验性功能,可能会在未来的版本中进行优化调整。
主要标准库升级
v1.25 引入了几个备受期待的标准库更新:
1、编码/json/v2
一个新的 JSON 处理包作为实验性功能发布,几乎完全重写,以解决旧版本的痛点。它提供:
反序列化速度提高 3-10 倍
零堆分配实现
支持大文档的流式处理
新增MarshalFunc/UnmarshalFunc接口,提供更灵活的自定义序列化方式
此功能可以通过启用GOEXPERIMENT=jsonv2,但请注意,API 仍可能根据用户反馈进行调整。
2、测试/同步测试
在 v1.24 中从实验状态毕业,成为稳定软件包。该软件包为并发代码测试提供了强大的支持,解决了 Go 中并发测试的长期难题。
工具链和编译器改进
v1.25 还为工具链带来了重大增强:
DWARF5 支持:编译器和链接器现在使用 DWARF 版本 5 生成调试信息,从而减少调试数据的存储空间,同时缩短大型二进制文件的链接时间。如有需要,可以通过 禁用此功能GOEXPERIMENT=nodwarf5。
切片性能优化:编译器现在可以在堆栈上分配连续的切片,从而显著提高涉及多个连续切片分配场景的性能。
扩展架构支持:Linux/loong64 端口现在支持竞争检测器,Linux/riscv64 端口支持插件功能 - 展示了 Go 对新兴架构的持续承诺。
迁移建议和最佳实践
要升级到 v1.25 及更高版本时,开发小组建议开发者,应该这样谨慎实施:
逐步迁移:尽管 Go 保持了强大的向后兼容性,但仍然建议先在测试环境中验证更改。
启用实验性功能:对于性能敏感的应用程序,尝试启用 GreenTea GC 和 JSON v2,并提供反馈以帮助改进这些功能。
利用新的工具链:用于go get -tool管理工具依赖关系,并用于testing.B.Loop简化基准测试。
注意模块设置:确保声明了正确的 Go 版本以go.mod启用相应版本的新功能。
平台兼容性:请注意,v1.25 需要 macOS 12 或更高版本,并且它将是支持旧版 Windows 组件的最后一个版本。
Go 语言发展趋势
从v1.20到v1.25的演进历程中,我们会发现它出现了几个清晰的发展方向:
持续的泛型优化:从引入到逐步完善,泛型正在成为 Go 生态系统不可或缺的一部分。
不懈追求性能:通过新的 GC 算法、数据结构和编译优化持续提高运行时性能。
增强开发人员体验:解决常见痛点(例如循环变量捕获)并简化并发编程。
云原生适应:加强容器感知,优化受限环境下的性能。
标准库扩展:填补功能空白并减少对第三方库的依赖。
v1.26 版本几乎没有什么引人注目的改动。没有会在 Hacker News 上爆红的新语言特性,也没有“Go 获得异步功能”这样的重大事件。相反,它悄然修复了多年来一直困扰 Go 开发者的问题,并带来了一项真正重要的运行时变更,几乎所有生产服务都将从中受益。
Green Tea现在是默认的垃圾回收器
v1.25 将 GreenTea (绿茶)垃圾回收器作为可选实验方案推出。v1.26 则将其设为默认方案。Go 团队报告称道,在实际程序中, GC 开销降低了 10% 到 40%,如果运行在 Intel Ice Lake 或 AMD Zen 4 或更新的处理器上,还能在此基础上再降低约 10%(因为新的回收器使用向量指令来扫描小对象)。
需要谨慎对待这个数字,因为“10%–40%”这个范围本身意义不大,需要结合上下文才能理解。这里需要说明的是:这是垃圾回收 (GC) 时间的减少,而不是总运行时间的减少。如果你的服务 20% 的 CPU 都花在了 GC 上,那么你只需要将 CPU 使用率降低到 12% 到 18% 之间。这不需要重写代码,简直是轻而易举。
GOEXPERIMENT=greenteagc
无需进行任何操作即可获得此功能。升级到 v1.26 后,您的服务会自动获得此功能。如果已经在 1.25 版本中运行此功能,则可以安全移除该标志。
实际的语言更改:使用新表达式new()
这个虽然是件小事,但也是多年来我一直渴望的改变。在 v1.26 中内置new函数接受一个表达式作为其操作数:
func personJSON(name string, born time.Time)([]byte,error) {
return json.Marshal(
Person{
Name: name,
Age:
new(yearsSince(born)),// ← 这里是new
})
}
在 1.26 版本之前需要分两步编写这段代码:
age := yearsSince(born)
return
json.Marshal(Person{
Name: name,
Age: &age,
})
虽然应用场景比较窄,但确实存在实用点:任何指向可选值的指针字段(JSON、protobuf、gRPC),现在都可以直接内联填充。这种变化在基准测试中可能不明显,但在你做过的每一次代码审查中都会体现出来。可能永远不会直接使用泛型更改。泛型类型不能在其类型参数列表中引用自身的限制已被取消:
type Adder[A Adder[A]]
interface {
Add(A) A
}
这是库作者非常喜欢的特性,而应用程序开发者则无需再编写任何代码。如果你正在构建数学库或集合框架,这将带来更简洁的抽象。如果你正在构建 Web 服务,则可以跳过这一部分。
能够为你节省数小时的工具变革:go fix重生了
这是我最期待的改变,但却是没人谈论的改变。
go fix它已完全重写。现在,它是 Go 语言现代化工具的家园——数十个自动化修复工具,可将你的代码更新为使用现代的惯用法和 API。它使用与 Go 相同的分析框架go vet,这意味着你已经信任的诊断工具现在可以建议并应用修复。
最强大的功能是源代码级内联。如果您维护一个库,并希望用户迁移到新的 API,您可以编写一个//go:fix inline指令,系统go fix会自动重写他们的代码。
实际上,这意味着:
将 Go 项目升级到 1.26现在go fix ./...不再需要使用新的惯用法。
从已弃用的 API 迁移不再是手动执行 grep 和替换操作。
库作者可以通过自动迁移路径发布重大变更。
如果曾经维护过庞大的 Go 代码库,并且害怕收到“升级 Go 版本”的 PR,那么这节就是为阁下准备的。
值得了解的较小运行时变化
v1.26 版本中还包含了其他三项运行时变更:
更快的 cgo 调用。如果你有一个 Go 服务需要调用 C 库(例如数据库驱动程序、图像处理程序或任何封装了 C API 的库),那么 cgo 的开销现在大大降低了。Go 团队尚未公布具体数值,但此次改进旨在降低每次调用的开销,尤其是在高负载路径中。
堆基地址随机化。这是一项安全加固措施。堆基地址现在已随机化,这使得某些内存损坏攻击更难得逞。您在代码中不会注意到这一点,但您的安全团队会在他们的威胁模型中发现它。
实验性 goroutine 泄漏分析。一种新的pprof分析类型,用于检测 goroutine 泄漏。此功能尚处于实验阶段,因此请勿将其用于生产环境调试,但值得在测试套件中尝试。
标准库新增内容
v1.26 发布三个新库,包括如下:
crypto/hpke— 混合公钥加密。如果你曾经需要在不事先进行密钥交换的情况下使用公钥加密数据,那么这就是标准做法。它现在已集成到标准库中,不再是第三方依赖项。
simd/archsimd(实验性)— SIMD 原语。如果您一直想用 Go 编写向量化代码,又不想直接使用汇编语言,那么这就是基础。它目前处于实验阶段,因此 API 会不断变化,但方向很明确:Go 正在认真提升 CPU 级性能。
runtime/secret(实验性)——一个用于管理密钥的软件包,无需将其暴露在堆栈跟踪、崩溃消息或日志中。这种功能早就应该出现了。它目前仍处于实验阶段,但如果按原样发布,将是一项真正的安全改进。
工具清理
应该了解的两项变化:
cmd/doc并go tool doc已被删除。请改用go doc等其他方法。相同的标志,相同的行为。如果你有调用该方法的脚本go tool doc,请立即更新它们。
pprof网页界面默认显示火焰图。如果你更喜欢旧版图表视图,它仍然位于“视图”→“图表”下,或者在/ui/graph中
可以忽略什么
并非版本发布中的每一项变更对每位开发者都至关重要。以下变更可以忽略:
自引用泛型类型更改——除非你在编写数学库,否则你不会碰它。
新的实验性软件包(simd/archsimd,runtime/secret)——它们是实验性的,API 将会改变,你现在不应该用它们构建生产系统。
平台特定的更改(Darwin、FreeBSD、Windows、PowerPC、RISC-V、S390X、WebAssembly)——只有在部署到这些平台时才重要。
你要做什么
将非生产环境服务升级到 1.26 版本。看看 Green Tea 是否能带来版本说明中承诺的 GC 改进。
go fix ./...先在一个小项目上运行一下。看看现代化工具会给出什么建议。你会惊讶地发现,你的代码中有多少地方还在使用过时的写法。
new(expr)下次编写 JSON 序列化函数时可以尝试一下。这只是一个小小的改动,但累积起来会效果显著。
真正的要点
v1.26 版本不会引发任何会议型的讨论,但它能让你现有的代码运行得更快、升级更轻松、代码库更简洁,而你无需做任何事情。单凭Green GC就值得升级,go fix重写也值得升级,new(expr)改动也值得升级。随便选一项,升级就值回票价。