CgroupsV2发行使用录
 Cgroups(control groups)是 Linux 内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu、内存等资源实现精细化的控制,开发者也可以使用 cgroups 提供的精细化控制能力,限制某一个或者某一组进程的资源使用。
Cgroups(control groups)是 Linux 内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu、内存等资源实现精细化的控制,开发者也可以使用 cgroups 提供的精细化控制能力,限制某一个或者某一组进程的资源使用。腾讯云TKE团队提交基于cgroupsv2的Memory QoS
随着云原生进入深水区,很多用户希望通过业务混部提升集群利用率。但由于 kernel 限制,部分资源隔离性不强,会导致业务受损。在这种背景下,腾讯云 TKE 团队向 Kubernetes 社区提交了KEP-2570: Support Memory QoS with cgroups v2,以希望解决内存隔离和服务质量问题。该提案和实现代码已被社区接受,计划在 Kubernetes v1.22 发布 alpha 版。
在原有方案中,Kubernetes 通过 cgroups v1 实现 CPU 和 Memory 隔离。CPU 属于可压缩资源,通过 cpuset.cpus/cpu.cfs_period_us/cpu.cfs_quota_us/cpu.shares 实现绑核、分核与权重等隔离。在节点 CPU 紧张时,任务只会被 throttle,不至于被 kill,影响范围可控。但 Memory 这类不可压缩资源,在节点内存不足时会触发 OOM Killer,通过 oom_socre_adj 做 kill 操作。这对部分 Burstable Pod 是不可接受的。而且某些内存消耗型 Pod 在创建和运行中会短时申请大量内存,导致节点内存瞬间飙升。节点内存紧张可能会导致内存高敏 Pod 在申请内存时触发慢路径,从而影响服务质量。cgroups v1 无法解决此类 Memory QoS 问题。
但幸运的是,cgroups v2 memory controller 为我们提供了丰富的参数用于实现内存预留与分配限速。在我们提交的 KEP 中,主要使用 memory.min/memory.high 实现容器/Pod/Burstable QoS 的内存保留与分配限速。
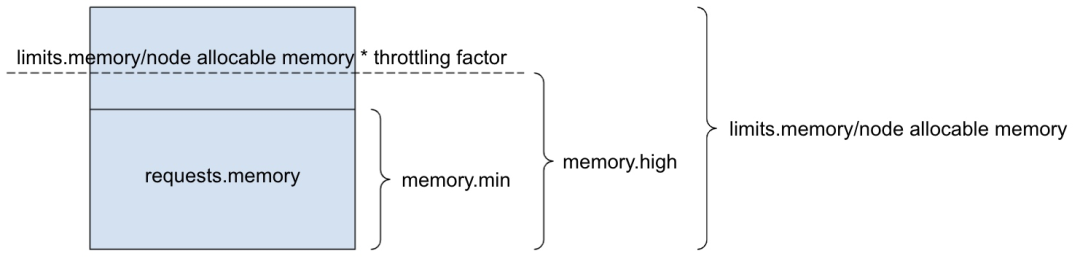
内存保留
对于容器,通过 memory.min=pod.spec.containers[i].resources.requests[memory] 为容器保留申请内存
对于 Pod,通过 memory.min=sum(pod.spec.containers[i].resources.requests[memory] 为 Pod 保留申请内存
对于 Burstable QoS,通过 memory.min=sum(pod[i].spec.containers[j].resources.requests[memory]) 为 Burstable Pods 保留申请内存
分配限速
若容器设置 limits.memory,我们通过 memory.high=pod.spec.containers[i].resources.limits[memory] * memory throttling factor 为容器超申请内存做分配限速
若容器未设置 limits.memory,我们通过 memory.high=node allocatable memory * memory throttling factor 为容器超申请内存做分配限速
更多设计细节可查阅此处。
目前实现代码已合入社区,详情见:
Feature: add unified on CRI to support cgroup v2
Feature: Support memory qos with cgroups v2
展望
随着 Linux cgroups v2 成熟和普及,以及 Kubernetes cgroups v2 支持进入 alpha,我们相信未来 Kubernetes 的资源 QoS 会逐渐 offload 到内核,资源隔离更多依赖内核进行强隔离。只有在这种趋势下,基于 Kubernetes 的大规模资源混部才会真正普及。
作者:徐蓓,腾讯云专家工程师,深耕云计算、Kubernetes、离在线混部领域,Kubernetes 社区积极贡献者。
Ubuntu 21.10 将默认使用 Cgroups v2
2021年8月中旬消息,根据邮件列表显示,Ubuntu 21.10 计划默认使用统一的 cgroup 层次结构 (Cgroups v2) 发布其 systemd 包。
在邮件中,Ubuntu 开发人员承认该计划已经 “拖延了很长时间”,上游 systemd 早已默认使用 Cgroups v2 层次结构,其它的 Linux 发行版,比如 Debian,则从 2019 年开始就切换到该结构,新近发布的第11版中就正式地启用了cgroup v2。上游 Snap 虽然目前没有支持,但已经有相关补丁在这个周期中被合并。因此Ubuntu 也将使用统一 cgroupsv2 层次结构支持的 systemd。此外,如果出于某种原因,用户需要保留传统的 cgroup v1 层次结构,则可以在启动时通过内核参数选择它:systemd.unified_cgroup_hierarchy=0。
IBM 为 Linux 内核提出新的命名空间机制
命名空间(Namespace)是 Linux 内核的一个特性,它对内核资源进行分区,使得一组进程看到一组资源,而另一组进程看到一组不同的资源。该功能的工作原理是为一组资源和进程使用相同的命名空间,但这些命名空间引用不同的资源。资源可能存在于多个空间中。此类资源的示例包括进程 ID、主机名、用户 ID、文件名以及一些与网络访问和进程间通信相关的名称。

IBM 工程师 Pratik Sampat 2021年10月发表了 Linux 内核的 CPU Namespace 接口的早期原型。设计这个命名空间是为了解决当前查看可用 CPU 资源的方法的一致性问题,以及解决因了解系统上的资源访问/位置而可能产生的安全问题。
如今,在容器上运行的应用程序在 cgroups 的帮助下执行它们的 CPU、内存限制与要求。然而,许多应用程序通过 sysfs/procfs 继承或以其他方式获得系统的视图,并根据这些信息分配资源,如线程/进程的数量,内存分配。这可能会导致意外的运行行为,并对性能产生很大影响。除了一致性问题,目前的处理方式也给多租户系统带来了安全和公平使用的影响,例如:
攻击者可以在知道 CPU 节点拓扑的情况下调度工作负载并选择 CPU,从而使总线被淹没而造成拒绝服务攻击;以及识别 CPU 系统拓扑结构可以帮助识别靠近总线和外围设备(如 GPU)的内核,以便从其他工作负载中获得不适当的延迟优势。因此,由 IBM 领导的 CPU Namespace 提案追求以下设计:
这个原型补丁集引入了一个新的内核命名空间机制 —— CPU Namespace。
CPU Namespace 通过虚拟化逻辑 CPU ID 和创建相同的虚拟 CPU 映射来隔离 CPU 信息。它锁定在 task_struct 上,并且 CPU 转化被设计成扁平的层次结构,这意味着每个虚拟命名空间 CPU 在创建命名空间时都映射到一个物理 CPU,转化速度更快;并且子代不需要向上遍历树来检索转化。该命名空间允许控制和显示接口都能够感知 CPU 命名空间上下文,这样命名空间内的任务只能通过虚拟 CPU 映射获取视图并因此控制它,以及查看可用的 CPU 资源。
在用 Nginx Web 服务器进行的测试中,内存利用率下降了 92-95%,延迟减少了 64%,每秒的请求和传输等吞吐量没有显著变化。虽然目前的设计仍有存在一些缺陷,但随着 IBM 的持续改进,Linux 的性能有望大幅提升。