Linux Kernel 进入4.x时代
 ------------------------------
------------------------------Linux内核进入4.0时代
2015年4月13日消息,今天早些时候 Linux 创始人 Linus Torvalds 在 Kernel 的 GitHub Master 中提交了一个改动,将 Kernel 正式从 3 时代带入 4 时代,即Linux 4.x内核相关发行记录。

Linux 4.0 主要包括以下特性:
“实时内核补丁”特性,该特性由 Red Hat 的Kpatch 和 SUSE 的 kGraft 合并而来,可以实时修补内核,而无需重启。
改进图形支持,Radeon DRM 驱动支持显示端口的音频输出,改良了风扇控制。HSA AMDKFD 开始对 Carrizo APU 进行开发;Intel 图形驱动方面,Skylake 支持已经基本成型;对 N 系显示方案的支持也有所改进。
储存系统方面的改进,包括 pNFS、Btrfs RAID 5/6 的相关支持,OverlayFS 也加入了一些新功能。
此外,新内核支持更多硬件,包括 Intel Quark SoC 以及更多ARM设备、IBM z13,改进了东芝系列笔记本、罗技输入设备的支持。
Linux 4.0 的发布让用户可以不需要重启操作系统。在大多数的服务器或者数据中心里,喜欢用 Linux 的一个原因是你不需要频繁的进行重启操作。诚然,某些关键性的补丁必须要进行重启,但你也可以等到数月后再做此操作。现在得益于 Linux 4.0 内核的发布,你也许可以数年间都不用重启。
Linux 发布版指的就是通常所说的“Linux操作系统”,它一般是由一些组织、团体、公司或者个人制作并发布的。Linux内核主要作为 Linux 发布版的一部分而使用。通常来讲,一个Linux 发布版包括 Linux 内核,以及将整个软件安装到电脑上的一套安装工具,还有各种 GNU 软件,和其他的一些自由软件,在一些 Linux 发布版中可能会包含一些专有软件。发布版为许多不同的目的而制作,包括对不同电脑硬件结构的支持,对普通用户或开发者使用方式的调整,针对实时应用或嵌入式系统的开发等等。目前,超过三百个发布版被积极的开发,最普遍被使用的发布版有大约十二个。较为知名的有 Fedora、Debian、Ubuntu 和Mageia 等。Linux 发行版也经常使用作为超级计算机的操作系统,2010年11月公布的超级计算机前 500 强,有 459 个(91.8%)运行 Linux 发行版。
1991年的10月5日,Linus Torvalds 在 comp.os.minix 新闻组上发布消息,正式向外宣布 Linux 内核的诞生,1994年3月,Linux 1.0 发布,代码量 17 万行。
Linux 4.0 kernel 有1403名开发者贡献了代码,为内核增加了 403,000行代码,删除了222,000行,净增181,000行。Linus Torvalds将 4.0 kernel称为是一次小更新,从状态树的变化来说确实如此。在Linux 4.0的开发中,最活跃的雇主是英特尔,其次是Red Hat,此外还有三星、Linaro、SUSE、思科、德州仪器和IBM等。根据代码行数统计贡献最多的开发者是Ben Skeggs,根据变更集统计贡献最多的开发者是Lars-Peter Clausen。
过去几十年涌现了许多类Unix内核,除了Linux内核外,我们所知道的类Unix内核还有GNU HURD、BSD、微软授权开发的Unix版本Xenix、学术性的Unix克隆Mini,以及Unix本身。但为什么只有Linux内核最终取得成功?这是自由开源软件领域中一个令人不解的谜团。
ESR(Eric S. Raymond)的一个观点是Linux采用了去中心化的开发模式,而GNU HURD失败的原因之一是开发方法过于集中化,但这一观点有缺陷,Linux作者在引导Linux开发上起着至关重要的作用。
另一个观点是Linux是实用主义,而GNU过于理想主义,但为什么理想主义的GNU开发出了许多成功的自由软件?
第三种观点是Linux在操作系统设计上比Unix更优越,RMS曾指出GNU HURD没有成功的部分理由是它的基本设计更像是一个研究项目。第四个观点是社区选择支持Linux。
---------------------------------------
Linux 内核 4.4 LTS 详细说明
2016年1月10日,Linux 历史翻开了新的一页,Linus Torvalds 以及千千万万辛勤的程序员们正式发布了 Linux 内核 4.4 LTS 版本(长期支持版)。
在这个版本中,最重要的更新莫过于在虚拟 GPU 驱动中支持了 3D 功能,这可以让虚拟机使用宿主机的 3D 硬件渲染功能。也就是说,现在可以在虚拟机中使用宿主机的 GPU 加速能力来玩 OpenGL 游戏了。
经过两年的努力,重构了 TCP 的实现,使 TCP 监听器的快速路径完全无锁化,可以支持更大的伸缩性和更快的 TCP 服务器了。在一台测试服务器上,每秒钟处理了 3,500,000 个 SYN 包仍富有余力,有可能还能提升2-3个数量级。
在 RAID/LVM 层增加了对日志型 RAID 5 阵列的支持。在日志型设备中,比如 NVRAM 或 SSD,写入到阵列的数据会首先写入到日志,然后才会写到阵列中。如果发生故障就可以从日志中恢复,加速阵列重新同步。同时修复了 RAID 的 Write Hole 问题。
此外,引入了支持异步 IO(Asynchronous I/O)和直接 IO(Direct I/O) 的更加精简快速的回路(loop)设备,从而提升了系统性能并减少了内存占用;通过 LightNVM 支持了开放通道固态硬盘;非特权用户可以运行 eBPF 程序了,从而实现了持久化运行,同时 pref 也增加了对 eBPF 程序的支持;支持块轮询Block polling以改善高端存储设备的整体性能;全新的 mlock2() 系统调用可以在内存页错误时锁住内存。
“这周没有什么意外发生,所以 Linux 4.4 如期到达。和之前的 4.4 rc8 差异不大”,Linus Torvalds 说,“其中有1/3的架构方面的更新、1/3的驱动和1/3的其它方面的更新(主要是一些内核和网络方面的),但是这些改动都很小。也许值得注意的是 x86-32 的 'sysenter' ABI,有些人(比如 android-x86)可能误用了它,没有使用 vdso 而是直接使用了该指令。”
完整的更新说明请参见 Linux Torvalds 的发布公告。
Linux 内核 4.4 LTS 是目前最新的长期支持内核分支,如果你想尝试一下,你也可以从 kernel.org 网站下载源代码,自己构建即可。
-------------------------------------------------------
Linux 已成为计算机史上最大的软件开发项目
2016年5月,Linux内核开发者和维护者Greg Kroah-Hartmant在柏林举行的CoreOS Fest上发表演讲,描述了Linux内核项目的庞大规模。 Kroah-Hartman称,最新版的Linux 4.5内核包含了超过2100万行代码,其中核心代码占5%,网络相关的代码占35%,驱动超过40%。
设备供应商可以根据自己的需要选择使用内核代码,他表示自己的笔记本电脑运行的内核只有160万行代码,而你的手机内核可能只有240万代码。Kroah-Hartman说,最令人影响的地方不是代码行数而是参与的人数:去年有大约4000名开发者和至少440家公司向内核贡献了代码。根据使用的人数,开发的人数,参与的公司数量——Linux是计算机历史上最大的软件项目。
------------------------------------------------
Linux Kernel 社区澄清 GPLv2 执法
今年(2017)早些时候,德国的 Netfilter 内核子系统贡献者 Patrick McHardy 引发了争议,他自行担负起了 GPL 执法的角色,他联络了德国的许多企业,以不遵守 GPL 为由索要小额金钱。在 18 个月内他利用这种方法勒索到了 200 万欧元。
他的行为招致了 Netfilter 项目的公开反对。自由软件社区认为需要尽快解决这种问题,否则会有越来越多的人模仿,可能会导致越来越多的企业停用 Linux。Patrick McHardy 的账号已经被 Netfilter 项目以违反执行原则为由封掉。
现在 Linux 基金会的技术委员会发布文件正式回应了有关 GPL 执法的担忧,文件得到了内核开发者的签名或支持。文件称,他们视采取法律行动为最后的手段,只有在社区的努力未能解决问题之后才会启动。一旦未遵守许可证的问题解决,用户将会重新被欢迎加入到 Linux 项目。
------------------------------------------------
Linux 内核 4.16 发布
此版本的显著变化包括:
对 Jailhouse 虚拟机管理程序的初始化支持
对用户拷贝白名单强化补丁程序
对 deadline 调度器的一些改进
对 Meltdown 和 Specter 漏洞的缓解工作
网络修复
固件升级
scsi 和 rdma 等驱动程序修复
------------------------------------------------
Linux Kernel 4.20 正式发布
在经过数个测试版本后,Linux Kernel 4.20 终于在圣诞前夕迎来了正式版本。Linus Torvalds 在邮件中写道:“看起来似乎没有理由再推迟 4.20 版本的发布,因为大家要准备休息了,圣诞节快乐!”
4.20 版本的更新亮点包括:
BPF 网络流解析器
taprio 流量调度器
PCI 层中的点对点 DMA 支持
支持 C-SKY 架构
pressure-stall 检测机制
XArray 数据结构
……
内核新增 AMD 7nm Zen2 架构优化
AMD 7nm Zen2处理器预计将在明年一季度大规模上市,其中第二代EPYC霄龙先行,随后是消费级锐龙Ryzen平台。经查,Linux 4.21内核新鲜增加了对AMD 7nm EPYC Rome(罗马)处理器的优化。
7nm Rome在设计上进行了一些大胆创新,比如结构上,CPU核心和I/O Die分离,DDR控制器也与I/O核心绑定,这意味着内存延迟将加大,同时CPU访问L3的速度也会牺牲。不过,内核调优后,新增了规定L3缓存限制、优先级和内存带宽强制执行的QoS域。这将有助于为新架构做好更广泛的软件生态系统准备,并可能避免新设计的一些古怪之处。此外这次调优也是为了更好地利用AMD Zen2的新编译器“znver2”,它支持包括 写回和不失效缓存(WBNOINVD), 读取处理器ID(RDPID)以及缓存线写回 (CLWB)等命令,后者可用于开启非易失性内存。
具体细节可查阅邮件列表和官方文档。
------------------------------------------------
eBPF 概念和基本原理
eBPF是Linux内核4.x正式引入的技术,让程序员在不修改内核空间的情况下,能够在内核中执行自定义的字节码并从内核函数中获取更多信息。原本这些目标需要通过系统调用或内核模块来完成,eBPF 降低了所需的复杂度和危险性。简单来说,eBPF 的工作流程:
把 eBPF 程序编译成字节码。
在载入到 Hook 之前,在虚拟机中对程序进行校验。
把程序附加到内核之中,被特定事件触发。
JIT 编译。
在程序被触发时,调用辅助函数处理数据。
在用户空间和内核空间之间使用键值对共享数据。
有了 eBPF,无需修改内核也不用加载内核模块,程序员也能在内核中执行自定义的字节码。eBPF 和内核紧密联系,先介绍一些相关的基本背景概念。
Linux 系统分为内核空间和用户空间。内核空间是操作系统的核心,对所有硬件都具备不受限制的完整的访问能力,例如内存、存储以及 CPU 等。内核既然具备了这样的超级权限,势必需要严加保护,仅允许运行最可靠的代码。而用户空间运行的就是非内核的进程——例如 I/O、文件系统等。这些进程仅能通过内核开放的系统调用,对硬件进行有限的访问。换句话说,用户空间的程序一定要经过内核空间的过滤。
系统调用接口能够满足绝大多数需要,开发者在面对新的硬件、文件系统、网络协议甚至自定义的系统调用时,还是需要更多的弹性的。在不修改内核源码的情况下,用户代码要直接访问硬件怎么办呢?可以使用 Linux 内核模块(LKM)。用户空间一般是需要通过系统调用来访问内核空间,而 LKM 是直接加载到内核的,是内核的一部分。LKM 最有价值的特点之一,就是可以在运行时加载,不用编译内核也不用重启机器。
LKM 非常有用,但是也引入了很多风险。内核和用户空间不同,要进行不同的安全考量。内核空间是为了操作系统内核这样的特权代码准备的。系统调用连接了内核和用户空间,让用户空间能够对硬件进行合适的操作。换个说法,LKM 是能够让内核崩溃的。模块和内核的紧密关系,使得安全和升级成本直线升高。
eBPF 是一个用于访问 Linux 内核服务和硬件的新方法,这一新技术已经用于网络、出错、跟踪以及防火墙等方面。
dtrace 是一个 Solaris 和 BSD 操作系统上的动态跟踪工具,eBPF 受到 dtrace 的启发,原意是设计一个更好的 Linux 跟踪工具。跟 dtrace 不同的是,Linux 无法获取运行中系统的鸟瞰视图,它被系统调用、库调用以及函数所限制。一部分工程师在 Berkeley Packet Filter(BPF)基础之上,构建一个内核虚拟机级别的包过滤机制,提供了类似 dtrace 的功能。2014 年第一个版本适配了 Linux 3.18,提供的功能相对较少。要使用完整的 eBPF,需要 Linux 4.4 或以上。
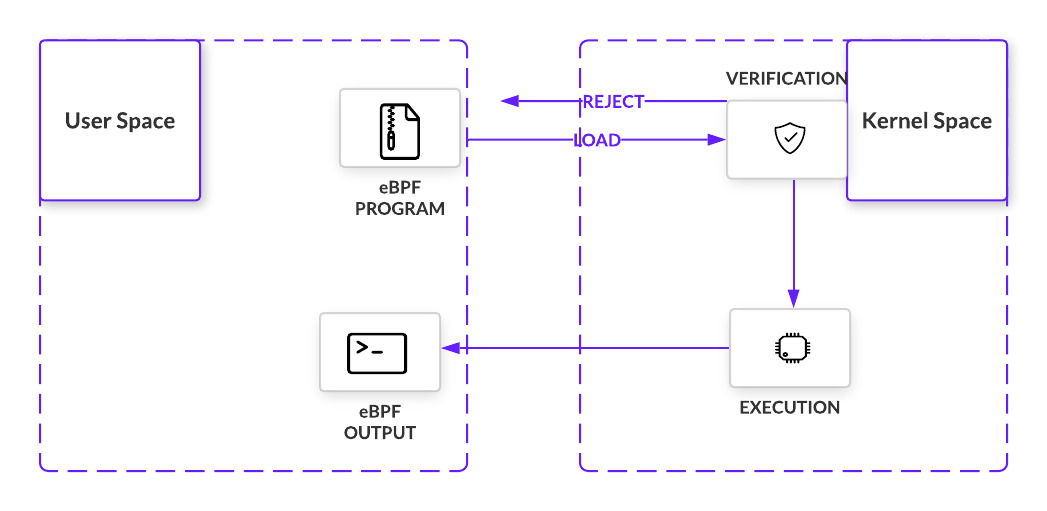
上图对 eBPF 架构进行了一个简单的展示。eBPF 程序需要满足一系列的需求,才能被加载到内核。Verifier 中有一万多行代码用来对 eBPF 程序进行检查。Verifier 会遍历对 eBPF 程序在内核中可能的执行路径进行遍历,确保程序能够在不出现导致内核锁定的循环的情况下运行完成。除此之外还有其它必须满足的检查,例如有效的寄存器状态、程序大小以及越界等。安全控制方面,eBPF 和 LKM 是颇有差异的。
如果所有的检查都通过了,eBPF 程序被加载并编译到内核中,并监听特定的信号。该信号以事件的形式出现,会被传递给被加载的 eBPF 程序。一旦被触发,字节码就会根据其中的指令执行并收集信息。
所以 eBPF 到底做了什么?程序员能够在不增加或者修改内核代码的情况下,就能够在 Linux 内核中执行自定义的字节码。虽说还远不能整体取代 LKM,eBPF 程序可以自定义代码来和受保护的硬件资源进行交互,对内核的威胁最小。
eBPF 的这些能力是由多个组件协同实现的,每一种都有自己的复杂度。下对其程序结构剖析:
事件和钩子
eBPF 程序是在内核中被事件触发的。在一些特定的指令被执行时时,这些事件会在钩子处被捕获。钩子被触发就会执行 eBPF 程序,对数据进行捕获和操作。钩子定位的多样性正是 eBPF 的闪光点之一。例如下面几种:
系统调用:当用户空间程序通过系统调用执行内核功能时。
功能的进入和退出:在函数退出之前拦截调用。
网络事件:当接收到数据包时。
kprobe 和 uprobe:挂接到内核或用户函数中。
辅助函数
eBPF 程序被触发时,会调用辅助函数。这些特别的函数让 eBPF 能够有访问内存的丰富功能。例如 Helper 能够执行一系列的任务:
在数据表中对键值对进行搜索、更新以及删除。
生成伪随机数。
搜集和标记隧道元数据。
把 eBPF 程序连接起来,这个功能被称为 tail call。
执行 Socket 相关任务,例如绑定、获取 Cookie、数据包重定向等。
这些助手函数必须是内核定义的,换句话说,eBPF 程序的调用能力是受到一个白名单限制的。这个名单很长,并且还在持续增长之中。
要在 eBPF 程序和内核以及用户空间之间存储和共享数据,eBPF 需要使用 Map。正如其名,Map 是一种键值对。Map 能够支持多种数据结构,eBPF 程序能够通过辅助函数在 Map 中发送和接收数据。
eBPF 程序的执行
加载和校验
所有 eBPF 程序都是以字节码的形式执行的,因此需要有办法把高级语言编译成这种字节码。eBPF 使用 LLVM 作为后端,前端可以介入任何语言。因为 eBPF 使用 C 编写的,所以前端使用的是 Clang。但在字节码被 Hook 之前,必须通过一系列的检查。在一个类似虚拟机的环境下用内核 Verifier阻止带有循环、权限不正确或者导致崩溃的程序运行。如果程序通过了所有的检查,字节码会使用 bpf() 系统调用被载入到 Hook 上。
JIT 编译器
校验结束后,eBPF 字节码会被 JIT 编译器转译成本地机器码。eBPF 是 64 位编码,共有 11 个寄存器,因此 eBPF 和 x86、ARM 以及 arm64 等硬件都能紧密对接。虽然 eBPF 受到 VM 限制,JIT 过程保障了它的运行性能。
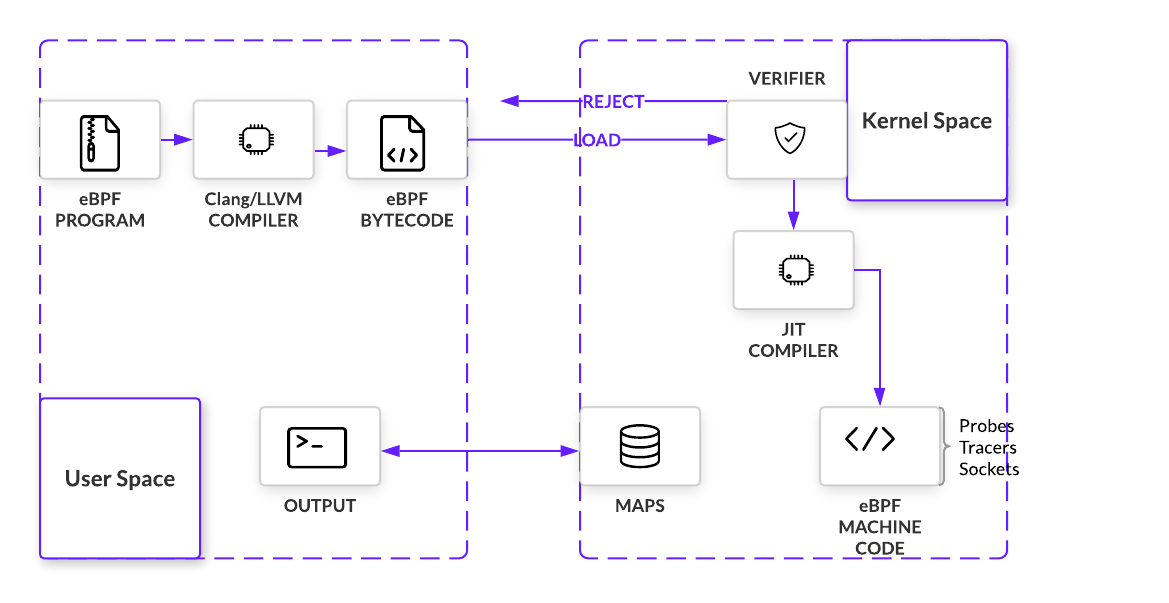
上面的概念们放在一起,eBPF 程序通过安全检查后插入钩子,被事件触发之后,程序会启动执行,用辅助函数和 Map 来对数据进行存储和操作。
自行编写代码,开发自己的 eBPF 可能有点难。但是很多开源的开发工具链正在涌现,简化了很多 eBPF 的相关场景,介绍几个最流行的:
BCC:BCC 是一个工具包用于创建高效的内核跟踪和处理程序,并包含了很多有用的工具和示例。BCC 简化了 BPF 程序的开发,内核指令使用 C 指令(包含了 LLVM 的封装),前端使用的是 Python 和 LUA。BCC 有很多用途,例如性能分析和网络流量控制。BCC 还为其它程序提供了 API。
bpftrace:BPFtrace 是一个高级跟踪语言,用 LLVM 作为后端把脚本编译为 BPF 字节码,并用 BCC 和 Linux BPF 系统进行交互,并支持现有的 Linux 跟踪能力:kprobe、uprobe 以及 tracepoint。
Go、C/C++ 以及 Rust 的通用库。
该文章最后由 阿炯 于 2024-08-22 15:12:34 更新,目前是第 2 版。