数据库年度报告(202x)
 本文收录了业界对数据库领域的点评,2030年之前截止,供各位参考。
本文收录了业界对数据库领域的点评,2030年之前截止,供各位参考。2021
2022年2月上旬消息,原文作者 Andy Pavlo 是卡内基梅隆大学计算机科学系数据库专业副教授,也是初创公司 OtterTune(为数据库提供自动调优服务)的联合创始人。译文转自Bytebase
数据库产业经历了爆发式增长的一年。在这一年里,数据库产业后浪推前浪,厂商围绕性能测试结果展开角逐,更有一轮又一轮额度惊人的融资。同时,在经历了一系列并购、破产和退出之后,我们也不得不同一些熟悉的数据库告别。年关将至,在正式进入 2022 年之前,这些事件也值得我们做一次盘点、总结与反思。以下是部分要点事件。关于它们在数据库领域的意义,我做的一些思考。
PostgreSQL 的统治力
开发者的习惯已经转变,PostgreSQL 成了新应用的首选。它可靠性高,功能丰富且依然在持续完善中。2010 年,PostgreSQL 的开发团队转而采用了更为激进的发布策略,每年进行一次大的版本更新(感谢 Tomas Vondra)。当然 PostgreSQL 还是开源项目。
如今很多系统都把兼容 PostgreSQL 作为差异化竞争力。这种兼容性是通过支持 PostgreSQL 的 SQL 方言 (DuckDB),传输协议 (QuestDB, HyPer),或者整个 Server 层前端 (Amazon Aurora, YugaByte, Yellowbrick) 来实现的。重量级玩家也已经入局。十月,谷歌宣布在 Cloud Spanner 中兼容 PostgreSQL。同样是在十月,Amazon 宣布了 Babelfish 的功能,它可以转换 SQL Server 的查询,用于 Aurora PostgreSQL。
DB-Engines 排行榜是衡量数据库流行度的标尺。这份排行不是十全十美的,评分也带有主观色彩。但它评选出的前十名还是基本合理的。排行榜显示,截止到 2021 年 12 月,PostgreSQL 在最受欢迎的数据库中仍旧位列第四,排在 Oracle 、MySQL 和 MSSQL 之后。不过在过去一年里它与 MSSQL 之间的差距已经缩小了。
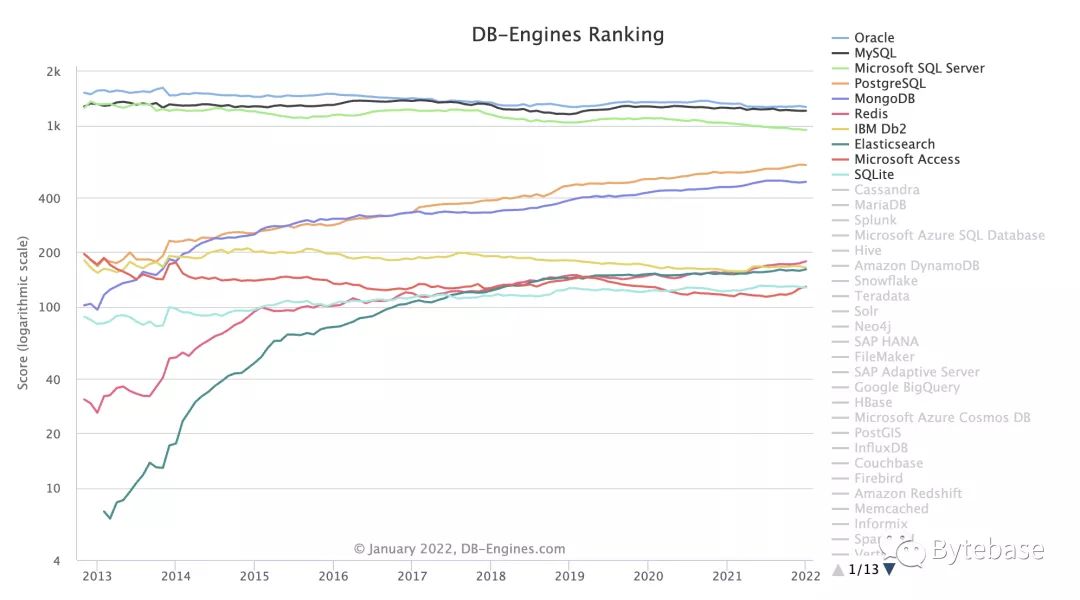
另一个值得思考的点是 PostgreSQL 在线上社区中被提及的频次。这为我们提供了另一种视角,让我们窥见当人们讨论数据库时他们究竟在讨论什么。我下载了 2021 年度 Reddit 中 Database 板块上的所有评论,并清点了各个数据库名称在其中出现的频次 (当然我是用 PostgreSQL 做这项工作的)。我从我的 Database of Databases 中交叉引用了我了解的所有数据库的列表,对缩写做了清洗(例如, Postgres → PostgreSQL, Mongo → MongoDB, ES → Elasticsearch),最后计算出了十个最常被提及的 DBMS:
dbms | cnt
---------------+-----
PostgreSQL | 656
MySQL | 317
MongoDB | 266
Oracle | 222
SQLite | 213
Redis | 88
Elasticsearch | 70
Snowflake | 52
DGraph | 46
Neo4j | 42
当然这张排名表没那么科学,因为我没有对这些评论做情感分析。然而,它确实清晰地展现出,在过去一年里,相较于其他数据库,PostgreSQL 被人们提及的频次要更多。经常有开发者发帖询问该选择哪一个 DBMS 来开发新应用。社区成员对此的回答几乎总是 PostgreSQL。
Andy 观点:先要说明,一个关系型数据库成为待开发应用的首选是件好事。这说明 Tedd Codd 的关系模型自上世纪七十年代长盛不衰。其次,PostgreSQL 是个伟大的数据库系统。当然和其他所有 DBMS 一样,它也有各种已知和未知的问题。但 PostgreSQL 已经赢得了如此之多的注意,人们也在其上灌注了许多精力。在这两点的加持下,它只会发展得越来越好。
性能测试乱战
这一年,各个数据库厂商对性能测试结果的热爱没有丝毫消退。从上个世纪八十年代起,它们就试图证明自己的数据库系统要快于竞争对手的产品。TPC 就是在这一背景下建立的。它为数据库间的比较提供了一个客观公允的平台。但在过去十年间,TPC 的影响力逐渐消退,普及度渐渐下降。于是如今,我们又被卷入了新一轮的数据库性能测试大战中。
这一年,围绕性能测试结果展开了三场激烈争斗。
Databricks vs.Snowflake
Databricks 宣布他们的新 Photon SQL 引擎在100TB TPC-DS 上创下了新的世界纪录。Snowflake 随即回击,声称自己的数据库要二倍于这个速度,而且 Databricks 没有正确运行 Snowflake。Databricks 予以反击,宣称他们的 SQL 引擎有着最佳的执行效率,性价比也高于 Snowflake。
Rockset vs.Apache Druid vs.ClickHouse
ClickHouse 跳了进来,表示自己在成本效率上完胜 Druid 和 Rockset。但先别急:作为回应,Imply对 Druid 的新版本进行了一系列测试,并宣告了胜利。Rockset 插进来,声称自家产品在实时分析方面的表现要优于另外两家。
ClickHouse vs.TimescaleDB
Timescale 嗅到了血腥气,下场参战。他们发布了自己的性能测试结果,逮到机会指出了 ClickHouse 技术上存在的弱点。有关第三方性能测试的讨论成了 Hacker News 的热门。
Andy 观点:在先前的性能测试争夺战里,数据库社区已是血流漂杵。我承认我也曾热衷于此。但在争吵中我失去了很多朋友。有一次,我甚至因为乱七八糟的性能测试结果和女朋友分了手。年岁渐长之后,我可以说这一切都不值得。现如今,要在不同的系统之间做对比变得更加困难。因为云 DBMS 有许多可变的部分和可调节的选项。所以要断定表现差异背后的真实原因通常会很困难。真实场景下的应用也不仅仅是在一遍又一遍地执行同一条指令。录入、变换和清洗数据时的用户体验和干巴巴的性能测试结果同等重要。正如我在此文中和采访者谈论 Databricks 的性能测试结果时说的那样,只有老古董才会在意 TPC 官方数据。
大数据,大投资
从 2020 年下半年开始,额度超过 1 亿美元的融资轮数一直在平稳增长。2020 年共有 327 次这种大额融资。这占据了近半风险投资总交易额。在 2021 年 1 月,一亿美元以上的风投轮数已经过百。
2021 年,许多投资都流向了数据库公司。在事务型数据库领域,CockroachDB 领跑募资大赛。CockroachDB 开年即进行了一轮 1.6 亿美元的融资,并在 2021 年 12 月募资高达 2.78 亿美元,为这一年画上句号。Yugabyte 则完成了 1.88 亿美元的 C 轮融资。作为 Vitess 的托管版本,PlanetScale 开启了 2000 万美元的 B 轮融资。NoSQL 的拥趸,相对较老的 DataStax 也在一轮风投中为他的 Cassandra 生意募集到了 3760 万美元。
这些数字已经很让人印象深刻了,然而分析型数据库的市场甚至要更加火热。2021 年 9 月,TileDB 完成了一轮融资,未透露具体金额。Vectorized.io 为他们兼容 Kafka 的流式平台募集到了 1500 万美元。StarTree 也走到台前,宣布完成了一轮 2400 万美元的融资,用以商业化 Apache Pinot。matviews-on-steroids DBMS Materialize 宣布他们在 C 轮融资中募集到了 6000 万美元。Imply 为基于 Apache Druid 的数据库服务筹集到了 7000 万美元。SingleStore 在 2021 年募集到了 8000 万美元,这让他们离 IPO 又近了一步。这一年伊始,Starburst Data 为 Trino 系统(前身是 PrestoSQL)募集了 1 亿美元。另一家走到台前的 DBMS 创业公司 Firebolt 宣布他们为自己基于 ClickHouse 分支的新型云数据仓库募集到了 1.27 亿美元。ClickHouse 募集到了惊人的 2.5 亿美元,用以围绕该系统建立一家新公司,同时也取得了对 Yandex 名下 ClickHouse 这一名称的使用权。但今年,当之无愧的融资冠军要属 Databricks,它以在 2021 年 8 月高达 16 亿美元的融资额力压群雄。
Andy 观点:我们正处在数据库的黄金时代。如今我们有许许多多优秀的选择。投资人正在数据库领域的创业公司中寻求下一个 Snowflake 式的 IPO。这些公司的融资额要远超先前的数据库创业公司。举例来说,直到 D 轮融资,Snowflake 的单轮融资额才达到了 1 亿美元。此时距它初创已经过去了五年。而 Starburst 在成立的三年内便完成了一轮 1 亿美元的融资。当然影响融资的因素有很多。比如说,在脱离 TeraData 出来创业之前,Starburst 的团队就已在 Presto 上躬耕多年。但在我看来,现如今有更多的资金正在涌向这一领域。
纪念堂
很遗憾,在过去的一年里不得不向几位老朋友说再见。
ServiceNow 收购了 Swarm64
这个公司最初的产品是一款 FPGA 加速器,用以在 PostgreSQL 上运行分析任务。之后,他们转向了单纯的软件加速器,为 PostgreSQL 提供插件。但他们缺乏持续发展的动力,尤其是相比其他资金充裕的云数据仓库。在被 ServiceNow 收购后,Swarm64 的产品前景仍不明朗。
Splice Machine 破产了
Splice 推行的是一个混合型 DBMS。它结合了针对事务型任务的 HBase 和针对分析的 Spark SQL。他们更进一步推出了服务于操作型/实时机器学习应用的平台。然而,由于专门的 OLTP 和 OLAP 系统的统治地位,这样一个多位一体的混合系统没能在数据库市场开辟出一条道路。
私募公司收购 Cloudera
过去五年,MapReduce 和 Hadoop 技术渐渐为潮流所抛弃。因此,Cloudera 也同样失去了在云数据仓库市场发展的动力。Impala 和 Kudu 的初代工程师团队大多都已经离开公司,尽管这些项目依旧在持续开发并迭代新版本。它的当前股价已经低于 2018 年 IPO 时的发行价。它的新投资人是否有能力扭转公司局面还有待观望。
Andy 观点:看到数据库项目和公司走上下坡路总归让人伤心,但这就是数据库产业内部的厮杀博弈。开源也许能让一款 DBMS 在母公司消失之后也能继续存在,但事实并不总是如此。由于数据库本身的复杂性,它必须要有全职员工进行维护,修正 bug 并添加新功能。不是说把破产 DBMS 的源代码权限和控制交到 Apache 软件基金会和 CNCF 这样的开源软件基金会手中,这个项目就会奇迹般复活了。
举例来说,公司破产后,RethinkDB 被捐赠给了 Linux 基金会。但从 GitHub 的各项表现看,它已经死透了(基本没有提交,PR 也不并入)。有类似遭遇的还有 DeepDB:它的母公司在倒闭后为它创立了自己的非盈利基金会,但没有人再去维护这个项目了。在下一年里,预计还会有更多的数据库公司因无力与大型云服务商和之前提到的众多资金充裕的创业公司抗衡而走上下坡路。
野火烧不尽
对很多人来说,疫情期间是段艰难的时光。在听到了这么多坏消息后,突然有个振奋人心的故事总能让人倍感欣慰。众所周知,甲骨文联合创始人 Larry Ellison 近几年的运气一路下滑。2015 年的时候,他气运还不错,那时他是世界上第五富有的人。然而人生起起伏伏。到了 2018 年,Larry 在富豪排行榜上已经跌到了第十位。
但在 2021 年 12 月,一切都变了。Larry Ellison 的身家超过了谷歌联合创始人 Larry Page 和 Sergey Brin,重回世界第五富的位置。2021 年 12 月,在公布了超预期的公司收入后,甲骨文的股价经历了过去二十年来的单日第二高涨幅,Larry Ellison 当天挣到了 160 亿美元。媒体将这归功于投资人高涨的信心。他们相信甲骨文向云端转变的策略起效了。
Andy 观点:我和 Larry 相识已久。不管对于数据库社区,还是对于全体人类来说,这都是件好事。运气不好滑到世界第十富的时候他可能有点伤心。但我很高兴能看到他走出低谷,重新回到应有的位置上去。
除了家人,数据库是我生命中最重要的事情。我们期望能够引领崭新的一年。数据库是一个有着高度韧性和创新性的行业,我们很高兴能成为其中的一份子。
PostgreSQL 2022 报告:流行度上涨,开源、可靠性和扩展是关键
Timescale 于2022年8月上旬发布了一份 2022 年 PostgreSQL 现状调查报告。调查持续时间为 2022 年 6 月 6 日到 6 月 30 日,共收到了来自全球各地 992 名开发者的回复。PostgreSQL 现状调查提供了对 PostgreSQL 功能和更广泛的 PostgreSQL 社区的一些重要见解。
2019 年发布的第一版报告收集了 500 多名开发人员的反馈,2021 年的第二版报告也抽样调查了近 500 名参与者。根据这两年的调查结果,来自EMEA(欧洲、中东、非洲)的受访者约占所有受访者的一半,其次是北美,占 25.9%。除了将调查发送给过去的参与者之外,Timescale 还在社交媒体、电子邮件通讯(他们自己的和第 3 方)、TimescaleDB 和 PostgreSQL Slack 频道、PostgreSQL 邮件列表、Reddit 和 Hacker News 上进行了推广。相较前两次,今年参与调查的人数有所增加。报告的主要发现包括:受访者为什么使用 PostgreSQL,他们如何对社区做出贡献,在各组织中的采用情况,以及最喜欢的工具和扩展。
通过组织和发布 PostgreSQL 状态报告,我们帮助开发人员和以开发人员为中心的公司和社区更好地了解 Postgres 正在发生的事情:不同类型的 Postgres 用户、他们正在处理的用例类型、他们去过的地方分享和学习,这一切是如何变化的,以及整个 Postgres 社区的改进机会,这也让我们有机会回馈更广泛的 PostgreSQL 社区,我们很自豪能够成为这个社区的一员,并且对我们非常有帮助。报告中的一些亮点内容包括:
DB engines 数据指出,PostgreSQL 正变得越来越流行。尝试使用该数据库不到一年的 PostgreSQL 新用户数量已经从 2021 年的 6.1% 增长到了 2022 年的 6.4%。
开源是大众选择 PostgreSQL 的第一大理由(19.3%),其次是可靠性(16.5%)和扩展(9.9%)。报告指出,选择 PostgreSQL 的原因随着经验的增长而变化。就使用 PostgreSQL 还未满 5 年的人来说,开源是他们选择 PostgreSQL 的最重要因素;对于那些使用了 PostgreSQL 6-10 年的人来说,可靠性和开源都很重要;使用 PostgreSQL 达 11-15 年的人选择 PostgreSQL 则主要是因为它的可靠性。
具有 15 年以上经验的 PostgreSQL 用户中,有 44% 至少为 PostgreSQL 做出过一次贡献。事实上,无论他们的经验如何,所有用户都为 PostgreSQL 社区做出了贡献。
55% 的受访者表示如今 PostgreSQL 的使用量比一年前更多。超过 3/4 的受访者表示将 PostgreSQL 用于个人项目,95% 的受访者在工作中使用 PostgreSQL ,74% 的受访者将 PostgreSQL 用于个人和专业项目。
大多数受访者 (76.2%) 表示技术文档是他们学习 PostgreSQL 的首选方式,其次是长篇博文 (51.5%) 和短篇博文 (43.3%)。拥有少于 5 年 PostgreSQL 经验的受访者更喜欢视频而不是博客文章。
在社区互动上,虽然有一些受访者提到使用 PostgreSQL 邮件列表作为与核心团队和整个项目交互的主要方式存在困难,但超过 20% 的受访者表示邮件列表是他们与社区保持联系的方式之一。其他的一些参与渠道包括 Slack (10%)、Stack Overflow (8%)、博客 (8%)、Twitter (6%) 和 Reddit (6%)。
受访者还分享了他们最喜欢的一些 PostgreSQL 扩展。排名靠前的依次有:PostGIS、TimescaleDB、pg_stat_statements、pgcrypto、pg_trgm、Citus、uuid-ossp。
SQL、Python、Java、Perl、shell 脚本和 JavaScript / TypeScript 被列为访问 PostgreSQL 最常用的语言。相较 Java,具有 0-5 年经验的 PostgreSQL 用户更有可能使用 JavaScript 或 TypeScript;拥有 6 年以上经验的用户更有可能使用 shell 脚本来访问数据库。
在使用工具连接 PostgreSQL 进行查询和管理任务的受访者中,psql (69.4%)、pgAdmin (35.3%) 和 DBeaver (26.2%) 是前三位的选择。Grafana、pgAdmin 和 DBeaver 是最可能使用的可视化工具。
与 2019 年和 2021 年相比,表示会自行管理 PostgreSQL 数据库的受访者越来越少。似乎 PostgreSQL 用户开始越来越多地使用 DBaaS 供应商来部署 PostgreSQL。在将 PostgreSQL 部署为 Kubernetes 容器的人中,44% 使用 Helm,16% 使用 Crunchy Operator,7% 使用 Zalando Operator。更多详情可查看完整报告。
Teradata 在华落幕
2023年2月15日,Teradata宣布基于中国未来商业环境评估,退出在中国的直接运营,后续将进入中国公司关闭程序。根据Teradata对中国当前和未来商业环境的慎重评估,我们做出了一个艰难的决定,Teradata将逐步结束在中国的直接运营;Teradata后续将进入中国公司的关闭程序。Teradata在华运营实体「天睿信科(北京)有限公司」显示参保人数为277人。
在《Gartner 2022 年云数据库管理系统(DBMS)魔力象限》中,Teradata与AWS、微软、甲骨文、谷歌、Snowflake、SAP、阿里云、Databricks、MongoDB、Clouddera、IBM 一同被评为“领导者”。
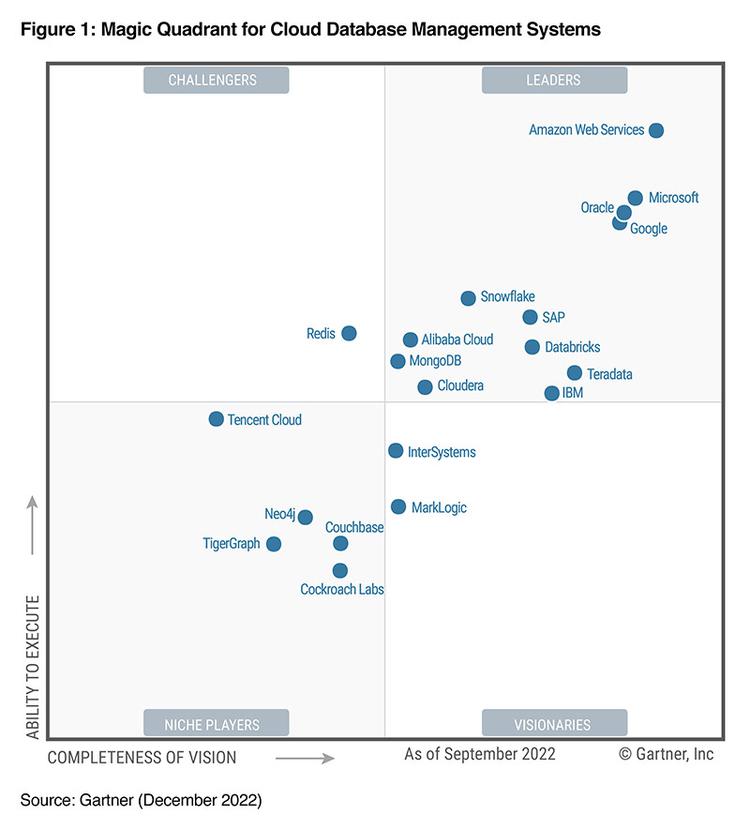
其在2022年营收为17.95亿美元,2021年为19.17亿美元,下降6%;GAAP营业利润为1.18亿美元,2021年为2.31亿美元。
上海银行将在2024年6月30前完成整体数据仓库迁移,不再使用Teradata;上海浦东发展银行启动了数据仓库平台重构建设项目,对现有Teradata数据仓库平台实施迁移、整体替换,实现安可要求;天津银行迁移工作已完成招标。2022年12月2日,上海银行股份有限公司发布《新一代数据仓库建设项目》招标公告,最高投标限价 4706 万元(含税)。
本项目拟通过公开招标选定一家合格的单位为招标人单位提供数据仓库建设。具体建设内容包括:
(1)提供服务器、存储、交换机等设备及相关服务,服务器 CPU 采用符合 ARM 架构的 CPU;
(2)提供 MPP(大规模并行处理)数据库软件(须配套同品牌的云平台软件生产环境软件涵盖开发测试环境软件);
(3)提供迁移实施服务:2024 年 6 月 30 日前完成数据仓库整体迁移上线,并配合招标人做好上线试运行准备;
(4)提供原厂技术服务:包括运维服务和开发技术支持服务。
投标人资格要求第三条条款明确要求:近三年投标人至少具有一家总资产规模大于 1.5 万亿银行业的总行级数据仓库从 Teradata 迁移至本次投标 MPP 数据库产品的实施案例。
2023年1月4日发布中标结果公示,中电金信软件有限公司(中)。中标候选人:
第一:中电金信软件有限公司
第二:深圳市长亮科技股份有限公司
2023年1月12日,上海浦东发展银行发布《数据仓库平台重构建设项目》资格预审公告。
浦发银行数据仓库平台自建设以来,承载了“高时效、强整合”数据处理场景,整合了全行业务数据,支撑客户管理、风险管理、运营管理、财务管理、监管报送等关键数据应用。为满足数据仓库平台安全可靠的建设要求,支撑浦发银行数据应用的后续发展,浦发银行启动了数据仓库平台重构建设项目,对现有Teradata数据仓库平台实施迁移、整体替换,实现安可要求。
项目建设以“高效稳定、快速承载、技术先进、安全可靠”为原则,要求完成现有Teradata数据仓库平台的快速迁移,同时保障迁移过程中的业务平稳性。投标人需提供完整的集成迁移方案,完成MPP分析型数据库安可产品的提供,新数据仓库集群的搭建,实施现有Teradata数据仓库平台上所有模型、数据和数据作业的快速迁移,快速承载“高时效、强整合”的数据处理场景,实现数据仓库平台的重构。
2022年6月30日,天津银行股份有限公司发布《监管报送系统迁移至大数据平台改造项目》竞争性磋商公告,预算 120.00 万元。
项目背景:
2010年,为满足天津银行股份有限公司整体发展策略,赢得市场先机,实现全行统一的数据存储及业务分析,天津银行股份有限公司搭建了Teradata数据仓库并依托数据仓库建立了监管报送系统(34套),实现了全行监管报送系统数据的统一存储、加工和计算,在天津银行股份有限公司长期发展建设过程中扮演了重要角色。
近几年,随着互联网金融的蓬勃发展及大数据技术的兴起,银行业务经营模式正在发生深刻的变革,天津银行股份有限公司也逐步向数字化、智能化、精细化转型。按照IT规划的总体要求,为提升自主可控能力,2020年天津银行股份有限公司启动数据仓库整体向大数据平台的迁移,并于2021年完成了基础数据、个人客户集市、对公客户集市的迁移工作。同时随着监管政策趋严,各监管机构对各项监管数据报送的时效性、准确性以及全行整体的数据处理、运算能力提出了更高的要求。基于以上考虑,今年我部计划启动监管报送系统向大数据平台迁移工作,将现有基于数据仓库建设的34套监管报送系统迁移到大数据平台。以大数据平台为“底座”,整合各系统数据,进行统一的加工、汇总,提升系统的整体运行效率,形成满足要求的监管数据。
项目目标:整合、分析现有生产环境中的监管报送系统应用接口,进行迁移、改造技术评估,实现监管报送系统的现存所有应用接口平稳迁移至大数据平台,保障生产环境中各监管报送系统现有用数接口的完整性、准确性和连续性以及数据报送的稳定性。
Andy说数据库的2021到2023
本节收集了2024年2月由卡内基梅隆大学计算机科学系数据库学副教授 Andy Pavlo 总结的从 2021 到 2023 连续三年对数据库领域的回顾,希望通过连续三年的回顾让你对数据库领域的技术发展有所了解。
关于 Andy Pavlo:卡内基梅隆大学计算机科学系数据库学副教授,数据库调优公司 OtterTune 的 CEO 兼联合创始人。
为了聚焦于数据库技术趋势演变,本文未对原文 “寒暄式” 开头和注释性语句作翻译。此外,为了节约部分读者的时间,本文分为 “观点简述” 及 “历年回顾” 两部分:在 “观点简述” 部分,你将了解到 Andy 这 3 年对数据库的看法、见解;在 “历年回顾” 部分,你将了解到该年具体的数据库领域发生的事件,以及 Andy 对该事件的看法。
观点简述
历年回顾
2023 年数据库回顾:向量数据库虽然大火,但没有技术壁垒
向量数据库的崛起
Andy 说:向量数据库没有技术护城河
SQL 持续变好
属性图查询(SQL/PGQ)
多维数组(SQL/MDA)
Andy 说:SQL:2023 是个里程碑
MariaDB 的困境
Andy 说:数据库的声誉比以往任何时候都重要
美国航空因政府数据库崩溃而停飞
Andy 说:历史悠久的核心数据系统,是每个数据库从业者最大的噩梦
数据库的融资情况
Andy 说:无论初创公司,还是高估值的公司日子都不好过
史上最贵的密码重置
Andy 说:意料之外的大人物生活
2022 年数据库回顾:江山代有新人出,区块链数据库还是那个傻主意
放缓的大规模数据库融资
Andy 说:不只是 OLAP 领域,OLTP 领域前景也一样严峻
区块链数据库还是那个蠢点子
Andy 说:有让人信服的用例才是合格的新技术
新的数据系统
Andy 说:欣然看到数据库领域的勃勃生机
数据库先驱的逝世
Andy 说:这是一个让人难过的消息
数据库的巨额财富和民主
Andy 说:Larry 干得漂亮
2021 年数据库回顾:性能之争烽烟起,不如低调搞大钱
PostgreSQL 的主导地位
Andy 说:PostgreSQL 只会在未来几年变得更好
基准测试之争
Databricks vs Snowflake
Rockset vs Apache Druid vs ClickHouse
ClickHouse vs TimescaleDB
Andy 说:性能之争不值当
大数据搞大钱
Andy 说:我们正处在数据库的黄金时代
消逝的数据库们
ServiceNow 收购了 Swarm64
Splice Machine 破产了
私募公司收购了 Cloudera
Andy 说:2022 年可能会有更多的数据库公司倒闭
坚持的回报
Andy 说:为 Larry 高兴
观点简述
从 2021 年兴起的数据库性能之争,似乎经过 2 年时间的洗礼,热度有所降低,2022、2023 的数据库厂商们相对 Peace 并没有发起过多的性能战。枯木又逢春,尽管向量数据库存在已久,2023 年 vector database 又大火的一把。不过在 Andy 看来,向量数据库并没有技术壁垒:有多种现成的集成方式,可快速集成向量能力到现有的数据库,这些集成方式甚至还有开源的,更是大大降低数据库厂商的集成成本。SQL 新规范 SQL:2023 在对图数据的支持上,虽然目前只是做了读查询的适配,在 Oracle v23c 给出了 Oracle 的图查询示例。不过,目前跟进 SQL/PGQ 的 DBMS 不多,像是 DuckDB 的实验性分支;此外,Andy 觉得 SQL/PGQ 对现有的图数据库并不会造成威胁,毕竟还有查询的性能问题需要攻克。在多维数组的支持上,SQL 新规范强化了数组功能,支持了真正意义上的数组 —— 任意维度的数组。
在融资方面,2021 年是融资大年,各类数据库无论是初创还是老牌数据库厂商都能融到八位数的融资;到了 2022 年,上半年依旧保持着 “好融资,融资高” 的劲头,但在下半年融资情况急转直下,大额度的融资变少了,资金缩紧。这个情况延续到了 2023 年,除了市场融资变冷清之外,更多的资金集中到了同向量相关的领域,虽然还是有一些数据库厂商 “破局” 成功融到了钱。
在数据库可持续发展方面,自 2021 年 Swarm64、Cloudera 被收购,Splice Machine 破产之后。随后的 2022、2023 年,MarkLogic、Ahana、EverSQL、Seafowl 也先后分别被 Progress Software、IBM、Aiven、EnterpriseD 收购,结束了他们的 “独立” 生涯。
这 3 年也发生了一些逸事,比如 Oracle 的联合创始人 Larry Ellison 虽然在 2018 年在亿万富翁排名中跌至第十位,但是在 2021 年重返第五位,甚至在 2023 年仅次于 Bernard Arnault、Elon Musk、Jeff Bezos 以 1,070 亿美元名列第四。此外,Larry Ellison 在 2023 年还花了 10 亿给 Elon Musk 来重置他的 Twitter 密码好继续他的推特之旅。习惯用子女名来命名数据库的 MySQL、MaxDB、MariaDB 之父 Monty Widenus 估计最近的日子不好过,因为 MariaDB 的公司和基金会发生了一些矛盾,不仅如此,它的市值还蒸发了 90%。
除了上面的一些事件,像是美国航空因政府数据库崩溃而停飞 11,000 多架飞机、区块链数据库是个蠢点子之类的指控,就得你翻阅历年回顾了。
历年回顾
2023 年数据库回顾:向量数据库虽然大火,但没有技术壁垒。英文原文
向量数据库的崛起
毫无疑问,2023 年是向量数据库的一年。尽管几年前相关的某些系统早已存在,但去年人们对 LLM 及其上构建的服务(例如,ChatGPT)的广泛关注让向量数据库成为大家的视线焦点。向量数据库旨在基于语义,而不仅仅是数据内容来提供更深层的数据检索能力,特别是针对非结构化数据。也就是说,应用程序可以搜索与主题相关的文档(例如,“有 Slinging 相关歌曲的 hip-hop 团体”),而不是包含精准关键字(例如,“Wu-Tang Clan”)的文档。
这种主题搜索所依赖的 “魔法” 是 transformer,它将数据转换为一个固定长度的一维浮点数向量,称之为嵌入 Embedding。人类虽然不能直接理解这些嵌入的值,但嵌入的内容编码了参数和 transformer 训练语料库之间的某种关系。这些嵌入向量的大小从简单 transformer 的数百维到高端模型的数千维不等。
假如,我们使用 transformer 为数据库中的所有记录生成嵌入,就能通过查找与给定输入在高维空间中最相近的记录嵌入来搜索相似记录。然而,暴力比较所有向量以找到最相近的匹配结果是非常昂贵的。这种暴力搜索的复杂度是 O (N * d * k),其中 N 是嵌入的数量,d 是每个向量的大小,k 是你想要的匹配数量 —— 你可能不知道这个复杂度代表什么,反正很糟糕就是。
这也促成向量数据库的崛起。本质上,向量数据库只是一个带有特定索引数据结构的文档数据库,以加速对嵌入的相似性搜索。不同于对查询进行精准匹配来找到最相似的向量,向量数据库用近似搜索来生成结果,在速度和精度之间做了权衡,这种结果做出了 “足够好” 的折中。
在 2022 年区块链数据库神话崩盘之后,风投们嗅到了向量数据库的商机,再次变得兴奋。他们几乎投资了向量数据库领域的所有主流玩家(厂商)们。在 2023 年的种子轮融资中,Marqo 爆出了一个 520 万美元的种子轮,Qdrant 拿到了 750 万美元的种子轮,而 Chroma 则融到一个巨额的 1,800 万美元种子轮。同年 4 月,Weaviate 在 B 轮成功融到 5,000 万美元。最抢眼的还是 2023 年 Pinecone 在 B 轮融到让人羡慕的 1 亿美元。很显然,向量数据库公司在正确的时间点出现在了正确的赛道。
Andy 说:向量数据库没有技术护城河
自从 LLM 在 2022 年末随着 ChatGPT 变成热点,在不到一年的时间,多家 DBMS 厂商便添加了自己的向量搜索扩展,其中包括有 SingleStore、Oracle、Rockset 和 ClickHouse。同时,不少基于 PostgreSQL 的数据库产品也宣布支持向量搜索;有些使用 pgvector 扩展(像 Supabase、AlloyDB),而另外一些则使用其他的开源 ANN(近似最近邻算法,Approximate Nearest Neighbor)库,比如:Timescale、Neon。此外,领先的 NoSQL 数据库,像 MongoDB 和 Cassandra,也支持了向量索引。
我们将多个 DBMS 对向量的快速支持,和先前 JSON 数据类型的兴起做个有意思的对比。在 2000 年代后期,原生存储 JSON 的 NoSQL 系统变得流行(像 MongoDB 和 CouchDB)。但在之后几年时间里,关系型 DBMS 的老牌厂商才添加了对 JSON 的支持,像 PostgreSQL、Oracle 和 MySQL 分别是在 2012、2014 和 2015 年支持的该类型。SQL 标准虽在 SQL:2016 中添加了操作 JSON 数据的函数,但直到 SQL:2023 才添加了官方的 JSON 数据类型。尽管许多关系型 DBMS 已经支持了概念上相似的 XML,这种适配的拖延还是让人唏嘘。
向量搜索索引的快速支持有两个可能的解释。第一个是能通过嵌入进行的相似性搜索越发重要,以至于每个 DBMS 厂商都快速推出了自己的向量版本并第一时间宣布该消息。第二个是引入新的访问方法和索引数据结构所需的工程成本如此低,以至于 DBMS 厂家们添加向量搜索并不需要太多工作。大多数厂商甚至没有从头开始编写向量索引,而是直接集成了几个可用的高质量开源库之一,像是 Microsoft DiskANN、Meta Faiss。
DBMS 集成向量搜索能力的成本如此低,向量 DBMS 厂商根本没有足够深的护城河来抵抗现有 DBMS 的侵略,保持竞争优势。
我最近和两家公司 Pinecone 和 Weaviate (上面提到融资成功的向量数据库厂商)的联合创始人聊过,他们可以走两条路(详情参考 Andy 对话 Weaviate CTO 的采访视频)。第一条路是,客户开始用向量 DBMS 作为 “记录数据库”,厂商将为操作型工作提供更好的支持。最终,向量数据库会看起来更像流行的文档 DBMS,比如:MongoDB。接着,在五年内,像之前的 NoSQL 一样增加对 SQL 的支持。另一条路是,向量 DBMS 作为次级数据库,通过上游操作型 DBMS 的变更进行更新。就像人们使用 Elastic 和 Vespa 这样的搜索引擎 DBMS 一样。在这种情况下,向量 DBMS 可以在不扩展它们的查询语言或拥有更结构化的数据模型的情况下生存。
旁注:我最近录制了一个关于向量与关系数据库的问答节目。在里面我提到了,每个关系型 DBMS 在未来五年内都将拥有一个高性能的向量索引实现。
SQL 持续变好
今年 2024 年是 Don Chamberlain 和 Ray Boyce (RIP) 在 IBM 研究院创建 SQL 的五十周年。最初被称为 SEQUEL(Structured English QUEry Language,结构化英语查询语言)的 SQL,自 1980 年代以来,一直是与数据库交互的事实标准。尽管 SQL 已经很老了,但它的使用情况和功能一直在增加,尤其是过去的十年。
去年,ISO/IEC 9075 规范的最新版本 SQL:2023 面世。这次更新包括了不少用来处理各种 SQL 方言中的痛点和不一致性的 “好用功能”,比如:ANY_VALUE)。值得一提的是,当中两个 SQL 增强功能,进一步削弱了对替代数据模型和查询语言的需求。不过需要注意一点,新的 SQL 规范包含这些内容,并不代表你喜欢的关系型 DBMS 会立即支持这些新特性。
属性图查询(SQL/PGQ)
目前,SQL 支持对图进行只读查询。这允许应用程序在现有表上声明一个属性图结构。下面这个 Oracle v23c 的图示例,它记录了哪些人在哪支乐队中:
CREATE TABLE PEOPLE (ID INT PRIMARY KEY, NAME VARCHAR(32) UNIQUE);
CREATE TABLE BANDS (ID INT PRIMARY KEY, NAME VARCHAR(32) UNIQUE);
CREATE TABLE MEMBEROF (PERSON_ID INT REFERENCES PEOPLE (ID),
BAND_ID INT REFERENCES BANDS (ID),
PRIMARY KEY (PERSON_ID, BAND_ID));
CREATE PROPERTY GRAPH BANDS_GRAPH
VERTEX TABLES (
PEOPLE KEY (ID) PROPERTIES (ID, NAME),
BANDS KEY (ID) PROPERTIES (ID, NAME)
)
EDGE TABLES (
MEMBEROF
KEY (PERSON_ID, BAND_ID)
SOURCE KEY (PERSON_ID) REFERENCES PEOPLE (ID)
DESTINATION KEY (BAND_ID) REFERENCES BANDS (ID)
PROPERTIES (PERSON_ID, BAND_ID)
);
它由 DBMS 决定是为属性图创建辅助数据结构(例如,邻接矩阵)还是仅跟踪元数据。你可以用 MATCH 关键字在 SQL 中编写图遍历查询,这个语法建立在现有查询语言(像是 Neo4j 的 Cypher,Oracle 的 PGQL 和 TigerGraph 的 GSQL)的基础上,并且兼容了新兴的 GQL 标准。以下查询返回每支乐队的成员数:
SELECT band_id, COUNT(1) AS num_members
FROM graph_table ( BANDS_GRAPH
MATCH (src) - [IS MEMBEROF] -> (dst)
COLUMNS ( dst.id AS band_id )
) GROUP BY band_id ORDER BY num_members DESC FETCH FIRST 10 ROWS ONLY;
截至 2024 年 1 月,我知道的唯一支持 SQL/PGQ 的 DBMS 是 Oracle。DuckDB 的实验性分支虽然也支持 SQL/PGQ,但上面示例不能运行,因为两个数据库支持的语法略有不同。你可以从 CWI/DuckDB 研究员 Gabor Szarnyas 整理的这个 SQL/PGQ 的优秀资源列表中了解更多关于 SQL/PGQ 的信息。
多维数组(SQL/MDA)
从 SQL:1999 引入有限的单维度、固定长度数组数据类型以来,SQL 就支持数组类型。而 SQL:2003 更是增强了该功能,支持嵌套数组,而无需预定义最大基数。在 SQL:2023 中,SQL/MDA 部分更新支持了使用整数坐标的真正的多维数组,这些数组可以是任意维度。此外,Rasdaman 的 RQL 大大地启发了 SQL/MDA 语法,SQL 可以提供与其兼容,并与集合语义正交的结构和操作数组构造。借此让应用程序只用在 SQL 中与多维数组交互和操作,而无需将它们导出,例如:到 Python Notebook。下表展示了在 CREATE TABLE 语句中使用 MDARRAY 数据类型的不同示例:

尽管 SQL/MDA 规范在 2019 年以技术报告的形式出现,但直到 SQL:2023 它才被正式纳入 SQL 标准。据我所知,除了 Rasdaman 之外,没有其他生产级别的 DBMS 支持 SQL/MDA 扩展。我能找到的唯一其他数据库是 ASQLDB,一个数据库 HSQLDB 的分支。
Andy 说:SQL:2023 是个里程碑
SQL:2023 修订版是 SQL 这种通用查询语言持续进化和改进的下一个阶段。当然,SQL 并不完美,也不具备真正的可移植性,因为每个 DBMS 都有自己的特点、专有特性和非标准扩展。就像我个人就非常喜欢 PostgreSQL 的 :: 转换操作符快捷方式。
虽然 SQL/PGQ(SQL 对图的支持)是个大事,但我不觉得它会立即对图数据库造成威胁,因为已经有多种方法将面向图的查询转换为 SQL。包括 SQL Server 和 Oracle 在内的 DBMS 都提供了内置的 SQL 扩展,可以容易地存储和查询图数据。Amazon Neptune 则是在 Aurora MySQL 之上的图数据服务层。Apache AGE 在 PostgreSQL 之上提供了一个 openCypher 接口。我预测其他主流 OLAP 数据系统,例如:Snowflake,Redshift,BigQuery,都会在不久的将来支持 SQL/PGQ。
但在一个 DBMS 中添加 SQL/PGQ 并不像添加新语法那样简单。要确保图查询性能良好,需要考虑几个工程上的问题。例如,图查询执行多路连接来遍历图。但当这些连接的中间结果比基础表还大时,问题就来了。一个 DBMS 必须使用最坏情况下最优连接(WCOJ,Worst-case optimal join)算法来更有效地执行两表联合查询,而不是通常用来连接两个表的 hash join。另一个技术要点是使用因式分解来避免在连接过程中物化冗余的中间结果。这种类型的压缩让 DBMS 规避了一遍又一遍地用相同的连接记录导致内存耗尽的问题。
上面我提到的优化点,并不是说现有的图数据库都做到了。据我所知,像是 Neo4j、TigerGraph 等图数据库都没有实现。我唯一知道的实现了优化的是滑铁卢大学的嵌入式图数据库 Kuzu。大多数关系型数据库也没有实现它们,至少我知道的那些开源数据库没有。上面提到的 DuckDB 实验分支实现了 WCOJ 和因式分解优化,并在 2023 年的论文中显示,在一个行业标准的图基准测试中,其性能比 Neo4j 高出多达 10 倍。
我很久之前说过,SQL 可能在你出生之前就存在,到你去世它依然会存在。对于那些声称自然语言查询将完全取代 SQL 的说法,我依旧嗤之以鼻。
旁注:从上次我公开说到 2030 年图数据库都不会在数据库市场上超过关系型数据库以来,已经两年过去了。到目前为止,我还是对的。
MariaDB 的困境
过去的一年,MariaDB 频频出现在新闻报道中,而且大多数都不是什么好消息。独立于 MariaDB 基金会的 MariaDB 公司显然是一个混乱的公司。在 2022 年,这家公司试图借壳 SPAC 上市,但是股票($MRDB)在 IPO 后的三天内立即跌了 40%。而为了加速在纽交所上市进度的借壳操作也被公诸于世。到 2023 年底,MariaDB 公司股价自开盘以来跌了 90% 以上。
因为这些糟糕的财务问题,MariaDb 公司宣布了两轮裁员。第一轮在 2023 年 4 月,但同年 10 月他们进行了另一轮更大规模的裁员。公司还宣布他们将关停两款产品:Xpand 和 SkySQL。前者是 MariaDB 公司在 2018 年收购的产品,当时它还被称为 Clustrix;我在 2014 年还参观了 Clustrix 的旧金山办公室,当时我觉得那里像个阴森的鬼城(办公室里一半的灯都熄灭了)。后者 SkySQL 的历史更加复杂。最初它只是一个提供 MariaDB 服务的独立公司,在 2013 年与 Monty Program AB 合并。在 2014 年,合并后的 Monty Program AB + SkySQL 公司变成了今天的 MariaDB 公司。但在 2023 年 12 月,公司又宣布 SkySQL 没有 “死去”,而是作为一个独立公司重新回到了市场!
MariaDB 公司的情况如此糟糕,以至于 MariaDB 基金会的 CEO 专门写文章,抱怨自从 MariaDB 公司上市以来基金会与公司的关系是如何恶化,他希望能够重新审视彼此关系。雪上加霜的是,微软在 2023 年 9 月宣布,未来不再提供作为托管 Azure 服务的 MariaDB,而是改为采用 MySQL。可能有人不知道,MariaDB 本身就是 MySQL 的一个分支,是 MySQL 的原创始人 Monty Widenus 在 2009 年 Oracle 宣布收购 Sun Microsystems 后创建的。回忆下,Oracle 在 2005 年买了 InnoDB 的制造商 InnoBase,Sun 在 2008 年买了 MySQL AB。现在 MySQL 运行良好,MariaDB 却遇到了问题。戏剧来源于现实,多看看数据库市场你能吃到各种瓜!
Andy 说:数据库的声誉比以往任何时候都重要
过去的十年,数据库客户的精明程度有了大幅度的提升。各家公司也不再能仅凭华而不实的性能数字、取代 SQL 的新查询语言,或是名人效应来 “扮成功直到真正成功”了。数据库的声誉比以往任何时候都更为重要,其背后的公司声誉也同样重要。也就是说,这意味着软件本身的稳定很重要,其公司也得有条不紊地运作。
开源数据库背后的公司如果倒闭了,很少数据库能继续发展和繁荣。不过,PostgreSQL 算一个例外,尽管今天我们用的开源版本是基于加州大学伯克利分校的源码,而不是 1996 年被 Informix 收购的商业版本 Illustra。另一个例子是,为 MySQL 构建 InfiniDB OLAP 引擎的公司在 2014 年破产后,其 GPLv2 源码被接手并作为 MariaDB 的 ColumnStore 持续发展。
相反,更多现实告诉我们,一旦支付最多开发费用的公司消失,对应的数据库就会逐渐衰落。唯二在某种程度上算是活下来数据库的例子是 Riak 和 RethinkDB。Basho 在 2017 年破产后,现在 Riak 由在 UK's NHS 工作的一个人维护。RethinkDB 公司在 2017 年倒闭(鉴于创始人对女性在科技界的看法,这并不奇怪)后,数据库源码就被转移到了 Linux 基金会。尽管基金会接手了项目,RethinkDB 仍处于活着的状态:该项目在 2023 年发布了一个新版本,但它们只是热修复,来解决一些已知问题。有兴趣的话,你可以去 Apache 基金会档案室看看那些被遗弃的数据库项目。
只在云端提供数据库服务的 DBaaS,在稳定性上只会更糟糕。因为如果公司失败,或是开始面临财务压力,他们就会关闭托管你数据库的服务器。Xeround 在 2013 年关闭云服务时,给了他们的客户两周时间迁移数据。为了降低成本,InfluxDB 在 2023 年 7 月删除整个 region 前给了客户六个月的时间迁移,但大家还是大吃一惊。
MariaDB 比一般的数据库创业公司处于更好的位置,因为 Monty 和其他人成立了一个管理开源项目的非营利基金。但当你是一个以盈利为目的的开源数据库公司,而帮助你管理该 DBMS 运作的非营利组织公开表示你管理混乱的话,那就是一个坏兆头!与此同时,MySQL 在持续改善,Oracle 依旧是那个从工程角度看不错的企业级数据库选择。MariaDB 公司的混乱将进一步促进人们转向使用 PostgreSQL。
MariaDB 肯定不能失败,据我所知,Monty 没有更多的孩子可以用来给数据库命名了(例如:MaxDB、MySQL、MariaDB)。
小趣闻:MariaDB 取名自 Monty 的小女儿 Maria,MaxDB 取名自儿子 Max,MySQL 来自大女儿 My。
美国航空因政府数据库崩溃而停飞
在 2023 年 1 月 11 日,由于飞行通知 NOTAM 系统故障,联邦航空管理局 FAA 停飞了美国所有的航班。NOTAM 系统向飞行员提供以纯文本编码的消息,告诉他们可能在飞行路径上会遇到的意外和潜在危险。当 NOTAM 系统在 1 月 11 日早晨崩溃时,直接导致美国大约 11,000 架航班无法起飞。所幸的是,其他国家运行着独立的、不受美国 NOTAM 故障影响的 NOTAM 系统能正常起飞。
根据 FAA 官方说法,这次故障是由于一个数据库文件损坏导致的。一名来自第三方承包商的工程师尝试用备份文件替换它,但结果是备份文件也有问题。2008 年也发生了类似的事件。
关于 FAA 在 NOTAM 所用的 DBMS 并没有公开信息。有一些报道称,NOTAM 仍然在运行于 1988 年的两台 Philips DS714/81 大型机上。但这些 Philips DS714 机器没有我们今天所知的操作系统;它们是 1960 大型机年代的遗物。也就是说,在 1980 年代 FAA 无法为应用使用现有的数据库系统,即便是那些当时已经存在的数据库,像是 Oracle、Ingres 和 Informix 都支持当时的各种 Unix。我觉得比较合理的可能是,NOTAM 可能用 Flat File(比如:CSV)来自行管理数据。1980 年代由非数据库专家编写的应用程序代码负责从文件中读取/写入记录,复制到备用服务器,并在出现故障时维护数据的完整性。
Andy 说:历史悠久的核心数据系统,是每个数据库从业者最大的噩梦
在无法替代的传统硬件上运行关键任务系统,使用的还是由早就退休的内部开发人员编写的自定义数据库访问库,这是每个数据库从业者最大的噩梦。我很惊讶它竟然没崩溃得更早(除非 2008 年的故障是同一系统),我觉得我们应该给这个运行了 35 年的系统一些掌声。
有消息称,NOTAM 系统每秒只处理 20 条消息。按照现代数据标准,这个数据量真的很小,但别忘记,FAA 是在 1980 年代配置的这个系统。数据库传奇人物,1998 年图灵奖得主 Jim Gray 在 1985 年写到,“普通” 的数据库管理系统可以执行大约每秒 50 次事务(txn/sec),而非常高端的系统可以达到每秒 200 次。作为参考,五年前,有人使用 1980 年代的基准测试(基于 TPC-A 的 TPC-B)在树莓派 3 上运行 PostgreSQL,大约达到了每秒 200 次事务。如果我们不考虑那些使用跨数据中心的强一致性复制(这会受到光速的限制)的系统,现代单节点在线事务处理(OLTP)DBMS 可以在某些工作负载下实现每秒数百万次事务的吞吐量。NOTAM 在 1980 年代的峰值每秒 20 条消息的吞吐量并没有推动当时的技术极限,而且显然今天也没有。
因为 NOTAM 没有将数据库与应用程序逻辑分离,所以独立升级这些组件是不可能的。考虑到在 1980 年代中期,关系模型的优点已经众所周知,NOTAM 这种设计是该批判的。当然,并不是说 SQL 就能防止这次确切的失败(这是一个人为错误),但独立性会让各个组件不那么笨重,更易于管理。
尽管如此,当时美国政府其实已经在用商用关系型 DBMS。例如,Stonebraker 的 RTI(Ingres 厂商)在 1988 年的 IPO 申报文件中提到,他们现有的客户包括国防部和内政部、军事分支和研究实验室。我相信当时美国政府的其他部门也在使用 IBM DB2 和 Oracle。因此,除非 NOTAM 有什么我不知道的特别之处,不然 FAA 本可以使用真正的数据库管理系统。
停飞事件发生的时候,我正在阿姆斯特丹的 CIDR 2023 会议的返程中。幸运的是,停飞没有影响入境的国际航班,我的飞机可以顺利地降落。但我还是被困在纽瓦克机场,因为美国所有国内航班都停飞了。熟悉纽瓦克机场的人都知道,在这里待着并不是什么好事。
延伸阅读:你可以阅读我之前的文章,了解下为什么如果 NOTAM 数据库运行在 Amazon RDS 上,不太可能发生数据库崩溃。
数据库的融资情况
除了上面提到的向量数据库是风投的 “新宠” 之外,其他类型的数据库在 2023 年也是有融资的。但总体而言,今年的数据库融资活动比往年要冷清得多。
自动调优初创公司 DBTune 在欧洲完成了 260 万美元的种子轮融资。PostgresML 获得了 450 万美元的种子轮融资,来打造一个通过自定义扩展来支持从 SQL 调用 ML 框架的 DBaaS。TileDB 在秋季宣布完成了 3,400 万美元的 B 轮融资,以此继续完善他们的阵列数据库管理系统。尽管有着 13 年的历史,SQReam 还是获得了 4,500 万美元的 C 轮融资,来继续开发他们的 GPU 加速数据库管理系统。Neon 在 2023 年 8 月完成了 4,600 万美元的 B 轮融资,以扩展无服务器 PostgreSQL 平台。当然,2023 年的融资赢家再次是 Databricks,他们在 2023 年 9 月完成了 5 亿美元的 I 轮融资。虽然这是一笔巨款,但并不如他们在 2021 年 H 轮的 16 亿美元来得多。
Peter Boncz 和 Tianzhou Chen 提醒我了,还有 MotherDuck(DuckDB 的商业版本)在 2023 年 9 月完成的 5,250 万美元的 B 轮融资。另一个数据库产品 DBeaver,完成了 500 万美元的种子轮融资,来继续研发受欢迎的 multi-DBMS 。
此外,2023 年数据库领域也发生了一些收购。最大的一笔交易在年初发生,MarkLogic 被 Progress Software 以 3.55 亿美元现金收购。MarkLogic 是最古老的 XML 数据库管理系统之一(约 2001 年),而 Progress 拥有 OpenEdge,一种更古老的数据库管理系统(约 1984 年)。IBM 收购了 Meta 的衍生公司 Ahana,该公司试图将 PrestoDB(它不同于已经更名为 Trino 的 PrestoSQL)商业化。多云数据库服务提供商 Aiven 收购了 AI 驱动的查询重写器初创公司 EverSQL。EnterpriseDB 用 Bain Capital(私募投资公司)的资金收购了基于 DataFusion 兼容 PostgreSQL 的 OLAP 引擎的 Seafowl 团队。Snowflake 收购了两家初创公司:(1)由前斯坦福教授 Peter Bailis 打造的 Sisu Data,以及(2)由伯克利教授 Aditya Parameswaran 基于 Modin 研发的 Ponder。
Andy 说:无论初创公司,还是高估值的公司日子都不好过
我的风投朋友们说,他们在 2023 年看到了更多新公司的推介,但比往年签发的支票更少。这个趋势贯穿所有初创领域,数据库市场也不例外。大部分的风投注意力都在那些和人工智能 + 大型语言模型(LLM)有一点点关系的项目,这也合理,毕竟这是计算领域的新篇章。
尽管美国 2023 年的宏观经济指标有些积极的迹象,但科技产业依旧紧张,每家企业都在削减成本。像 OtterTune(作者所在的公司)客户希望我们的数据库优化服务能在 2023 年帮助他们降低数据库基础设施成本。这与公司早些年人们主要来找 OtterTune 提高数据库管理系统的性能和稳定性不同。我们计划在 2024 年宣布新功能,以帮助降低数据库成本。回到大学,这个学期有比平常更多的学生请我帮他们找数据库开发的工作。这让我很吃惊,因为 CMU 的计算机科学学生一直不愁找工作,靠自己就拿到不错的实习和全职 offer,除了有次我最优秀的本科生重写了我们的查询优化器,但因为忘了问我,结果找不到暑期实习,最后在匹兹堡机场附近的迪克体育用品店做网页开发 —— 他现在在 Vertica 工作得很开心。
如果美国的科技市场继续低迷不振,接下来的几年众多数据库初创公司都难有大发展。小型的数据库初创公司要么会被大型科技公司或私募股权收购,要么就直接倒闭。但是,那些融到大笔钱且估值很高的公司也不好过。正如我之前说的那样,有些公司可能无法 IPO,而且没有哪家大型科技公司会需要这些 DBMS,因为如今大家都有自己的数据库系统。因此,这些大数据库管理系统公司将面临三个选择:接受降低估值的融资以保持运营;通过私募股权获得支持,保持运营(比如:Cloudera);被一家 IT 服务公司收购(比如:Rocket,Actian),这些公司将 DBMS 置于维护模式,但继续从那些被困的客户那里收取许可费,因为这些客户有他们无法轻易迁移的遗留应用程序。不过,这三条路对于数据库公司来说都不理想,应该会吓跑潜在的新客户。
最后,我要重述一句:不要问 Databricks 是不是会 IPO,而是它何时会 IPO。
史上最贵的密码重置
2023 年,数据库传奇大佬 Larry Ellison 春风得意。对于他原本杰出的职业生涯来说,2023 年也是一个标志性的一年。2023 年 6 月,他重返世界第四富有的位置。Oracle 公司的股价($ORCL)在 2023 年上涨了 22%,略低于标准普尔 500 指数 24% 的回报率。此外,在 2023 年 9 月,Larry 第一次去了 Redmond,并与微软首席执行官 Satya Nadella 一起登台宣布,Oracle 可作为 Azure 云平台上托管服务使用。随后同年 11 月,股东们压倒性地投票支持 79 岁的 Larry 继续担任 Oracle 董事会主席。
但 2023 年真正的大新闻是,Elon Musk 在 Larry 对 Musk 收购社交媒体公司投资了 10 亿美元后,亲自帮 Larry 重置了 Twitter 密码。正是这笔价值 10 亿美元的密码重置,我们在 2023 年 10 月有幸看到了 Larry 的第二条推文,也是他十多年来的首条新推文。Larry 预告了他即将前往牛津大学的行程,后来他在那里宣布在牛津大学成立埃里森技术研究院(EIT)。
Andy 说:意料之外的大人物生活
其实 Larry 发了什么根本不重要,重要的是 Larry 回归推特发推文。我偷偷打听过,Larry 偶尔会看看推特,主要关注创业点子提案、祝福以及不经意冒出的奇思妙想。
Larry 的推文之所以出人意料,是因为人们一般会认为他总是忙于更宏伟的活动。毕竟,他拥有一架 MiG-29 战斗机和一个夏威夷岛屿。他有很多更伟大的事情可以做。所以,当他抽出时间在一个日益衰落的社交媒体上写推文,告诉我们他在做什么。这对我们所有人来说,都是一个重大的生活事件。为此,Larry 不得不请他那个世界上最富有的朋友来重置他的密码。虽然花费 10 亿美元,但当你拥有 1,030 亿美元时,这都不是什么事了。
2022 年数据库回顾:江山代有新人出,区块链数据库还是那个傻主意,英文原文
放缓的大规模数据库融资
正如我去年说的那样,2021 年是数据库融资的大年。随着投资者继续寻找下一个 Snowflake,大量资金涌向了新的 DBMS 初创公司。2022 年初看起来像是要再过一次 2021 年,有非常多的大额融资消息。
融资狂欢在 2022 年的 2 月开始,Timescale 完成了 1.1 亿美元的 C 轮融资,Voltron Data 完成了 1.1 亿美元的种子轮 + A 轮融资,Dbt Labs 完成了 2.22 亿美元的 D 轮融资。Starburst 在 3 月宣布了他们 2.5 亿美元的 D 轮融资来继续提升他们的 Trino 产品。Imply 在 5 月拿出 1 亿美元的 D 轮融资用于开发他们的 Druid 商业版本。DataStax 在 6 月的 IPO 途中获得了 1.15 亿美元的资金。最后,SingleStore 在 7 月完成了 1.16 亿美元的 F 轮融资,然后在 10 月又融了 3,000 万美元。
2022 年上半年还有几家较小的公司完成了让人印象深刻的 A 轮融资,包括 Neon 的 3,000 万美元 A 轮用来研发无服务器 PostgreSQL 产品,ReadySet 2,900 万美元 A 轮融资来研发查询缓存层,Convex 的 2,600 万美元 A 轮来继续开发他们基于 PostgreSQL 的应用程序框架,以及 QuestDB 的 1,500 万美元 A 轮来开发时序数据库。尽管我们 OtterTune 没有新的 DBMS 或相关基础设施,但我们也在 4 月完成了 1,200 万美元的 A 轮融资。
但是,到了 2022 年下半年,大规模的融资轮停止了。尽管早期初创公司还是有较小额的融资进来,但更后面的公司再也没有九位数的美元融资了。
流处理引擎 RisingWave 在 10 月筹集了 3,600 万美元的 A 轮,Snowflake 查询加速器 Keebo 融到 1,050 万美元的 A 轮资金。在 11 月,我们看到了 MotherDuck 的 4,500 万美元种子轮 + A 轮融资的新闻来开发商业化 DuckDB 的云版本,以及 EdgeDB 在 11 月的 1,500 万美元 A 轮融资。最后,是 SurrealDB 完成了 600 万美元的种子轮融资。我可能漏掉了一些其他公司,这不是一个详尽的列表。
在数据库领域唯一其他值得注意的金融事件是,MariaDB 在 12 月的灾难性地通过 SPAC IPO,股价在首个交易日就下跌了 40%。
Andy 说:不只是 OLAP 领域,OLTP 领域前景也一样严峻
与 2021 年相比,在 2022 年大额融资轮减少的原因有两个。最明显的是整个科技行业在降温,部分原因是人们对通货膨胀、利率和加密经济崩溃的担忧。另一个原因是,有能力大额融资的公司在资金干涸之前就完成了融资。例如,Starburst 在 2021 年完成了 1 亿美元的 C 轮融资后,在 2022 年进行了它的 D 轮融资。在过去两年完成巨额融资的数据库公司,很快就需要再次融资来保持增长势头。
坏消息是,除非科技行业有所改善,并且大型机构投资者开始再次将资金投入市场,否则这些公司们将面临困境。市场无法维持这么多独立软件供应商(ISVs)为数据库服务。这些拥有十亿美元估值的公司唯一继续前进的法子是,进行首次公开募股或破产。这些公司对于大多数公司来说太贵了,无法被收购(除非风投公司愿意大打折扣)。
此外,进行大型并购的大型科技公司(比如:亚马逊、谷歌、微软)都有了自己的云数据库产品。因此,不清楚谁会收购这些数据库初创公司。亚马逊没有理由在他们 Redshift 每年赚取数十亿美元时,去以 2021 年的 20 亿美元估值购买 ClickHouse。这个问题不仅限于 OLAP 数据库公司;OLTP 数据库公司很快也将面临同样的问题。
我并不是唯一一个对数据库初创公司的前景做出如此严峻预测的人。Gartner 分析师预测,到 2025 年,50% 的独立 DBMS 供应商将退出市场。显然我有自己的看法,我认为未来生存下来的公司是那些致力改善或者是强化 DBMS 的公司,而不是替换它们的公司(比如:dbt、ReadySet、Keebo 和 OtterTune)。
我无法判断 MariaDB 借壳 SPAC “快速上市” 是否是个好主意。这种金融操作不在我的专业领域(数据库)内。但既然这和前美国总统用他的社交媒体公司做的事情一样,我就姑且认为它不是什么好主意。
区块链数据库还是那个蠢点子
关于 Web3 根本性转变了构建新应用程序方式这点,有很多夸张的说法。我有一个学生甚至因为我教授的是关系数据库而不是 Web3,愤然从我的课堂离席。Web3 运动的核心是在区块链数据库中存储状态。
区块链本质上是去中心化的分散的日志结构数据库(即,账本),它们通过使用某种 Merkle 树的变体和 BFT 共识协议来维护增量校验和,从而确定下一个要入库的更新。这些增量校验和是区块链确保数据库日志记录不变性的方式:客户端使用这些校验和来验证之前的数据库更新没有被更改。
区块链是之前想法的巧妙结合。但是,厂商们认为去中心化账本是每个人构建 OLTP 应用程序必须的,这点是一种误导。从数据库的角度,除了加密货币之外,区块链数据库和现有的 DBMS 没有任何差别。此外,任何区块链在数据库安全性和可审计性比现有 DBMS 表现更好的说法,都是胡说。
如果说加密货币是区块链数据库的最佳实践,那么 2022 年加密市场的崩溃显然没有帮到它们,甚至是进一步阻碍了区块链数据库的发展。当然我会忽略 FTX 的崩盘(他们申请了破产保护),毕竟它就是彻头彻尾的诈骗,和数据库一点关系都没。不过,我要指出,FTX 和所有其他加密货币交易所一样,并没有在区块链数据库上运行业务,而是使用了 PostgreSQL。
此外,其他与加密货币无关的区块链数据库用例,如交易和游戏平台,都因为不切实际或诈骗没有落地。
Andy 说:有让人信服的用例才是合格的新技术
评估某项技术的原则之一是,一旦厂商开始制作它的媒体广告,它就不再是 “新” 技术了。简单来说,像是 IBM 之类的厂商在打广告的时还没有出来让人信服的用例,那么这个产品永远也不会有用例。
举个例子,IBM 在 2002 年在一则商业广告中吹捧 Linux 是一个热门的新事物,但那时已经有包括谷歌在内的成千上万的公司将 Linux 作为主要服务器操作系统使用了。所以,当 IBM 在 2018 年发布他们的区块链广告时,我就知道这项技术除了在加密货币领域有用,在其他领域毫无用处。因为其他领域没有一个问题是去中心化的区块链能解决,而中心化的 DBMS 不能解决的。
因此,2022 年 IBM 宣布将关闭与航运巨头 Maersk 合作的供应链 IT 基础设施改造项目,也就不奇怪了,毕竟这正是 IBM 在广告中炒作的场景。
相比任意一个可信权威管理、只允许受信任的客户端直连、用心编写的事务数据库,区块链数据库的效率低得可怕。除了加密货币(见上文)或者其他什么欺诈场景,现实数据世界的运行方式都是和其他数据库目前处理的那样。
信任是一个正常运转的社会的基石。例如,我授权托管 OtterTune 网站的公司向我的信用卡收费,他们又信任一个云提供商来托管他们的软件。没人会需要使用区块链数据库来进行这些 “信任” 交易。
从工作量证明(PoW:proof-of-work)转换到不那么费事的权益证明(PoS:proof-of-stake),共识机制确实提升了区块链数据库的性能。但这只影响数据库的吞吐量;区块链交易的延迟仍然以数十秒计算。如果解决这些长延迟的方法是使用参与者较少的 PoS 区块链,那么应用程序使用 PostgreSQL 来认证这些参与者会更好。
你可以读一读 Tim Bray(XML 之父)同 AWS 高层内部讨论是否有区块链可行用例的精彩文章。值得留意的是,Tim 说 AWS 在 2016 年就得出过区块链数据库是数据问题的解决方案的结论,这比 IBM 推出区块链数据库广告早了两年!虽然 AWS 最终在 2018 年发布了 QLDB 服务,但它不同于区块链;它是一个中心化的可验证账本,不使用 BFT 共识。与亚马逊极为成功的 Aurora 产品相比,QLDB 客户的采用率一直不太理想。
趣闻:在 FTX 崩盘(申请破产保护)前的三周,有人和我说 OtterTune 的全职工程师人数和 FTX 在巴哈马的团队一样。这个人还说,既然工程师人数一样,OtterTune 应该像 FTX 那样更有前景,而且现在应该有 10 亿美元的年度经常性收入(ARR)。真是有意思呀。
新的数据系统
今年有不少新的 DBMS 软件的重大新闻:
Google AlloyDB:2022 年最让人震惊的消息是 5 月份谷歌云宣布了它们的新数据库服务。AlloyDB 不是基于 Spanner 构建的,而是一个修改版的 PostgreSQL,它分离了计算层和存储层,并且支持在存储中直接处理 WAL 记录。
Snowflake Unistore:6 月份,Snowflake 宣布了他们的新 Unistore 引擎,用 “混合表” 来支持 DML 操作的低延迟交易。当查询要更新表时,变更会传到 Snowflake 的列式存储中。SingleStore 数据库的某个人有些激动,说 SingleStore 在这个领域有一些专利,虽然这个说法没啥实质性证据支撑。补充信息:SingleStore 和 Snowflake Unistore 有部分技术交集,你可以理解为他们存在一定的竞争关系。
MySQL Heatwave:当 Oracle 发现 Amazon 从 MySQL 赚的钱比他们多后,终于在 2020 年决定为 MySQL 构建自己的云服务。但他们并没有仅仅做个 RDS(关系数据库服务)克隆版,而是用一个叫做 Heatwave 的内存向量化 OLAP 引擎扩展了 MySQL。2021 年 Oracle 还宣布他们的 MySQL 服务还支持自动化数据库优化(但与 OtterTune 提供的优化服务不同)。到了 2022 年,Oracle 终于发现他们不是领先的云供应商,并向 AWS “低头” 在 AWS 上托管了 MySQL Heatwave。
Velox:Meta 在 2020 年开始构建 Velox,作为 PrestoDB 的新执行引擎。两年后,他们宣布了这个项目并发表了一篇关于它的 VLDB 论文。Velox 并不是一个完整的 DBMS:它不带 SQL 解析器、目录、优化器或网络支持。相反,它是一个带有内存池和存储连接器的 C++ 可扩展执行引擎。人们可以基于 Velox 构建一个成熟的 DBMS。
InfluxDB IOx:就像 Meta 的 Velox 一样,Influx 团队在过去两年一直在努力开发新 IOx 引擎。在 10 月,他们宣布新引擎正式上线(GA)。InfluxDB 从零开始基于 DataFusion 和 Apache Arrow 构建了 IOx。值得庆祝下的是,我在 2017 年和 Influx 的 CTO 说使用 MMAP 是个坏主意后,他们在新系统中抛弃了 MMAP。
Andy 说:欣然看到数据库领域的勃勃生机
很高兴见证了 2022 年数据库领域发生的这些事。我对 AlloyDB 的看法是,它是一个简洁的系统,当中投入了让人感叹的工程量,但我还是不知道它有什么创新点。AlloyDB 的架构类似于 Amazon 的 Aurora 和 Neon,在 DBMS 存储中有个额外的计算层,可以独立于计算节点处理 WAL 记录。尽管谷歌云已经拥有坚挺的数据库产品组合(比如:Spanner、BigQuery),但它们还是觉得有必要构建 AlloyDB 来尝试赶上亚马逊和微软。
需要关注的长期趋势是诸如 Velox、DataFusion 和 Polars 之类的框架的普及。结合像 Substrait 之类的项目,这些查询执行组件的商品化意味着未来的五年内,所有的 OLAP DBMS 将在性能上大致持平。
与其完全从头开始构建一个新的 DBMS,或者是 hard fork 一个现有系统(像 Firebolt fork ClickHouse),比如使用一个像 Velox 这样的可扩展框架。也就是说,每个 DBMS 都将具备同 Snowflake 十年前独有的相同向量化执行能力。尤其是在云上,存储层对每个人来说都是相同的(比如:亚马逊控制的 EBS/S3),那么区分 DBMS 产品的关键因素将会是那些难以量化的事物,如 UI/UX 设计和查询优化。
数据库先驱的逝世
在 2022 年 7 月有一个让人难过的消息,Martin Kersten 逝世了。Martin 是 CWI 的研究员,他是多个颇具影响力的数据库项目的引领者,包括 1990 年代最早的分布式内存 DBMS(PRISMA/DB)和 2000 年代最早的列式 OLAP DBMS(MonetDB)。因为他在数据库方面的贡献,Martin 在 2020 年因被荷兰政府授予皇家骑士称号。
MonetDB 的代码库还是其他几个 OLAP 系统项目的跳板。在 2000 年代末,Peter Boncz 和 Marcin Żukowski fork MonetDB 它开发 MonetDB/X100,后来商业化为 Vectorwise(现在叫 Actian Vector)。Marcin 后来离开,联合他人共同创立的 Snowflake,采用了原来他在 MonetDB 代码上开发的许多技术点。最近,Hannes Mühleisen 搞了个 MonetDB 的嵌入式版本 MonetDBLite,后来他又重写了项目,变成了现在的 DuckDB。
Martin 对现代数据库系统的贡献如此重大,以至于你如果使用任何现代分析型 DBMS(像是 Snowflake、Redshift、BigQuery、ClickHouse),你就是在享受 Martin 和他的学生在过去 30 年开发的众多进步成果。
Andy 说:这是一个让人难过的消息
我知道,相比 Mike Stonebraker(研究数据库的计算机科学家,2014 年图灵奖获得者)这样的人,数据库研究圈外人可能知晓 Martin 没那么多。我总把 Martin 看作是 Stonebraker 的欧洲版:他们都是多产的数据库研究者,高个子、瘦弱、戴眼镜,年龄相仿。但 Martin 并不是像 Nintendo Smitch 山寨 Nintendo Switch 那样的山寨货。
除了研究,在业余时间 Martin 也乐于同他人讨论数据库架构。我最后一次见 Martin 是在新冠爆发之前的 2019 年。我们就他为什么认为在 MonetDB 中使用 MMAP 是正确的选择争论了一个小时;他声称因为 MonetDB 专注只读的 OLAP 工作负载,所以 MMAP 就够好了。其实有件事很对不住 Martin,就是那些他应对过的在 YouTube 观看我的数据库课程后,给他发邮件询问为什么 MonetDB 做出了我声称的较差设计的学生。
我建议你看下 Martin 在 2021 年 CMU-DB 研讨会的压轴演讲。我和 Martin 承诺在他的演讲中,我不会用 MonetDB 采纳 MMAP 这点让他分心。为了表示诚意,在这个视频的前面 60 秒,我找了个荷兰人录制一个仿皇家的 Martin 短片介绍。
数据库的巨额财富和民主
2022 年 5 月,《华盛顿邮报》报道说,Oracle 创始人和帆船爱好者 Larry Ellison 参加了 2020 年 11 月刚结束的选举的电话会议,与会的有美国总统和其他保守派领袖。
电话会议集中讨论了总统的盟友和活动分子可能采取的、来推翻总统选举的结果的不同策略。正如《邮报》文中指出的那样,目前尚不清楚为什么政府要让 Larry 参与通话。一种猜测是,鉴于 Larry 显而易见的强大技术背景,他可能很适合评估外国势力利用某种方式来使用卫星技术来远程操控美国选举的说法是否可行。
Andy 说:Larry 干得漂亮
相信 Larry 和我都厌倦了人们对他支持美国右翼的离谱言论,甚至有人说这个电话是 Larry 做过的最糟糕的事。这不是真的,要知道这样的新闻和社交媒体言论会让 Larry 感到难过。
我向你保证,Larry 只是试图用他作为世界第七富有的人的巨额财富来帮助他的国家。他参与这次通话是值得钦佩的,应该受到赞扬。自由和公正的选举不是一件小事,不像划船比赛,有时候只要你能赢,搞点小动作也没关系。Larry 用他的钱做了一些被人忽视的伟大事情,比如:为了活得更久,在抗衰老研究上花费了 3.7 亿美元;投资了 10 亿美元帮助 Elon Musk 运营 (?,那时候推特尚未被收购) 推特。所以,我支持 Larry 这个行为。
2021 年数据库回顾:性能之争烽烟起,不如低调搞大钱,英文原文
对数据库行业来说,2021 年是疯狂的一年,数据库的新人 “超越” 了老牌厂商,数据库厂商们为基准测试的数字争论不休,还有各种引人注目的融资轮次。好消息是不少,但是收购、破产或重组之类的不好消息,也让一些数据库消失在数据库市场。
PostgreSQL 的主导地位
开发者的认知已经发生转变:PostgreSQL 成为香饽饽,已是新应用程序的首选。它稳定可靠,功能丰富,且在不断增加新功能。2010 年,PostgreSQL 开发团队采取了更积极的发布计划,每年发布一个新的主要版本,这里要感谢下 Tomas Vondra。顺便提一嘴,PostgreSQL 是开源的。
如今,对很多系统来说,PostgreSQL 的兼容性是一个显著亮点。这种兼容性是通过支持 PostgreSQL 的 SQL 方言(如 DuckDB)、线协议(如 QuestDB、HyPer)或整个前端(如 Amazon Aurora、YugaByte、Yellowbrick)来实现的。大公司们也跟进了这个趋势。谷歌在 10 月宣布在 Cloud Spanner 中增加了 PostgreSQL 兼容性。还是在 10 月,亚马逊宣布了 Babelfish 功能,将 SQL Server 查询转换成 Aurora PostgreSQL 查询。
数据库受欢迎程度的一个衡量标准是 DB-Engine 排名。这个排名不是很客观,得分带有一点程度的主观性,但就排名前十的系统结果还是合理的。截至 2021 年 12 月,DB-Engine 排名显示,虽然 PostgreSQL 仍然是第四大流行数据库(仅次于 Oracle、MySQL 和 MSSQL),但它在过去的一年里缩小了与 MSSQL 的差距。另一个值得考虑的趋势是 PostgreSQL 在线上社区的提及频率。它给我们提供了人们在数据库中讨论什么的信息。我下载了 Reddit 上 2021 年在数据库相关的所有评论,并计算了数据库名称的出现频率,自然 PostgreSQL 在其中。我又交叉参考数据库的列表,合并了缩写(例如,Postgres → PostgreSQL,Mongo → MongoDB,ES → Elasticsearch),最后整理出了前 10 个提及最多的 DBMS:
dbms | cnt
---------------+-----
PostgreSQL | 656
MySQL | 317
MongoDB | 266
Oracle | 222
SQLite | 213
Redis | 88
Elasticsearch | 70
Snowflake | 52
DGraph | 46
Neo4j | 42
自然,这个排名还是不科学,因为我没有对评论进行情感分析。但它清楚地显示了,在过去的一年里,人们提到 Postgres 的次数远超过其他数据系统。经常有开发者发帖询问新应用该用什么 DBMS,线上社区的回应几乎都是 Postgres。
Andy 说:PostgreSQL 只会在未来几年变得更好
首先,关系数据库系统成为新应用的首选肯定是一件好事。这表明 Ted Codd 在 1970 年代提出的关系模型的持久影响力。其次,PostgreSQL 是一个很棒的数据库系统。同所有 DBMS 一样,它有已知的问题和不足之处。但是有着如此高的关注,PostgreSQL 只会在未来几年变得更好。
基准测试之争
不同的数据库厂商之间在基准测试结果争议,今年并不少见。数据库厂商们试图证明他们的系统比竞争对手的更快,这种做法可以追溯到 1980 年代末。这也是为什么 TPC(交易处理性能委员会)成立的原因,希望能提供一个中立平台来监管性能比较。但随着 TPC 在过去十年的影响力和普及度的减弱,数据库们再次处于数据库基准测试战争的漩涡中。让人印象深刻的有三场基准测试争论。
Databricks vs Snowflake
Databricks 宣布他们新的 Photon SQL 引擎在 100TB TPC-DS 测试中创造了新的世界纪录。Snowflake 回击说,他们的数据库速度是 Databricks 的两倍,并且 Databricks 运行 Snowflake 的方式不正确。Databricks 反驳道,他们的 SQL 引擎在执行和价格、性能方面都优于 Snowflake。
Rockset vs Apache Druid vs ClickHouse
ClickHouse 强势声明,与 Druid 和 Rockset 相比,CK 的成本效率方面更出色。但没那么简单:Imply 立即用 Druid 的新版本进行了测试,并声称 Druid 获得了性能胜利。Rockset 也加入了讨论,说它的性能在实时分析上比其他两个要好。
ClickHouse vs TimescaleDB
感受数据库市场的风向变化,采取老虎式行事风格的 Timescale 加入了性能战争。他们发布了自己的基准测试结果,并借此机会指出 ClickHouse 技术的弱点。在 Hacker News 上,第三方基准测试的相关讨论变得非常火爆。
Andy 说:性能之争不值当
在先前的数据库基准测试中,已经有太多血淋淋的故事(参考:https://www.percona.com/blog/is-voltdb-really-as-scalable-as-they-claim/、https://www.youtube.com/watch?v=-TIUGC4X2q8&t=418s),我也曾是其中一员。但在性能竞争的路上,我失去了太多:不只是朋友,还有女朋友。随着时间的流逝,现在我觉得性能之争不值得。
现如今客观地比较数据系统更加困难,因为云数据库管理系统有很多可移动的部件和可调选项,往往很难确定性能差异的真正原因。真实的应用程序也不仅仅是一遍又一遍地运行相同的查询。在提取、转换和清洗数据时的用户体验,和原始性能数字一样重要。正如我在这篇关于 Databricks 基准测试结果的文章中告诉记者的那样,只有老年人才关心官方的 TPC 数字。
大数据搞大钱
自 2020 年下半年以来,价值至少 1 亿美元的风险投资轮次数量一直在稳步增加。2020 年有 327 笔这样的大宗交易,几乎占总风险资本交易量的一半。截至 2021 年 1 月,价值 1 亿美元或以上的风险投资回合已经超过 100 轮。
2021 年,大量投资资金涌向数据库公司。在运营数据库方面,CockroachDB 以 1.6 亿美元的融资轮次领跑筹资排行榜,在 2021 年 12 月它再次融了 2.78 亿美元。Yugabyte 完成了 1.88 亿美元的 C 轮融资。PlanetScale 为他们的 Vitess 托管版融到了 2,000 万美元的 B 轮。相对较老的 NoSQL 簇拥者 DataStax 为他们的 Cassandra 实现了 3,760 万美元的风险融资。
尽管这些融资金额都很惊人,分析型数据库市场的竞争更为激烈。TileDB 在 2021 年 9 月筹集了一笔未披露金额的资金。Vectorized.io 为他们与 Kafka 兼容的流处理平台筹到 1,500 万美元。StarTree 不再低调,宣布了用来打造商业化 Apache Pinot 的 2,400 万美元融资。有着附加功能的物化视图的 DBMS Materialize 宣布他们在 C 轮获得了 6,000 万美元。Imply 为基于 Apache Druid 的数据库服务筹集了 7,000 万美元。SingleStore 在 2021 年 9 月筹集了 8,000 万美元,使他们朝着 IPO 迈近了一大步。
2021 年年初,Starburst Data 为其 Trino 系统(前身为 PrestoSQL)筹集了 1 亿美元。Firebolt 是另一家不再低调 DBMS 初创公司,他们发布了基于 ClickHouse 分支的云数仓的 1.27 亿美元融资新闻。一家新公司,ClickHouse, Inc.,融了可怕的 2.5 亿美元,来以 ClickHouse 为主建立新公司,以及从 Yandex 获得使用 ClickHouse 名称的权利。
不过 2023 年数据库领域融资的最大赢家显然是 Databricks,他们在 2021 年 8 月筹集了高达 16 亿美元的资金,遥遥领先其他数据库。
Andy 说:我们正处在数据库的黄金时代
我们正处在数据库的黄金时代,有很多优秀的数据库可以选择。投资者们正在寻觅下一个像 Snowflake 一样可以 IPO 的数据库初创公司。2021 年的融资金额比以往数据库初创公司都要大。例如,Snowflake 直到成立五年后的 D 轮融资才有超过 1 亿美元的单轮融资。Starburst 在成立不到三年的时间内就完成了 1 亿美元的融资。现在融资涉及许多因素,比如:Starburst 团队从 TeraData 独立出来之前已经在 Presto 工作多年,我觉得如今数据库的投入资金更多了。
消逝的数据库们
遗憾的是,2021 年我们也 “送别” 了一些数据库。
ServiceNow 收购了 Swarm64
该公司最初是开发在 PostgreSQL 上运行分析工作负载的 FPGA 加速器。后来,他们转向仅使用扩展作为 PostgreSQL 的软件加速器。但他们未能获得关注,尤其是与其他资金充裕的云数仓相比。在 ServiceNow 收购之后,目前仍然没有消息表明 Swarm64 产品是否会继续维护。
Splice Machine 破产了
Splice 推出了一种混合型(HTAP)DBMS,它结合了 HBase 和 Spark SQL,前者用来处理操作性工作负载,后来用来分析数据。后来,他们推动提供一个用于操作性 / 实时机器学习应用的平台。但是,由于专业的 OLTP 和 OLAP 系统在市场的主导地位,all-in-one 的混合系统在市场并没有取得什么进展。
私募公司收购了 Cloudera
在 2010 年到 2020 年这十年的后期,技术重心从 MapReduce 和 Hadoop 技术转移之后,Cloudera 同这些技术一样在云数仓市场上失去了竞争力。尽管项目依旧在开发且在发布新版本,Impala 和 Kudu 的初创团队的大部分人都已经离职。股价也跌破了 2018 年 IPO 的初始价。新投资者能否扭转公司局面,还有待观察。
Andy 说:2022 年可能会有更多的数据库公司倒闭
看到数据库项目或公司倒闭的新闻,总是让人唏嘘,但这也是数据库行业的残酷现实。开源可能有利于 DBMS 比开发它的厂商活得更久,但事实并非总是如此。由于数据库的复杂性,它需要全职人员持续地修复 bug 和新增功能。将一个只有躯壳(defunct)的 DBMS 的源码权和控制权转移到像 Apache 或是 CNCF 这样的开源软件基金会,并不代表这个项目就会神奇般地复苏。
例如,RethinkDB 在公司破产后捐给了 Linux 基金会,从 GitHub 上的迹象来看,这个项目已经处于停滞状态(很少有提交,PR 也没有合并)。无独有偶,另一个例子是 DeepDB:公司失败后,他们为代码创建了自己的非营利基金会,但从来没有人在上面工作。我预测,2022 年将有更多无法与主流云厂商、上面提到的那些资金充足的初创公司竞争的数据库公司倒闭。
坚持的回报
近年来,Oracle 的联合创始人 Larry Ellison 运气不是很好。早在 2015 年,他还是世界上第五富有的人。但世事难料,在 2018 年的亿万富翁排名中他跌到了第十位。
但这一切在 2021 年 12 月发生了转变,当 Larry 超过谷歌的联合创始人 Larry Page 和 Sergey Brin,再次登上世界第五富有的位置。在 2021 年 12 月的某天,在宣布公司季度盈利超过预期时,Oracle 股票达到过去 20 年单日第二高涨幅,Larry 也在一天之内赚了 160 亿美元。新闻媒体认为,这归功于投资者对 Oracle 成功转向云服务十分有信心。
Andy 说:为 Larry 高兴
Larry 和我是旧相识,他重返财富榜第五位无疑是一个振奋人心的新闻。当他运气不好,仅仅是世界上第十富有的人时,他可能有些忧郁。但是我很高兴看到他能够从低谷中走出来,回到他应有的排位。
以上为 Andy 教授三年来的数据库回顾。
参考资料
2021 年数据库回顾原文
2022 年数据库回顾原文
2023 年数据库回顾原文
DB-Engines 被英国数据库软件开发商 Redgate 收购
一封署名为 SolidIT 首席执行官 Paul Andlinger 博士的邮件显示,DB-Engines 已于 2024 年 5 月 21 日被 Redgate 收购,且所有与 SolidIT 的协议将由 Redgate 监管。邮件还提及 Redgate 暂时不会对 DB-Engines 网站进行重大改动,继续让其保持独立运营 —— 包括数据库排名报告、广告展示等业务依旧照常运作。此外,如果合作伙伴对 Redgate 这次收购有意见,他们可以在三个月内提出异议。如果选择 “分手”,Redgate 也会帮助对方进行平稳过渡。
Redgate 是提供数据库开发工具以及解决方案的英国软件公司。DB-Engines 是全球知名的数据库流行度排行榜网站,其根据流行度对数据库管理系统进行排名,排名每月更新一次。排名的数据依据 5 个不同的指标:
Google 以及 Bing 搜索引擎的关键字搜索数量
Google Trends 的搜索数量
Indeed 网站中的职位搜索量
LinkedIn 中提到关键字的个人资料数
Stackoverflow 上相关的问题和关注者数量
这份榜单分析旨在为数据库相关从业人员提供一个技术方向的参考,其中涉及到的排名情况并非基于产品的技术先进程度或市场占有率等因素。
《中国数据库2023年度行业分析报告》节选:数据库关键技术及发展趋势
墨天轮于2024年5月29日正式发布 《2023 年中国数据库年度行业分析报告》,总结梳理了中国数据库行业的技术演进及趋势。作为云上数据库和数据计算领域的领先者,拓数派受邀参与创作,联合编写了《AI 时代下新一代数据仓库的演进》《从数据库到数据计算系统》、《传统数仓的痛点》等多个章节,本文为精华内容节选。
随着科学技术的发展,特别是信息技术的发展,人类获取数据、存储数据、分析数据的能力有了划时代的进步。近年来,移动互联网、物联网、5G 等技术持续发展,全球数据圈(Global Datasphere)呈指数级递增, IDC 预测全球数据圈将于 2025 年增长值 175ZB,而中国的数据圈有望于 2025 年爆炸式增长为世界第一。众多围绕数据获取、数据存储、数据分析的应用也如同雨后春笋般地涌现出来。这些事实说明,数据很有可能成为人类科技和经济进步的下一个引爆点。 因此人们提出了 “数据要素” 的概念,把数据列为和 “人力”、“资源” 等并列的生产要素,由此可见人们已经对数据的定位产生了本质的变化。
2023 年国家正式成立了国家数据局,负责协调推进数据基础制度建设,统筹数据资源整合共享和开发利用,统筹推进数字中国、数字经济、数字社会规划和建设等,不仅体现了对数据资源的战略性管理和规范化利用的需求,也体现了国家层面对数字经济发展和数据治理的重视。
此外,云平台的快速发展也为数据系统带来了新的发展机遇。云平台代表了目前最大的计算能力、存储能力和水平扩展能力。云平台为数据系统提供了近乎无限的存储资源和算力资源, 使得类似 ChatGPT 这样的应用成为可能。因此越来越多的企业将应用向云上迁移,而越来越多的数据也流向云上。
1、AI 时代下新一代数据仓库
为了助力企业优化计算瓶颈,充分利用和发挥数据规模优势,构建核心技术壁垒,更好地赋能业务发展,新一代数据仓库需要能够整合企业所有多模态数据资源,提供多模态大模型下数据计算支撑,更贴近数据科学家的需求和使用。
1.1 数据仓库上云虚拟化的核心价值
新一代数据仓库需要能够采用领先的数仓虚拟化技术,将多个数仓统一整合到一个高可用的云虚拟数仓,打通多云的数据管道,数据计算资源按需扩缩容,提升数仓的敏捷性和弹性,助力企业降低数仓管理复杂度,具有可扩展性、灵活性和可靠性等优点。典型产品包括拓数派的云原生虚拟数仓 PieCloudDB Database 产品。
降低数仓硬件和管理成本
通过云原生存算分离架构,物理数仓被整合到云原生数据计算平台,支持根据数据授权动态创建虚拟数仓,打破数据孤岛,解决数据多副本问题,帮助企业降低数仓管理复杂度,以更低的成本实现存算资源在云上更灵活的配置。
提升数据计算资源利用效益
数据计算资源按需扩缩容,实现计算资源配置最优化,提升数仓的敏捷性和弹性,打开无限数据计算空间,支撑更大模型所需的数据和计算。更好地赋能业务发展并走向绿色。
新一代数据仓库天然支持云环境,无需进行额外的定制。企业可根据对资源的需求,灵活地以低成本和高效的方式,单独地进行存储或计算资源的弹性扩展,提高了资源的利用率,节省空间成本和能耗开销。并支持随着负载的变化实现高效的伸缩,轻松应对 PB 级海量数据,具有高容错性、易于管理和便于观察等特性。结合可靠的自动化⼿段,能够轻松地对系统做出频繁和可预测的重⼤变更。
云原生的 “即开即用” 特性为企业节省了大量运维开支。由于其计算节点部署于云端,摆脱了物理限制和潜在的延迟,可随时随地通过互联网轻松管理,无需任何硬件。数据随时随地可用,无需处理任何后端技术问题,为企业进行跨部门、跨区域的数据共享和协作开辟了捷径,保证了企业的全球化进程。
高在线、高安全、高可靠
数据仓库上云,用户最关注的一点就是数据安全问题。传统数据平台将文件和资源存储在同一主机中,以主备节点数据方式补偿节点宕机时间,严重影响数据时效性,增加了运维的成本和难度。云时代下的数据仓库通过数据透明加密(TDE)等技术保证所有数据在落盘前完成加密,服务器无感知技术 (Serverless) 利用云上无限计算资源和弹性保证了计算永远在线可用,S3 存储和跨云灾备能力保证了永不丢数,确保业务连续性。
1.2 数据仓库上云虚拟化的技术突破
为了实现数据仓库上云虚拟化,为企业提供全新基于云数仓数字化解决方案,助力企业建立以数据资产为核心的竞争壁垒,以云资源最优化配置实现无限数据计算可能,新一代数据仓库需要实现以下技术突破:
打造云原生存算分离架构,云上资源弹性分配
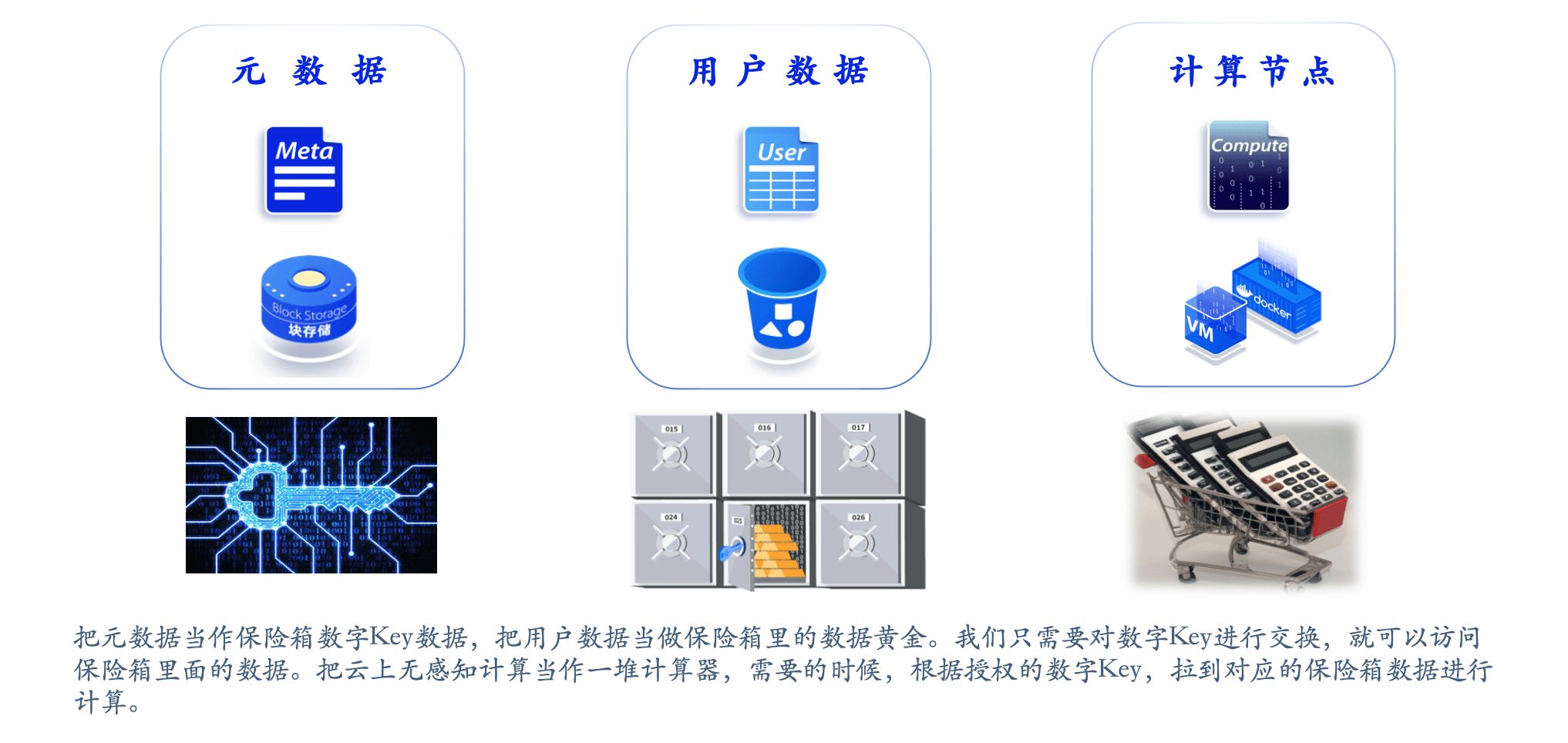
云时代下的数据仓库在设计与实现的过程中,需要充分考虑云平台的弹性和分布式特性,实现元数据、用户数据和计算资源的解耦分离。通过把元数据,用户数据和计算资源进⾏解耦,元数据可以被当作保险箱数字 Key 数据,用户数据可以被当作保险箱里的数据黄⾦。用户只需要对数字 Key 进⾏交换,就可以访问保险箱里面的数据。把云上⽆感知计算当作⼀堆计算器,需要的时候,根据授权的数字 Key,拉到对应的保险箱数据即可进⾏计算。
新一代的数据仓库需采用高效并行的方式进行数据加载和处理,处理速度随节点增加而提升,支持流数据快速加载。通过云原生虚拟数仓的存算分离架构,实现多集群并发执行任务,企业可灵活进行扩缩容,随着负载的变化实现高效的伸缩,轻松应对 PB 级海量数据,具有高容错性、易于管理和便于观察等特性。并结合可靠的自动化⼿段,轻松地对系统做出频繁和可预测的重⼤变更。
打造云原生交互存储与缓存架构设计
对象存储天然适应云原生环境,与云计算平台、容器编排技术等其他云原生技术无缝集成。此外,相对于传统的存储方式,对象存储通常具有更低的成本,成为数据仓库更有优势的一种存储选择。然而,由于对象存储通常是基于分布式系统和网络存储的,数据的传输和检索通常需要网络进行,因此相对于本地存储,会存在一定的延迟。这一缺陷也对云时代的数据仓库底层的存储和存储引擎也提出了新的挑战。
新一代数据仓库需要能够具备强大的存储适配接口能力,确保支持各种类型存储,保证和不同云环境的兼容性。此外,各个计算节点需针对元数据和用户数据均设计多层缓存结构,避免网络延迟和数据移动,提高计算效率,保证用户的实时性需求。针对底层对象存储,新一代数据仓库需设计高效的文件格式,在节省网络请求的同时提高计算效率。
云原生优化器的设计与打造
优化器作为数据库管理系统中的关键技术,对数据库性能和效率具有重要影响。针对云原生和分布式场景,优化器需要实现包括聚集下推、预计算、Block Skipping 等高级特性,全面满足各种复杂的分析查询需求。
向量化执行器的设计与打造
数据分析和应用的重要性日益增长,对于数据平台来说,极致的性能是关键需求之一。为实现更高效的数据并行计算,新一代数据仓库优秀的执行器需要能够充分利用硬件资源,如 CPU 的并行计算能力和 SIMD 指令集,充分利用了数据并行计算的优势,通过将多个数据元素打包成向量,并同时对其执行相同的操作,提高了计算效率和吞吐量。
大模型时代 AI 的支持与集成
新一代数据仓库是大模型时代的分析型数据库升维。对于大模型而言,模型所需的数据都经过了向量化过程,经过向量化的数据可以大幅提升模型的查找效率,降低训练成本。大模型时代下的数据仓库需要能够进一步实现海量向量数据存储与高效查询,助力多模态大模型 AI 应用,支持和配合大模型的 Embeddings,提供对向量的高效存储、索引和查询功能,具备高效存储和检索向量数据、相似性搜索、向量索引、向量聚类和分类、高性能并行计算、强大可扩展性和容错性等特性,帮助基础模型在场景 AI 的快速适配和二次开发。
对新硬件的支持和兼容
为了加速大数据处理和计算的性能,云时代下新一代数据仓库需要能够充分依赖新的硬件来进行异步计算,例如 GPU、FPGA 等。通过充分利用新一代硬件加速器,数据仓库可以实现更高的计算性能、更低的延迟和更好的扩展性。这将使得大数据处理和计算变得更加高效和可靠,推动云时代下数据分析和决策支持能力的进一步发展。
2、从数据库到数据计算系统
云计算技术、人工智能(AI)等多种技术的快速发展,数据系统也展现出云原生和智能化的趋势。数据分析技术也在从传统的 BI 向支撑深度学习、大语言模型等新型应用演进。数据系统的走向云原生化和 AI 化是数据系统发展的新趋势。
人们通常说的数据库是指关系型数据库管理系统(Relational Database Management System,RDBMS)。除了关系型数据库之外,还有针对各种非结构化数据的数据库,例如文档(Document)数据库、图(Graph)数据库、流式(Streaming)数据库等。
企业的数据平台一般由多种数据库联合组成,不同种类的数据库分别处理不同的数据。为了统一管理,人们提出了 “企业数据湖” 的概念,一般来说,多种数据源和针对不同数据源的处理工具组成了企业数据湖。在数据湖中,数据根据使用的频率分为 “冷 - 温 - 热” 数据,“热” 数据一般存储在数据仓库中,在处理 “温” 数据或者 “冷” 数据时,一般需要有一个 “由湖入仓” 的 “数据抽取 - 数据转换 - 数据加载”(ETL)操作,把数据加载到数据仓库中。
为了打破各种数据种类的边界,降低移动数据的 ETL 操作的代价,人们提出了 “湖仓一体” 架构,来解决例如事务支持、数据模型化、数据治理等问题。云原生技术和人工智能技术的发展,对数据库、数据湖的架构带来了潜移默化的影响。
一种新型的数据架构 “数据计算系统(data computing system)” 被业界提出。 数据和计算是数据计算系统的两个独立子系统,其中数据是核心,计算是产生数据价值的手段。
2.1 数据子系统
元数据(metadata)从用户数据中分离,各个计算任务提供数据的发现、授权、使用等服务。
用户数据打破数据类型和数据模式的边界,使用统一的格式存储。
2.2 计算子系统
针对不同种类的数据使用不同的计算引擎:
SQL 引擎用来执行关系型数据的计算任务;
向量引擎用来执行与向量数据相关的计算任务;
图数据引擎用来执行与图数据相关的计算任务;
Python/R 等引擎用来执行 BI/AI 相关的 Python/R 的计算任务。
除此之外,数据计算系统还有如下特点:
事务支持
对事务的 ACID 支持,可确保数据并发访问的一致性、正确性。
数据治理
保证数据完整性,并且具有健全的治理和审计机制。
BI 支持
支持直接在源数据上使用 BI 工具,这样可以加快分析效率,降低数据延时。
开放性
采用开放、标准化的存储格式提供丰富的 API 支持,因此,各种工具和引擎(包括机器学习和 Python/R 库)可以高效地对数据进行直接访问。
支持多种数据类型
具备多模态数据支持能力,支持包括结构化数据、半结构化数据、非结构化数据及二进制数据等数据类型。
支持各种工作负载
支持包括数据科学、机器学习、SQL 查询、分析等多种负载类型。
2025
2025 开源数据工程全景图
DolphinScheduler社区,作者 | Alireza Sadeghi,译自 Practical Data Engineering
2025 年开源数据工程领域呈现蓬勃创新与生态重构的双重态势,九大技术赛道在实时化、轻量化与云原生架构驱动下加速演进。一份来自外网的 2025 年开源数据工程全景图全面地展示了这一领域的发展态势与走向,现翻译此文供相关从业者参考。
值得注意的是,在数据工程领域全景图中,白鲸开源运营的开源项目 Apache DolphinScheduler 凭借其高扩展性、可视化 DAG 编排及对混合云环境的深度适配,持续领跑工作流编排领域,尤其在金融、制造业复杂任务调度场景中成为 Airflow 的有力竞争者。其社区活跃度与商业化成熟度显著提升,日均调度任务量突破千万级,助力企业实现 DataOps 全链路自动化。与此同时,白鲸开源运营的另一开源项目 Apache SeaTunnel 以批流一体引擎与超 200 种异构数据源的无缝集成能力,重塑数据集成范式,将传统 ETL 工具(如 Nifi)的同步效率提升 3 倍以上,成为多云环境下数据迁移的首选方案。两大项目的卓越表现不仅印证了开源生态的技术韧性,更凸显了数据工程向低门槛、高弹性架构转型的核心趋势 ------ 实时流处理(Flink 生态主导)、零磁盘存储架构(如 Apache Iceberg)及单节点计算引擎(DuckDB 崛起)正共同定义下一代数据基础设施的黄金标准。
引言
开源数据工程领域持续快速发展,2024 年在存储、处理、集成和分析等方向均取得重大进展。这是开源数据工程全景图的第二次年度发布,目标是识别并展示数据工程领域的关键活跃项目和核心工具,提供对这一动态生态系统的全面概览,并分析主要趋势与发展。尽管全景图每年发布一次,其配套的 GitHub 仓库会全年持续更新。若发现遗漏内容,欢迎随时贡献补充。
工具选择标准
每个类别的开源项目数量庞大,难以涵盖所有工具。GitHub 页面提供了更完整的工具列表,但年度全景图仅包含活跃项目,排除已停滞或成熟度不足的新项目。需要注意的是,部分入选工具可能尚未完全达到生产就绪状态,仍处于发展阶段。
下面是 2025 年开源数据工程全景图:

2025 开源数据工程全景图
开源生态现状(2025 年)
2024 年开源数据工程生态显著增长,新增超 50 个工具,同时移除约 10 个不活跃或归档项目;尽管并非所有新增工具诞生于 2024 年,但它们代表了生态系统的关键扩展。
许可协议挑战与行业贡献
1.许可协议争议:Redis、CockroachDB、ElasticSearch、Kibana 等老牌项目转向更封闭的许可协议(Elastic 随后宣布回归开源)。
2.行业巨头贡献:Snowflake 贡献 Polaris、Databricks 开源 Unity Catalog、OneHouse 捐赠 Apache XTable、Netflix 发布 Maestro,彰显企业对开源的支持。
基金会动态
1.Apache 基金会:持续孵化前沿项目,包括 Apache XTable(通用表格式)、Apache Amoro(湖仓管理)、Apache HoraeDB(时序数据库)、Apache Gravitino(数据目录)、Apache Gluten(中间件)和 Apache Polaris(数据目录)。
2.Linux 基金会:托管 Delta Lake、Amundsen、Kedro、Milvus、Marquez 等明星项目,2024 年新增 vLLM(加州大学伯克利分校捐赠)和 OpenSearch(从 AWS 移交)。
开源模式之争:Open Core vs Open Foundation
并非所有项目均为完全开源的中立工具。部分采用 Open Core 模式 (核心功能需付费),其可持续性面临挑战。相比之下,Open Foundation 模式(开源软件作为商业化产品基础)可能成为未来主流,确保开源工具的生产就绪性。
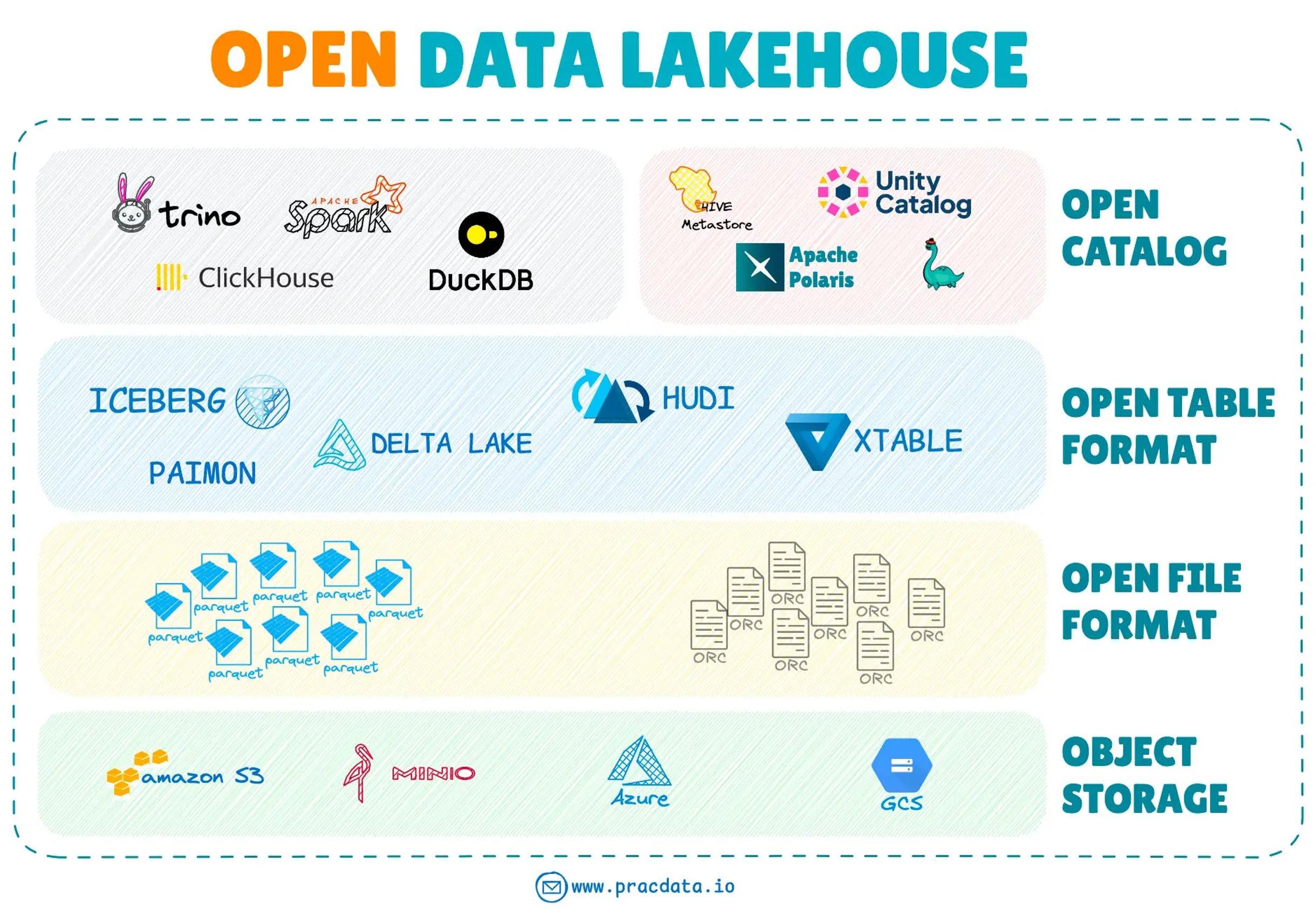
九大核心分类概览
数据工程全景图划分为 9 大类别:
1.存储系统:OLTP、OLAP 及专用存储引擎
2.数据湖平台:湖仓架构工具
3.数据处理与集成:批流处理框架与 Python 工具
4.工作流编排与 DataOps:流水线编排与数据运营管理
5.数据集成:数据摄取与 CDC 工具
6.数据基础设施:容器编排与监控组件
7.ML/AI 平台:机器学习与向量数据库
8.元数据管理:数据目录与治理
9.分析与可视化:BI 工具与可视化框架
以下为各领域关键进展分析:
1、存储系统
2024 年,存储系统在架构上取得了显著进展,特别是在 OLAP 数据库系统领域。
DuckDB 在 1.0 版本发布后,成为嵌入式 OLAP 类别的主要成功案例。新的嵌入式 OLAP 系统如 chDB(基于 ClickHouse)、GlareDB 和 SlateDB 的出现,反映了对轻量级分析处理能力的需求增长。
OLAP 扩展与 HTAS 架构 :
PostgreSQL 生态涌现 OLAP 扩展(如 MotherDuck 的 pg_duckdb、Crunchy Data 的 pg_parquet),将 OLTP 数据库升级为支持数据湖的 HTAS(混合事务分析存储)系统。
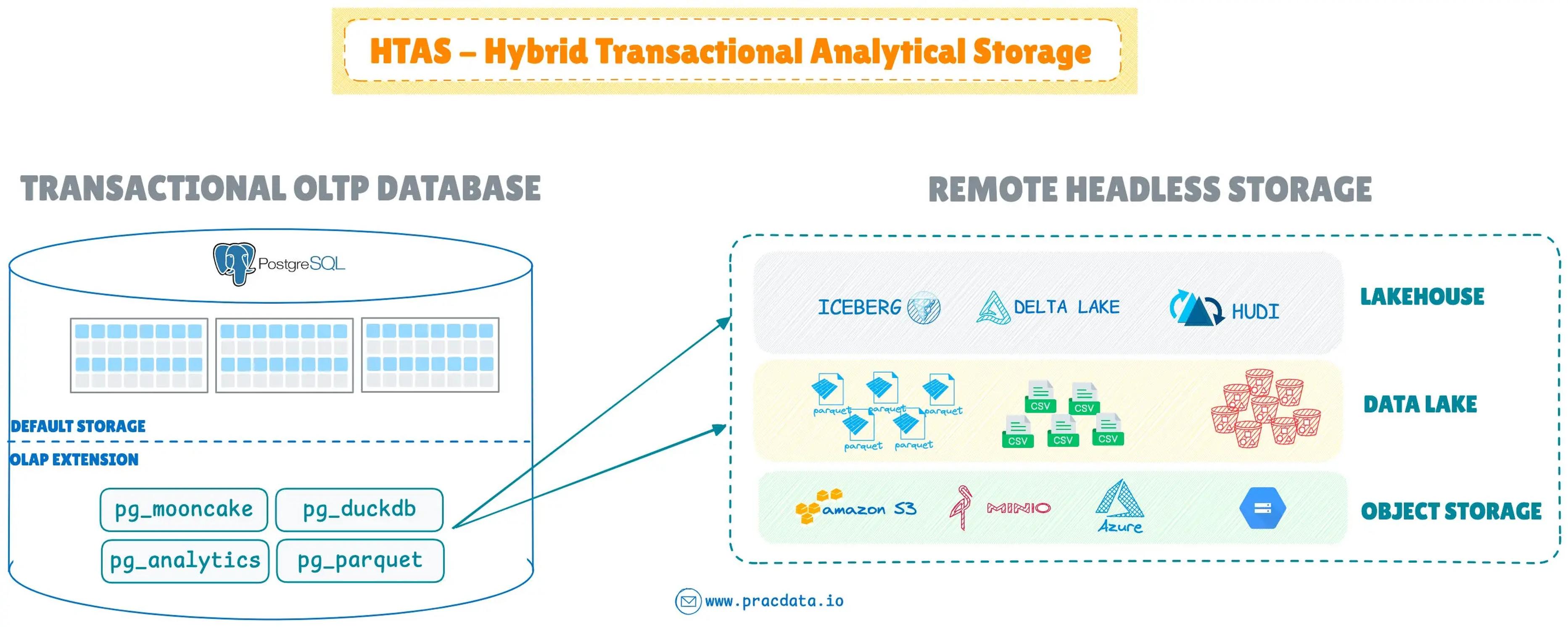
零磁盘架构崛起 :
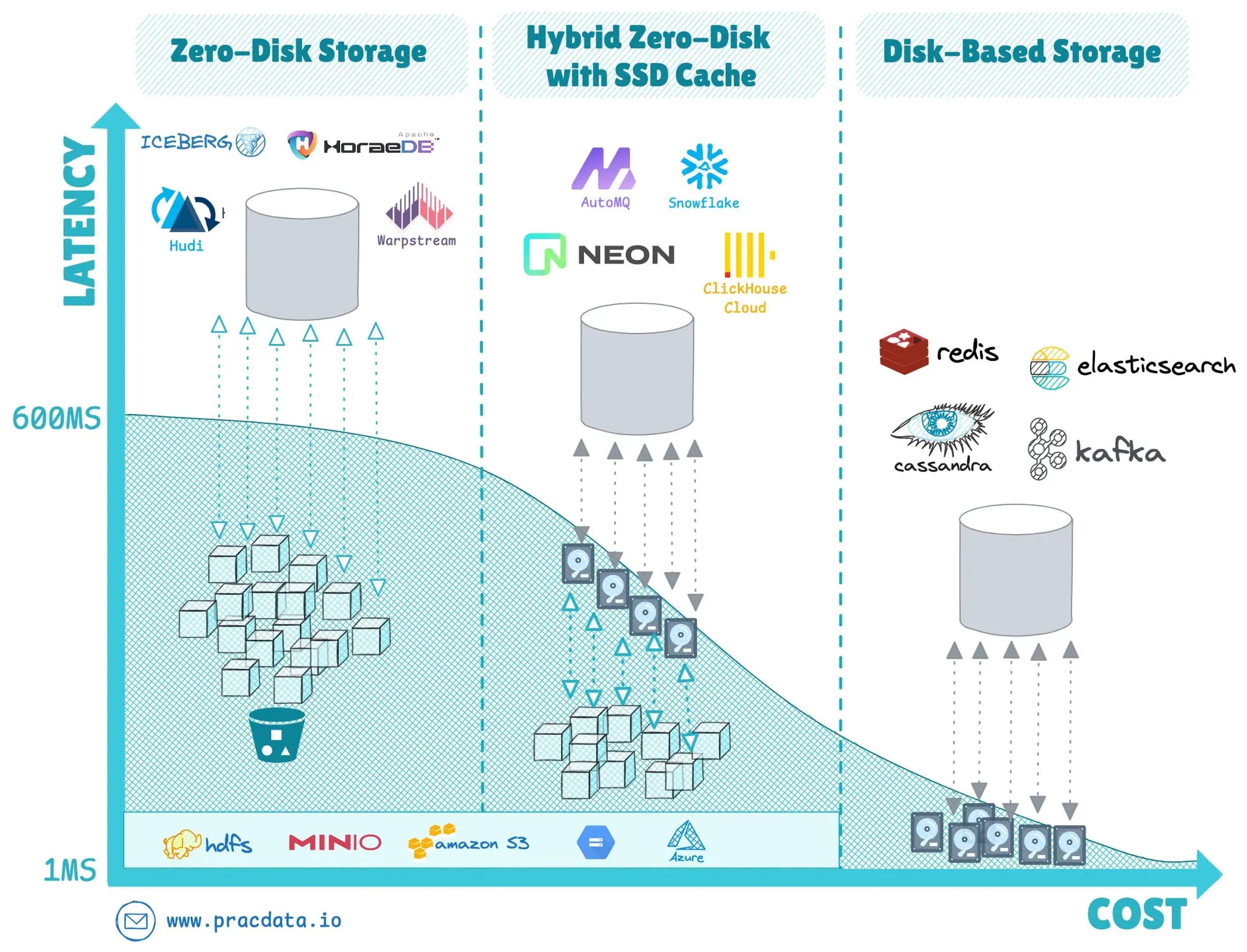
基于 S3 等远程存储的架构成为主流,SlateDB、Apache HoraeDB 等新系统原生支持,Apache Doris、StarRocks 等老牌系统 2024 年跟进。
其他亮点 :
Redis 闭源后,Valkey 成为最受关注的开源替代品,获 Google Memorystore 和 Amazon ElastiCache 支持。
PostgreSQL 生态的 Elasticsearch 替代品 ParadeDB、流式存储系统 Proton 和 Fluss 推动流批融合。
2、数据湖平台
随着数据库先驱迈克尔・斯通布雷克(Michael Stonebraker)将湖仓架构和开放表格格式誉为 "下一个十年的 OLAP 数据库管理系统原型",数据湖仓(lakehouse)继续成为数据工程领域的热点话题。
开放表格格式的生态系统在 2024 年持续演进。第四种主要开放表格格式,Apache Paimon,从孵化阶段毕业,带来了与 Apache Flink 集成的流式湖仓能力。Apache XTable 作为一个新项目,专注于双向格式转换,而 Apache Amoro 进入孵化阶段,提供湖仓管理框架。
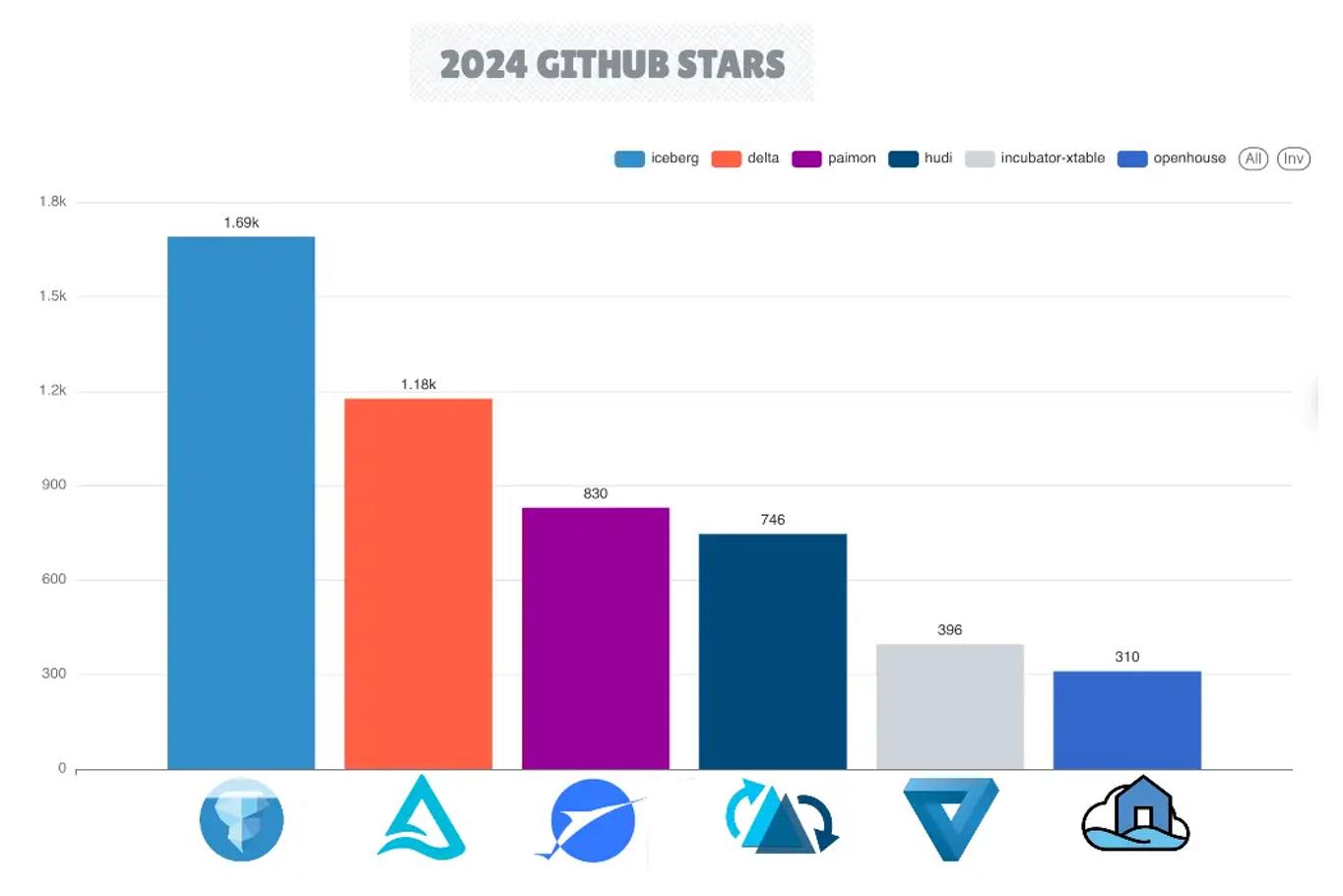
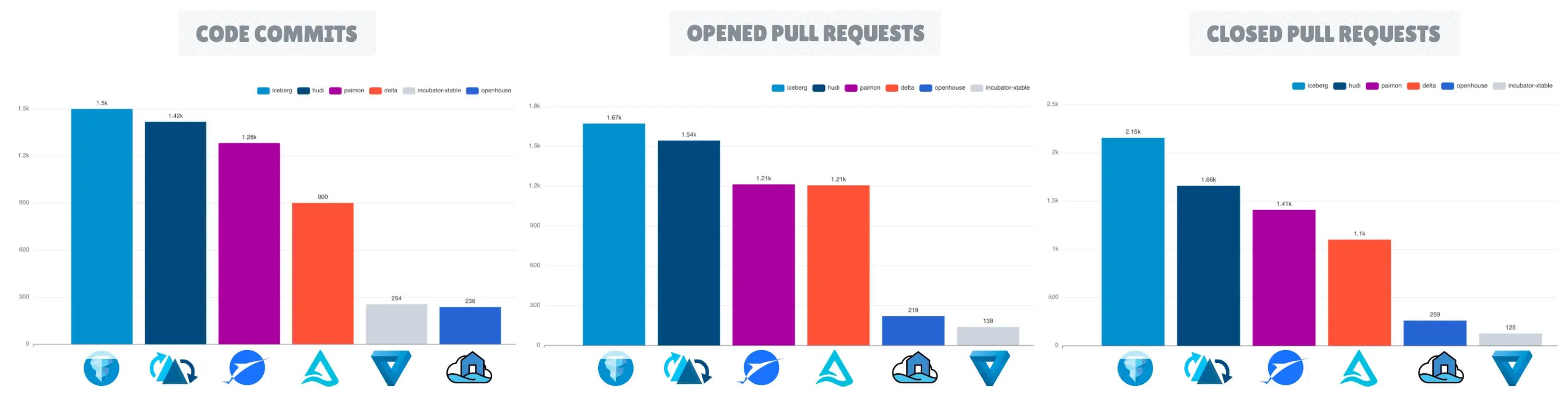
在 2024 年,Apache Iceberg 已确立其作为开放表格格式框架的领先地位,凭借其生态系统的扩展和 GitHub 仓库的指标,包括更高的星标、分叉、拉取请求和提交次数。
所有主要的 SaaS 和云供应商都在增强其平台,以支持对开放表格格式的访问。然而,写入支持相对较少,Apache Iceberg 是全面 CRUD(创建、读取、更新、删除)集成的首选。
谷歌的 BigLake 托管表,允许在客户管理的云存储中使用可变的 Iceberg 表,亚马逊新宣布的 S3 表,原生支持 Iceberg,以及其他主要 SaaS 工具,如 Redpanda 推出的 Iceberg 主题和 Crunchy Data Warehouse 深度集成 Apache Iceberg,都是 Iceberg 在生态系统中日益采用和深度集成的例子。
展望未来,像 Apache XTable 和 Delta UniForm(Delta Lake Universal Format)这样的通用表格格式可能面临在各种格式之间功能潜在分歧的重大挑战,开放表格格式的命运可能类似于开放文件格式,当 Parquet 成为事实上的标准时。
随着湖仓生态系统的持续增长,采用可互操作的开放标准和框架的开放数据湖仓平台预计将获得更多的关注。
原生表数据库兴起
在数据湖生态系统中,一种新的趋势正在兴起,即开发原生的表格式库,这些库使用 Python 和 Rust 编程语言编写。这些库的目标是直接访问开放的表格式,而无需依赖像 Spark 这样重量级的框架。 一些值得关注的例子包括:
1.Delta-rs:这是一个原生的 Rust 库,用于 Delta Lake,并提供了 Python 绑定。它允许开发者直接操作 Delta Lake 表,而无需依赖 Java 或 Apache Spark。
2.Hudi-rs:这是 Apache Hudi 的原生 Rust 实现,同样提供了 Python API。它使 Python 和 Rust 生态系统中的开发者能够更轻松地访问 Hudi 表,而无需依赖 Apache Spark、Java 或 Hadoop。
3.PyIceberg:这是一个正在发展的 Python 库,旨在增强对 Iceberg 表格式的访问能力,使其能够在默认的 Spark 引擎之外使用。
这些原生库的出现,为数据湖的开发和管理提供了更多选择,特别是在需要轻量级解决方案或跨语言开发的场景中。
3、数据处理与集成
单节点处理的崛起
单节点处理的崛起代表了数据处理的根本转变,向传统的分布式优先方法发起挑战。最近的分析显示,许多公司高估了其大数据需求,促使重新评估其数据处理要求。即使在拥有大量数据的组织中,约 90% 的查询仍在可管理的工作负载范围内,可以在单台机器上运行,仅扫描最近的数据。
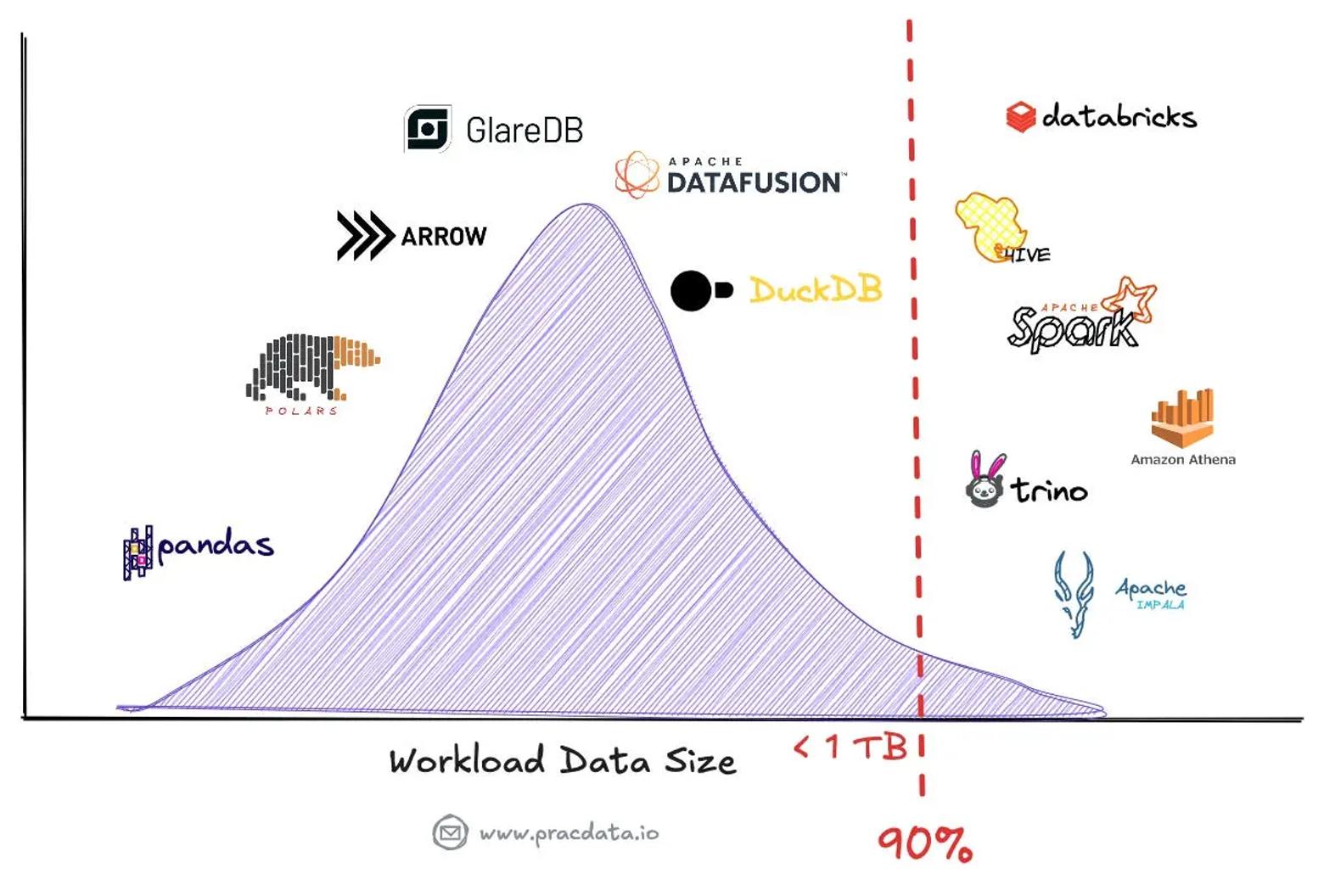
现代单节点处理引擎,如 DuckDB、Apache DataFusion 和 Polars,已成为强大的替代方案,能够处理以前需要分布式系统(如 Hive/Tez、Spark、Presto 或 Amazon Athena)的工作负载。
流处理
流处理生态系统在 2024 年持续扩展,Apache Flink 进一步巩固了其作为首选流处理引擎的地位,而 Apache Spark 仍保持其强大的地位。
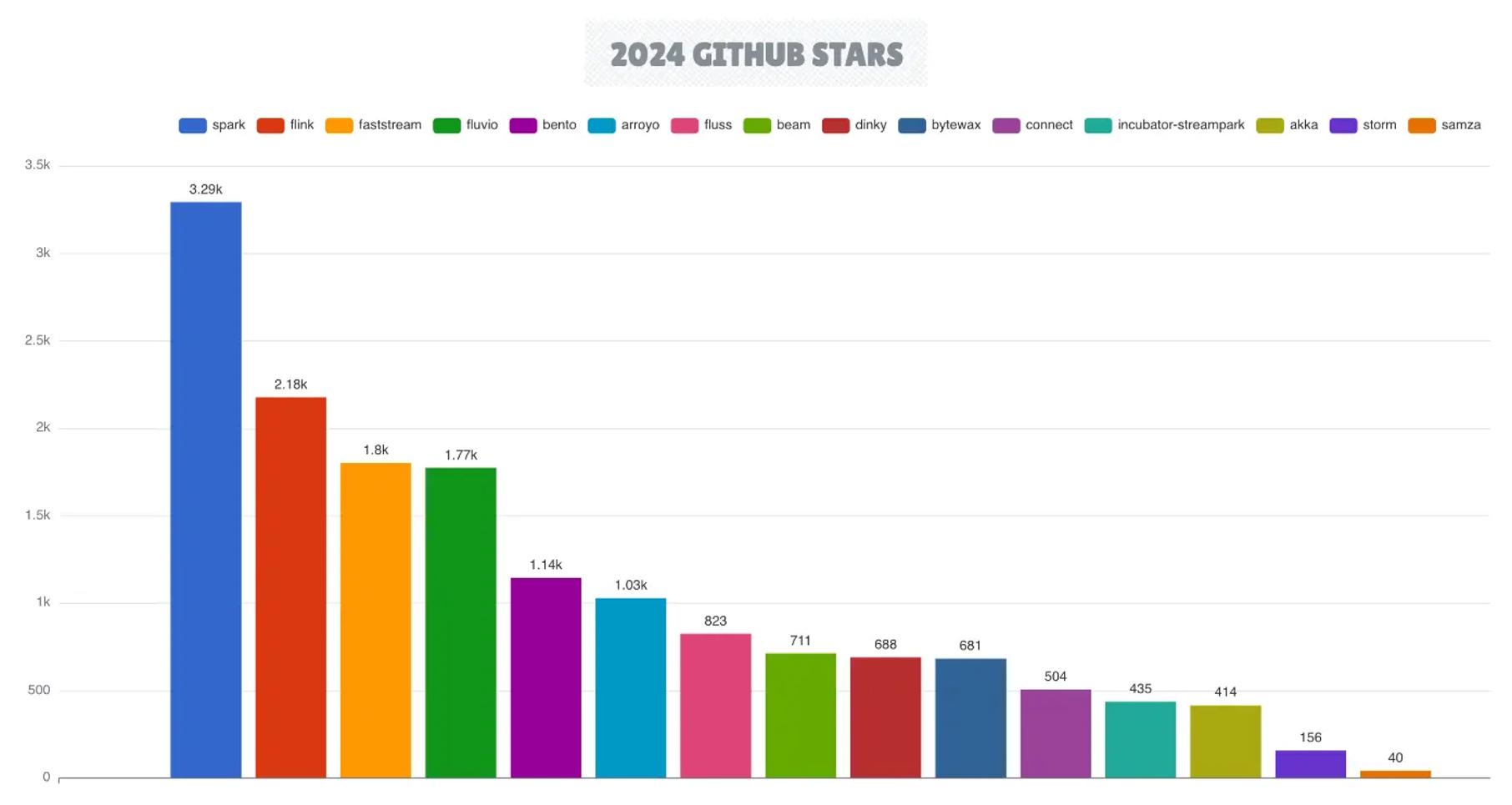
在庆祝其十周年之际,Flink 发布了 2.0 版本,这是自 Flink 1.0 发布八年来的首次重大更新。Apache Flink 生态系统显著扩展,引入了 Apache Paimon 开放表格格式和新开源的 Fluss 流处理引擎。2024 年,领先的云供应商越来越多地将 Flink 集成到其托管服务中,最新的是谷歌的无服务器 BigQuery 引擎用于 Apache Flink 解决方案。
新兴的流处理引擎,如 Fluvio、Arroyo 和 FastStream,努力与这些成熟的竞争者竞争。Fluvio 和 Arroyo 作为唯一的基于 Rust 的引擎,旨在消除传统 JVM 基础的流处理引擎通常存在的开销。
在开源流处理领域的重大新闻中,Redpanda 收购了 Benthos.dev,并将其重新命名为 Redpanda Connect,同时将其许可模式转变为更偏向专有许可。作为回应,WarpStream 对 Benthos 项目进行了分叉,将其重命名为 Bento,并承诺保持其 100% 的 MIT 开源许可。
Python 处理框架
在 Python 数据处理生态系统中,Polars 目前是占主导地位的高性能 DataFrame 库,适用于数据工程工作负载(不包括 PySpark)。Polars 在 2024 年达到了 8900 万次下载的显著里程碑,并发布了 1.0 版本。然而,Polars 现在面临来自 DuckDB 的 DataFrame API 的竞争,后者以其与外部存储系统的惊人简单集成和与 Apache Arrow 的零复制集成(不同系统之间的直接内存共享)引起了社区的关注。两者都在去年排名前 1% 的最受欢迎的 Python 库中。
Apache Arrow 巩固了其作为 Python 数据处理生态系统中内存数据表示的事实标准的地位。该框架与各种 Python 处理框架(包括 Apache DataFusion、Ibis、Daft、cuDF 和 Pandas 3.0)建立了深度集成。Ibis 和 Daft 是其他具有高潜力的创新 DataFrame 项目。Ibis 提供了对各种基于 SQL 的数据库的无缝后端接口,而 Daft 提供了分布式计算能力,从一开始就支持分布式 DataFrame 处理。
4、工作流编排与 DataOps
在 2025 年,开源工作流编排类别依然是数据工程生态系统中最有活力的部分之一,拥有超过 10 个活跃项目,从成熟的平台如 Apache Airflow、Apache DolphinScheduler 到新开源的引擎如 Netflix 的 Maestro。
数据质量
Great Expectations 继续作为领先的 Python 数据质量和验证框架,也被列入 Databricks 2024 年十大数据和 AI 产品榜单,紧随其后的是 Soda 和 Pandera。然而,也有一些令人遗憾的消息:Data-Diff 项目已于 2024 年被其主要维护者 Datafold 存档。
数据版本控制
数据版本控制仍然是 2024 年的一个重要话题,努力将现代版本控制系统(如 Git)的功能引入数据湖和湖仓。像 LakeFS 和 Nessie 这样的项目,通过扩展事务性元数据层,增强了现代数据湖和开放表格格式(如 Iceberg 和 Delta Lake)的功能。
数据转换
dbt 在数据转换方面的应用范围正在扩大,超越了最初在数据仓库系统中的数据建模功能。它现在通过新的集成和插件,利用 Trino 等短暂计算引擎,进入了数据湖等非仓库环境。
目前,dbt 主要面临 SQLMesh 的竞争。2024 年,SQLMesh 与 dbt 之间的竞争引起了广泛关注,Tobiko 的首席执行官在社交媒体上声称,SQLMesh 优秀到被 dbt 的 Coalesce 大会 "禁用"!
5、数据集成
在数据集成领域,Airbyte 保持领先地位,在为版本 1.x 做准备时,成功关闭了 13,000 个拉取请求。
dlt 框架通过 1.0 版本的发布,展示了显著的成熟度,而 Apache SeaTunnel 作为一个有竞争力的替代方案,获得了越来越多的关注。
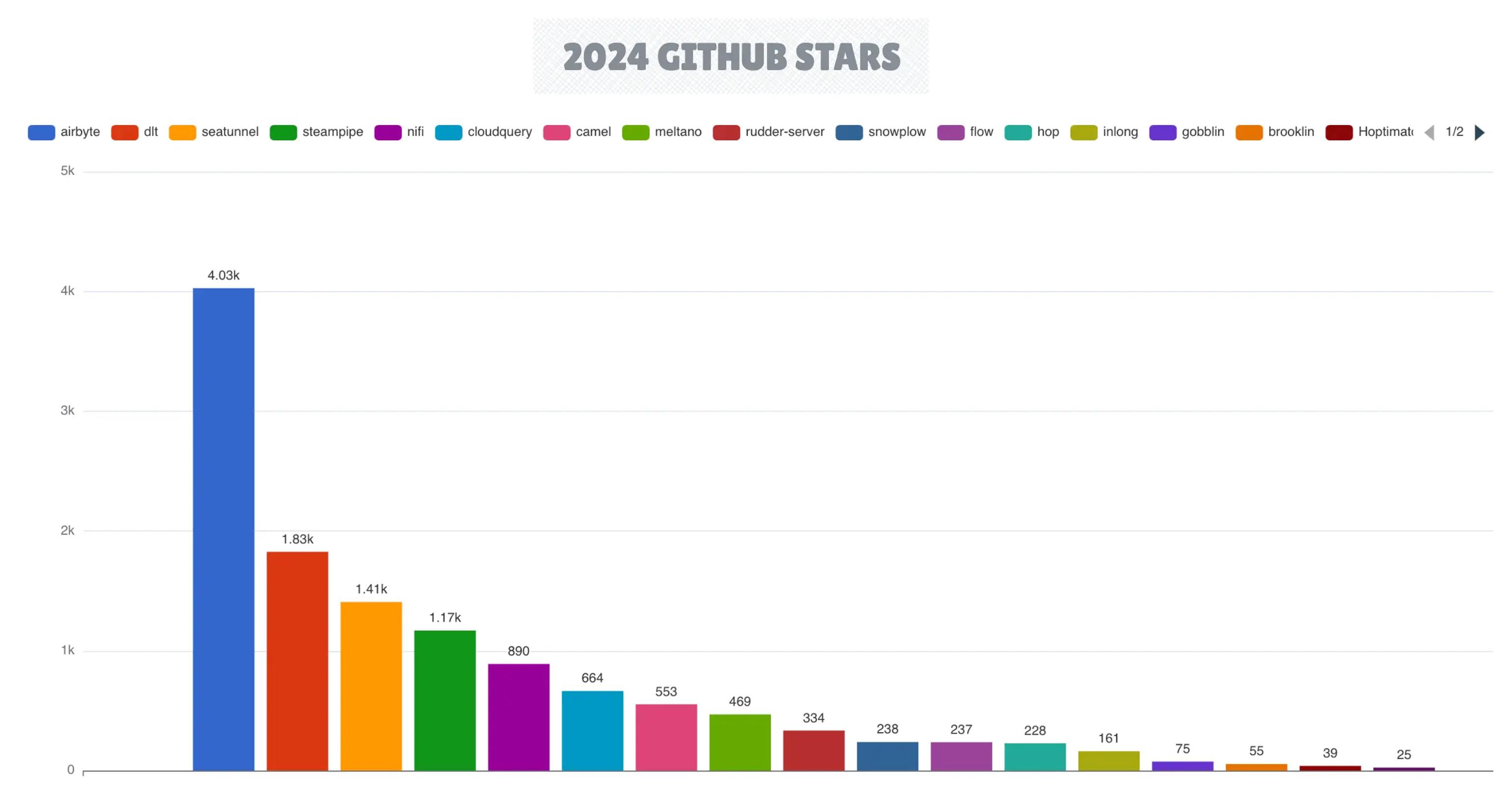
变更数据捕获(CDC)框架
CDC 框架领域出现了新工具,包括 Artie Transfer 和 PeerDB(被 ClickHouse 收购),同时 Flink CDC 连接器在使用 Flink 作为主要流处理引擎的平台中获得了广泛采用。
事件中心(流式发布/订阅服务)
2024 年,数据集成领域出现了显著的架构转变,即存储和计算的分离,以及采用零磁盘架构的对象存储。WarpStream 是实时流式领域中率先实现这一架构的先驱。
这种模型还使得灵活的 "自带云"(BYOC)部署策略成为可能,因为计算和存储可以托管在客户首选的基础设施上,而服务提供商维护控制平面。
WarpStream 的成功促使主要竞争者采用类似的架构。
Redpanda 推出了 Cloud Topics,增强了其产品线,而 AutoMQ 实施了混合方法,采用快速缓存层以提高 I/O 性能。此外,StreamNative 为 Apache Pulsar 推出了 Ursa 引擎,Confluent 在 2024 年推出了自己的云原生 Freight Clusters。
最终,Confluent 决定收购 WarpStream,进一步扩展其产品线,采用 BYOC 模型。与此同时,Apache Kafka 正处于可能定义其未来方向的关键时刻。
6、数据基础设施
2024 年,数据基础设施领域保持稳定,Kubernetes 在庆祝其十周年之际,继续领衔云环境中的资源调度和虚拟化引擎。
在可观察性领域,InfluxDB、Prometheus 和 Grafana 继续占据主导地位,Grafana Labs 通过一轮 2.7 亿美元的融资,巩固了其核心产品(如 Grafana)作为通用可观察性解决方案的长期可行性。
7、机器学习/人工智能平台
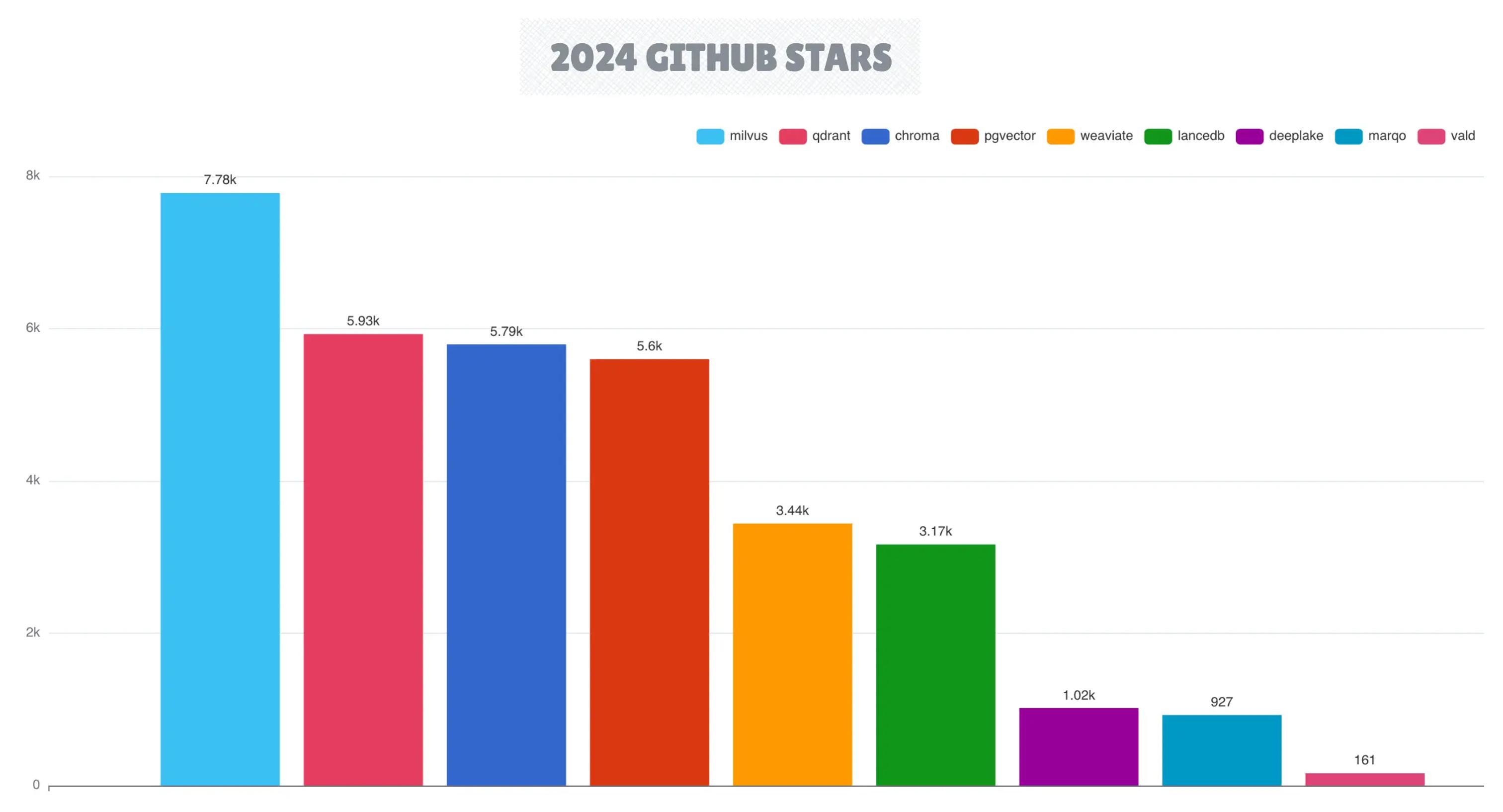
向量数据库在 2023 年的强劲势头下,继续保持增长,Milvus 成为领先者,其它项目包括 Qdrant、Chroma 和 Weaviate。该类别目前有十个活跃的向量数据库项目,反映了向量搜索能力在现代 AI 驱动的数据架构中的重要性。
本年度,LLMOps(也称为 GenOps)作为一个独立类别出现,标志着 Dify 和 vLLM 等新项目的快速增长,专注于管理 LLM 模型。
8、元数据管理
元数据管理平台近年来获得了显著进展,DataHub 通过积极的开发和社区参与,继续在开源领域保持领先地位。然而,2024 年在目录管理方面出现了最显著的发展。与前几年不同,2024 年市场上涌现出一波新的开放目录解决方案,包括 Snowflake 开源的 Polaris、Databricks 开源的 Unity Catalog、LakeKeeper 和 Apache Gravitino。
这种繁荣反映了新兴的数据湖仓平台,依赖于开放表格格式,缺乏内置的高级目录管理功能,以实现多引擎的无缝互操作性。所有这些项目都有潜力建立新的标准,成为数据湖仓平台中供应商中立的开放目录服务。就像 Hive Metastore 曾成为 Hadoop 平台的事实标准一样,这些新兴的目录可能最终取代 Hive Metastore 在开放数据平台上的长期主导地位。
9、分析与可视化
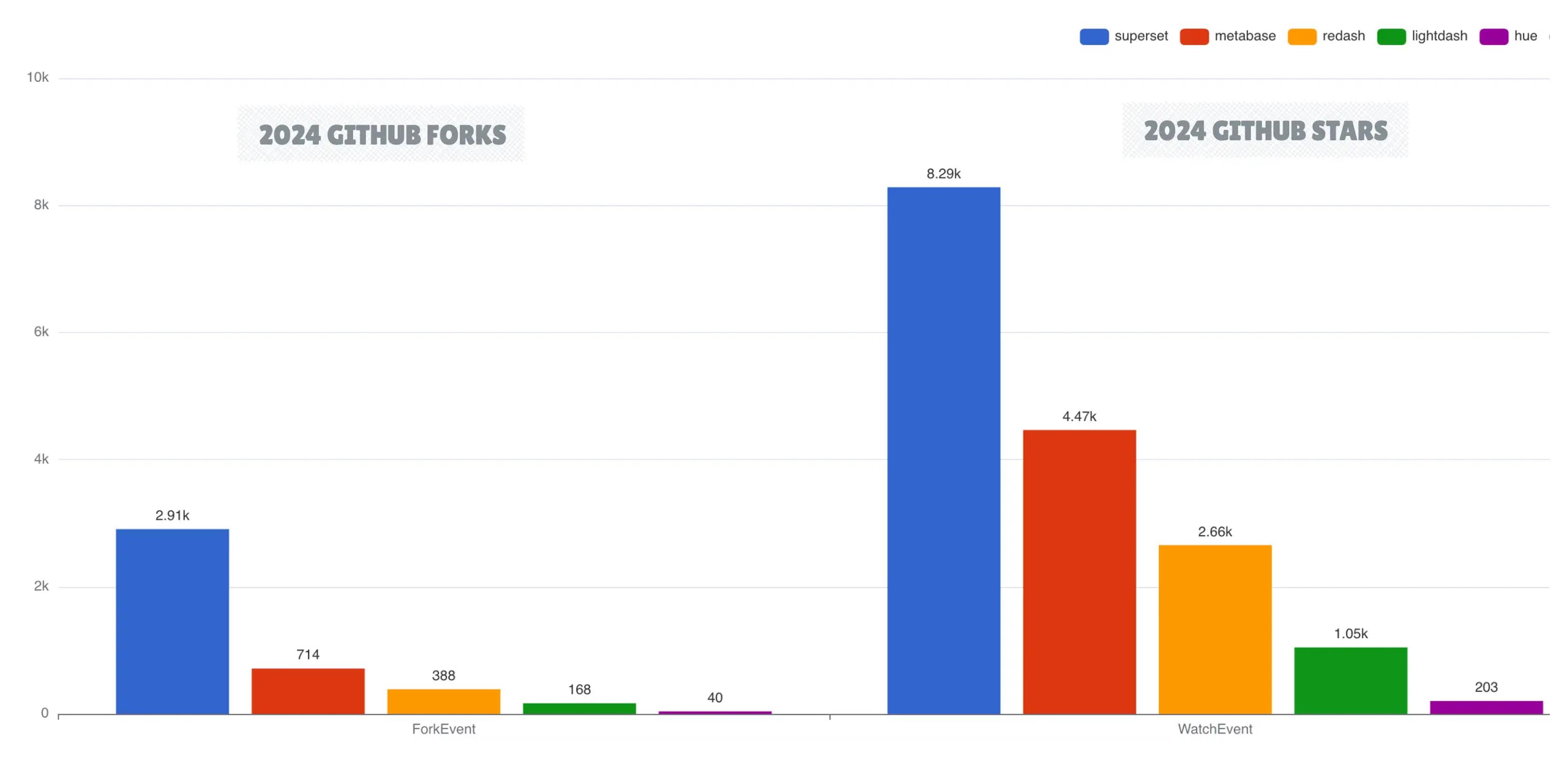
在开源商业智能领域,Apache Superset 和 Metabase 仍然是领先的 BI 解决方案。虽然 Superset 在 GitHub 上更受欢迎,但 Metabase 的开发活动更为活跃。
Lightdash 作为一个有前途的新兴工具,获得了 1100 万美元的融资,展示了市场对轻量级 BI 解决方案的需求。
BI 即代码解决方案
BI 即代码作为一个独特的类别出现,受到 Streamlit 持续成功的推动,Streamlit 保持其作为最受欢迎的 BI 即代码解决方案的地位。
这些工具使开发者能够使用代码、SQL 和模板(如 Markdown 或 YAML)创建交互式应用和轻量级 BI 仪表板,将软件工程的最佳实践,如版本控制、测试和 CI/CD,融入到仪表板开发工作流中。
除了广为人知的 Streamlit 和 Evidence 之外,像 Quary 和 Vizro 这样的新入者也逐渐崭露头角。其中,Quary 特别引人注目,因为它采用了基于 Rust 的开发方式,这与该领域常见的以 Python 为中心的模式有所不同。
可组合 BI 堆栈
系统解耦的演变不仅限于存储系统;它还影响了商业智能(BI)堆栈。一种新兴趋势是将轻量级、无后端服务器的 BI 工具与无头嵌入式 OLAP 解决方案(如 Apache DataFusion、Apache Arrow 和 DuckDB)相结合。
这种集成解决了开放源 BI 堆栈中的一些空白,例如原生查询外部数据湖和湖仓的能力,同时保持轻量级、解耦的架构的优势。
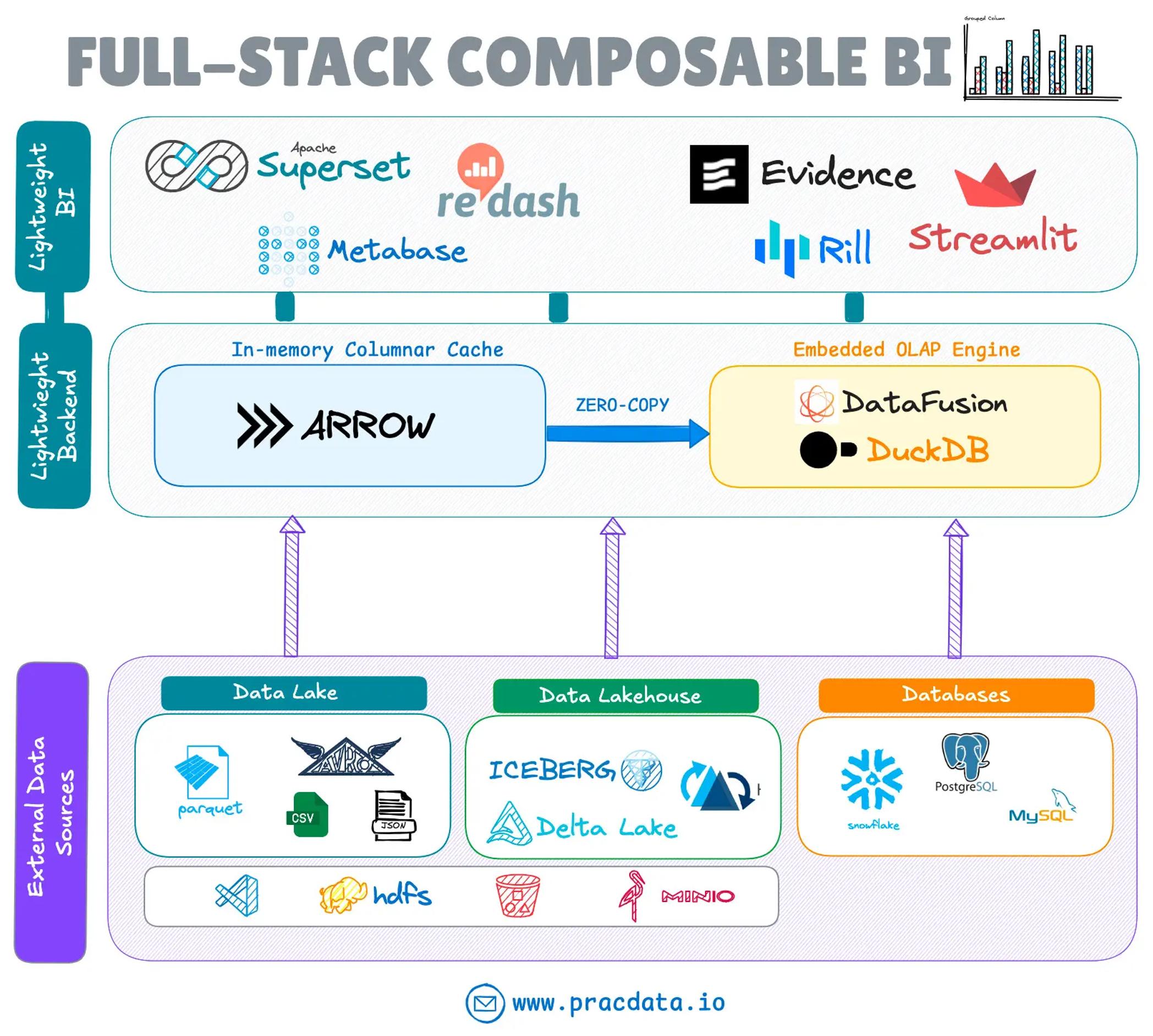
像 Omni、GoodData、Evidence 和 Rilldata 这样的 BI 产品,已经将这些引擎集成到其 BI 和数据探索工具中。Apache Superset(使用 duckdb-engine 库)和 Metabase 现在也支持嵌入式 DuckDB 连接。
MPP 查询引擎
在后 Hadoop 时代,开源 MPP(大规模并行处理)系统的创新和引入相对较少,而现有引擎继续成熟。
虽然 Hive 的份额在下降,但 Presto 和 Trino 仍然是生产中使用的主要开源 MPP 查询引擎,尽管面临着 Spark 作为统一引擎,以及 Databricks、Snowflake 和 AWS Redshift Spectrum 等托管云 MPP 产品的激烈竞争。
未来展望与结论
开源数据生态系统正进入一个成熟阶段,关键领域如数据湖仓,其特征是围绕经过验证的技术的整合和对操作效率的更大关注。
该领域继续朝着云原生、可组合架构方向发展,同时围绕主导技术进行标准化。需要关注的关键领域包括:
1.开放表格格式领域的进一步整合
2.实时和事务性系统中零磁盘架构的持续演变
3.提供统一湖仓体验的追求
4.LLMOps 和 AI 工程的崛起
5.数据湖仓生态系统在开放目录集成和本地库开发等领域的扩展
6.单节点数据处理和嵌入式分析的日益关注。