 Perl语言的正则表达式功能非常强大,基本上是常用语言中最强大的,很多语言设计正则式支持的时候都参考Perl的正则表达式。一般分为三种形式,分别是匹配,替换和转化:
Perl语言的正则表达式功能非常强大,基本上是常用语言中最强大的,很多语言设计正则式支持的时候都参考Perl的正则表达式。一般分为三种形式,分别是匹配,替换和转化:匹配:m//(还可以简写为//,略去m)
替换:s///
转化:tr///
这三种形式一般都和 =~ 或 !~ 搭配使用, =~ 表示相匹配,!~ 表示不匹配。
模式匹配有一些常用的修饰符,如下所示:
| 修饰符 | 描述 |
|---|---|
| i | 忽略模式中的大小写 |
| m | 多行模式 |
| o | 仅赋值一次 |
| s | 单行模式,"."匹配"\n"(默认不匹配) |
| x | 忽略模式中的空白 |
| g | 全局匹配 |
| cg | 全局匹配失败后,允许再次查找匹配串 |
处理完后会给匹配到的值存在三个特殊变量名:
$`: 匹配部分的前一部分字符串
$&: 匹配的字符串
$': 还没有匹配的剩余字符串
如果将这三个变量放在一起将得到原始字符串。
替换操作符 s/// 是匹配操作符的扩展,使用新的字符串替换指定的字符串。基本格式如下:
s/PATTERN/REPLACEMENT/;
PATTERN 为匹配模式,REPLACEMENT 为替换的字符串。
替换操作修饰符如下表所示:
| 修饰符 | 描述 |
|---|---|
| i | 如果在修饰符中加上"i",则正则将会取消大小写敏感性,即"a"和"A" 是一样的。 |
| m | 默认的正则开始"^"和结束"$"只是对于正则字符串如果在修饰符中加上"m",那么开始和结束将会指字符串的每一行:每一行的开头就是"^",结尾就是"$"。 |
| o | 表达式只执行一次。 |
| s | 如果在修饰符中加入"s",那么默认的"."代表除了换行符以外的任何字符将会变成任意字符,也就是包括换行符! |
| x | 如果加上该修饰符,表达式中的空白字符将会被忽略,除非它已经被转义。 |
| g | 替换所有匹配的字符串。 |
| e | 替换字符串作为表达式 |
转化操作符相关的修饰符:
| 修饰符 | 描述 |
|---|---|
| c | 转化所有未指定字符 |
| d | 删除所有指定字符 |
| s | 把多个相同的输出字符缩成一个 |
后发现一篇较为简洁的Perl正则表达式的入门教程,在此共享:This document presents a tabular summary of the regular expression (regexp) syntax in Perl, then illustrates it with a collection of annotated examples.
Metacharacters
char meaning
^ beginning of string
$ end of string
. any character except newline
* match 0 or more times
+ match 1 or more times
? match 0 or 1 times; or: shortest match
| alternative
( ) grouping; “storing”
[ ] set of characters
{ } repetition modifier
\ quote or special
To present a metacharacter as a data character standing for itself, precede it with \ (e.g. \. matches the full stop character . only).
In the table above, the characters themselves, in the first column, are links to descriptions of characters in my The ISO Latin 1 character repertoire - a description with usage notes. Note that the physical appearance (glyph) of a character may vary from one device or program or font to another.
Repetition
a* zero or more a’s
a+ one or more a’s
a? zero or one a’s (i.e., optional a)
a{m} exactly m a’s
a{m,} at least m a’s
a{m,n} at least m but at most n a’s
repetition? same as repetition but the shortest match is taken
Read the notation a’s as “occurrences of strings, each of which matches the pattern a”. Read repetition as any of the repetition expressions listed above it. Shortest match means that the shortest string matching the pattern is taken. The default is “greedy matching”, which finds the longest match. The repetition? construct was introduced in Perl version 5.
Special notations with \
Single characters
\t tab
\n newline
\r return (CR)
\xhh character with hex. code hh
Matching
\w matches any single character classified as a “word” character (alphanumeric or “_”)
\W matches any non-“word” character
\s matches any whitespace character (space, tab, newline)
\S matches any non-whitespace character
\d matches any digit character, equiv. to [0-9]
\D matches any non-digit character
“Zero-width assertions”
\b “word” boundary
\B not a “word” boundary
Character sets: specialities inside [...]
Different meanings apply inside a character set (“character class”) denoted by [...] so that, instead of the normal rules given here, the following apply:
[characters] matches any of the characters in the sequence
[x-y] matches any of the characters from x to y (inclusively) in the ASCII code
[\-] matches the hyphen character “-”
[\n] matches the newline; other single character denotations with \ apply normally, too
[^something] matches any character except those that [something] denotes; that is, immediately after the leading “[”, the circumflex “^” means “not” applied to all of the rest
Examples
expression matches...
abc abc (that exact character sequence, but anywhere in the string)
^abc abc at the beginning of the string
abc$ abc at the end of the string
a|b either of a and b
^abc|abc$ the string abc at the beginning or at the end of the string
ab{2,4}c an a followed by two, three or four b’s followed by a c
ab{2,}c an a followed by at least two b’s followed by a c
ab*c an a followed by any number (zero or more) of b’s followed by a c
ab+c an a followed by one or more b’s followed by a c
ab?c an a followed by an optional b followed by a c; that is, either abc or ac
a.c an a followed by any single character (not newline) followed by a c
a\.c a.c exactly
[abc] any one of a, b and c
[Aa]bc either of Abc and abc
[abc]+ any (nonempty) string of a’s, b’s and c’s (such as a, abba, acbabcacaa)
[^abc]+ any (nonempty) string which does not contain any of a, b and c (such as defg)
\d\d any two decimal digits, such as 42; same as \d{2}
\w+ a “word”: a nonempty sequence of alphanumeric characters and low lines (underscores), such as foo and 12bar8 and foo_1
100\s*mk the strings 100 and mk optionally separated by any amount of white space (spaces, tabs, newlines)
abc\b abc when followed by a word boundary (e.g. in abc! but not in abcd)
perl\B perl when not followed by a word boundary (e.g. in perlert but not in perl stuff)
Examples of simple use in Perl statements
These examples use very simple regexps only. The intent is just to show contexts where regexps might be used, as well as the effect of some “flags” to matching and replacements. Note in particular that matching is by default case-sensitive (Abc does not match abc unless specified otherwise).
s/foo/bar/;
replaces the first occurrence of the exact character sequence foo in the “current string” (in special variable $_) by the character sequence bar; for example, foolish bigfoot would become barlish bigfoot
s/foo/bar/g;
replaces any occurrence of the exact character sequence foo in the “current string” by the character sequence bar; for example, foolish bigfoot would become barlish bigbart
s/foo/bar/gi;
replaces any occurrence of foo case-insensitively in the “current string” by the character sequence bar (e.g. Foo and FOO get replaced by bar too)
if(m/foo/)...
tests whether the current string contains the string foo
小结如下
正则表达式有三种存在形式
分别是
(1) 模式匹配:m/<regexp>/ #平时我们简写 /<regexp>/ ,略去m
三个参数
/i不区分大小写 /s匹配任何字符 /x添加空格 /o 不重复编译正则表达示
(2) 模式替换:s/<pattern>/<replacement>/
/g 进行全局替换 \U 大小写转换,例如s/(fred|barney)/\U$1/gi;
\L 转换小写 \E 影响到剩余的(替换的)字符串
\l 和\u 写形式时(\l 和\u),只作用于下一个字符
(3) 模式转化:tr/<pattern>/<replacemnt>/
这三种形式一般都和 =~ 或 !~ 搭配使用,"=~" 表示相匹配(does),"!~" 表示不匹配(doesn't),并在左侧有待处理的标量变量;如果没有该要处理的变量,则默认为处理 $_ 变量中的内容。
*?、+?、?? 为这三个数量词的非贪婪的类型。
扩展模式匹配
/pattern(?=string)/ 肯定和否定的匹配 ?= 和 ?-,这个在(?=)中的内容不会存到$&中。
处理完后会给匹配到的值分三部分存到三个特殊变量名中
$&, $`, $':匹配上的那部分字符串将自动存储在 $& 之中,即 $& 为整个被匹配的部分,匹配部分的前一部分存放在 $` 之中,后一部分被存到 $';另一种说法是,$` 中含有正则表达式引擎在匹配成功前所找到的变量,而 $' 为此模式还没有匹配的剩余部分。如果将这三个变量放在一起将得到原始字符串。
可选的修饰符
有几个修饰符,通常叫做标记,可以后缀在正则表达式后面来改变其默认的行为。
/i :不区分大小写
/s :匹配任何字符。例如: 点(.)不匹配换行符,如果加上/s这个修饰符,它将点(.)的行为变成同字符类[\d\D]的行为类似,可以匹配任何字符,包括换行符。
/x :添加空格。/x修饰符允许你在模式中加入任何数量的空白,以方便阅读。
例如: (/-? \d+ \.? \d* /x) 等同于 (/-?\d+\.?\d*/)
将可选修饰符结合起来,其顺序是不重要的,例如 (/barney.*fred/is)
正则的优化建议
(1).使用 /o 来优化要多次运行但不修改的表达示
(2).使用 qr 在运行前编译要多次运行的正则表达示
(3).短字符用 /aaa/ || /bbb/ || /ccc/分割比 /aaa|bbb|ccc/ 速度快
(4).试着用 study 模式来学习正则
判断当前位置的前后字符,是否符合指定的条件,但不匹配前后的字符。
字符:描述
\:将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。
^:匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。
$:匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。
*:匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。
+:匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。
?:匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。
{n}:n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。
{n,}:n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。
{n,m}:m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。
?:当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。
.:匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。
(pattern):匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。
(?:pattern):匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。
(?=pattern):正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern):负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
x|y:匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。
[xyz] :字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。
[^xyz]:负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。
[a-z]:字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。
[^a-z]:负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。
\b:匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B:匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。
\cx:匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。
\d:匹配一个数字字符。等价于 [0-9]。
\D:匹配一个非数字字符。等价于 [^0-9]。
\f:匹配一个换页符。等价于 \x0c 和 \cL。
\n:匹配一个换行符。等价于 \x0a 和 \cJ。
\r:匹配一个回车符。等价于 \x0d 和 \cM。
\s:匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S:匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\t:匹配一个制表符。等价于 \x09 和 \cI。
\v:匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w:匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
\W:匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。
\xn:匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。
\num:匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。
\n:标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。
\nm:标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。
\nml:如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。
\un:匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。
图示如下: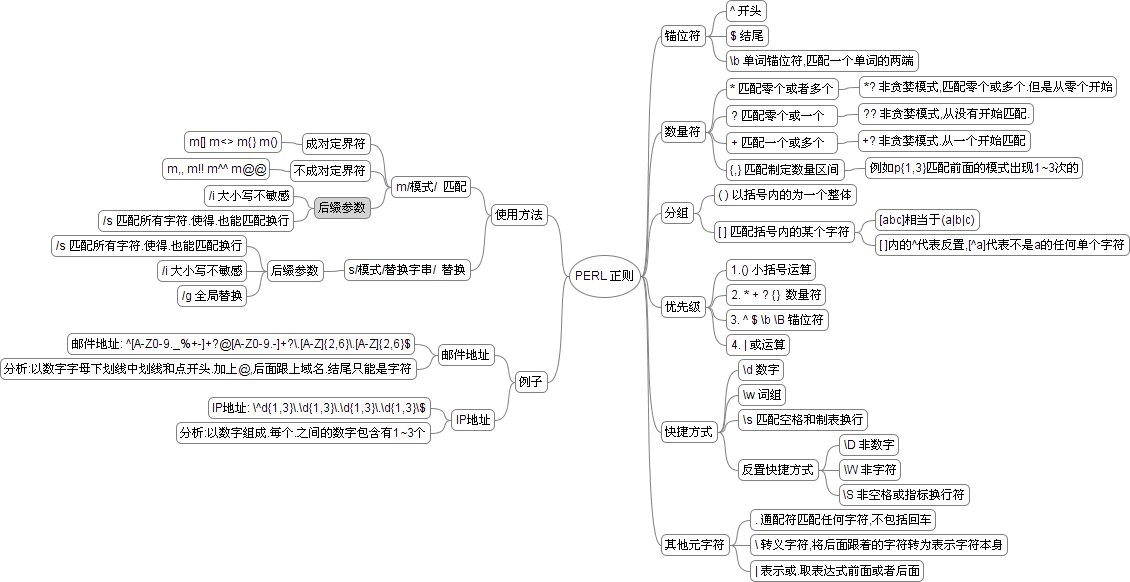
学完本篇,还可以通过站内另外两篇来巩固和晋级:
Perl正则表达式进阶
Perl正则表达式详细教程
参考链接:
Regular Expressions
Regular expressions in Perl
Special pattern matching character operators