开源汇编语言简介
 汇编语言(英语:assembly language)是一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同的设备中,汇编语言对应着不同的机器语言指令集。一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。
汇编语言(英语:assembly language)是一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同的设备中,汇编语言对应着不同的机器语言指令集。一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。使用汇编语言编写的源代码,然后通过相应的汇编程序将它们转换成可执行的机器代码,这一过程被称为汇编过程。许多汇编程序为程序开发、汇编控制、辅助调试提供了额外的支持机制。有的汇编语言编写工具经常会提供宏,它们也被称为宏汇编器。它使用助记符(Mnemonics)来代替和表示特定低级机器语言的操作,特定的汇编目标指令集可能会包括特定的操作数。许多汇编程序可以识别代表地址和常量的标签(Label)和符号(Symbols),这样就可以用字符来代表操作数而无需采取写死的方式。普遍地说,每一种特定的汇编语言和其特定的机器语言指令集是一一对应的。
现在汇编语言已不像其他大多数的程序设计语言一样被广泛用于程序设计,在今天的实际应用中,它通常被应用在底层硬件操作和高要求的程序优化的场合,如驱动程序、嵌入式操作系统和实时运行程序都需要汇编语言。由于汇编更接近机器语言,能够直接对硬件进行操作,生成的程序与其他的语言相比具有更高的运行速度,占用更小的内存,因此在一些对于时效性要求很高的程序、许多大型程序的核心模块以及工业控制方面大量应用。虽然有众多编程语言可供选择,但汇编依然是各大学计算机科学类专业学生的必修课,以让学生深入了解计算机的运行原理。
汇编语言是一门至关重要的技术,它为计算机程序员提供了一种底层的编程方式,直接与计算机硬件进行交互。在二十世纪中期,计算机远非今天的小巧便携设备,而是占据整个房间的巨型机器。这些计算机使用的是机器语言,一种直接操作硬件的低级语言,需要程序员使用数字代码来编写程序,这对于人们来说非常复杂和繁琐。其诞生可以追溯到20世纪50年代,当时计算机科学家们意识到,编写机器语言程序是一项繁重的工作,容易出错,并且不利于程序的维护和修改。因此人们开始寻找一种更高级的方式来编写程序,这就是汇编语言的契机。1950年代末期,IBM公司推出了第一种汇编语言,称为“汇编程序”。这个汇编语言是为了IBM 704计算机而设计的,它使用英语单词和助记符来代替数字代码,大大提高了程序的可读性和可维护性。这个创举标志着汇编语言的诞生,它为程序员提供了一种更加人性化的编程方式。
汇编语言并没有停留在IBM的汇编程序上。随着计算机技术的不断发展,各种各样的汇编语言涌现出来,每种语言都针对特定的硬件架构和应用领域进行了优化。这些语言包括x86汇编、ARM汇编等,它们逐渐成为了不同计算机体系结构的标准编程语言。其诞生和发展对计算机科学产生了深远的影响。它让程序员更接近计算机硬件,能够更精细地控制计算机的行为。此外,汇编语言也是高级编程语言的基础,现代编程语言如C、C++、Perl等都是建立在汇编语言的基础上,通过编译器将高级代码转化为汇编语言,最终执行在计算机上。
机器语言和汇编语言
机器语言是机器指令的集合,是一系列二进制数字组成的,CPU可通过电脉冲驱动直接执行这些二进制的机器指令。因CPU的硬件设计和内部结构的不同,导致不同的CPU具有不同的机器指令集,也即不同的机器语言。例如8086 CPU完成运算s=768+12288-1280时,机器码如下:
101110000000000000000011
000001010000000000110000
001011010000000000000101
可读性非常差,如果某个二进制位写错,将非常难以找出错误。所以汇编语言出现了,汇编语言的主题是汇编指令。汇编指令和机器指令的区别在于指令的表示方法上,汇编指令是机器指令的更便于记忆的版本。例如:
操作:将寄存器BX的内容送到寄存器AX中
机器指令版:1000100111011000
汇编指令版:mov ax,bx
其中寄存器是CPU中可以存放数据的器件,一个CPU可有多个寄存器,AX、BX都是寄存器的代号。
CPU只认识二进制的机器语言,不认识汇编语言的指令,汇编指令只有程序员理解,为了让汇编指令也能让CPU执行,需要使用汇编编译器将汇编指令翻译为机器指令。
程序员 -> 汇编指令(mov ax,bx) -> 编译器 -> 机器指令(1000100111011000) -> CPU
汇编语言有三类指令组成:
(1).汇编指令:是机器指令的助记符,均有对应的二进制机器指令,是汇编语言的核心指令
(2).伪指令:没有对应的机器指令,是由编译器负责执行的,计算机自身不执行
(3).其它符号:如+ - * /等,也是由编译器识别的,没有对应的机器指令
存储器:内存
CPU是计算器核心部件,负责所有运算。但是运算需要有指令(做什么运算)和数据(对谁做运算),指令和数据存放在存储器中,即内存中。CPU不直接从磁盘读取数据,如果指令和数据存放在磁盘上,则先从磁盘读取到内存,然后CPU从内存中读取数据。
所谓的指令和数据都是二进制数字,都存放在内存或磁盘上。但是CPU需要在逻辑上区分某段二进制数字是指令还是数据。比如二进制10001001 11011000,计算机既可以将其看作是数据89D8H(其中H用于表示前面的89D8是十六进制)进行处理,也可以将其看作是指令mov ax,bx进行执行。
存储单元
存储器(内存)被划分为若干存储单元,从0开始顺序编号,这些编号是每个存储单元在内存中的地址。例如0-127表示有128个存储单元。电子计算机的最小信息单位是比特(bit),即一个二进制的位,1字节(Byte)为8bit,即8个二进制位。每个存储单元可存储1字节,所以128个存储单元可存储128字节的数据。
CPU对内存的读写
内存被划分成存储单元,CPU要读写内存,需要三步:
(1).CPU要找到目标存储单元的地址信息来表示读写哪一个存储单元(地址信息)
(2).CPU要指明操作哪个部件(因为除了内存还有其它部件),以及做读操作还是写操作(控制信息)
(3).从内存读数据,或向内存写数据(数据信息)
CPU要传输信息都是通过电信号(用高低电平来表示1和0)完成,电信号需要使用导线来传送。所以,在计算机中,使用一根根的导线来连接CPU和其它部件的芯片,这一根根的导线称为总线。每一个CPU芯片都有许多针脚,这些针脚和总线相连,或者说,这些针脚引出总线。
从物理结构上来看,总线就是导线的集合。从逻辑上来划分,总线分为三类:
地址总线:在CPU和其它部件的芯片之间传输地址信息
控制总线:在CPU和其它部件的芯片之间传输控制信息
数据总线:在CPU和其它部件的芯片之间传输数据
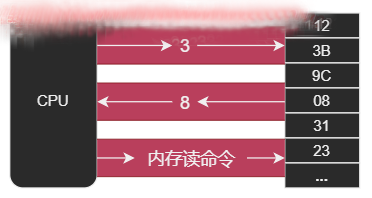
例如,从内存的3号存储单元读取数据:
CPU通过地址总线将地址信息3发送出去
CPU通过控制总线发出内存读命令,选中内存芯片并通知它,将要读取数据
内存将3号存储单元的数据8通过数据总线传输给CPU
如果要向3号存储单元写入数据26。则:
CPU通过地址总线将地址信息3发出
CPU通过控制总线发出内存写命令,选中内存芯片并通知它,将要写入数据
CPU将数据26通过数据总线传给内存的3号存储单元
基于如上描述的读、写过程,读操作对应的机器指令和汇编指令分别为:
含义:从3号单元读取数据送到寄存器AX
机器指令:1010 0001 0000 0011 0000 0000
汇编指令:MOV AX,[3]
地址总线
CPU通多地址总线来寻找存储单元,所以地址总线上能传输多少个不同信息,就决定了CPU能对多少个存储单元进行寻址。
每根导线都只能传输高低电平两种稳定状态,分别对应二进制的1和0。所以,10根总线总共能传输10个二进制位,所以10根总线能描述2^10个数据,即0-1023。
所以,如果是10根地址总线,那么总共能寻址1024个存储单元。如果此时10根地址总线的CPU要向11号存储单元发送信息,这10根地址总线上的二进制数据将为00 0000 1011。
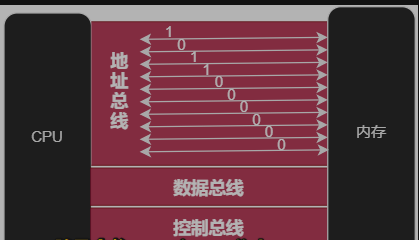
所以,CPU地址总线的宽带(即有几根地址总线)决定了CPU能对多少个存储单元进行寻址(2的N次方),也即决定了能认识多少内存地址,也即决定了最多识别多大内存。
数据总线
CPU和内存或其他部件之间的数据传输是通过数据总线传输的。数据总线的宽度决定了CPU和外界部件之间数据传输的速度。例如,8根数据总线的CPU(比如8088 CPU)一次可传送8个二进制位即一个字节的数据,而16根数据总线的CPU(比如8086 CPU)可一次性传输2个字节。假设要向内存写入数据89D8H,8088和8086传输数据的方式:
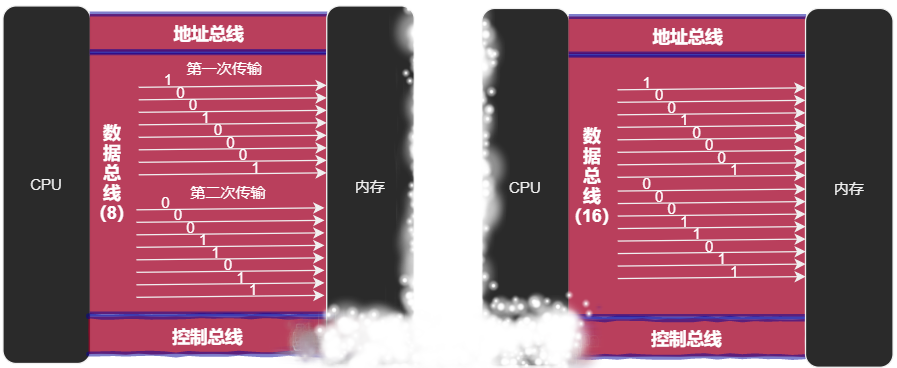
控制总线
CPU通过控制总线来控制外界部件,有多种控制总线的类型。比如读信号控制线负责将CPU发出的控制信息向外传送。控制总线的多少决定了CPU对外界有多少种控制。所以,控制总线的宽度决定CPU对外界部件的控制能力。
内存地址空间
主板上有核心部件和一些主要部件,包括CPU、内存、外围芯片组、扩展插槽等,这些部件通过总线(地址总线、数据总线、控制总线)相连。其中扩展插槽一般插有内存条和其它接口卡。
对于不在主板上的硬件(比如显示器、音箱),它们插在扩展插槽的接口卡上,CPU无法直接控制它们,控制它们的是扩展插槽上的接口卡。因为CPU和扩展插槽是总线相连的,所以CPU可以控制扩展插槽上的内存条或接口卡,然后接口卡控制这些外部设备,从而让CPU间接控制这些外部设备。
一台PC机种,装有多个存储器芯片,分为两类:RAM(可读可写)和ROM(只读)
主存一般由多个位置上的RAM组成:主板上的RAM、扩展插槽上的RAM,接口卡上可能也有RAM,比如显卡的RAM(即显存)
ROM可能也在多个地方提供,一般用于存放BIOS:主板的ROM存放主板的BIOS、显卡的ROM存放显卡的BIOS、网卡的ROM存放网卡的BIOS
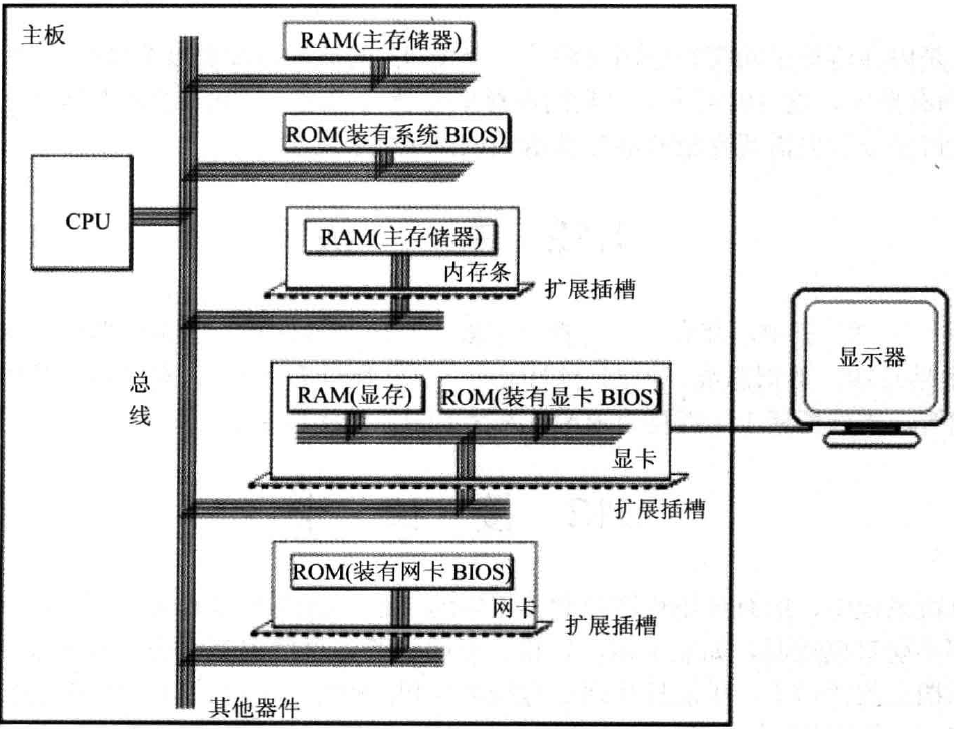
虽然有这么些独立的物理存储器,但是这些存储器都通过总线和CPU相连,且CPU都通过控制总线向它们发送读写控制命令。所以CPU把它们都当作内存来对待:将它们组成一个大的逻辑存储器,对其划分存储单元后,就是内存地址空间。
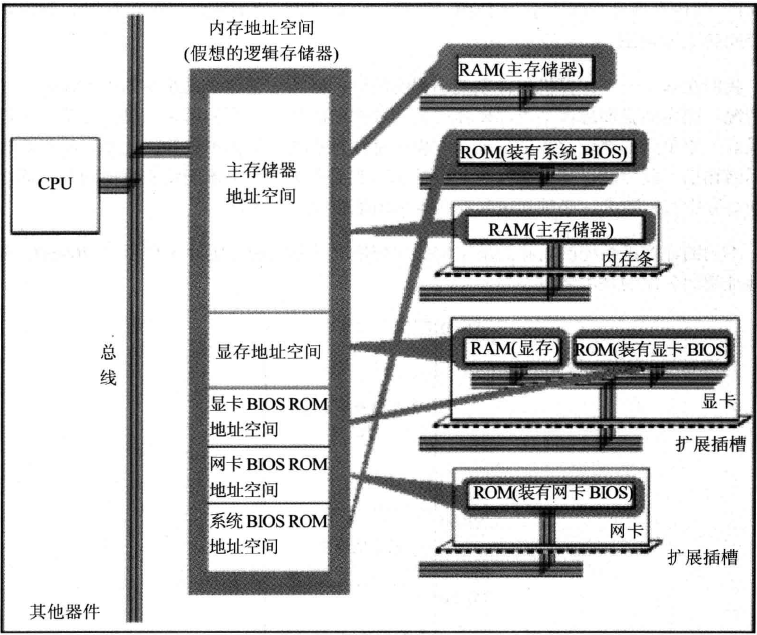
虽然各物理存储器组成了大的逻辑存储器,但每个物理存储器都对应这个大的逻辑存储器中的一个地址段。CPU在某段地址空间读写数据,实际上就是在对应的物理存储器上读写数据。注意,如果CPU是对ROM存储器对应的地址空间段写数据,输入操作将无效,因为ROM是只读不可写的。
CPU的寻址能力由地址总线的宽度决定,所以CPU能寻址的内存地址空间的大小也是由总线宽度决定的。
汇编语言面对的就是内存地址空间。在进行编程的时候,必须要知道内存地址空间的分配情况。比如想要在某类存储器中读写数据,必须要知道它的第一个存储单元的地址和最后一个存储单元的地址,才能保证读写操作是在预期的存储器中进行的。不同计算机的内存地址空间分配情况不一样,8086 PC机的内存地址空间分配情况如下:

所以,CPU向A0000-BFFFF的内存单元写数据,表示向显存中写数据,向C0000-FFFFF的内存单元写数据是无效的,因为它们对应的是只读的ROM。
x86/amd64汇编指令的两大风格分别是Intel汇编与AT&T汇编,分别被Microsoft Windows/Visual C++与GNU/Gas采用。典型的现代汇编器(assembler)建造目标代码,由解译组语指令集的助记符(Mnemonics)到操作码,并解析符号名称(Symbolic names)成为存储器地址以及其它的实体。
开源界的两种类型的汇编语言工具:nasm、yasm,以下为某软件在编译过程中所报出的asm的相关依赖。
checking for yasm... no
no yasm
checking for nasm... no
no nasm
configure: error: No modern nasm or yasm found as required. Nasm should be v2.11.01 or later (v2.13 for AVX512) and yasm should be 1.2.0 or later.
NASM (Netwide Assembler) is an 80x86 assembler designed for portability and modularity. It includes a disassembler as well(是一个80x86汇编程序,设计用于可移植性和模块化。它还包括一个可拆卸的单位工具)。
Netwide Assembler(简称 NASM)是一款基于英特尔 x86 架构的汇编与反汇编工具。它可以用来编写16位、32位(IA-32)和64位(x86-64)的程序,NASM被认为是Linux平台上最受欢迎的汇编工具之一。NASM 最初是在朱利安·霍尔的协助下由西蒙·泰瑟姆开发的。截至2016年,它被一个由H.Peter Anvin领导的小团队所维护。
NASM 可以输出包括 COFF、OMF、a.out、可执行与可链接格式(ELF)、Mach-O 和二进制文件(.bin,二进制磁盘映像,用于编译操作系统)等多种二进制格式,而地址无关代码仅支持ELF对象文件,NASM 也有自己的称为 RDOFF 的二进制格式。
输出格式的广泛性允许将程序重定向到任何 x86 操作系统(OS)。 此外,NASM 可以创建浮动二进制文件,它可用于写入引导加载程序、只读存储器(ROM)映像以及操作系统开发的各个方面。NASM 可以作为交叉汇编程序(如PowerPC和SPARC)在非 x86 平台上运行,尽管它不能生成这些机器可用的程序。NASM 使用英特尔汇编语法的变体而不是 AT&T 语法(GNU 汇编器采用的语法)。它还避免了 MASM 和兼容汇编器使用的自动生成段覆盖(以及相关的 ASSUME 指令)等功能。
最新版本:2.14
官方主页:https://www.nasm.us/
Yasm is a complete rewrite of the NASM-2.14.02 assembler. It supports the x86 and AMD64 instruction sets, accepts NASM and GAS assembler syntaxes and outputs binary, ELF32 and ELF64 object formats.
Yasm是基于NASM-2.14.02汇编程序进行了完整重写。它支持x86和AMD64指令集,接受NASM和GAS汇编程序语法,并能输出二进制、ELF32和ELF64对象格式。
Yasm is a complete rewrite of the NASM assembler under the 'new' BSD License (some portions are under other licenses, see COPYING for details).Yasm can be easily integrated into Visual Studio 2005/2008 and 2010 for assembly of NASM or GAS syntax code into Win32 or Win64 object files.
Yasm currently supports the x86 and AMD64 instruction sets, accepts NASM and GAS assembler syntaxes, outputs binary, ELF32, ELF64, 32 and 64-bit Mach-O, RDOFF2, COFF, Win32, and Win64 object formats, and generates source debugging information in STABS, DWARF 2, and CodeView 8 formats.
最新版本:1.3
官方主页:
https://yasm.tortall.net/
https://github.com/yasm
开发人员要了解的汇编语言
计算机不理解程序员所使用的高级语言,必须通过编译器转成二进制代码才能运行。学会高级语言并不等于理解计算机实际的运行步骤。
计算机真正能够理解的是低级语言,它专门用来控制硬件。汇编语言就是低级语言,直接描述/控制 CPU 的运行。如果想了解 CPU 到底干了些什么,以及代码的运行步骤,就一定要学习汇编语言。但对它的学习不容易,就连简明扼要的介绍都很难找到。下面引入他人所写的一篇最好懂的汇编语言教程,解释 CPU 如何执行代码。
一、汇编语言是什么?
我们知道,CPU 只负责计算,本身不具备智能。当输入一条指令(instruction),它就运行一次,然后停下来,等待下一条指令。这些指令都是二进制的,称为操作码(opcode),比如加法指令就是00000011。编译器的作用,就是将高级语言写好的程序,翻译成一条条操作码。对于人类来说,二进制程序是不可读的,根本看不出来机器干了什么。为了解决可读性的问题,以及偶尔的编辑需求,就诞生了汇编语言。
「汇编语言是二进制指令的文本形式」,与指令是一一对应的关系。比如,加法指令00000011写成汇编语言就是 ADD。只要还原成二进制,汇编语言就可以被 CPU 直接执行,所以它是最底层的低级语言。
二、来历
最早的时候,编写程序就是手写二进制指令,然后通过各种开关输入计算机,比如要做加法了,就按一下加法开关。后来,发明了纸带打孔机,通过在纸带上打孔,将二进制指令自动输入计算机。为了解决二进制指令的可读性问题,工程师将那些指令写成了八进制。二进制转八进制是轻而易举的,但是八进制的可读性也不行。
很自然地,最后还是用文字表达,加法指令写成 ADD。内存地址也不再直接引用,而是用标签表示。这样的话,就多出一个步骤,要把这些文字指令翻译成二进制,这个步骤就称为 assembling,完成这个步骤的程序就叫做 assembler。它处理的文本,自然就叫做 aseembly code。标准化以后,称为 assembly language,缩写为 asm,中文译为汇编语言。

每一种 CPU 的机器指令都是不一样的,因此对应的汇编语言也不一样。本节介绍的是目前最常见的 x86 汇编语言,即 Intel 公司的 CPU 使用的那一种。
三、寄存器
学习汇编语言,首先必须了解两个知识点:寄存器和内存模型。先来看寄存器。CPU 本身只负责运算,不负责储存数据。数据一般都储存在内存之中,CPU 要用的时候就去内存读写数据。但是,CPU 的运算速度远高于内存的读写速度,为了避免被拖慢,CPU 都自带一级缓存和二级缓存。基本上,CPU 缓存可以看作是读写速度较快的内存。但 CPU 缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU 每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU 还自带了寄存器(register),用来储存最常用的数据。也就是说,那些最频繁读写的数据(比如循环变量),都会放在寄存器里面,CPU 优先读写寄存器,再由寄存器跟内存交换数据。
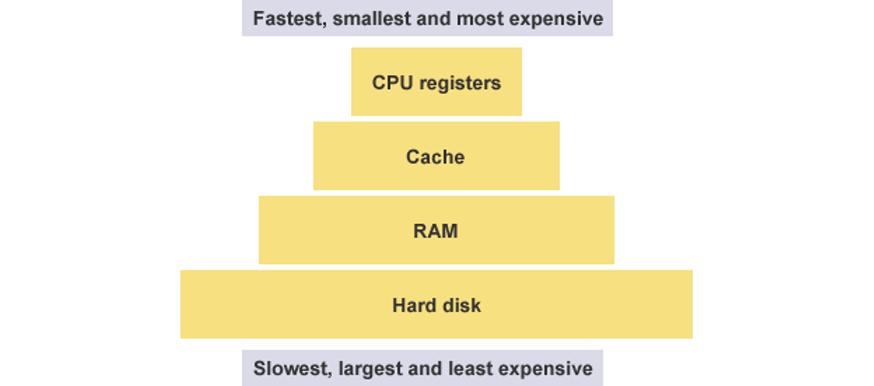
寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉 CPU 去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是 CPU 的零级缓存。
四、寄存器的种类
早期的 x86 CPU 只有8个寄存器,而且每个都有不同的用途。现在的寄存器已经有100多个了,都变成通用寄存器,不特别指定用途了,但是早期寄存器的名字都被保存了下来。EAX、EBX、ECX、EDX、EDI、ESI、EBP、ESP这8个寄存器之中,前面七个都是通用的。ESP 寄存器有特定用途,保存当前 Stack 的地址(详见下一节)。
常常看到 32位 CPU、64位 CPU 这样的名称,其实指的就是寄存器的大小。32 位 CPU 的寄存器大小就是4个字节。
五、内存模型:Heap
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。

程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020。
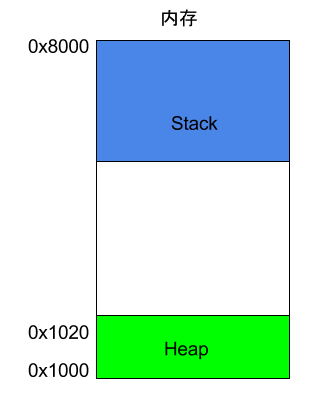
这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
六、内存模型:Stack
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于函数运行而临时占用的内存区域。
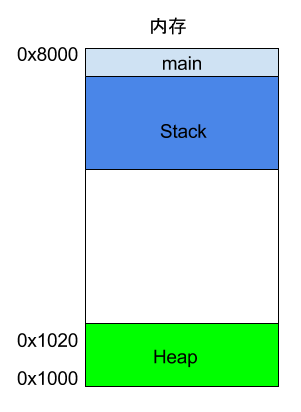
请看下面的例子。
int main() {
int a = 2;
int b = 3;
}
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
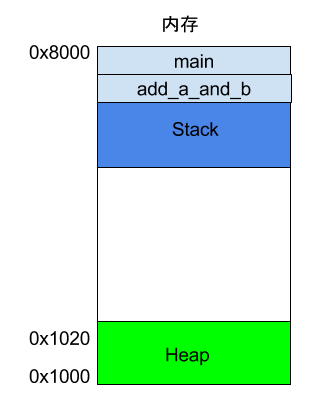
如果函数内部调用了其他函数,会发生什么情况?
int main() {
int a = 2;
int b = 3;
return add_a_and_b(a, b);
}
上面代码中,main函数内部调用了add_a_and_b函数。执行到这一行的时候,系统也会为add_a_and_b新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
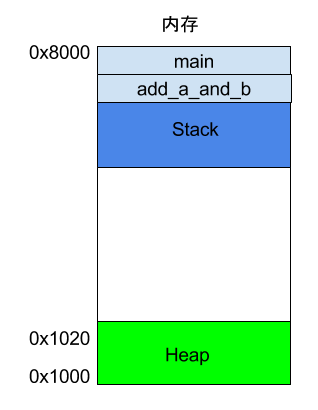
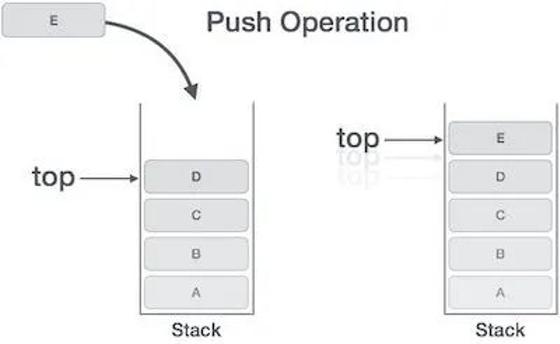
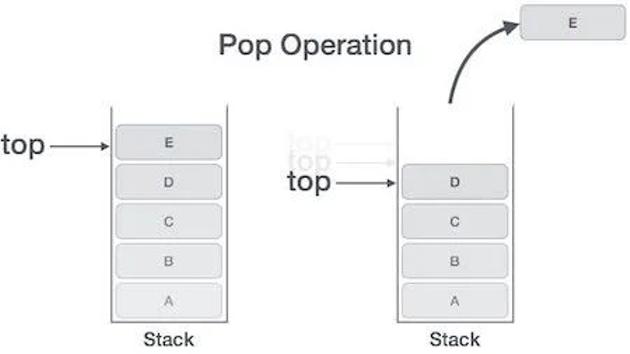
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做"入栈",英文是 push;栈的回收叫做"出栈",英文是 pop。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做"后进先出"的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
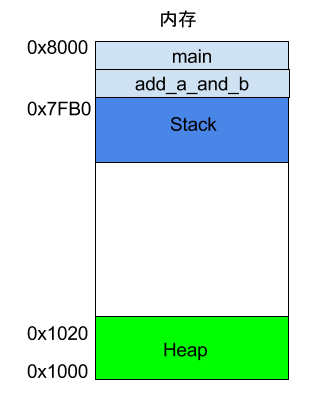
Stack 是由内存区域的结束地址开始,从高位(地址)向低位(地址)分配。比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
七、CPU 指令
7.1 一个实例
了解寄存器和内存模型以后,就可以来看汇编语言到底是什么了。下面是一个简单的程序example.c。
int add_a_and_b(int a, int b) {
return a + b;
}
int main() {
return add_a_and_b(2, 3);
}
gcc 将这个程序转成汇编语言。
$ gcc -S example.c
上面的命令执行以后,会生成一个文本文件example.s,里面就是汇编语言,包含了几十行指令。这么说吧,一个高级语言的简单操作,底层可能由几个,甚至几十个 CPU 指令构成。CPU 依次执行这些指令,完成这一步操作。example.s经过简化以后,大概是下面的样子。
_add_a_and_b:
push %ebx
mov %eax, [%esp+8]
mov %ebx, [%esp+12]
add %eax, %ebx
pop %ebx
ret
_main:
push 3
push 2
call _add_a_and_b
add %esp, 8
ret
可以看到,原程序的两个函数add_a_and_b和main,对应两个标签_add_a_and_b和_main。每个标签里面是该函数所转成的 CPU 运行流程。每一行就是 CPU 执行的一次操作。它又分成两部分,就以其中一行为例。
push %ebx
这一行里面,push是 CPU 指令,%ebx是该指令要用到的运算子。一个 CPU 指令可以有零个到多个运算子。下面就一行一行讲解这个汇编程序,建议读者最好把这个程序,在另一个窗口拷贝一份,省得阅读的时候再把页面滚动上来。
7.2 push 指令
根据约定,程序从_main标签开始执行,这时会在 Stack 上为main建立一个帧,并将 Stack 所指向的地址,写入 ESP 寄存器。后面如果有数据要写入main这个帧,就会写在 ESP 寄存器所保存的地址。然后,开始执行第一行代码。
push 3
push指令用于将运算子放入 Stack,这里就是将3写入main这个帧。虽然看上去很简单,push指令其实有一个前置操作。它会先取出 ESP 寄存器里面的地址,将其减去4个字节,然后将新地址写入 ESP 寄存器。使用减法是因为 Stack 从高位向低位发展,4个字节则是因为3的类型是int,占用4个字节。得到新地址以后, 3 就会写入这个地址开始的四个字节。
push 2
第二行也是一样,push指令将2写入main这个帧,位置紧贴着前面写入的3。这时 ESP 寄存器会再减去 4个字节(累计减去8)。

7.3 call 指令
第三行的call指令用来调用函数。
call _add_a_and_b
上面的代码表示调用add_a_and_b函数。这时,程序就会去找_add_a_and_b标签,并为该函数建立一个新的帧。下面就开始执行_add_a_and_b的代码。push %ebx
这一行表示将 EBX 寄存器里面的值,写入_add_a_and_b这个帧。这是因为后面要用到这个寄存器,就先把里面的值取出来,用完后再写回去。这时push指令会再将 ESP 寄存器里面的地址减去4个字节(累计减去12)。
7.4 mov 指令
mov指令用于将一个值写入某个寄存器。
mov %eax, [%esp+8]
这一行代码表示,先将 ESP 寄存器里面的地址加上8个字节,得到一个新的地址,然后按照这个地址在 Stack 取出数据。根据前面的步骤,可以推算出这里取出的是2,再将2写入 EAX 寄存器。下一行代码也是干同样的事情。
mov %ebx, [%esp+12]
上面的代码将 ESP 寄存器的值加12个字节,再按照这个地址在 Stack 取出数据,这次取出的是3,将其写入 EBX 寄存器。
7.5 add 指令
add指令用于将两个运算子相加,并将结果写入第一个运算子。
add %eax, %ebx
上面的代码将 EAX 寄存器的值(即2)加上 EBX 寄存器的值(即3),得到结果5,再将这个结果写入第一个运算子 EAX 寄存器。
7.6 pop 指令
pop指令用于取出 Stack 最近一个写入的值(即最低位地址的值),并将这个值写入运算子指定的位置。pop %ebx
上面的代码表示,取出 Stack 最近写入的值(即 EBX 寄存器的原始值),再将这个值写回 EBX 寄存器(因为加法已经做完了,EBX 寄存器用不到了)。注意,pop指令还会将 ESP 寄存器里面的地址加4,即回收4个字节。
7.7 ret 指令
ret指令用于终止当前函数的执行,将运行权交还给上层函数。也就是,当前函数的帧将被回收。
ret
可以看到,该指令没有运算子。随着add_a_and_b函数终止执行,系统就回到刚才main函数中断的地方,继续往下执行。
add %esp, 8
上面的代码表示,将 ESP 寄存器里面的地址,手动加上8个字节,再写回 ESP 寄存器。这是因为 ESP 寄存器的是 Stack 的写入开始地址,前面的pop操作已经回收了4个字节,这里再回收8个字节,等于全部回收。
ret
最后,main函数运行结束,ret指令退出程序执行。
汇编语言创建者 Kathleen Booth 去世,享年 100 岁
外媒 TheRegister 报道称,英国最后一位早期计算机先驱 Kathleen Booth 教授于 2022 年 9 月 29 日去世,享年 100 岁。
Kathleen Hylda Valerie Britten 1922 年 7 月 9 日出生于英国伍斯特郡。二战期间,她就读于伦敦大学皇家霍洛威学院,并于 1944 年获得数学学士学位。毕业后,她在范堡罗的一个研究机构 -- 皇家飞机研究所成为一名初级科学官员。两年后,她转到伯贝克学院先是担任研究助理,后来成为讲师,然后又成为了研究员。
她还曾在英国橡胶生产商研究协会 (BRPRA) 工作,在那里遇到了数学家和物理学家 Andrew Donald Booth 与之共事,并结为了夫妻。AD Booth 在跟随 X 射线晶体学家 JD Bernal 教授(Bernal Sphere 的发明者)学习后, 在利用 X 射线衍射数据来研究晶体结构时发现手动计算非常繁琐;于是他建造了一台模拟计算机,使部分工作自动化。
1946 年,Britten 和 Booth 在伯贝克合作开发了一台非常早期的数字计算机,即自动中继计算器 (ARC),并以此建立了现在的伯贝克计算机科学与信息系统系。ARC 建于韦林花园城,靠近 BRPRA 总部。AD Booth 设计了它,但 Kathleen Britten 和她的研究助理 Xenia Sweeting 构建了硬件。另一方面,Bernal 则从洛克菲勒基金会为 Booth 和 Britten 获得了访问普林斯顿高等研究院的资金。

后来,Booth 和 Britten 又重新设计了他们的计算器,从而产生了 ARC2;并在此过程中发明了第一个 drum memory,以提供足够的存储空间来保存程序信息和数据。事实证明,用继电器来建造 ARC2 是不可能的,所以在 1948 年,Booth 和 Britten 转向简单电子计算机 (SEC),然后是 All Purpose Electronic X-Ray Computer 或 APE(X)C。你可以在 MESS emulator 中试用 APE (X) C。
APE (X) C 设计后来被英国制表机有限公司商业化并作为 HEC 出售,最终成为 ICL。
1950 年,Kathleen 和 Andrew 结婚,同年她又从伦敦大学获得了应用数学博士学位。为了为他们的工作争取更多资金,Boot 夫妇再次前往洛克菲勒基金会寻求资助,该基金会提出的的条件则是让 APE (C) X 可以与人类语言以及数学一起工作。结果是在 1955 年 11 月,进行了一场机器翻译演示。
除了为第一台机器构建硬件外,她还为 ARC2 和 SEC 机器编写了所有软件,在此过程中发明了她所谓的 “Contracted Notation”,后来被称为汇编语言。她还发表了一篇论文讨论了同步操作与异步操作,她于 1958 年出版的《Programming for an Automatic Digital Calculator》一书可能是第一本由女性撰写的关于编程的书。
同年,她开始研究神经网络,这也是她与儿子 Ian JM Booth 博士共同撰写并于 1993 年发表的最后一篇论文 —— 使用神经网络识别海洋哺乳动物。1960 年代初 Booth 一家搬到了加拿大,Kathleen 和 Andrew 继续在学术界工作;上世纪70年代后期,她正式退休。
FC游戏主要使用汇编语言编写
FC游戏曾经是80、90一代儿时最热爱的娱乐方式之一。这些游戏包括《超级玛丽》、《马里奥兄弟》、《魂斗罗》和《洛克人》等,它们不仅给我们带来了无数小时的娱乐,也启发了对计算机科学的兴趣。那么这些经典的FC游戏是用什么语言编写的呢?

首先需要了解一下FC游戏是如何运行的。FC游戏是通过一个名为“红白机”的主机来运行的,它使用了一种名为6502的CPU芯片。6502 CPU芯片是一种8位微处理器,由MOS Technology公司在1975年推出,它非常受欢迎,因为它不仅便宜,而且性能卓越。在1983年,任天堂选择了6502作为FC主机的核心。

那么FC游戏是用什么语言编写的呢?实际上,FC游戏的开发使用了一种名为汇编语言的语言。汇编语言是一种低级语言,它使用机器码来编写程序。机器码是一种二进制代码,用于指定CPU执行的指令。由于汇编语言非常接近计算机硬件,因此它能够在低级别上精细地控制计算机,使程序执行速度更快。在汇编语言中,程序员需要使用一些专门的指令来控制CPU。这些指令包括算术操作指令、移位指令、跳转指令和逻辑操作指令等。由于每个指令都对应一个特定的机器码,因此程序员必须知道每个指令的机器码是什么,才能正确地编写程序。这使得汇编语言相对于高级语言来说更加难学习,但它也更加高效。
在FC游戏的开发中,程序员通常会使用一个名为NES汇编语言的汇编语言。NES汇编语言是专门为FC游戏开发而设计的汇编语言,它提供了一些方便的指令和宏,使得编写程序更加容易。此外还提供了一些基本的库,如屏幕输出库、输入库和音频库等,使得程序员可以更加方便地编写程序。

虽然汇编语言相对于高级语言来说更难学习,但是在FC主机的硬件环境下,它是最适合的编程语言。FC主机只有2K的RAM(随机访问存储器)和40K的ROM(只读存储器),这意味着程序员必须非常小心地控制内存使用,以避免溢出或浪费。使用汇编语言编写程序,程序员可以更加精细地控制计算机硬件,使得程序可以运行得更快,并且在极限的内存限制下,仍然能够保持高效。