高级编程语言-Julia
 Julia是一个始发于2009年且具有高性能动态高级编程语言,最初是为了满足高性能数值分析和计算科学的需要而设计的,不需要解释器,速度快,也可用于客户端和服务器的Web用途、低级系统编程或用作规约语言。语法和其他编程语言类似,易于其他语言用户学习的通用高性能语言,在科学计算和数值分析中较为流行。其拥有丰富的函数库,提供了数字精度、精致的增幅器(sophisticated amplifier)和分布式并行运行方式。核心函数库等大多数库是由Julia编写,但也可以使用成熟的C和FORTRAN库来处理线性代数、随机数产生和字符串处理等问题。Julia语言可定义函数并且根据用户自定义的参数类型组合再进行重载,核心模块采用MIT协议授权。
Julia是一个始发于2009年且具有高性能动态高级编程语言,最初是为了满足高性能数值分析和计算科学的需要而设计的,不需要解释器,速度快,也可用于客户端和服务器的Web用途、低级系统编程或用作规约语言。语法和其他编程语言类似,易于其他语言用户学习的通用高性能语言,在科学计算和数值分析中较为流行。其拥有丰富的函数库,提供了数字精度、精致的增幅器(sophisticated amplifier)和分布式并行运行方式。核心函数库等大多数库是由Julia编写,但也可以使用成熟的C和FORTRAN库来处理线性代数、随机数产生和字符串处理等问题。Julia语言可定义函数并且根据用户自定义的参数类型组合再进行重载,核心模块采用MIT协议授权。Julia is a high-level, high-performance dynamic programming language for technical computing, with syntax that is familiar to users of other technical computing environments. It provides a sophisticated compiler, distributed parallel execution, numerical accuracy, and an extensive mathematical function library. The library, largely written in Julia itself, also integrates mature, best-of-breed C and Fortran libraries for linear algebra, random number generation, signal processing, and string processing. In addition, the Julia developer community is contributing a number of external packages through Julia’s built-in package manager at a rapid pace. IJulia, a collaboration between the IPython and Julia communities, provides a powerful browser-based graphical notebook interface to Julia.
Julia设计的独特之处包括,参数多态的类型系统,完全动态语言中的类型,以及它多分派的核心编程范型。它允许并发、并行和分布式计算,并直接调用C和Fortran库而不使用粘合代码。它还拥有垃圾回收机制,使用及早求值,包含了用于浮点计算、线性代数、随机数生成和正则表达式匹配的高效库。有许多库可以使用,其中一些(如用于快速傅里叶变换的库)已经预先捆绑在Julia里。
它由一群拥有各种语言丰富编程经验的Matlab高级用户,对现有的科学计算编程工具感到不满——这些软件对自己专长的领域表现得非常棒,但在其它领域却非常糟糕。他们想要的是一个开源的软件,它要像C语言一般快速而又拥有如同Ruby的动态性;要具有Lisp般真正的同像性而又有Matlab般熟悉的数学记号;要像Python般通用、像R般在统计分析上得心应手、像Perl般自然地处理字符串、像Matlab般具有强大的线性代数运算能力、像shell般胶水语言的能力,易于学习而又不让真正的黑客感到无聊;还有,它应该是交互式的,同时又是编译型的。
特点
核心语言非常小。标准库用的是Julia语言本身写的
调用许多其它成熟的高性能基础代码。如线性代数、随机数生成、快速傅里叶变换、字符串处理
丰富的用于建立或描述对象的类型语法
高性能,接近于静态编译型语言。包括用户自定义类型等
为并行计算和分布式计算而设计
轻量级协程与优雅的可扩展的类型转换/提升
支持Unicode,包括但不限于UTF-8
可直接调用C函数(不需要包装或是借助特殊的API)
有类似Shell的进程管理能力
有类似Lisp的宏以及其它元编程工具
可与Jupyter notebook 一起使用
JIT高性能编译器
Julia使用的JIT(Just-in-Time)实时编译器很有效地提高了它的运行效率,在某些地方甚至能比得上C和C++。
下面通过标准测试程序来测试下它的效率,你可以自己比较下各语言的运行效率。
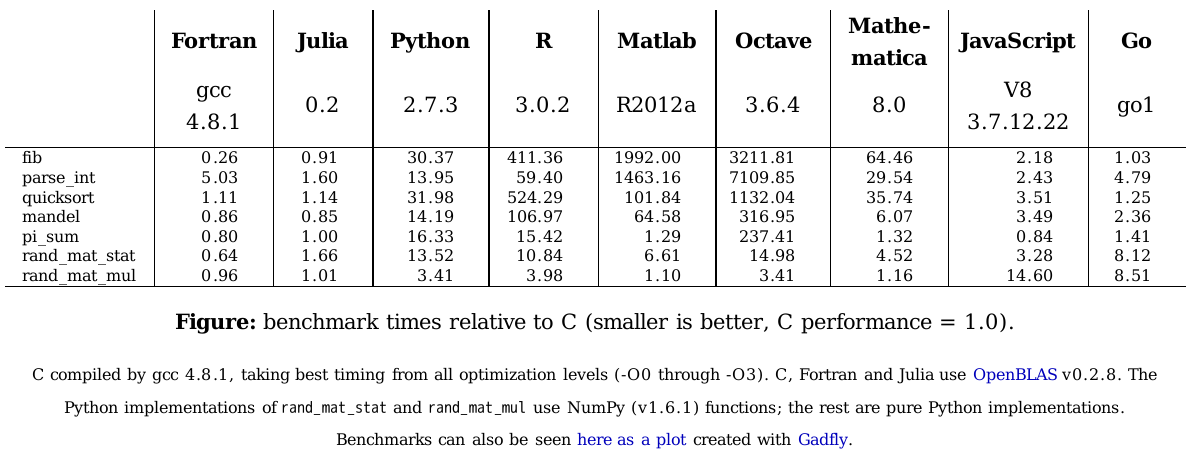
注:运行环境是MacBook Pro,2.53GHz,Intel Core2 Duo CPU和8G 1066MHz,DDR3内存。
上表中只有C++运行时间是绝对时间,其它都是相对于C++的相对时间,数值越小代表用时越少。除少数几项测试Julia惜败于Matlab和JavaScript外,Julia完胜其他高级语言,甚至在pi summation上,成功以25%的优势击败C++。通过使用Intel核心数学库(MKL),MatLabs在矩阵乘法运算中稍占便宜,但是拥有MKL授权的Julia同样可以使用Intel MKL库,不过默认的开源BLAS库性能也不错。
这个测试表是通过编译器性能对一系列常用代码模式进行分析而得出的。比如:字符串解析、函数调用/回调、排序和数值循环、生成随机数和数组运算等。
Julia克服了高级语言一直难以逾越的难关:标量算数循环(在pi summation上就能体现出来。)。Matlab的浮点运算JIT和 V8 JS引擎对此也处理得很好。但JS不支持LAPACK等线性代数库导致了在矩阵运算中的低性能,而Julia有比较多的方法消除负载(overhead),使得它可以轻松支持任何函数库。
矩阵统计的Julia代码虽然性能上比不上C++但却要简洁得多。然而,规范和编制太过随意可能会在将来成为一个问题。
为并行处理和云计算而生
Julia为分布式计算提供很多关键模块,使得它可以更加灵活地支持多种并行处理。虽然还是早期版本,Julia已经支持了云计算。
Julia将提供更加完整的性能支持云计算操作,比如分享和编辑,包括数据管理、数据挖掘和可视化操作等。它还允许用户操作大数据类型而不用关心数据操作行为。
免费、开源和Library Friendly
TJulia的核心代码遵循MIT协议,而其他库各自遵循GPL/LGPL/BSD等协议。用户还可以方便地将Julia作为核心功能共享库与C/FORTRAN代码联合使用。
最新版本:1.1
此版本带来的新特性包括:
维护一个异常堆栈 exception stack,作用于每一个任务,以使异常处理更加健壮,并且可以分析根本原因。可以使用实验性函数 Base.catch_stack 访问堆栈。
实验性的宏 Base.@locals 返回当前局部变量名称和值的字典。
二进制 ~ 现在可以使用 . 引用,如 x.~y。
完整更新信息查看发行公告。
最新版本:1.6
Julia 1.6.0 已于2021年3月下旬发布。官方表示,这很可能会成为下一个长期支持(LTS)版本。因此其花了很多时间来开发这个版本,以确保那些对生态系统未来健康发展所需的功能能够被纳入到这个版本中。此外,开发团队还针对所有已注册的开源软件包对该版本进行了回归测试,并对问题进行了跟踪和修正。关于 Julia 1.6 是否会成为新的 LTS,最终的决定将在经过实战测试后,也就是 1.7 版本进入稳定状态前后做出。此版本的一些更新亮点如下:
并行预编译:执行一个模块中的所有语句往往涉及到编译大量的代码,所以 Julia 创建了模块的预编译缓存来减少这个时间。在 1.6 中,这个包的预编译速度更快,并且在退出pkg>模式之前发生。
(v1.6) pkg> add DifferentialEquations
...
Precompiling project...
Progress [========================================>] 112/112
112 dependencies successfully precompiled in 72 seconds
julia> @time using DifferentialEquations
4.995477 seconds …
编译时间百分比
消除不必要的重新编译
减少编译器延迟:开发团队一直在尝试加快编译器本身的速度。此版本中没有任何重大突破,但鉴于在方法表数据结构上的工作,还是实现了一些适度的改进。
帮助优化程序包延迟的工具:Julia 1.6 与 SnoopCompile v2.2.0 或更高版本相结合,为 compiler introspection 提供了新的工具,特别是(但不限于)类型推理。开发人员可以使用新工具来分析类型推断,并确定特定的包实现选择如何与编译时间交互。早期采用者已经使用这些工具消除了从百分之几到大部分的首次使用延迟。
二进制加载加速
下载和网络选项:在 Julia 1.6 中,所有的下载都是通过新的 Download.jl 标准库用 libcurl-7.73.0 完成的。下载是在进程中完成的,TCP+TLS 连接是共享和重用的。如果服务器支持 HTTP/2,向该服务器发出的多个请求甚至可以复用到同一个 HTTPS 连接上。所有这些都意味着下载速度更快。
改进的 stacktrace 格式
更多详细内容可查看官方博客说明。
最新版本:1.9
Julia 编程语言 1.9 版本已于2023年5月中旬发布,Julia 1.9 是 1.x 系列版本中的第九个次要版本,添加了一些新特性和功能,主要更改如下:
本机代码的缓存
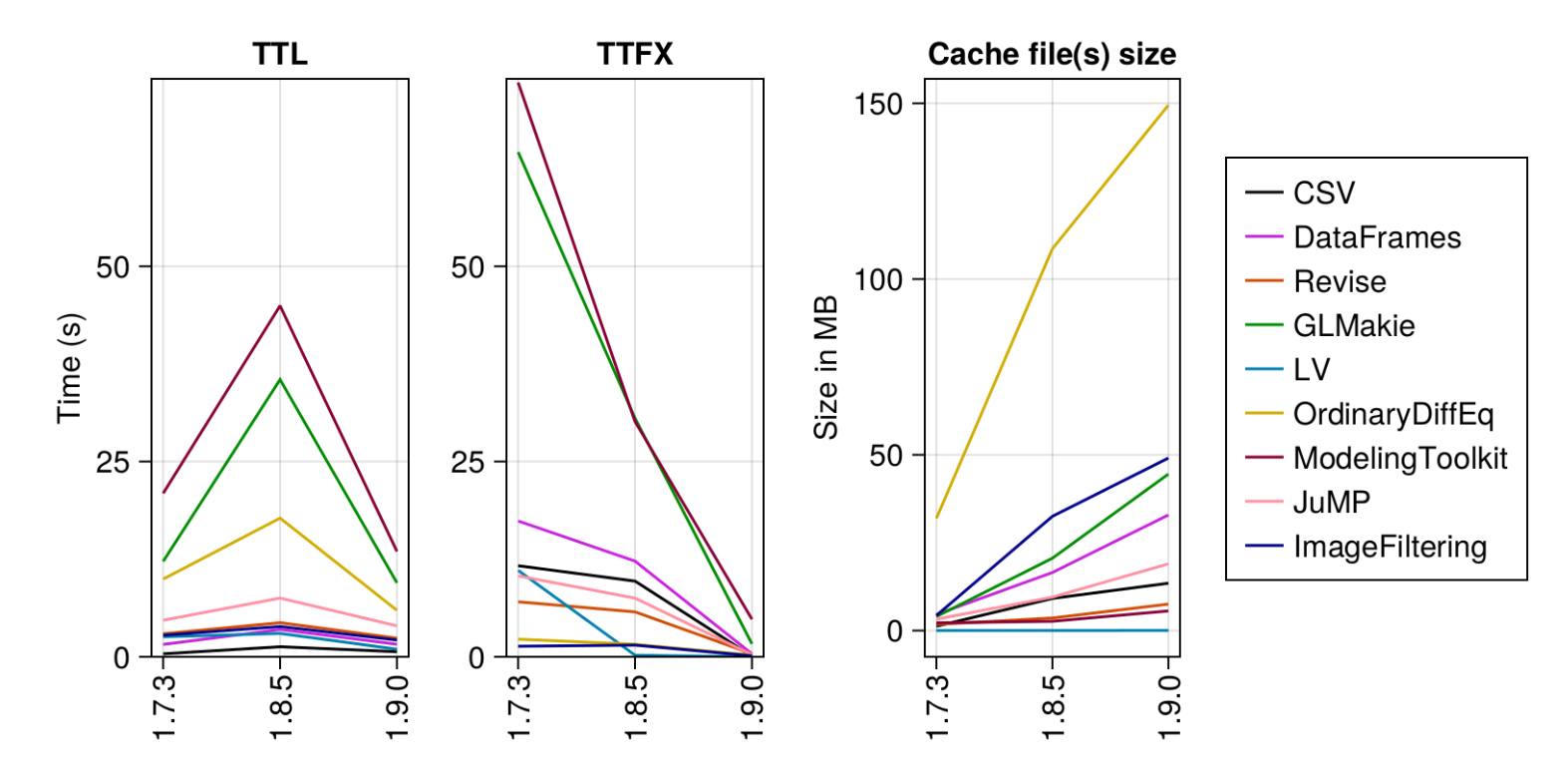
本机代码缓存现已可用,从而显着改善了 TTFX (首次执行时间 )延迟,包作者现在可以利用带有 PrecompileTools 的precompile 语句或工作负载来提前缓存重要的例程。用户还可以创建自定义本地 “启动” 包,以加载依赖项并预编译适合其日常工作的工作负载。此功能带来一些额外的负载,例如预编译时间增加 10%-50%,但这是一次性成本。由于存储更多数据和使用不同的序列化格式,缓存文件也变得更大。下图说明了从 Julia 1.7 开始加载时间 (TTL)、TTFX 和缓存文件大小的变化:
包扩展
Julia 1.9 引入了 “包扩展”,从广义上讲,这是一种在加载一组包时自动加载模块的功能。该模块包含在 ext 父包目录中的一个文件中,加载 “弱依赖” 和扩展方法。包扩展提供的功能类似于 Requires.jl 已经提供的功能,但具有关键优势,例如允许预编译条件代码,和添加弱依赖性的兼容性约束。ForwardDiff.jl 包提供了优化的示例,在 Julia 1.8 中它无条件加载 StaticArrays 包,而在 1.9 中,它使用包扩展缩短加载时间。
堆快照
现在可以生成可以使用 Chrome DevTools 检查的堆快照。要创建堆快照,只需使用 Profile 包并调用 take_heap_snapshot 函数,如下所示:
using Profile Profile.take_heap_snapshot("Snapshot.heapsnapshot")
如果对对象的数量更感兴趣,则可以使用该 all_one=true 参数。这会将每个对象的大小报告为一个,更容易识别保留的对象总数。
Profile.take_heap_snapshot("Snapshot.heapsnapshot", all_one=true)
要分析堆快照,请打开 Chromium 浏览器并按照以下步骤操作 right click -> inspect -> memory -> load:上传您的.heapsnapshot 文件,左侧将出现一个新选项卡以显示快照的详细信息。
GC 的内存使用提示 --heap-size-hint
Julia 1.9 引入了一个新的命令标志 --heap-size-hint=<size>,使用户能够设置内存使用限制,之后垃圾收集器 (GC) 将更积极地工作,以清理未使用的内存。通过指定内存限制,用户可以确保垃圾收集器更主动地管理内存资源,降低内存耗尽的风险。要使用这个新功能,只需运行 Julia,并在 --heap-size-hint 标志后面加上所需的内存限制:
julia --heap-size-hint=<size>
替换 <size> 为适当的值(例如,1G 或 512M)。
这一增强功能在处理内存密集型应用程序时提供更好的控制和灵活性。
排序算法性能
默认排序算法已升级为更具自适应性的排序算法,该算法始终稳定且通常具有最先进的性能,它对于简单的类型和顺序 —— BitInteger 、 IEEEFloat 和 Char 使用基数排序,它具有与输入大小相关的线性运行时间。这种效果对于 Float16 尤其明显,它在 1.8 上获得了 3x-50x 的加速。对于其他类型,默认排序算法在大多数情况下已更改为内部的 ScratchQuickSort ,它稳定且通常比 QuickSort 更快,对于内存效率至关重要的情况,可以通过指定 alg=QuickSort 来覆盖这些新的默认值。
任务和交互式线程池
在 1.9 版本之前,Julia 的任务在所有可用线程上运行,没有任何优先级区别。但在某些情况可能希望优先处理某些任务,例如运行心跳、提供交互式界面或显示进度更新。
现在可以在 Threads.@spawn 时将任务指定为交互式任务:
using Base.Threads @spawn :interactive f()
可以使用以下命令设置可用的交互式线程数:
julia --threads 3,1
此命令以 3 个 “正常” 线程和一个交互式线程(在交互式线程池中)启动 Julia。
更多内容请查看更新公告。
官方主页:http://julialang.org/