Unix下的5种I/O模型
 本文是《UNIUX网络编程》关于IO模型章节的一个小记,它们分别是:
本文是《UNIUX网络编程》关于IO模型章节的一个小记,它们分别是:阻塞IO
非阻塞IO
IO复用(select和poll)
信号驱动式IO(SIGIO)
异步IO(POSIX的aio系列函数)
阻塞I/O模型
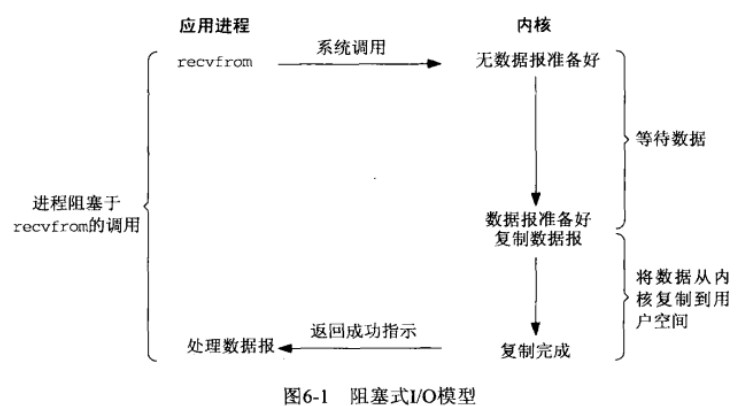
本例子中,我们吧recvfrom函数视为系统调用,为的是区分应用进程和内核,不论它是如何实现的。在上图中,进程调用recvfrom,其系统调用直到数据报到达且被复制到应用进程的缓存或者发生错误才会返回。进行在recvfrom开始到它返回的整段时间内是被阻塞的,recvfrom成功返回后,应用进程开始处理数据报。
在调用recvfrom到返回,可以分为两个过程:
内核等待数据
把数据从内核复制到用户空间。
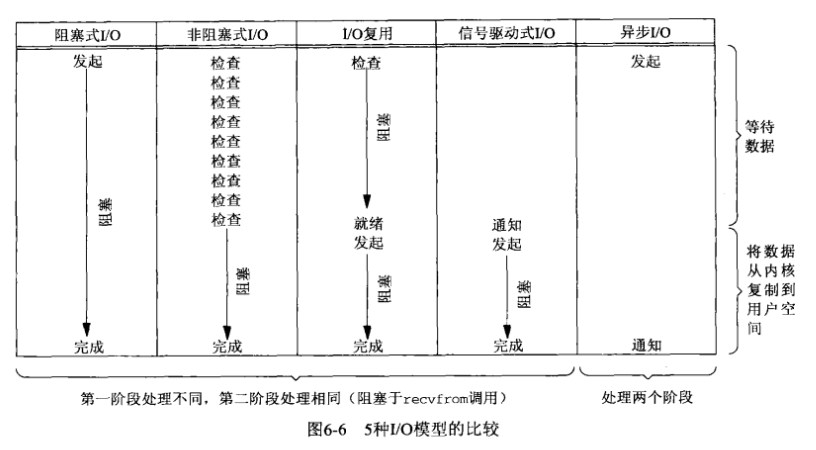
可以看到使用阻塞式IO在进行在上面两个过程中都处于等待(阻塞)当中。后面讲到的其他模型和阻塞IO的区别就在于不同的方式处理上面两个进程。
非阻塞IO
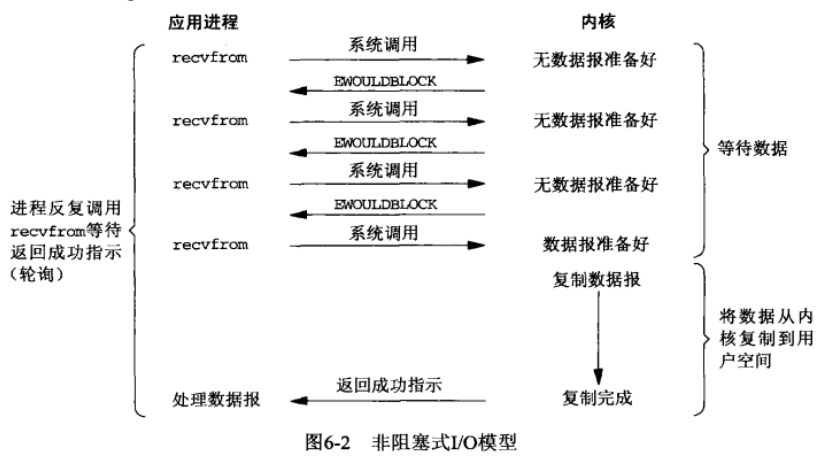
非阻塞IO和阻塞IO的最大区别在于等待数据这个过程,在阻塞IO中内核处于等待数据的过程中,进程是处于阻塞状态的。而在非阻塞IO中不会阻塞,当数据报没有准备好的时候,会直接返回一个EWOULDBLOCK错误。
应用程序像这样对一个非阻塞描述符循环调用recvfrom时,我们称之为轮询,但是持续轮询内核以查看某个操作是否就绪,往往浪费大量的cpu时间。
IO复用(select和poll)
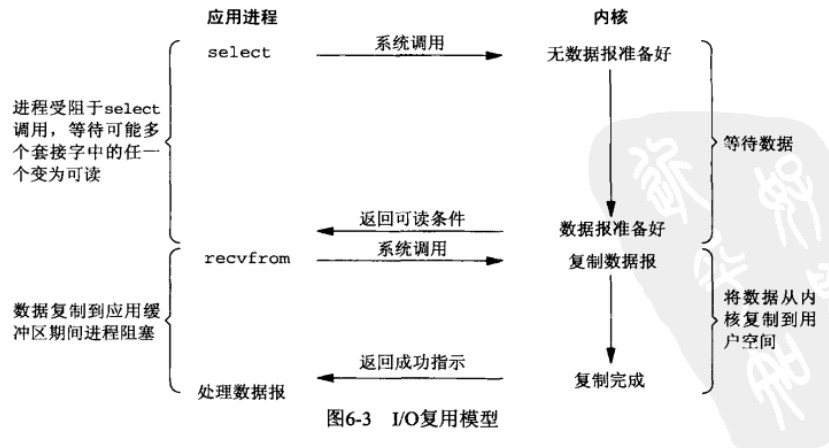
相比阻塞IO,IO复用把等待数据和复制数据到用户缓存区两个操作分开做了,需要两次系统调用。这样看来IO复用不具有什么优势,事实上select的优势在于我们可以等待多个描述符就绪。(socket数据或者是文件数据)
信号驱动式IO(SIGIO)
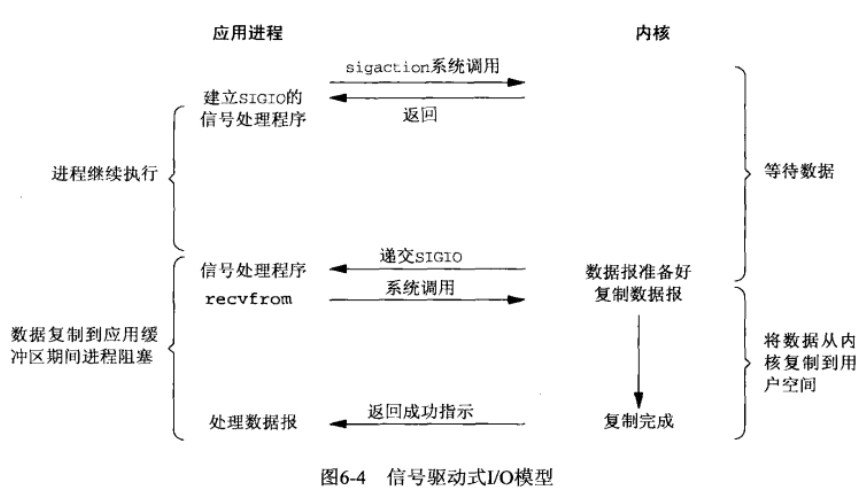
我们首先开启套接字的信号驱动式IO功能,并且通过sigaction系统调用安装一个信号处理函数,该系统调用立刻返回,我们的进行继续工作。
当数据准备好之后,内核就为该进程产生一个SIGIO信号,这个时候进程就知道数据准备好了,可以让内核进行复制数据到用户空间操作了。这个模式比起阻塞IO来说,等待数据这步不需要阻塞。
异步IO(POSIX的aio系列函数)
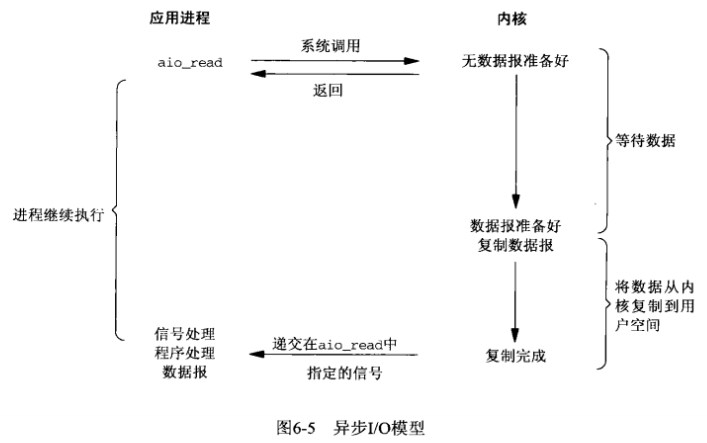
应用程序先进行一次系统调度,告诉内核需要监听的描述符,缓存区指针,缓存区大小,文件偏移,该系统调度立马返回。待内核把数据准备好,并且复制到用户空间了,再通知进程,在异步IO中,进程完全不需要阻塞。
上面看到的四种模式,在复制数据到用户空间这个过程中,进程都需要阻塞的,唯独异步IO在这个过程中,不需要阻塞。
模型对比
POSIX把两个属于定义如下:
同步IO操作:导致请求进程阻塞,直到IO操作完成。
异步IO操作:不导致请求阻塞。
可以得出结论,阻塞IO、非阻塞IO、复用IO、信号驱动式IO都为同步IO操作,异步IO模型与POSIX的异步IO操作匹配。
上文源自:互联网
再识一些IO底层原理
本节从底层讲解了下从BIO到NIO的一个过程,着重介绍了IO多路复用的几个系统调用select()、poll()、epoll(),分析了下各自的优劣,技术都是持续发展演进的;算是对上面5种I/O模型的展开。
1、IO 概念
IO是Input和Output的缩写,即输入和输出。广义上的围绕计算机的输入输出有很多:鼠标、键盘、扫描仪等等。而我们今天要探讨的是在计算机里面,主要是作用在内存、网卡、硬盘等硬件设备上的输入输出操作。
谈起IO的模型,多数人有比较模糊的概念,“阻塞”、“非阻塞”,“同步”、“异步”有什么区别?这里尝试简单地去解释下为啥会出现这种现象,其中一个很重要的原因就是大家看到的资料对概念的解释都站在了不同的角度,有的站在了底层内核的视角,有的直接在java层面或者Netty框架层面给大家介绍API,所以给大家造成了一定程度的困扰。这里将会从底层内核的层面给大家讲解下IO。因为万变不离其宗,只有了解了底层原理,不管语言层面如何花里胡哨,我们都能以不变应万变。
2、用户和内核空间
为了便于大家理解复杂的IO以及零拷贝相关的技术,还是得花点时间在回顾下操作系统相关的知识。这一节重点看下用户空间和内核空间(也称用户态或内核态),基于此后面才能更好地讲解多路复用和零拷贝。
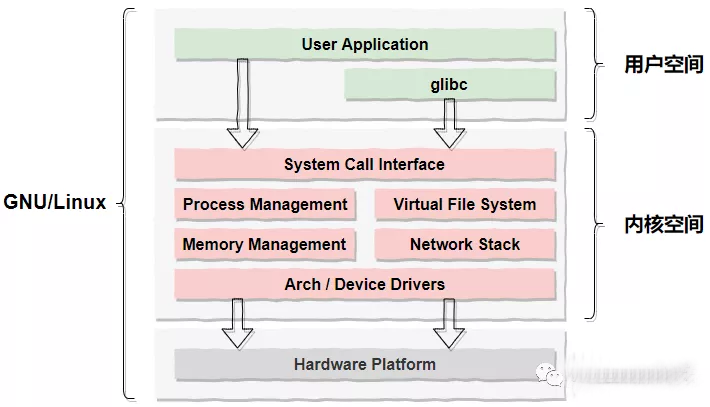
硬件层(Hardware)
包括和我们熟知的和IO相关的CPU、内存、磁盘和网卡几个硬件;
内核空间(Kernel Space)
计算机开机后首先会运行内核程序,内核程序占用的一块私有的空间就是内核空间,并且可支持访问CPU所有的指令集(ring0 - ring3)以及所有的内存空间、IO及硬件设备;
用户空间(User Space)
每个普通的用户进程都有一个单独的用户空间,用户空间只能访问受限的资源(CPU的“保护模式”)也就是说用户空间是无法直接操作像内存、网卡和磁盘等硬件的;
如上所述,那可能会有疑问,用户空间的进程想要去访问或操作磁盘和网卡该怎么办呢?
为此,操作系统在内核中开辟了一块唯一且合法的调用入口“System Call Interface”,也就是我们常说的系统调用,系统调用为上层用户提供了一组能够操作底层硬件的API。这样一来,用户进程就可以通过系统调用访问到操作系统内核,进而就能够间接地完成对底层硬件的操作。这个访问的过程也即用户态到内核态的切换。常见的系统调用有很多,比如:内存映射mmap()、文件操作类的open()、IO读写read()、write()等等。
3、IO模型
3.1、 BIO(Blocking IO)
先看一下大家都熟悉的BIO模型:
创建ServerSocket,并监听8080端口;
主线程进入死循环,用来阻塞监听客户端的连接,socket.accept();
数据读取,socket.read();
写入数据,socket.write();
问题
以上三个步骤:accept(...)、read(...)、write(...)都会造成线程阻塞。上述这个代码使用了单线程,会导致主线程会直接夯死在阻塞的地方。
优化
我们要知道一点“进程的阻塞是不会消耗CPU资源的”,所以在多核的环境下,我们可以创建多线程,把接收到的请求抛给多线程去处理,这样就有效地利用了计算机的多核资源。甚至为了避免创建大量的线程处理请求,我们还可以进一步做优化,创建一个线程池,利用池化技术,对暂时处理不了的请求做一个缓冲。
3.2、著名的“C10K”问题
“C10K”即“client more than 10k”用来指代数量庞大的客户端;
BIO看上去非常的简单,事实上采用“BIO+线程池”来处理少量的并发请求还是比较合适的,也是最优的。但是面临数量庞大的客户端和请求,这时候使用多线程的弊端就逐渐凸显出来了:
严重依赖线程,线程还是比较耗系统资源的(一个线程大约占用1M的空间);
频繁地创建和销毁代价很大,因为涉及到复杂的系统调用;
线程间上下文切换的成本很高,因为发生线程切换前,需要保留上一个任务的状态,以便切回来的时候,可以再次加载这个任务的状态。如果线程数量庞大,会造成线程做上下文切换的时间甚至大于线程执行的时间,CPU负载变高。
3.3、NIO非阻塞模型
下面开始真正走向Java NIO或者Netty框架所描述的“非阻塞”,NIO叫Non-Blocking IO或者New IO,由于BIO可能会引入的大量线程,所以可以简单地理解NIO处理问题的方式是通过单线程或者少量线程达到处理大量客户端请求的目的。为了达成这个目的,首先要做的就是把阻塞的过程非阻塞化。要想做到非阻塞,那必须得要有内核的支持,同时需要对用户空间的进程暴露系统调用函数。所以,这里的“非阻塞”可以理解成系统调用API级别的,而真正底层的IO操作都是阻塞的,我们后面会慢慢介绍。
事实上,内核已经对“非阻塞”做好了支持,举个我们刚刚说的的accept()方法阻塞的例子(Tips:java中的accept方法对应的系统调用函数也叫accept),看下官方文档对其非阻塞部分的描述。
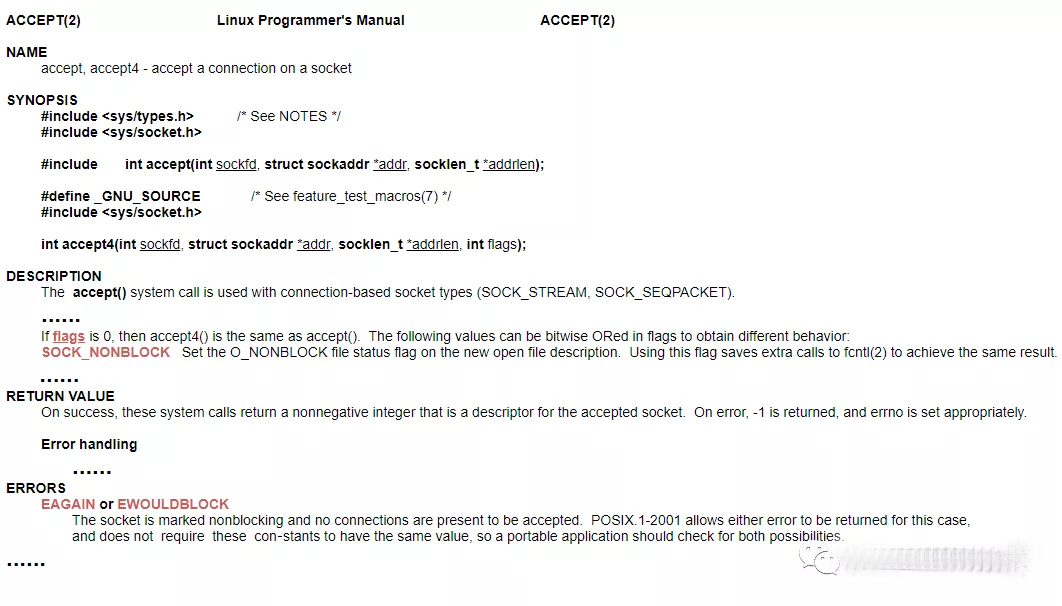
官方文档对accetp()系统调用的描述是通过把"flags"参数设成"SOCK_NONBLOCK"就可以达到非阻塞的目的,非阻塞之后线程会一直处理轮询调用,这时候可以通过每次返回特殊的异常码“EAGAIN”或"EWOULDBLOCK"告诉主程序还没有连接到达可以继续轮询。
我们可以很容易想象程序非阻塞之后的一个大致过程。所以非阻塞模式有个最大的特点就是:用户进程需要不断去主动询问内核数据准备好了没有!
下面我们通过一段伪代码,看下这个调用过程:
// 循环遍历
while(1) {
// 遍历fd集合
for (fdx in range(fd1, fdn)) {
// 如果fdx有数据
if (null != fdx.data) {
// 进行读取和处理
read(fdx)&handle(fdx);
}
}
}
这种调用方式也暴露出非阻塞模式的最大的弊端,就是需要让用户进程不断切换到内核态,对连接状态或读写数据做轮询。有没有一种方式来简化用户空间for循环轮询的过程呢?那就是我们下面要重点介绍的IO多路复用模型。
4、IO多路复用模型
非阻塞模型会让用户进程一直轮询调用系统函数,频繁地做内核态切换。想要做优化其实也比较简单,我们假想个业务场景,A业务系统会调用B的基础服务查询单个用户的信息。随着业务的发展,A的逻辑变复杂了,需要查100个用户的信息。很明显,A希望B提供一个批量查询的接口,用集合作为入参,一次性把数据传递过去就省去了频繁的系统间调用。
多路复用实际也差不多就是这个实现思路,只不过入参这个“集合”需要你注册/填写感兴趣的事件,读fd、写fd或者连接状态的fd等,然后交给内核帮你进行处理。
那我们就具体来看看多路复用里面大家都可能听过的几个系统调用 - select()、poll()、epoll()。
4.1 select()
select() 构造函数信息如下所示:
/**
* select()系统调用
*
* 参数列表:
* nfds - 值为最大的文件描述符+1
* *readfds - 用户检查可读性
* *writefds - 用户检查可写性
* *exceptfds - 用于检查外带数据
* *timeout - 超时时间的结构体指针
*/
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
官方文档对select()的描述:
DESCRIPTION
select() and pselect() allow a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become "ready" for some class of I/O operation (e.g.,input possible). A file descriptor is considered ready if it is possible to perform the corresponding I/O operation (e.g., read(2)) without blocking.
select()允许程序监控多个fd,阻塞等待直到一个或多个fd到达"就绪"状态。
内核使用select()为用户进程提供了类似批量的接口,函数本身也会一直阻塞直到有fd为就绪状态返回。下面我们来具体看下select()函数实现,以便我们更好地分析它有哪些优缺点。在select()函数的构造器里,我们很容易看到"fd_set"这个入参类型。它是用位图算法bitmap实现的,使用了一个大小固定的数组(fd_set设置了FD_SETSIZE固定长度为1024),数组中的每个元素都是0和1这样的二进制byte,0,1映射fd对应位置上是否有读写事件,举例:如果fd == 5,那么fd_set = 000001000。
同时 fd_set 定义了四个宏来处理bitmap:
FD_ZERO(&set); // 初始化,清空的作用,使集合中不含任何fd
FD_SET(fd, &set); // 将fd加入set集合,给某个位置赋值的操作
FD_CLR(fd, &set); // 将fd从set集合中清除,去掉某个位置的值
FD_ISSET(fd, &set); // 校验某位置的fd是否在集合中
使用bitmap算法的好处非常明显,运算效率高,占用内存少(使用了一个byte,8bit)。我们用伪代码和图片来描述下用户进程调用select()的过程:
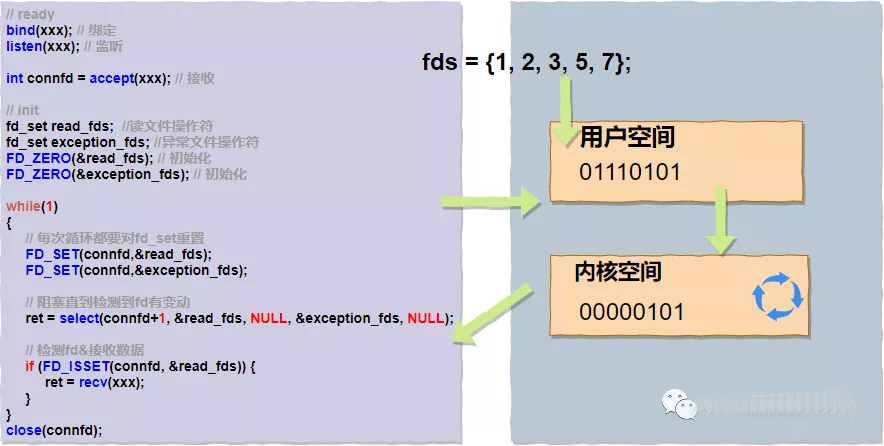
假设fds为{1,2,3,5,7}对应的bitmap为"01110101",抛给内核空间轮询,当有读写事件时重新标记同时停止阻塞,然后整体返回用户空间。由此我们可以看到select()系统调用的弊端也是比较明显的:
复杂度O(n),轮询的任务交给了内核来做,复杂度并没有变化,数据取出后也需要轮询哪个fd上发生了变动;
用户态还是需要不断切换到内核态,直到所有的fds数据读取结束,整体开销依然很大;
fd_set有大小的限制,目前被硬编码成了1024;
fd_set不可重用,每次操作完都必须重置;
4.2 poll()
poll() 构造函数信息如下所示:
/**
* poll()系统调用
*
* 参数列表:
* *fds - pollfd结构体
* nfds - 要监视的描述符的数量
* timeout - 等待时间
*/
int poll(struct pollfd *fds, nfds_t nfds, int *timeout);
### pollfd的结构体
struct pollfd{
int fd;// 文件描述符
short event;// 请求的事件
short revent;// 返回的事件
}
官方文档对poll()的描述:
DESCRIPTION
poll() performs a similar task to select(2): it waits for one of a set of file descriptors to become ready to perform I/O.
poll() 非常像select(),它也是阻塞等待直到一个或多个fd到达"就绪"状态。
看官方文档描述可以知道,poll()和select()是非常相似的,唯一的区别在于poll()摒弃掉了位图算法,使用自定义的结构体pollfd,在pollfd内部封装了fd,并通过event变量注册感兴趣的可读可写事件(POLLIN、POLLOUT),最后把 pollfd 交给内核。当有读写事件触发的时候,我们可以通过轮询 pollfd,判断revent确定该fd是否发生了可读可写事件。
老样子我们用伪代码来描述下用户进程调用 poll() 的过程:
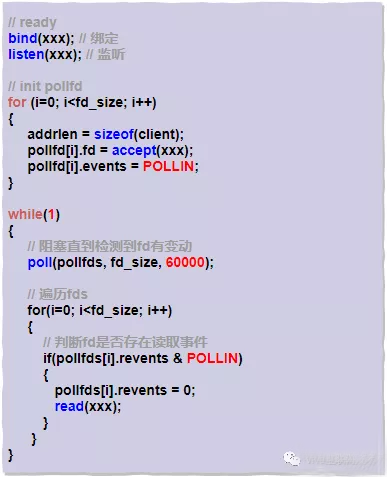
poll() 相对于select(),主要的优势是使用了pollfd的结构体:
没有了bitmap大小1024的限制;
通过结构体中的revents置位;
但是用户态到内核态切换及O(n)复杂度的问题依旧存在。
4.3 epoll()
epoll()应该是目前最主流,使用范围最广的一组多路复用的函数调用,像我们熟知的Nginx、Redis都广泛地使用了此种模式。接下来我们重点分析下,epoll()的实现采用了“三步走”策略,它们分别是epoll_create()、epoll_ctl()、epoll_wait()。
4.3.1 epoll_create()
/**
* 返回专用的文件描述符
*/
int epoll_create(int size);
用户进程通过 epoll_create() 函数在内核空间里面创建了一块空间(为了便于理解,可以想象成创建了一块白板),并返回了描述此空间的fd。
4.3.2 epoll_ctl()
/**
* epoll_ctl()系统调用
*
* 参数列表:
* epfd - 由epoll_create()返回的epoll专用的文件描述符
* op - 要进行的操作例如注册事件,可能的取值:注册-EPOLL_CTL_ADD、修改-EPOLL_CTL_MOD、删除-EPOLL_CTL_DEL
* fd - 关联的文件描述符
* event - 指向epoll_event的指针
*/
int epoll_ctl(int epfd, int op, int fd , struce epoll_event *event );
刚刚我们说通过epoll_create()可以创建一块具体的空间“白板”,那么通过epoll_ctl() 我们可以通过自定义的epoll_event结构体在这块“白板上”注册感兴趣的事件了。
注册 - EPOLL_CTL_ADD
修改 - EPOLL_CTL_MOD
删除 - EPOLL_CTL_DEL
4.3.3 epoll_wait()
/**
* epoll_wait()返回n个可读可写的fds
*
* 参数列表:
* epfd - 由epoll_create()返回的epoll专用的文件描述符
* epoll_event - 要进行的操作例如注册事件,可能的取值:注册-EPOLL_CTL_ADD、修改-EPOLL_CTL_MOD、删除-EPOLL_CTL_DEL
* maxevents - 每次能处理的事件数
* timeout - 等待I/O事件发生的超时值;-1相当于阻塞,0相当于非阻塞。一般用-1即可
*/
int epoll_wait(int epfd, struce epoll_event *event , int maxevents, int timeout);
epoll_wait() 会一直阻塞等待,直到硬盘、网卡等硬件设备数据准备完成后发起硬中断,中断CPU,CPU会立即执行数据拷贝工作,数据从磁盘缓冲传输到内核缓冲,同时将准备完成的fd放到就绪队列中供用户态进行读取。用户态阻塞停止,接收到具体数量的可读写的fds,返回用户态进行数据处理。
整体过程可以通过下面的伪代码和图示进一步了解:
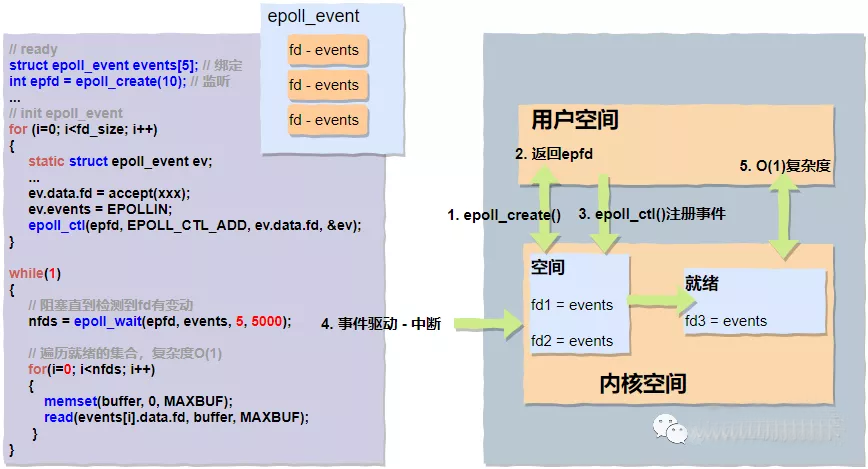
epoll() 基本上完美地解决了 poll() 函数遗留的两个问题:
没有了频繁的用户态到内核态的切换;
O(1)复杂度,返回的"nfds"是一个确定的可读写的数量,相比于之前循环n次来确认,复杂度降低了不少;
5、同步、异步
细心的朋友可能会发现,本节一直在解释“阻塞”和“非阻塞”,“同步”、“异步”的概念没有涉及,其实在很多场景下同步&异步和阻塞&非阻塞基本上是一个同义词。阻塞和非阻塞适合从系统调用API层面来看,就像我们本文介绍的select()、poll()这样的系统调用,同步和异步更适合站在应用程序的角度来看。应用程序在同步执行代码片段的时候结果不会立即返回,这时候底层IO操作不一定是阻塞的,也完全有可能是非阻塞。所以说:
阻塞和非阻塞:读写没有就绪或者读写没有完成,函数是否要一直等待还是采用轮询;
同步和异步:同步是读写由应用程序完成。异步是读写由操作系统来完成,并通过回调的机制通知应用程序。
这边顺便提两种大家可能会经常听到的模式:Reactor和Preactor。
Reactor 模式:主动模式。
Preactor 模式:被动模式。
异步IO进化史:从select到io_uring的30年
本节于2025年11月转自“讳疾忌医”的博客空间,感谢原作者。可做为对上文的时间线上的补充,引入了在AIO之后于2019年出现的io_uring的说明。
1999年,一个叫Dan Kegel的程序员在网上发了个帖子,标题叫"The C10K problem"。
C10K,意思是一台服务器能不能同时处理1万个并发连接?在那个年代,这是个看起来不可能完成的任务,不是硬件不够强,而是Linux的IO模型撑不住。拿今天的硬件来说,即使一台服务器有8核CPU、16G内存,硬件配置不差,但如果用传统的同步IO模型,只要并发连接数超过几千,系统就开始卡顿,CPU利用率却只有20%。
这就像一个车间,有8个工人,但大部分时间都在等物料,闲着没事干。
┌─────────────────────────────────┐
│ 服务器 (8核CPU, 16G内存) │
└─────────────────┬───────────────┘
│
┌──────────────────┼──────────────────┐
│ │ │
连接1 连接2 ... 连接10000
[等待] [等待] [等待]
│ │ │
└──────────CPU利用率仅20%─────────────┘
问题:CPU大部分时间在等待IO,无法处理更多连接。
问题出在哪?
问题出在同步IO。传统的read()和write(),CPU发起IO请求后就只能等着,直到数据准备好,一个连接在等CPU就被拖住了,1万个连接CPU就得在1万个等待之间来回切换,累死也忙不过来。这就是Linux异步IO进化的起点。
1990年代:select在Linux上的应用
select()最早在1983年出现在4.2BSD中。到了Linux时代(1990年代),select成了解决C10K问题的第一个尝试。其思路很简单:既然一个线程只能等一个IO,那就让一个线程同时等多个IO。哪个IO准备好了,就处理哪个。
select工作原理:
应用程序 内核
│ │
│ ① 传入fd_set(1024个) │
│ ───────────────────────>│
│ │ ② 轮询检查每个fd
│ │ [检查fd1] [检查fd2] ... [检查fd1024]
│ │
│ ③ 返回"有事件" │
│ <─────────────────────── │
│ │
│ ④ 遍历所有fd找出就绪的 │
│ [检查fd1] [检查fd2] ... [检查fd1024]
│ │
└─────────────────────────┘
问题:需要遍历1024次 × 2(内核1次 + 应用1次)
典型用法是这样的:
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(socket1, &readfds);
FD_SET(socket2, &readfds);
// ... 添加更多socket
int ret = select(max_fd + 1, &readfds, NULL, NULL, NULL);
if (ret > 0) {
// 遍历所有fd,检查哪些准备好了
for (int i = 0; i < max_fd; i++) {
if (FD_ISSET(i, &readfds)) {
// 这个fd准备好了,可以read()了
read(i, buf, sizeof(buf));
}
}
}
看起来不错?确实比一个线程只等一个IO强多了。但select有两个致命问题。
第一个问题:只能监听1024个文件描述符。这是硬编码在内核里的,FD_SETSIZE就是1024。想监听1万个连接?对不起,做不到。
第二个问题:需要遍历所有fd。select()返回后,你不知道是哪个fd准备好了,只能从头到尾遍历一遍用FD_ISSET()挨个检查,监听1000个fd每次都要检查1000遍,这效率跟暴力轮询有什么区别?而且每次调用select()都要把fd_set从用户空间拷贝到内核空间再拷贝回来,1000个fd每次都要拷贝两次。
所以select虽然解决了"一个线程等多个IO"的问题,但性能瓶颈很明显:fd数量上不去,遍历开销下不来。
C10K问题还是没解决。
1997年:poll的小步改进
1997年Linux引入了poll()系统调用,算是对select的一次小升级。
poll的API长这样:
struct pollfd fds[1000];
fds[0].fd = socket1;
fds[0].events = POLLIN;
fds[1].fd = socket2;
fds[1].events = POLLIN;
// ...
int ret = poll(fds, 1000, -1);
if (ret > 0) {
for (int i = 0; i < 1000; i++) {
if (fds[i].revents & POLLIN) {
read(fds[i].fd, buf, sizeof(buf));
}
}
}
poll改进了什么?
select vs poll 对比:
┌────────────────┬──────────────────┬──────────────────┐
│ │ select │ poll │
├────────────────┼──────────────────┼──────────────────┤
│ 最大fd数量 │ 1024 (硬限制) │ 无限制 │
├────────────────┼──────────────────┼──────────────────┤
│ 数据结构 │ bitmap │ pollfd数组 │
├────────────────┼──────────────────┼──────────────────┤
│ 查找就绪fd │ O(n) 遍历 │ O(n) 遍历 │
├────────────────┼──────────────────┼──────────────────┤
│ 性能 │ 差 │ 差 │
└────────────────┴──────────────────┴──────────────────┘
poll的改进:突破1024限制
poll的遗留问题:还是要遍历所有fd
突破了1024的限制。poll用数组存储fd,理论上可以监听任意多个。只要内存够,监听1万个、10万个都行。
但是!
poll还是要遍历所有fd。返回后还是要从头到尾检查一遍revents看哪个fd有事件,监听1万个fd每次都要遍历1万次,而且每次调用poll()还是要把整个pollfd数组从用户空间拷贝到内核、处理完再拷贝回来,1万个fd每次拷贝的数据量就是1万个pollfd结构体。
所以poll只解决了"监听fd数量"的问题,但"遍历开销"和"拷贝开销"的问题还是没解决。并发连接数从1000提升到5000,勉强能用。但要到1万?还是卡。
2002年:epoll横空出世
2002年Linux 2.5.44引入了epoll,这是一次真正的革命。
epoll的核心思想是:事件驱动。
select和poll都是"轮询模型":你问内核"有哪些fd准备好了",内核告诉你"有",然后你自己遍历去找,而epoll是"事件模型":你告诉内核"帮我盯着这些fd",内核主动告诉你"fd 123准备好了"。
这个区别看起来不大,但性能差了天和地。epoll事件驱动架构:
内核空间
┌──────────────────────────┐
│ 红黑树 (管理所有fd) │
│ ┌───┐ │
│ ┌─>│fd1│ │
│ ┌─>│ └───┘ │
│ │ │ │ ┌───┐ │
│ │ └────┼─>│fd2│ │
│ │ │ └───┘ │
│ │ └───>│ │
│ │ ┌▼──┐ │
│ └───────────│fd3│ │
│ └───┘ │
└───────────┬───────────────┘
│ 事件触发 (回调)
▼
┌──────────────────────────┐
│ 就绪链表 (只含就绪fd) │
│ [fd2] -> [fd5] -> NULL │
└───────────┬───────────────┘
│
▼ epoll_wait()返回
用户空间:只遍历就绪的fd
监听10000个fd,只有10个活跃 → 只遍历10次!
epoll的三个API
epoll分三步:
第一步:创建epoll实例
int epfd = epoll_create1(0);
这会在内核里创建一个epoll实例,维护一个事件表。
第二步:注册事件
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = socket1;
epoll_ctl(epfd, EPOLL_CTL_ADD, socket1, &ev);
告诉内核:"帮我监听socket1,有数据来了就通知我。"
关键点:这一步只需要做一次。不像select和poll,每次都要把整个fd列表传给内核。
第三步:等待事件
struct epoll_event events[1000];
int n = epoll_wait(epfd, events, 1000, -1);
for (int i = 0; i < n; i++) {
int fd = events[i].data.fd;
read(fd, buf, sizeof(buf));
}
注意!epoll_wait()返回的events数组,只包含有事件的fd,不包含没事件的fd。
监听1万个fd,只有10个有数据来,epoll_wait()就只返回这10个。你只需要遍历10次,不是1万次。
这就是epoll的威力。
epoll为什么这么快?
第一,epoll用红黑树管理fd。内核维护一棵红黑树,所有被监听的fd都在树上,查找、插入、删除都是O(log n);
第二,epoll用就绪链表返回事件,当某个fd有事件时内核通过回调函数把这个fd加入到一个就绪链表里,epoll_wait()直接返回这个链表不需要遍历所有fd;
第三,不需要每次拷贝fd列表,注册事件时拷贝一次之后就不用拷贝了,epoll_wait()只返回就绪的fd数据量很小。
有人测过,监听1万个连接,select要遍历1万次,epoll只需要遍历有事件的那几个。如果只有10个连接活跃,epoll的性能是select的1000倍。
C10K问题,终于解决了。
但是!epoll还是同步IO
很多人以为epoll是异步IO。错了。epoll只是"IO多路复用",本质上还是同步IO。
为什么?
因为epoll只负责"通知"不负责"读写",epoll_wait()告诉你"socket 123有数据了"然后呢?你还得自己调用read()去读数据,这个read()是阻塞的,数据从内核缓冲区拷贝到用户空间CPU还是要等。
同步IO的定义:用户进程参与数据拷贝。异步IO的定义:内核完成数据拷贝,然后通知用户进程。
同步IO(epoll)vs 异步IO 的本质区别:
╔═══════════════════ 同步IO (epoll) ═══════════════════╗
║ ║
║ 应用程序 内核 ║
║ │ │ ║
║ │ epoll_wait() │ ║
║ │─────────────>│ ║
║ │ │ 监听事件... ║
║ │ 返回"fd就绪" │ ║
║ │<─────────────│ ║
║ │ │ ║
║ │ read(fd) │ ⚠️ 关键:应用调用read() ║
║ │─────────────>│ ║
║ │ [阻塞等待] │ 拷贝数据: 内核 → 用户空间 ║
║ │ 返回数据 │ ║
║ │<─────────────│ ║
║ │ │ ║
║ CPU还是要等待数据拷贝 ║
╚════════════════════════════════════════════════════════╝
╔═══════════════════ 异步IO (io_uring) ════════════════╗
║ ║
║ 应用程序 内核 ║
║ │ │ ║
║ │ 提交read请求 │ ║
║ │─────────────>│ ║
║ │ │ ║
║ │ 继续干别的事 │ 后台异步处理: ║
║ │ ... │ ① 读磁盘/网络 ║
║ │ ... │ ② 拷贝数据: 内核→用户空间 ║
║ │ │ ③ 放入完成队列 ║
║ │ │ ║
║ │ 检查完成队列 │ ║
║ │<─────────────│ 返回"已完成,数据在buf" ║
║ │ │ ║
║ CPU可以去做别的事,内核搞定一切 ║
╚════════════════════════════════════════════════════════╝
关键区别:谁负责数据拷贝?
- 同步IO:应用程序调用read(),CPU等待
- 异步IO:内核自己拷贝,应用程序不等待
epoll只是减少了等待的次数,但数据拷贝这一步,还是要你自己做。所以epoll是同步IO。
这也是为什么,即使用了epoll,高并发场景下CPU占用率还是很高。因为数据拷贝都是CPU在做。
真正的异步IO应该是:你告诉内核"帮我读这个文件",然后就去干别的事,内核读完了通知你"读好了,数据在这"。
epoll总共有三大系统调用:epoll_create、epoll_ctl、epoll_wait。
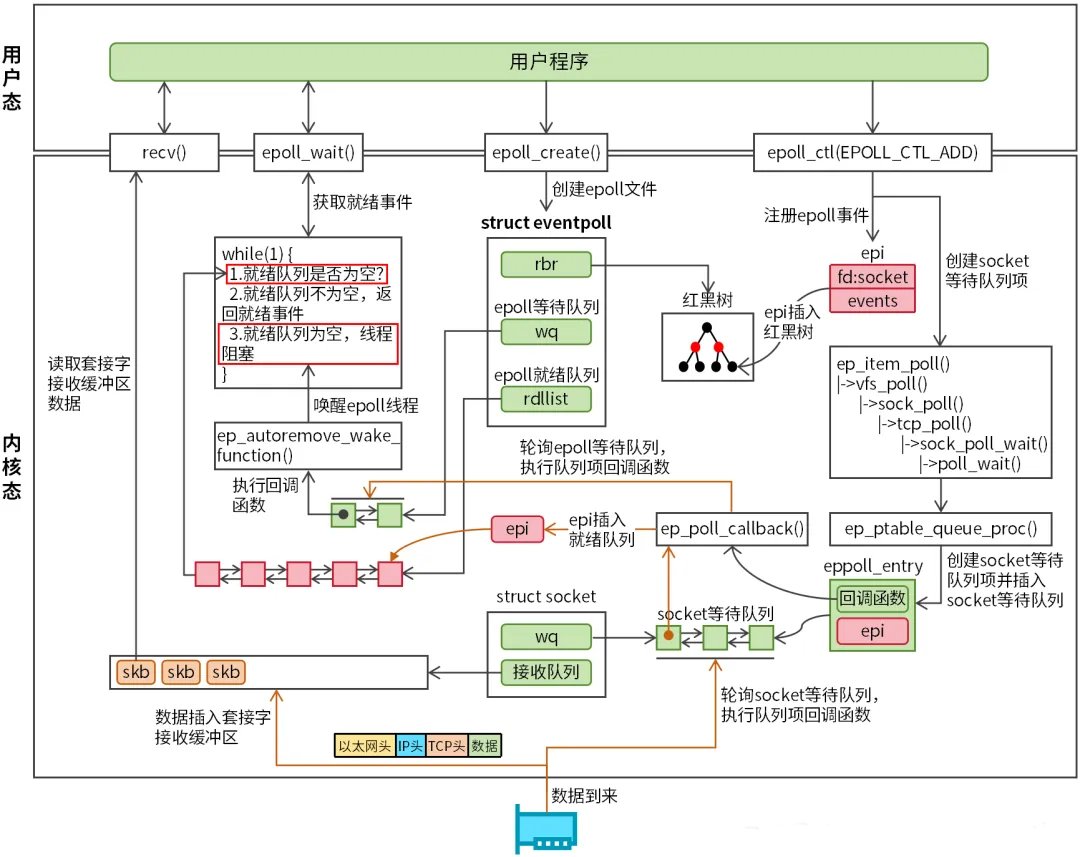
epoll_create用来在内核里创建一个eventpoll对象(epoll实例)并返回一个文件描述符(epfd),通过epfd我们能够快速访问eventpoll对象。eventpoll对象内核定义如下:
struct eventpoll {
wait_queue_head_t wq; // 等待队列
struct list_head rdllist; // 就绪队列
struct rb_root rbr; // 红黑树
......
};
eventpoll对象中有三个重要成员:
wq:等待队列,内核通过等待队列唤醒epoll线程。
rdllist:就绪队列,用于存储就绪事件。
rbr:红黑树,用于存储所有通过epoll_ctl注册的I/O事件。
epoll_ctl用于向epoll实例中添加、修改或删除需要监控的文件描述符及其事件,内核对于epoll事件的定义为struct epitem结构。
struct epitem {
union {
struct rb_node rbn; /* 红黑树节点*/
};
struct list_head rdllink; /* 就绪队列节点*/
struct epoll_filefd ffd; /* 文件描述符信息,包含fd和对应的file指针 */
int nwait;
struct eventpoll *ep; /* 指向所属的eventpoll实例 */
struct epoll_event event; /* 通过epoll_ctl设置的epoll_event事件,包含文件描述符和感兴趣的事件类型 */
......
};
epitem对象(上图中简称epi)是内核epoll事件管理的基本单元。
用户程序调用epoll_ctl函数(操作类型指定为EPOLL_CTL_ADD)时,内核会创建epitem对象,然后将用户设置的epoll事件(包含文件描述符和事件类型)复制至epitem对象,再将epitem对象插入红黑树。
epitem对象插入红黑树后,内核需要激活事件驱动机制,即当事件就绪后,主动通知epoll。具体做法是创建一个socket等待队列项(struct eppoll_entry结构),eppoll_entry的base成员指向epitem对象,同时epoll_entry中注册一个回调函数ep_poll_callback(用于通知epoll事件就绪),最后将epoll_entry插入socket等待队列。
完成epoll事件注册后,用户程序调用epoll_wait函数获取epoll就绪事件,epoll_wait负责把就绪事件从内核搬到用户程序。内核会循环检测epoll就绪队列是否为空。如果就绪队列不为空,内核会将所有就绪事件拷贝至epoll_event数组(epoll_wait函数参数);否则,epoll线程会创建一个epoll等待队列项并注册回调函数ep_autoremove_wake_function(用于唤醒epoll线程),等待队列项将插入epoll等待队列,随后内核切换epoll线程至阻塞状态。
数据到来时,数据经网卡->网络设备子系统->网络协议栈,最后存储至套接字接收缓冲区。一旦数据被套接字接收,则epoll读事件就绪。内核会轮询socket等待队列,并执行ep_poll_callback回调函数,该函数有两个作用:
1.将socket等待队列项中的epitem对象插入epoll就绪队列。
2.轮询epoll等待队列,执行ep_autoremove_wake_function回调函数,将epoll线程唤醒。
epoll线程被唤醒后,它会将epoll就绪队列中的就绪事件从内核拷贝至用户程序。用户程序检测到就绪事件后,就能够读写数据了。下面简单总结一下epoll的优缺点。
epoll的优点如下:
1.无文件描述符数量限制,非常适用于高并发场景。
2.采用事件驱动模型,不需要轮询每个文件描述符状态来获取就绪事件。
相对于epoll的优点,笔者更愿意来讨论epoll的缺点,如果我们能够准确地指出epoll的缺点,意味着我们对epoll有了非常深入的理解。
epoll的缺点为:epoll处理I/O事件时,伴随着大量的系统调用,并且epoll不能够批量地处理I/O事件。
Linux有真正的异步IO吗?
有。但很尴尬。
2006年:Linux AIO的尴尬
2006年Linux 2.6内核引入了AIO(Asynchronous I/O)。这是Linux第一次尝试真正的异步IO。
AIO的思路很清晰:应用程序提交IO请求,内核异步处理,处理完了通知应用程序。听起来完美。
它有两套API:
1. POSIX AIO(aio_read/aio_write):glibc实现,实际是用线程池模拟异步,不是真正的内核异步IO。
2. Linux Native AIO(io_submit/io_getevents):libaio库,真正的内核异步IO。
POSIX AIO的用法长这样:
struct aiocb cb;
memset(&cb, 0, sizeof(cb));
cb.aio_fildes = fd;
cb.aio_buf = buf;
cb.aio_nbytes = sizeof(buf);
cb.aio_offset = 0;
// 提交异步读请求
aio_read(&cb);
// 去干别的事...
// 检查是否完成
while (aio_error(&cb) == EINPROGRESS) {
// 还没完成,继续等
}
// 完成了,获取结果
ssize_t ret = aio_return(&cb);
看起来很美好?但无论哪套API,Linux AIO都有几个致命问题,导致它几乎没人用。
第一,只支持O_DIRECT。Linux Native AIO只支持直接IO(direct I/O),不支持缓冲IO(buffered I/O)。
什么意思?
正常情况下你调用read()内核会先检查页缓存(page cache),如果数据在缓存里就直接返回不需要读磁盘,这是缓冲IO也是Linux默认的IO方式,但Linux AIO要求你用O_DIRECT标志打开文件绕过页缓存直接读磁盘,这意味着你失去了页缓存的加速、要自己对齐内存必须是512字节的倍数否则报错、写入不走缓存可靠性下降。
第二,只支持磁盘文件,不支持网络socket。想用AIO读socket?对不起,不支持。
第三,语义复杂,易出错。如果文件被其他进程截断了,如果磁盘满了,AIO的错误处理非常麻烦。
第四,性能不稳定。某些场景下Linux AIO甚至比同步IO还慢。
所以Linux AIO成了一个"半成品",Linus本人都吐槽过:"Linux AIO是个笑话"。
大部分开源项目(Nginx、Redis)都没用Linux AIO,还是用epoll + 同步IO。真正的异步IO,Linux等了13年。
2019年:io_uring的革命
2019年Linux 5.1引入了io_uring。这一次Linux终于有了真正好用的异步IO。
io_uring的设计者是Jens Axboe,Linux块设备子系统的维护者。他设计io_uring的目标很明确:
1.真正的异步IO
2.同时支持磁盘和网络
3.性能要比epoll强
4.API要简单
他做到了。
io_uring的核心设计:ring buffer
io_uring的核心是两个ring buffer(环形缓冲区):
1.SQ (Submission Queue):提交队列。应用程序往里面放IO请求。
2.CQ (Completion Queue):完成队列。内核往里面放IO结果。
这个设计很巧妙。
传统的系统调用每次都要从用户态切换到内核态再切回来,用户态和内核态的切换开销很大,而io_uring用ring buffer共享内存,应用程序和内核都能访问这块内存不需要来回拷贝也不需要频繁切换。
io_uring的ring buffer架构:
用户空间 内核空间
│ │
│ ① 准备IO请求 │
│ SQE: {fd, buf, op} │
│ │
▼ │
┌────────────────────┐ │
│ SQ (提交队列) │◄───────────┼─── 共享内存
│ Ring Buffer │ │ (mmap映射)
│ [SQE1][SQE2][SQE3] │ │
└────────┬───────────┘ │
│ │
│ ② io_uring_submit() │
└───────────────────────>│
│
│ ③ 内核异步处理
│ - 读磁盘/网络
│ - 拷贝数据
│ - 不阻塞应用
│
▼
┌────────────────────┐
│ CQ (完成队列) │
│ Ring Buffer │
│ [CQE1][CQE2][CQE3] │
└────────┬───────────┘
│
┌────────────────────────┘
│ ④ io_uring_wait_cqe()
▼
取出完成事件
- res: 读取的字节数
- data: 用户数据
关键优势:
1.共享内存,无需拷贝
2.批量提交,减少系统调用
3.真正异步,CPU不等待
流程是这样的:
第一步:应用程序准备IO请求,放到SQ里。
struct io_uring ring;
io_uring_queue_init(256, &ring, 0);
// 获取一个SQE(Submission Queue Entry)
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
// 准备一个read请求
io_uring_prep_read(sqe, fd, buf, sizeof(buf), 0);
// 提交
io_uring_submit(&ring);
第二步:内核从SQ里取出请求,异步处理。
内核读磁盘、读网络,把数据拷贝到buf,全程不阻塞应用程序。
第三步:内核处理完,把结果放到CQ里。
第四步:应用程序从CQ里取出结果。
struct io_uring_cqe *cqe;
io_uring_wait_cqe(&ring, &cqe);
// 检查结果
if (cqe->res < 0) {
// 出错了
} else {
// 成功了,cqe->res是读取的字节数
printf("读取了 %d 字节\n", cqe->res);
}
io_uring_cqe_seen(&ring, cqe);
注意!整个过程中,数据拷贝都是内核做的,应用程序只是提交请求、获取结果。
这才是真正的异步IO。
io_uring有多快?
有人用io_uring和epoll做了对比测试(场景:网络IO,10万个并发连接,每秒100万次小数据包请求):
1.epoll + read/write:CPU占用80%,QPS 50万
2.io_uring:CPU占用50%,QPS 100万
性能翻倍,CPU占用还降了。注意,实际性能差异取决于具体的IO类型(网络/磁盘)、数据包大小、并发连接数等因素。
为什么io_uring这么快?
第一,减少了系统调用次数,epoll需要多次系统调用(epoll_ctl、epoll_wait、read/write)而io_uring只需要两次(io_uring_submit、io_uring_wait_cqe);
第二,减少了数据拷贝,ring buffer是共享内存不需要在用户空间和内核空间来回拷贝;
第三,真正的异步,数据拷贝由内核完成CPU可以去做别的事;
第四,支持高级特性,io_uring支持批量提交、链式请求、零拷贝,优化空间很大。
io_uring的最新进展(2024-2025)
截至2024年底/2025年初,io_uring持续演进,最新的内核版本(Linux 6.x系列)增加了以下特性:
1.Ring Resizing(动态调整ring大小):应用可以从小ring开始,按需增长,避免一开始就分配很大的ring浪费内存。
2.Hybrid IO Polling(混合IO轮询):结合中断和轮询,在低延迟和高吞吐之间找到平衡。
io_uring还在不断进化,已经成为Linux高性能IO的标准方案。
io_uring是异步I/O模型,它的实现原理和同步I/O模型有很大的区别。
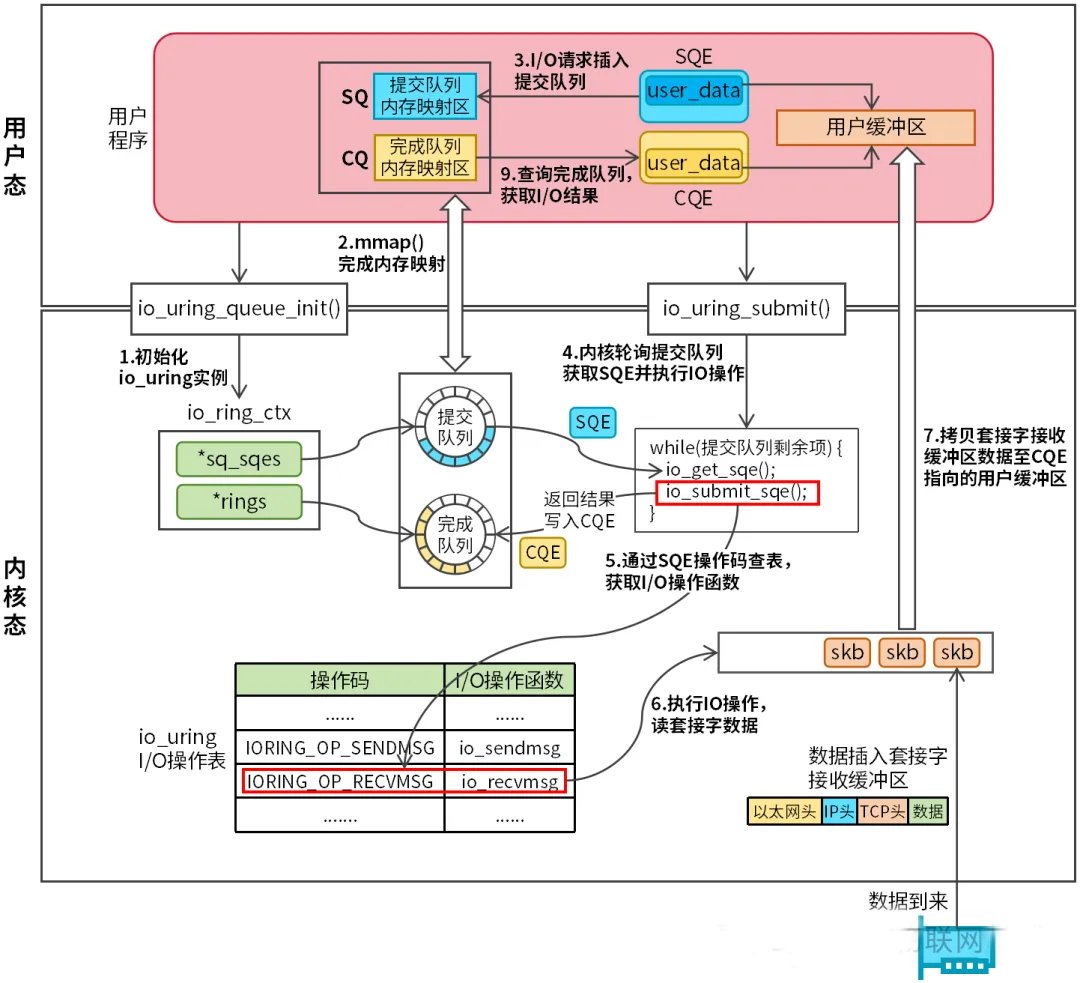
io_uring同样有三个系统调用:
io_uring_setup:用于创建和初始化io_uring实例。
io_uring_enter:负责提交I/O请求和获取完成事件。
io_uring_register:用于将文件描述符、缓冲区等资源预先注册到io_uring实例中。
上图中并没有出现这三个系统调用,实际开发中会使用liburing库,其将io_uring中的三个系统调用进行了封装,提供了更加丰富和友好的编程接口。用户程序调用io_uring_queue_init函数(内部封装了io_uring_setup系统调用),该函数将创建和初始化一个io_uring实例(struct io_ring_ctx),内核定义如下:
struct io_ring_ctx {
struct io_rings *rings; /* 指向完成队列CQ */
struct io_uring_sqe *sq_sqes; /* 指向提交队列SQ */
......
};
struct io_ring_ctx结构复杂,这里不展开讲解,需要关注两个重要成员:rings(CQ,完成队列)和sq_sqes(SQ,提交队列)。
CQ和SQ都是无锁环形队列。内核初始化io_uring实例时,会从内核直接映射区分配内存作为CQ和SQ。之所以从内核直接映射区分配内存,是为了方便用户程序执行mmap内存映射,确保用户程序和内核能够直接都能够访问这块内存区域。CQ和SQ是用户程序和内核数据传输的通道,借用这个通道,用户程序可以在不使用系统调用的情况下和内核实现数据交换。CQ和SQ采用无锁化编程,在高并发场景下,能够最大程度减少锁的开销。
内核维护了一张io_uring I/O操作表,这张表定义了io_uring所有的I/O操作,共50多种操作,定义如下:
/* 内核io_uring I/O操作表 */
conststructio_issue_def io_issue_defs[] = {
......
[IORING_OP_SENDMSG] = {
.needs_file = 1,
.unbound_nonreg_file = 1,
.pollout = 1,
.ioprio = 1,
.async_size = sizeof(struct io_async_msghdr),
.prep = io_sendmsg_prep,
.issue = io_sendmsg,
},
[IORING_OP_RECVMSG] = {
.needs_file = 1,
.unbound_nonreg_file = 1,
.pollin = 1,
.buffer_select = 1,
.ioprio = 1,
.async_size = sizeof(struct io_async_msghdr),
.prep = io_recvmsg_prep,
.issue = io_recvmsg,
},
......
}
每个I/O操作都有一个操作码,内核根据操作码查找I/O操作表,获取I/O操作函数并执行。
io_uring执行一个异步I/O操作的流程为:
步骤1:用户程序从SQ中申请一个空闲的SQE,然后设置SQE中的I/O操作码和用户数据。
步骤2:用户程序调用io_uring_submit函数(内部封装了io_uring_enter系统调用)提交SQE,内核通过I/O操作码查询I/O操作表获取I/O操作函数并执行。I/O操作成功后,内核从CQ中申请一个CQE,将返回结果存储在CQE。
步骤3:用户程序检测CQ是否为空,如果CQ不为空,用户程序从CQ中获取CQE,并解析I/O操作返回结果。
最后同样来看一下io_uring有哪些优缺点。
io_uring优点如下:
用户程序和内核共享内存:SQ/CQ通过mmap映射,避免传统read/write的多次数据拷贝。
批处理:一次提交/收割多个I/O请求,减少系统调用次数。
SQPOLL模式:内核线程(SQ线程)主动轮询SQ,进一步减少系统调用。
io_uring在设计上并没有很大的缺陷,由于io_uring是一种比较新的网络I/O模型,所以还要持续优化。
io_uring与epoll的对比测试
| 对比项目 | epoll | io_uring |
| I/O模型 | 同步 | 异步 |
| 数据复制 | 用户态与内核数据复制 | 支持用户态与态零复制 |
| 调用开销 | 每次i/o操作都需要执行系统调用 | 通过mmap内存映射与批量处理最大程序降低开销 |
| 使用场景 | 高并发网络服务 | 高并发网络服务、数据库等 |
对比总结
Linux IO模型演进时间轴 (1983-2025):
1983 1997 1999 2002 2006 2019 2024
│ │ │ │ │ │ │
│ │ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼ ▼
select poll C10K问题 epoll Linux AIO io_uring io_uring
(BSD) (Linux) (提出) (革命性) (不成熟) (完美方案) (增强)
│ │ │ │ │ │ │
1024 突破 1万个 事件 只支持 真正的 动态
限制 限制 并发 驱动 O_DIRECT 异步IO 调整
│ │ │ │ │ │ │
└───────┴─────────┼────────┴─────────┼───────────┴─────────┘
│ │
[同步IO时代] [向异步IO过渡]
关键里程碑:
• 1999: Dan Kegel提出C10K挑战
• 2002: epoll解决C10K,但仍是同步IO
• 2019: io_uring实现真正的异步IO
• 2024: io_uring成为高性能IO标准
从select到io_uring,Linux的IO模型走过了30年。
| select | poll | epoll | io_uring | |
| 引入时间 | 1990年代 | 1997年 | 2002年 | 2019年 |
| 最大连接数 | 1024 | 无限制 | 无限制 | 无限制 |
| 查找就绪fd | O(n) 遍历 | O(n) 遍历 | O(1) 事件驱动 | O(1) ring buffer |
| 数据拷贝 | 每次拷贝fd_set | 每次拷贝pollfd | 只在注册时拷贝 | 共享内存,无拷贝 |
| 同步/异步 | 同步IO | 同步IO | 同步IO | 异步IO |
| 是否阻塞 | read()阻塞 | read()阻塞 | read()阻塞 | 不阻塞,内核处理 |
| 适用场景 | 小并发(<1000) | 中并发(<5000) | 高并发(<10万) | 超高并发(>10万) |
看这张表就明白了,每代技术都在解决前一代留下的问题:
1.select和poll解决了"一个线程等多个IO"的问题,但遍历开销大。
2.epoll用事件驱动,彻底解决了遍历开销,成为高并发的标配。
3.io_uring更进一步,用异步IO + ring buffer,性能再上一个台阶。
选择哪种方案?
如果并发量小(<1000),用阻塞IO + 多线程。简单直接且够用。
如果并发量中等(1000-10000),用epoll。成熟稳定,生态完善。Redis、Nginx都用epoll。
如果追求极致性能(>10000),用io_uring。性能最强,但要求Linux 5.1+且API还在演进。
目前越来越多的项目开始迁移到io_uring:PostgreSQL、RocksDB、QEMU都在实验io_uring。
个人觉得未来几年,io_uring肯定会逐渐取代epoll,成为Linux高性能IO的新标准。
写在最后
从select到io_uring,Linux的IO模型一步步演进,每一代都在解决前一代留下的问题:
1.select:能等多个IO,但有1024限制
2.poll:突破1024,但还要遍历
3.epoll:事件驱动,不用遍历,但还是同步IO
4.io_uring:真正的异步IO,性能拉满
这就是技术演进的魅力:没有一步到位的完美方案,每一代都在已有基础上优化一点,积累30年,就是质的飞跃。
下次写高并发服务器,想想用的是哪一代IO模型?为什么用它?它解决了什么问题,又留下了什么问题?
理解了这些就理解了Linux IO的本质。下面通过对Kafka的架构解析来看看mmap的机制。
Kafka为什么快,什么是mmap
这类的问题都逃不过的一个点就是零拷贝,虽然还有一些其他的原因,但更主要的就是零拷贝。
传统IO
在开始谈零拷贝之前,首先要对传统的IO方式有一个概念。基于传统的IO方式,底层实际上通过调用read()和write()来实现。通过read()把数据从硬盘读取到内核缓冲区,再复制到用户缓冲区;然后再通过write()写入到socket缓冲区,最后写入网卡设备。
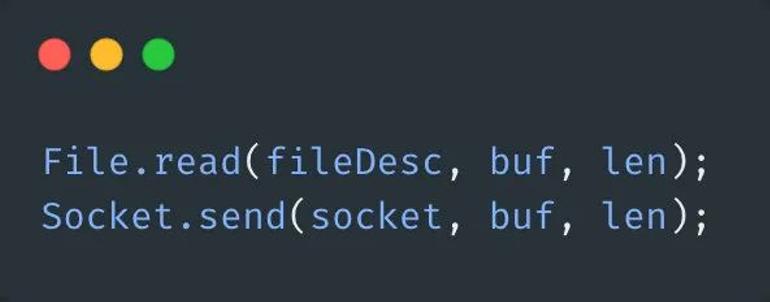
整个过程发生了4次用户态和内核态的上下文切换和4次拷贝,具体流程如下:
用户进程通过read()方法向操作系统发起调用,此时上下文从用户态转向内核态
DMA控制器把数据从硬盘中拷贝到读缓冲区
CPU把读缓冲区数据拷贝到应用缓冲区,上下文从内核态转为用户态,read()返回
用户进程通过write()方法发起调用,上下文从用户态转为内核态
CPU将应用缓冲区中数据拷贝到socket缓冲区
DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,write()返回
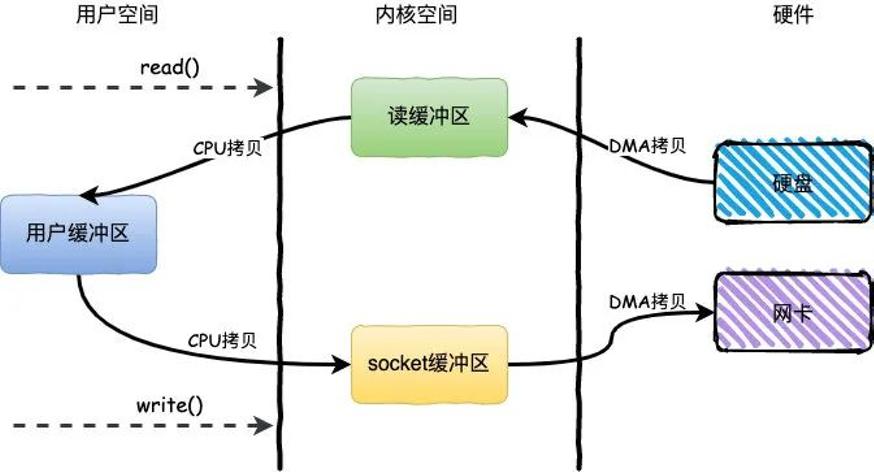
那么这里指的用户态、内核态指的是什么?上下文切换又是什么?
简单来说,用户空间指的就是用户进程的运行空间,内核空间就是内核的运行空间。如果进程运行在内核空间就是内核态,运行在用户空间就是用户态。
为了安全起见,它们之间是互相隔离的,而在用户态和内核态之间的上下文切换也是比较耗时的。从上面可以看到,一次简单的IO过程产生了4次上下文切换,这个无疑在高并发场景下会对性能产生较大的影响。
那么什么又是DMA拷贝呢?
因为对于一个IO操作而言,都是通过CPU发出对应的指令来完成,但是相比CPU来说,IO的速度太慢了,CPU有大量的时间处于等待IO的状态。
因此就产生了DMA(Direct Memory Access)直接内存访问技术,本质上来说他就是一块主板上独立的芯片,通过它来进行内存和IO设备的数据传输,从而减少CPU的等待时间。
但是无论谁来拷贝,频繁的拷贝耗时也是对性能的影响。
零拷贝
零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域,这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
那么对于零拷贝而言,并非真的是完全没有数据拷贝的过程,只不过是减少用户态和内核态的切换次数以及CPU拷贝的次数。这里仅仅有针对性的来谈谈几种常见的零拷贝技术。
mmap+write
mmap+write简单来说就是使用mmap替换了read+write中的read操作,减少了一次CPU的拷贝。
mmap主要实现方式是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
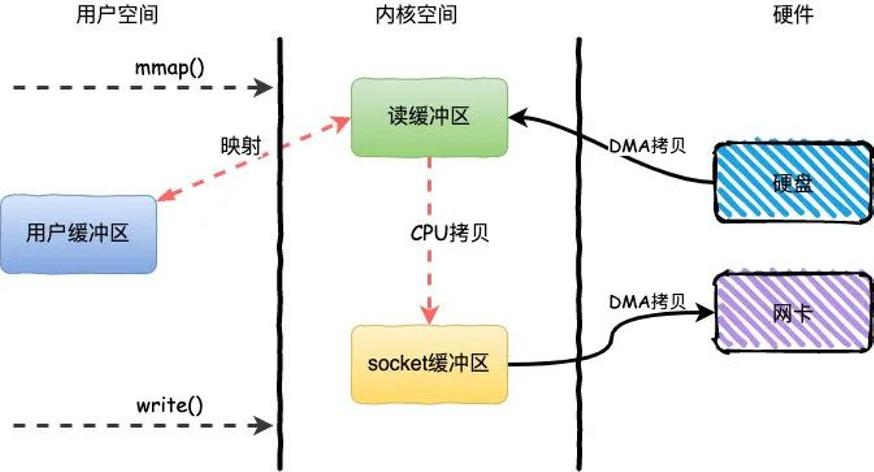
整个过程发生了4次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
用户进程通过mmap()方法向操作系统发起调用,上下文从用户态转向内核态
DMA控制器把数据从硬盘中拷贝到读缓冲区
上下文从内核态转为用户态,mmap调用返回
用户进程通过write()方法发起调用,上下文从用户态转为内核态
CPU将读缓冲区中数据拷贝到socket缓冲区
DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,write()返回
mmap的方式节省了一次CPU拷贝,同时由于用户进程中的内存是虚拟的,只是映射到内核的读缓冲区,所以可以节省一半的内存空间,比较适合大文件的传输。
sendfile
相比mmap来说,sendfile同样减少了一次CPU拷贝,而且还减少了2次上下文切换。
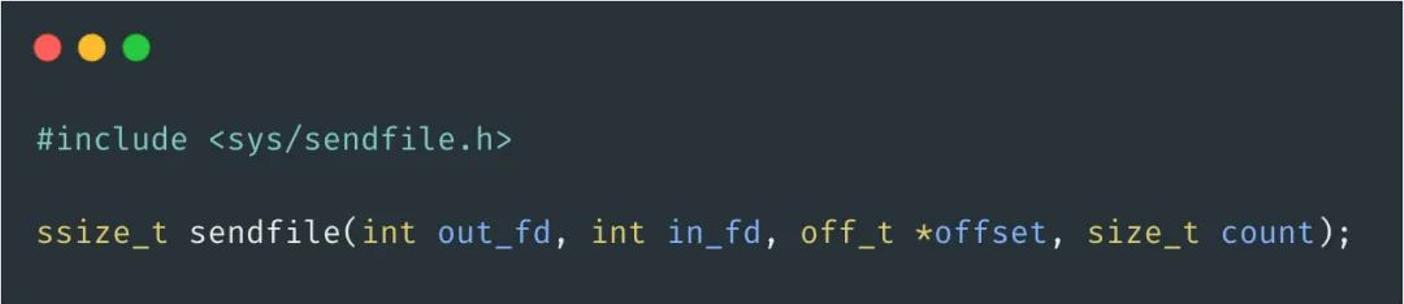
sendfile是Linux 2.1内核版本后引入的一个系统调用函数,通过使用sendfile数据可以直接在内核空间进行传输,因此避免了用户空间和内核空间的拷贝,同时由于使用sendfile替代了read+write从而节省了一次系统调用,也就是2次上下文切换。
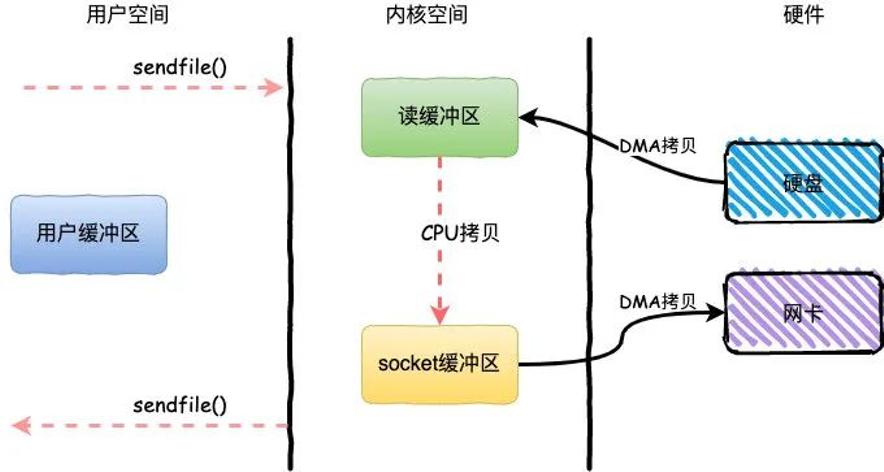
整个过程发生了2次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
用户进程通过sendfile()方法向操作系统发起调用,上下文从用户态转向内核态
DMA控制器把数据从硬盘中拷贝到读缓冲区
CPU将读缓冲区中数据拷贝到socket缓冲区
DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,sendfile调用返回
sendfile方法IO数据对用户空间完全不可见,所以只能适用于完全不需要用户空间处理的情况,比如静态文件服务器。
sendfile+DMA Scatter/Gather
Linux2.4内核版本之后对sendfile做了进一步优化,通过引入新的硬件支持,这个方式叫做DMA Scatter/Gather 分散/收集功能。
它将读缓冲区中的数据描述信息--内存地址和偏移量记录到socket缓冲区,由 DMA 根据这些将数据从读缓冲区拷贝到网卡,相比之前版本减少了一次CPU拷贝的过程。
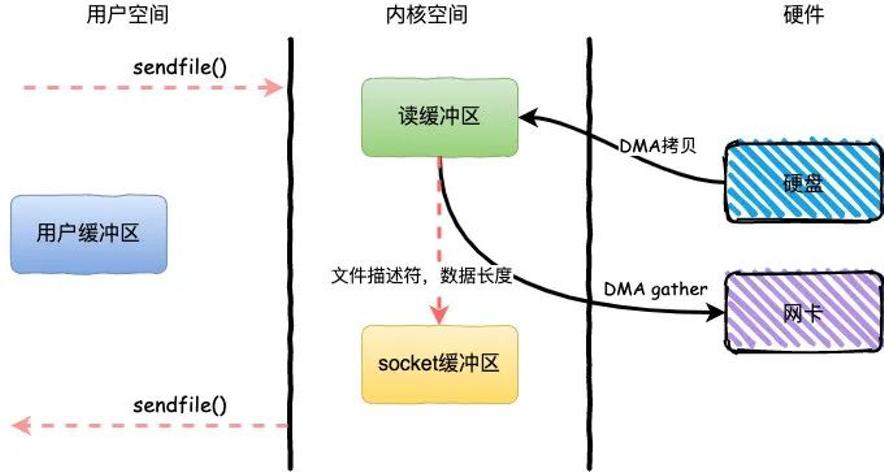
整个过程发生了2次用户态和内核态的上下文切换和2次拷贝,其中更重要的是完全没有CPU拷贝,具体流程如下:
用户进程通过sendfile()方法向操作系统发起调用,上下文从用户态转向内核态
DMA控制器利用scatter把数据从硬盘中拷贝到读缓冲区离散存储
CPU把读缓冲区中的文件描述符和数据长度发送到socket缓冲区
DMA控制器根据文件描述符和数据长度,使用scatter/gather把数据从内核缓冲区拷贝到网卡
sendfile()调用返回,上下文从内核态切换回用户态
DMA gather和sendfile一样数据对用户空间不可见,而且需要硬件支持,同时输入文件描述符只能是文件,但是过程中完全没有CPU拷贝过程,极大提升了性能。
应用场景
对于MQ而言,无非就是生产者发送数据到MQ然后持久化到磁盘,之后消费者从MQ读取数据。RocketMQ来说这两个步骤使用的是mmap+write,而Kafka则是使用mmap+write持久化数据,发送数据使用sendfile。
小结
由于CPU和IO速度的差异问题,产生了DMA技术,通过DMA搬运来减少CPU的等待时间。
传统的IOread+write方式会产生2次DMA拷贝+2次CPU拷贝,同时有4次上下文切换。
而通过mmap+write方式则产生2次DMA拷贝+1次CPU拷贝,4次上下文切换,通过内存映射减少了一次CPU拷贝,可以减少内存使用,适合大文件的传输。
sendfile方式是新增的一个系统调用函数,产生2次DMA拷贝+1次CPU拷贝,但是只有2次上下文切换。因为只有一次调用,减少了上下文的切换,但是用户空间对IO数据不可见,适用于静态文件服务器。
sendfile+DMA gather方式产生2次DMA拷贝,没有CPU拷贝,而且也只有2次上下文切换。虽然极大地提升了性能,但是需要依赖新的硬件设备支持。
内存映射-Mmap
内存映射,简而言之就是将内核空间的一段内存区域映射到用户空间。映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,相反内核空间对这段区域的修改也直接反映用户空间。那么对于内核空间与用户空间两者之间需要大量数据传输等操作的话效率是非常高的。当然也可以将内核空间的一段内存区域同时映射到多个进程,这样还可以实现进程间的共享内存通信。
系统调用mmap()就是用来实现上面说的内存映射。最长见的操作就是文件(在Linux下设备也被看做文件)的操作,可以将某文件映射至内存(进程空间),如此可以把对文件的操作转为对内存的操作,以此避免更多的lseek()与read()、write()操作,这点对于大文件或者频繁访问的文件而言尤其受益。
概述
mmap将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。munmap执行相反的操作,删除特定地址区域的对象映射。
当使用mmap映射文件到进程后,就可以直接操作这段虚拟地址进行文件的读写等操作,不必再调用read,write等系统调用。但需注意,直接对该段内存写时不会写入超过当前文件大小的内容。
采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据:一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回文件的。因此,采用共享内存的通信方式效率是非常高的。
通常使用mmap()的三种情况: 提高I/O效率、匿名内存映射、共享内存进程通信。
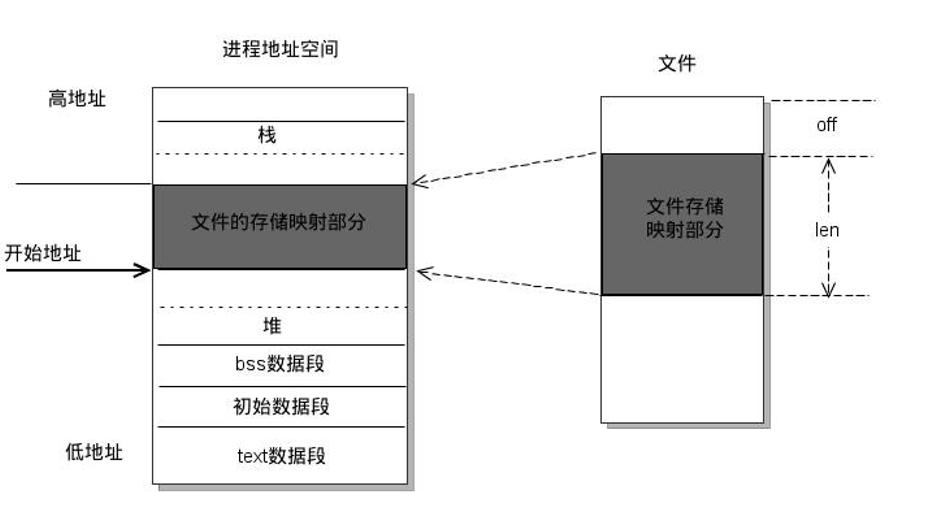
用户空间 mmap()函数 void *mmap(void *start, size_t length, int prot, int flags,int fd, off_t offset),下面就其参数解释如下:
start:用户进程中要映射的用户空间的起始地址,通常为NULL(由内核来指定)
length:要映射的内存区域的大小
prot:期望的内存保护标志
flags:指定映射对象的类型
fd:文件描述符(由open函数返回)
offset:设置在内核空间中已经分配好的的内存区域中的偏移,例如文件的偏移量,大小为PAGE_SIZE的整数倍
返回值:mmap()返回被映射区的指针,该指针就是需要映射的内核空间在用户空间的虚拟地址
内存映射的应用
X Window服务器
众多内存数据库如MongoDB操作数据,就是把文件磁盘内容映射到内存中进行处理,为什么会提高效率? 很多人不解。下面就深入分析内存文件映射。
通过malloc来分配大内存其实调用的是mmap,可见在malloc(10)的时候调用的是brk,malloc(10 * 1024 * 1024)调用的是mmap
mmap()用于共享内存的两种方式
使用普通文件提供的内存映射:适用于任何进程之间;此时,需要打开或创建一个文件,然后再调用mmap();典型调用代码如下:
fd=open(name, flag, mode);
if(fd<0)
...
ptr=mmap(NULL, len , PROT_READ|PROT_WRITE, MAP_SHARED , fd , 0);
使用特殊文件提供匿名内存映射:适用于具有亲缘关系的进程之间;由于父子进程特殊的亲缘关系,在父进程中先调用mmap(),然后调用fork()。那么在调用fork()之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区域进行通信了。注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而mmap()返回的地址,却由父子进程共同维护。对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可。
示例
驱动+应用
首先在驱动程序分配一页大小的内存,然后用户进程通过mmap()将用户空间中大小也为一页的内存映射到内核空间这页内存上。映射完成后,驱动程序往这段内存写10个字节数据,用户进程将这些数据显示出来。
#include <linux/miscdevice.h>
#include <linux/delay.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/mm.h>
#include <linux/fs.h>
#include <linux/types.h>
#include <linux/delay.h>
#include <linux/moduleparam.h>
#include <linux/slab.h>
#include <linux/errno.h>
#include <linux/ioctl.h>
#include <linux/cdev.h>
#include <linux/string.h>
#include <linux/list.h>
#include <linux/pci.h>
#include <linux/gpio.h>
#define DEVICE_NAME "mymap"
static unsigned char array[10]={0,1,2,3,4,5,6,7,8,9};
static unsigned char *buffer;
static int my_open(struct inode *inode, struct file *file){
return 0;
}
static int my_map(struct file *filp, struct vm_area_struct *vma){
unsigned long page;
unsigned char i;
unsigned long start = (unsigned long)vma->vm_start;
//unsigned long end = (unsigned long)vma->vm_end;
unsigned long size = (unsigned long)(vma->vm_end - vma->vm_start);
//得到物理地址
page = virt_to_phys(buffer);
//将用户空间的一个vma虚拟内存区映射到以page开始的一段连续物理页面上
if(remap_pfn_range(vma,start,page>>PAGE_SHIFT,size,PAGE_SHARED))//第三个参数是页帧号,由物理地址右移PAGE_SHIFT得到
return -1;
//往该内存写10字节数据
for(i=0;i<10;i++)
buffer[i] = array[i];
return 0;
}
static struct file_operations dev_fops = {
.owner = THIS_MODULE,
.open = my_open,
.mmap = my_map,
};
static struct miscdevice misc = {
.minor = MISC_DYNAMIC_MINOR,
.name = DEVICE_NAME,
.fops = &dev_fops,
};
static int __init dev_init(void){
int ret;
//注册混杂设备
ret = misc_register(&misc);
//内存分配
buffer = (unsigned char *)kmalloc(PAGE_SIZE,GFP_KERNEL);
//将该段内存设置为保留
SetPageReserved(virt_to_page(buffer));
return ret;
}
static void __exit dev_exit(void){
//注销设备
misc_deregister(&misc);
//清除保留
ClearPageReserved(virt_to_page(buffer));
//释放内存
kfree(buffer);
}
module_init(dev_init);
module_exit(dev_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("LKN@SCUT");
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <linux/fb.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#define PAGE_SIZE 4096
int main(int argc , char *argv[]){
int fd;
int i;
unsigned char *p_map;
//打开设备
fd = open("/dev/mymap",O_RDWR);
if(fd < 0){
printf("open fail\n");
exit(1);
}
//内存映射
p_map = (unsigned char *)mmap(0, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED,fd, 0);
if(p_map == MAP_FAILED){
printf("mmap fail\n");
goto here;
}
//打印映射后的内存中的前10个字节内容
for(i=0;i<10;i++)
printf("%d\n",p_map[i]);
here:
munmap(p_map, PAGE_SIZE);
return 0;
}
进程间共享内存
UNIX访问文件的传统方法是用open打开它们,如果有多个进程访问同一个文件,则每一个进程在自己的地址空间都包含有该文件的副本,这不必要地浪费了存储空间。下图说明了两个进程同时读一个文件的同一页的情形。系统要将该页从磁盘读到高速缓冲区中,每个进程再执行一个存储器内的复制操作将数据从高速缓冲区读到自己的地址空间。
现在考虑另一种处理方法共享存储映射:进程A和进程B都将该页映射到自己的地址空间,当进程A第一次访问该页中的数据时,它生成一个缺页中断。内核此时读入这一页到内存并更新页表使之指向它。以后当进程B访问同一页面而出现缺页中断时,该页已经在内存,内核只需要将进程B的页表登记项指向次页即可。如下图所示:
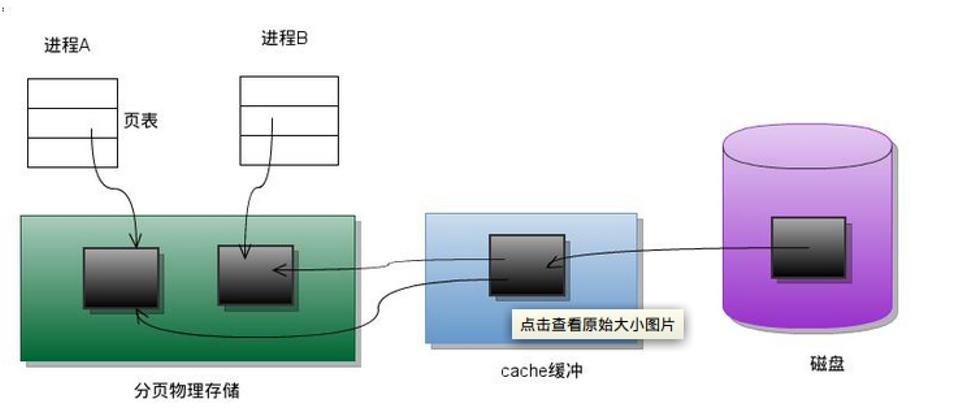
下面就是进程A和B共享内存的示例。两个程序映射同一个文件到自己的地址空间, 进程A先运行, 每隔两秒读取映射区域, 看是否发生变化。进程B后运行, 它修改映射区域, 然后退出, 此时进程A能够观察到存储映射区的变化。
进程A的代码:
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <error.h>
#define BUF_SIZE 100
int main(int argc, char **argv){
int fd, nread, i;
struct stat sb;
char *mapped, buf[BUF_SIZE];
for (i = 0; i < BUF_SIZE; i++){
buf[i] = '#';
}
/* 打开文件 */
if ((fd = open(argv[1], O_RDWR)) < 0){
perror("open");
}
/* 获取文件的属性 */
if ((fstat(fd, &sb)) == -1) {
perror("fstat");
}
/* 将文件映射至进程的地址空间 */
if ((mapped = (char *)mmap(NULL, sb.st_size, PROT_READ |
PROT_WRITE, MAP_SHARED, fd, 0)) == (void *)-1) {
perror("mmap");
}
/* 文件已在内存, 关闭文件也可以操纵内存 */
close(fd);
/* 每隔两秒查看存储映射区是否被修改 */
while (1) {
printf("%s\n", mapped);
sleep(2);
}
return 0;
}
进程B的代码:
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <error.h>
#define BUF_SIZE 100
int main(int argc, char **argv){
int fd, nread, i;
struct stat sb;
char *mapped, buf[BUF_SIZE];
for (i = 0; i < BUF_SIZE; i++) {
buf[i] = '#';
}
/* 打开文件 */
if ((fd = open(argv[1], O_RDWR)) < 0) {
perror("open");
}
/* 获取文件的属性 */
if ((fstat(fd, &sb)) == -1) {
perror("fstat");
}
/* 私有文件映射将无法修改文件 */
if ((mapped = (char *)mmap(NULL, sb.st_size, PROT_READ |
PROT_WRITE, MAP_PRIVATE, fd, 0)) == (void *)-1) {
perror("mmap");
}
/* 映射完后, 关闭文件也可以操纵内存 */
close(fd);
/* 修改一个字符 */
mapped[20] = '9';
return 0;
}
匿名映射实现父子进程通信
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define BUF_SIZE 100
int main(int argc, char** argv){
char *p_map;
/* 匿名映射,创建一块内存供父子进程通信 */
p_map = (char *)mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if(fork() == 0) {
sleep(1);
printf("child got a message: %s\n", p_map);
sprintf(p_map, "%s", "hi, dad, this is son");
munmap(p_map, BUF_SIZE); //实际上,进程终止时,会自动解除映射。
exit(0);
}
sprintf(p_map, "%s", "hi, this is father");
sleep(2);
printf("parent got a message: %s\n", p_map);
return 0;
}
mmap进行内存映射的原理
mmap系统调用的最终目的是将设备或文件映射到用户进程的虚拟地址空间,实现用户进程对文件的直接读写,这个任务可以分为以下三步:
1.在用户虚拟地址空间中寻找空闲的满足要求的一段连续的虚拟地址空间,为映射做准备(由内核mmap系统调用完成)
假如vm_area_struct描述的是一个文件映射的虚存空间,成员vm_file便指向被映射的文件的file结构,vm_pgoff是该虚存空间起始地址在vm_file文件里面的文件偏移,单位为物理页面。mmap系统调用所完成的工作就是准备这样一段虚存空间,并建立vm_area_struct结构体,将其传给具体的设备驱动程序.
2.建立虚拟地址空间和文件或设备的物理地址之间的映射(设备驱动完成) 建立文件映射的第二步就是建立虚拟地址和具体的物理地址之间的映射,这是通过修改进程页表来实现的。mmap方法是file_opeartions结构的成员:int (*mmap)(struct file *,struct vm_area_struct *);
linux有2个方法建立页表:
使用remap_pfn_range一次建立所有页表。int remap_pfn_range(struct vm_area_struct *vma, unsigned long virt_addr, unsigned long pfn, unsigned long size, pgprot_t prot)。
使用nopage VMA方法每次建立一个页表项。 struct page *(*nopage)(struct vm_area_struct *vma, unsigned long address, int *type);
3.当实际访问新映射的页面时的操作(由缺页中断完成)
page cache及swap cache中页面的区分:一个被访问文件的物理页面都驻留在page cache或swap cache中,一个页面的所有信息由struct page来描述。struct page中有一个域为指针mapping ,它指向一个struct address_space类型结构。page cache或swap cache中的所有页面就是根据address_space结构以及一个偏移量来区分的。
文件与 address_space结构的对应:一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构,其中的i_mapping域指向一个address_space结构。这样一个文件就对应一个address_space结构,一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面。因此,当要寻址某个数据时,很容易根据给定的文件及数据在文件内的偏移量而找到相应的页面。
进程调用mmap()时,只是在进程空间内新增了一块相应大小的缓冲区,并设置了相应的访问标识,但并没有建立进程空间到物理页面的映射。因此,第一次访问该空间时,会引发一个缺页异常。
对于共享内存映射情况,缺页异常处理程序首先在swap cache中寻找目标页(符合address_space以及偏移量的物理页),如果找到,则直接返回地址;如果没有找到,则判断该页是否在交换区 (swap area),如果在,则执行一个换入操作;如果上述两种情况都不满足,处理程序将分配新的物理页面,并把它插入到page cache中。进程最终将更新进程页表。 注:对于映射普通文件情况(非共享映射),缺页异常处理程序首先会在page cache中根据address_space以及数据偏移量寻找相应的页面。如果没有找到,则说明文件数据还没有读入内存,处理程序会从磁盘读入相应的页面,并返回相应地址,同时进程页表也会更新。
所有进程在映射同一个共享内存区域时,情况都一样,在建立线性地址与物理地址之间的映射之后,不论进程各自的返回地址如何,实际访问的必然是同一个共享内存区域对应的物理页面。