Linux进程编程入门
 一、Linux下多任务机制的介绍
一、Linux下多任务机制的介绍Linux有一特性是多任务,多任务处理是指用户可以在同一时间内运行多个应用程序,每个正在执行的应用程序被称为一个任务。
多任务操作系统使用某种调度(shedule)策略由内核来执行支持多个任务并发执行。事实上,单核处理器在某一时刻只能执行一个任务。每个任务创建时被分配时间片几十到上百毫秒,任务执行占用CPU时,时间片递减。操作系统会在当前任务的时间片用完时调度执行其他任务。由于任务会频繁地切换执行,因此给用户多个任务运行的感觉。所以可以说,多任务由“时间片 + 轮换”来实现。多任务操作系统通常有三个基本概念:任务、进程和线程。
进程的基本概念
进程是指一个具有独立功能的程序在某个数据集合上的动态执行过程,它是操作系统进行资源分配和调度的基本单元。简单的说,进程是一个程序的一次执行的过程。进程具有并发性、动态性、交互性和独立性等主要特性。进程和程序是有本质区别的:
1程序(program)是一段静态的代码,是保存在非易失性存储器磁盘上的指令和数据的有序集合,没有任何执行的概念;
2进程(process)是一个动态的概念,它是程序的一次执行过程在RAM上执行,包括了动态创建、调度、执行和消亡的整个过程,它是程序执行和资源管理的最小单位。
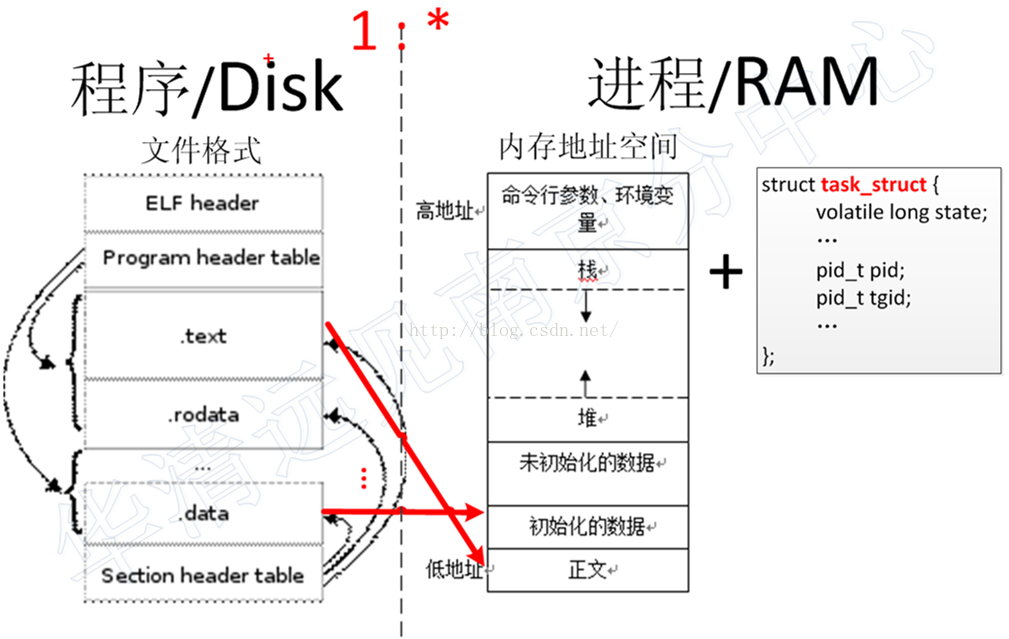
这里,我们可以看到,进程由两部分组成:内存地址空间 + task_struct ,task_struct 下面我们会讲到,内存地址空间就是我们程序在内存中运行进程时所开辟的4GB虚拟地址空间,用于存放代码段、数据段、堆、栈等;从操作系统的角度看,进程是程序执行时相关资源的总称。当进程结束时,所有资源被操作系统回收。
Linux系统中主要包括下面几种类型的过程:
1交互式进程;
2批处理进程;
3守护进程;
Linux下的进程结构
进程不但包括程序的指令和数据,而且包括程序计数器和处理器的所有寄存器以及存储临时数据的进程堆栈。因为Linux是一个多任务的操作系统,所以其他的进程必须等到操作系统将处理器的使用权分配给自己之后才能运行。当正在运行的进程需要等待其他的系统资源时,Linux内核将取得处理器的控制权,按照某种调度算法将处理器分配给某个等待执行的进程。
在上面介绍程序和进程的区别时,我们看到进程除了内存地址空间以外,还有个结构体task_struct,内核将所有进程存放在双向循环链表进程链表中,链表的每一项就是这个结构体task_struct,称为进程控制块的结构。该结构包含了与一个进程相关的所有信息,在linux内核目录下<include/Linux/sched.h>文件中定义。task_struct内核结构比较大,它能完整地描述一个进程,如进程的状态、进程的基本信息、进程标示符、内存的相关信息、父进程相关信息、与进程相关的终端信息、当前工作目录、打开的文件信息,所接收的信号信息等。
下面详细讲解task_struct结构中最为重要的两个域:stat 进程状态 和 pid 进程标示符。
1、进程状态
Linux中的进程有以下几种主要状态:运行状态、可中断的阻塞状态、不可中断的阻塞状态、暂停状态、僵死状态、消亡状态,它们之间的转换关系如下:
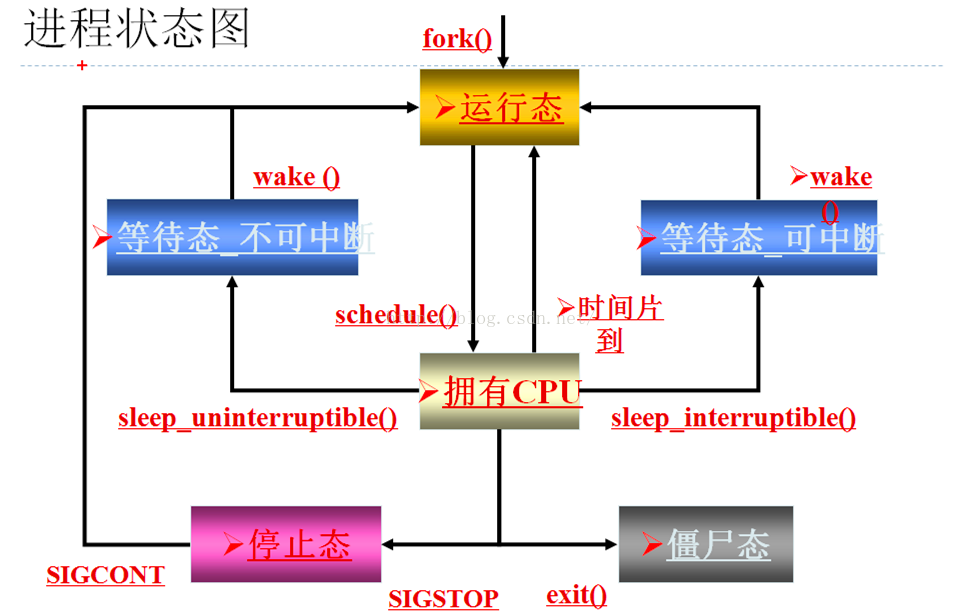
1运行态TASK_RUNNING:进程当前正在运行,或者正在运行队列中等待调度排队中;
2等待态_可中断TASK_INTERRUPTIBLE:进程处于阻塞睡眠sleep,主动放弃CPU状态,正在等待某些事件发生或能够占用某些资源。处于这种状态下的进程可以被信号中断。接收到信号或被显式地唤醒呼叫如调用wake_up系列宏:wake_up、wake_up_interruptible等唤醒之后,进程将转变为运行态,继续排队等待调度;
3登台态_不可中断TASK_UNINTERRUPTIBLE:此进程状态类似于可中断的阻塞状态TASK_INTERRUPTIBLE,只是他不会处理信号,把信号传递到这种状态下的进程不能改变它的状态,即不可被信号所中断,不能被随便调度。在一些特定的情况下进程必须等待,知道某些不能被中断的事件发生,这种状态是很有用的。只有在它等待的事件发生时,进程才被显示地唤醒呼叫唤醒,进程将转变为运行态,继续排队等待调度;
4停止态TASK_STOPPED,即暂停状态,进程的执行被暂停,当进程受到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU等信号,就会进入暂停状态,知道收到继续执行信号,转变为运行态,继续排队等待调度;
5僵尸态EXIT_ZOMBIE:子进程运行结束,父进程尚未使用wait 函数族如使用wait()函数等系统调用来回收退出状态。处于该状态下的子进程已经放弃了几乎所有的内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中即task_struct保留一个位置,记载该进程的退出信息供其父进程收集。即进程结束后,内存地址空间被释放、task_struct 成员被释放,但task_struct 这个空壳还存在,它就是僵尸,这个僵尸我们用kill 是杀不掉的。所以,一般在子进程结束后,我们会对其进行回收。回收的方法有三种:
(1谁创建谁回收,即用父进程来回收;
(2父进程不回收,通知内核来回收;
(3由init 进程来回收,当父进程先死掉,子进程成为孤儿进程,由 init 进程来认养;
当这三种条件都不满足时,比如父进程不去回收子进程,自己却未死掉,僵尸便会出现,这是非常棘手的,可以通过杀死父进程来杀死僵尸不推荐使用;
2、进程标识符
Linux内核通过唯一的进程标示符PID来标识每个进程。PID存放在task_strcut 的pid字段中。当系统启动后,内核通常作为某一个进程的代表。一个指向task_struct 的宏 current 用来记录正在运行的进程。current 进程作为进程描述符结构指针的形式出现在内核代码中,例如,current->pid 表示处理器正在执行的进程的PID。当系统需要查看所有的进程时,则调用 for_each_process(宏),这将比系统搜索数组的速度要快的多。
在Linux 中获得当前进程的进程号PID和父进程号 (PPID) 的系统调用函数分别为 getpid() 和 getppid() 。
3、进程的模式
进程的执行模式分别为用户模式和内核模式。
在CPU的所有指令中,有一些指令是非常危险的,如果错用,将导致整个系统崩溃。比如:清内存、设置时钟等。如果所有的程序都能使用这些指令,那么你的系统一天死机n回就不足为奇了。所以,CPU将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通的应用程序只能使用那些不会造成灾难的指令。Intel的CPU将特权级别分为4个级别:RING0,RING1,RING2,RING3。
linux的内核是一个有机的整体。每一个用户进程运行时都有一份内核的拷贝,每当用户进程使用系统调用时,都自动地将运行模式从用户态转为内核态,此时进程在内核的地址空间中运行。
当一个任务进程执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态或简称为内核态。此时处理器处于特权级最高的0级内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。
当进程在执行用户自己的代码时,则称其处于用户运行态用户态。即此时处理器在特权级最低的3级用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。
内核态与用户态是操作系统的两种运行级别,跟intel cpu没有必然的联系, 如上所提到的intel cpu提供Ring0-Ring3四种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为 内核态,没有使用Ring1和Ring2。Ring3状态不能访问Ring0的地址空间,包括代码和数据。Linux进程的4GB地址空间,3G-4G部 分大家是共享的,是内核态的地址空间,这里存放在整个内核的代码和所有的内核模块,以及内核所维护的数据。用户运行一个程序,该程序所创建的进程开始是运行在用户态的,如果要执行文件操作,网络数据发送等操作,必须通过write,send等系统调用,这些系统调用会调用内核中的代码来完成操作,这时,必须切换到Ring0,然后进入3GB-4GB中的内核地址空间去执行这些代码完成操作,完成后,切换回Ring3,回到用户态。这样,用户态的程序就不能 随意操作内核地址空间,具有一定的安全保护作用。
处理器总处于以下状态中的一种:
1)、内核态,运行于进程上下文,内核代表进程运行于内核空间;
2)、内核态,运行于中断上下文,内核代表硬件运行于内核空间;
3)、用户态,运行于用户空间。
从用户空间到内核空间有两种触发方式:
1)、用户空间的应用程序,通过系统调用,进入内核空间。这个时候用户空间的进程要传递很多变量、参数的值给内核,内核态运行的时候也要保存用户进程的一些寄存器值、变量等。所谓的“进程上下文”,可以看作是用户进程传递给内核的这些参数以及内核要保存的那一整套的变量和寄存器值和当时的环境等。
2)、硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的“中断上下文”,其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境主要是当前被打断执行的进程环境。
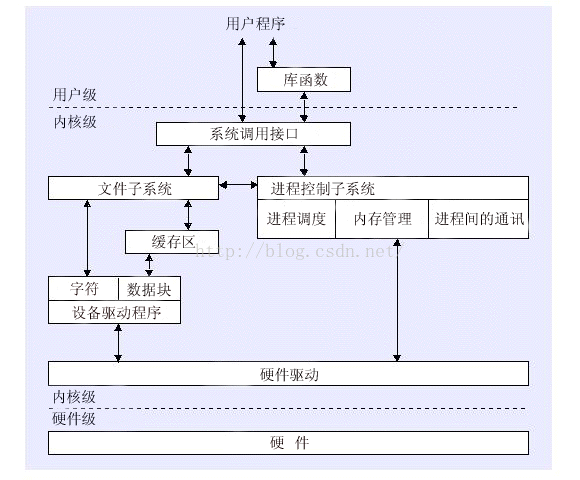
一个程序我们可以从两种角度去分析。其一就是它的静态结构,其二就是动态过程。下图表示了用户态和内核态直接的关系静态的角度来观察程序
二、进程编程函数
1、fork() 函数
在Linux 中创建一个新进程的方法是使用fork() 函数。fork() 函数最大的特性就是执行一次返回两个值。
函数原型如下:
所需头文件
#include <sys/types.h> //提供类型pid_t定义
#include <unistd.h>
函数原型 pid_t fork(void)
函数返回值
0:子进程
子进程PID大于0的整数:父进程
-1:出错
fork()函数用于从已存在的进程中创建一个新进程。新进程称为子进程,而原进程称为父进程。具体fork()函数究竟做了什么,我们先看这张图:
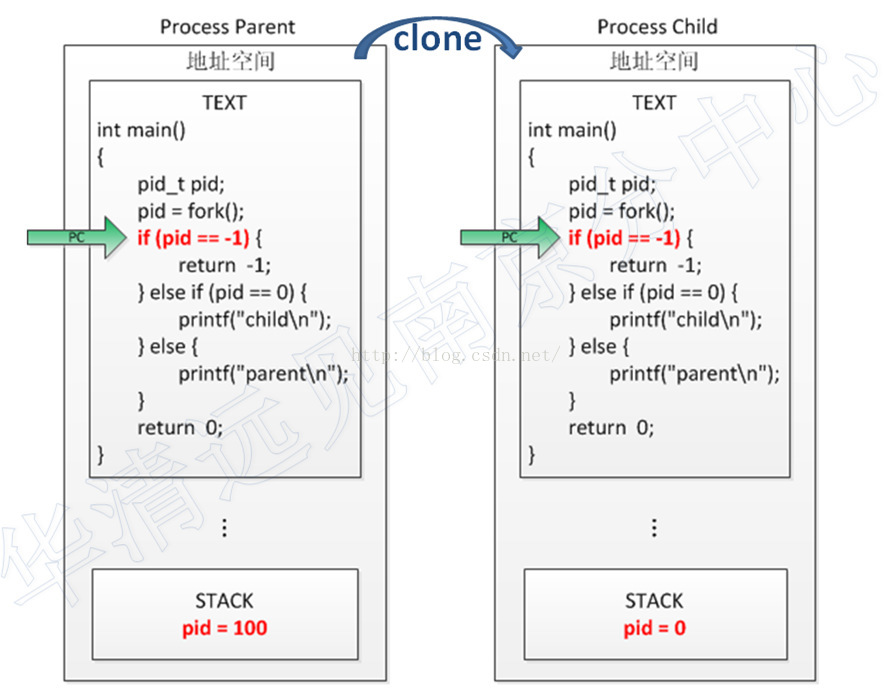
这里我们可以看到,使用fork () 函数得到的子进程是父进程的一个复制品,它从父进程处继承了整个进程的地址空间注意:子进程有其独立的地址空间,只是复制了父进程地址空间里的内容,包括进程上下文、代码段、进程堆栈、内存信息、打开的文件描述符、信号处理函数、进程优先级等。而子进程所独有的只是它的进程号、资源使用和计时器等。
因为子进程几乎是父进程的完全复制,所以父子进程会运行同一个程序,这里,两个进程都会从PC位置往下执行;如何区分它们呢?父子进程一个很重要的区别是, fork()返回值不同。父进程中返回值是子进程的进程号,而子进程中返回0;所以在上图中,两个进程会通过判断PID来选择执行的语句。
注意:子进程没有执行fork() 函数,而是从fork() 函数调用的下一条语句开始执行。
下面,写一个fork()程序,来加深对fork()的理解:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
int global = 22;
int main(void){
int test = 0,stat;
pid_t pid;
pid = fork();
if(pid < 0){
perror("fork");
return -1;
}
else if(pid == 0){
global++;
test++;
printf("global = %d test = %d Child,my PID is %d\n",global,test,getpid());
exit(0);
}
else{
global += 2;
test += 2;
printf("global = %d test = %d Parent,my PID is %d\n",global,test,getpid());
exit(0);
}
}
从结果我们可以发现几个问题:
1最后一行光标在闪,是程序没执行完吗?第三行中子进程打印前是bash,这是什么原因呢?
其实我们这里执行的程序中有三个进程在执行:父进程、子进程、bash。从打印结果中我们可以看到父进程先执行完,然后是bash,最后子进程执行完,这里的光标其实是bash的。所以,我们可以发现:父进程、子进程谁先运行时不可知的,谁先运行有内核调度来确定;
2从打印结果中,可以看出父子进程打印出了各自的进程号和对应变量的值,显然global和test在父子进程间是独立的,其各自的操作不会对对方的值有影响;
2、exec 函数族
fork() 函数用于创建一个子进程,该子进程几乎赋值了父进程的全部内容。我们能否让子进程执行一个新的程序呢?exec 函数族就提供了一个在进程中执行里一个程序的办法。它可以根据指定的文件名或目录找到可执行文件,并用它来取代当前进程的数据段、代码段和堆栈段。在执行完之后,当前进程除了进程号外,其他的内容都被替换掉了。所以,如果一个进程想执行另一个程序,那么它就可以调用fork() 函数创建一个进程,然后调用exec家族中的任意一个函数,这样看起来就像执行应用程序而产生了一个新进程。
Linux 中并没有exec() 函数,而是有6个以 exec 开头的函数,下面是函数语法:
所需头文件 #include <stdio.h>
函数原型
int execl (const char *path,const char *arg,...);
int execv (const char *path, char *const argv[]);
int execle (const char *path,const char *arg,....,char *const envp[]);
int execve(const char *path, char const *argv[],char *const envp[]);
int execlp (const char *file,const char *arg,...);
int execvp (const char *file, char *const argv[]);
函数返回值 -1;出错
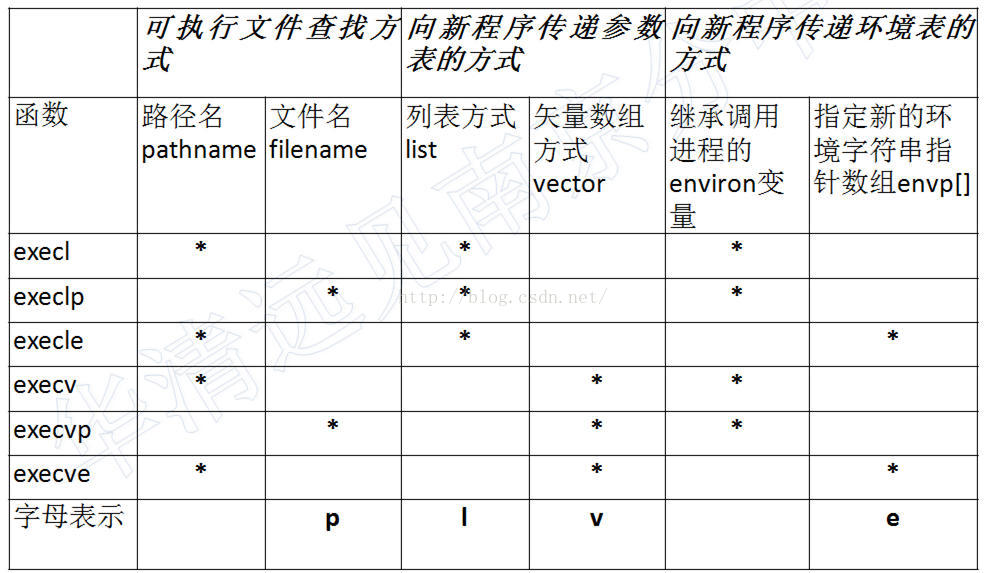
exec 函数族使用区别
1).可执行文件查找方式
表中的前四个函数的查找方式都是指定完整的文件目录路径,而最后两个函数(以p 结尾的函数)可以只给出文件名,系统会自动从环境变量“$PATH”所包含的路径中进行查找。
2).参数表传递方式
两种方式:逐个列举或是将所哟参数通过指针数组传递
以函数名的第五位字母来区分,字母为" l ”(list) 的表示逐个列举的方式;字母为" v "(vertor) 的表示将所有参数构成指针数组传递,其语法为 char *const argv[]
3).环境变量的使用
exec 函数族可以默认使用系统的环境变量,也可以传入指定的环境变量,这里以"e" (Enviromen) 结尾的两个函数execle、execve 就可以在 envp[] 中传递当前进程所使用的环境变量;
exev使用示例:
#include <stdio.h>
#include <unistd.h>
int main(){
//调用execlp 函数,相当于调用了 "ps -ef"命令
if(execlp("ps","ps","-ef",NULL) < 0) //这里"ps"为filename "ps" 为argv[0] "-ef"为argv[1],NULL为参数结束标志
{
perror("execlp error");
return -1;
}
return 0;
}
如果我们使用execvp,则
char *argv[] = { "ps","-ef",NULL};
execvp("ps",argv);
3、exit() 和_exit()
1) exit()和_exit()函数说明
exit()和_exit() 都是用来终止进程的。当程序执行到exit()或_exit()时,进程会无条件的停止剩下的所有操作,清除各种数据结构,并终止本进程的运行。但这两个函数是有区别的:
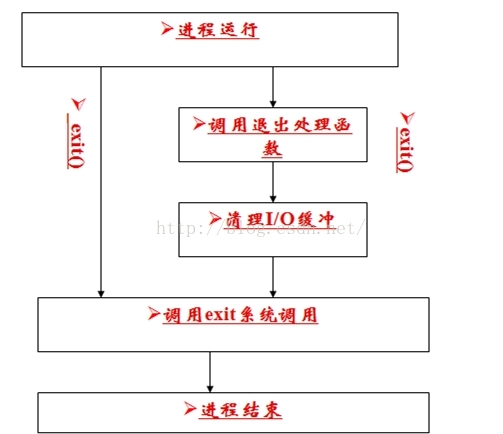
可以看出exit() 是库函数,而_exit() 是系统调用;
_exit()函数的作用最为简单:直接使进程终止运行,清除其使用的内存空间,并销毁其在内核中的各种数据结构;exit()函数则在这些基础上作了一些包装,在执行退出之前加了若干道工序。
函数描述如下:
所需头文件
exit():#include <stdlib.h>
_exit():#include <unistd.h>
函数原型
exit():void exit(int status);
_exit():void _exit(int status);
函数传入值
status 是一个整形的参数,可以利用这个参数传递进程结束时的状态。通常0表示正常结束;其他的数值表示出现了错误,进程非正常结束。在实际编程时,可以用wait 系统调用接收子进程的返回值,进行相应的处理。
其实,在main函数内执行return 语句,也会使进程正常终止;
exit(status) 执行完会将终止状态status传给内核,内核会将status传给父进程的wait(&status),wait()会提取status,并分析。
4、wait 和waitpid()
wait()函数
调用该函数使进程阻塞,直到任一个子进程结束或者是该进程接受到了一个信号为止。如果该进程没有子进程或其子进程已经结束。wait 函数会立即返回。函数描述如下:
所需头文件
#include <sys/types.h>
#includ <sys/wait.h>
函数原型 pid_t wait(int *status)
函数参数
status是一个整型指针,指向的对象用来保存子进程退出时的状态
status 若为空,表示忽略子进程退出时的状态;
status 若不为空,表示保存子进程退出时的状态;
另外,子进程的结束状态可有Linux 中的一些特定的宏来测宏。
函数返回值
成功:子进程的进程号
失败: -1
附:检查wait 所返回的终止状态的宏
WIFEXTED (status) :若为正常终止子进程返回的状态,则为真。对于这种情况可执行 WEXITSTATUS (status) ,取子进程传送给exit参数的低八位;首先判断子进程是否正常死亡,异常死亡是不会运行到exit()的,这时分析status 是无意义的;
wait() 会回收任一一个先死亡的子进程;
下面看一个程序,wait()与exit()的使用
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char **argv){
pid_t pid;
printf("parent[pid=%d] is born\n", getpid());
if (-1 == (pid = fork())){
perror("fork error");
return -1;
}
if (pid == 0){
printf("child[pid=%d] is born\n", getpid());
sleep(20);
printf("child is over\n");
exit(123); //return 123;
}else{
pid_t pid_w;
int status;
printf("parent started to wait...\n");
pid_w = wait(&status);
printf("parent wait returned\n");
if (pid_w < 0){
perror("wait error");
return 1;
}
if (WIFEXITED(status)){
status = WEXITSTATUS(status);
printf("wait returns with pid = %d. return status is %d\n", pid_w, status);
}else{
printf("wait returns with pid = %d. the child is terminated abnormally\n", pid_w);
}
// while(1);
printf("father is over\n");
return 0;
}
}
waitpid()函数
waitpid()函数和wait()的作用是完全相同的,但waitpid 多出了两个可有用户控制的参数pid 和 options,从而为用户编程提供了一种更为灵活的方式。waitpid 可以用来等待指定的进程,可以使进程不挂起而立刻返回。
wait(&status);等价于waitpid(-1, &status, 0);
其函数类型如下:
所需头文件
#include <sys/types.h> /* 提供类型pid_t的定义 */
#include <sys/wait.h>
函数原型
pid_t waitpid(pid_t pid,int *status,int options)
函数传入值 pid > 0 时,只等待进程ID等于pid的子进程,不管其它已经有多少子进程运行结束退出了,只要指定的子进程还没有结束,waitpid就会一直等下去。
pid = -1时,等待任何一个子进程退出,没有任何限制,此时waitpid和wait的作用一模一样。
pid = 0 时,等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid不会对它做任何理睬。
pid < -1时,等待一个指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值。
函数传入值
WNOHANG 如果没有任何已经结束的子进程则马上返回, 不予以等待;
WUNTRACED 如果子进程进入暂停执行情况则马上返回,但结束状态不予以理会;
0:同wait(),阻塞父进程,直到指定的子进程退出;
函数返回值
> 0:已经结束运行的子进程的进程号;
0:使用选项WNOHANG 且没有子进程退出
-1:出错
代码示例如下:
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
int main(){
pid_t pc, pr;
pc = fork();
if(pc < 0) /* 如果fork出错 */
printf("Error occured on forking\n");
else if(pc == 0) /* 如果是子进程 */
{
sleep(10); /* 睡眠10秒 */
exit(0);
}
/* 如果是父进程 */
do{
pr = waitpid(pc, NULL, WNOHANG); /* 使用了WNOHANG参数,waitpid不会在这里等待 */
if(pr == 0) /* 如果没有收集到子进程 */
{
printf("No child exited\n");
sleep(1);
}
}while(pr == 0); /* 没有收集到子进程,就回去继续尝试 */
if(pr == pc)
printf("successfully get child %d\n", pr);
else
printf("some error occured\n");
}
父进程经过10次失败的尝试之后,终于收集到了退出的子进程。
三、进程fork()
在开始之前,我们先来了解一些基本的概念:
1. 程序, 没有在运行的可执行文件;进程, 运行中的程序
2. 进程调度的方法:
按时间片轮转
先来先服务
短时间优先
按优先级别
3. 进程的状态:
就绪 ->> 运行 ->> 等待
运行 ->> 就绪 //时间片完了
等待 ->> 就绪 //等待的条件完成了
查看当前系统进程的状态 ps auxf
status:
D Uninterruptible sleep (usually IO)
R Running or runnable (on run queue)
S Interruptible sleep (waiting for an event to complete)
T Stopped, either by a job control signal or because it is being traced.
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z Defunct ("zombie") process, terminated but not reaped by its parent.
< high-priority (not nice to other users)
N low-priority (nice to other users)
L has pages locked into memory (for real-time and custom IO)
s is a session leader
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)
+ is in the foreground process group
4. 父进程/子进程 , 让一个程序运行起来的进程就叫父进程, 被调用的进程叫子进程
5. getpid //获取当前进程的进程号
getppid //获取当前进程的父进程号
6. fork //创建一个子进程,创建出来的子进程是父进程的一个副本,除了进程号,父进程号不同。
子进程从fork()后开始运行, 它得到的fork返回值为0
父进程得到的返回值为子进程的进程号
返回值为-1时, 创建失败
来看一个程序:
#include <stdio.h>
#include <unistd.h>
int main(void){
pid_t pid ;
//printf("hello world \n");
//从fork开始就已经产生子进程
pid = fork(); //就已经产生新的4G空间,复制空间
//创建出来的子进程是父进程的一个副本,除了进程号,父进程号和子进程号不同
//printf("hello kitty\n");
if(pid == 0)
{
//子进程运行区
printf("child curpid:%d parentpid:%d \n" , getpid() , getppid());
return 0 ;
}
//父进程运行区
printf("parent curpid:%d parentpid:%d \n" , getpid() , getppid());
return 0 ;
}
四、守护进程
守护进程是什么?就是在后台运行的进程。那么如何创建守护进程呢?
1. 创建孤儿进程
2. setsid() 创建进程会话
3. 重定向标准输入, 标准输出
4. chdir, 改当当前进程的工作目录
接下来看一个例子:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main(void){
//进程成为守护进程的步骤
//代号:Ss
//守护进程也称为精灵进程
//1.产生孤儿进程
pid_t pid ;
int fd ;
pid = fork();
if(0 == pid){
//2.改变工作目录
chdir("/");
//3.成为进程组长
setsid();
//4 1>.关闭标准输入,输出,出错
//close(0);
//close(1);
//close(2);
//2> 重定向
fd = open("/dev/null" , O_RDWR);
if(-1 == fd){
perror("Open null file fail");
return -1 ;
}
//禁掉标准输入,输出,出错,不然输出的东西会在终端乱喷
//Ctrl + C 无效
dup2(fd , 0);
dup2(fd , 1);
dup2(fd , 2);
while(1){
//main event loop
printf("hello world \n");
sleep(1);
}
return 0 ;
}
//父进程直接退出
return 0 ;
}
五、孤儿进程
孤儿进程, 指在父进程退出后,而子进程还在运行,这个子进程就成了孤儿进程,这时由init进程(pid=1)接管。
来看看例子:
#include <stdio.h>
#include <unistd.h>
int main(void){
pid_t pid ;
//父进程先结束,子进程还在运行
//如果父进程结束,则子进程的父亲为init
//孤儿进程由进程他的祖先收留
pid = fork();
if(0 == pid){
printf("first child pid:%d ppid:%d \n" , getpid() , getppid());
sleep(2);
printf("second child pid:%d ppid:%d \n" , getpid() , getppid());
while(1)
sleep(1);
return 0 ;
}
sleep(1);
printf("parent pid:%d ppid:%d \n" , getpid() , getppid());
printf("I am die ... \n");
return 0 ;
}
六、僵尸进程
僵尸进程, 指子进程退出后, 父进程还没有回收子进程的资源,这个子进程就处在于僵尸状态。来看看如何产生?
#include <stdio.h>
#include <unistd.h>
int main(void){
pid_t pid ;
//zombie 子进程先退出,父进程没有回收子进程资源
//这就是僵尸进程
//僵尸进程不能被直接杀死,只能通过杀死父进程来终止僵尸进程
pid = fork();
if(pid == 0){
printf("i am die ... \n");
printf("pid:%d ppid:%d \n" , getpid() , getppid());
return 0 ;
}
while(1)
sleep(1);
return 0 ;
}
本文总结自杨源鑫的博客,感谢原作者。