软件编译时的选项理解
 编译时configure选项的理解
编译时configure选项的理解C语言编译过程一览
软件编译原理简介
程序编译之函数库1
程序编译之函数库2
主流编译器一览
编译时configure选项的理解
软件编译时configure的build、host、target编译选项的这三个参数在编译时一般不怎么引人注意,也不会有所更改,但它们究竟是什么意思呢,个人理解如下:
build:执行代码编译的主机,正常的话就是你的主机系统。这个参数一般由config.guess来猜就可以,当然自己指定也可以。
host:编译出来的二进制程序所执行的主机,因为绝大多数是如果本机编译,本机执行。所以这个值就等于build。只有交叉编译的时候(也就是本机编译,其他系统机器执行)才会build和host不同。用host指定运行主机。
target:这个选项只有在建立交叉编译环境的时候用到,正常编译和交叉编译都不会用到。用于build主机上的编译器,编译一个新的编译器(binutils,gcc,gdb等),这个新的编译器将来编译出来的其他程序将运行在target指定的系统上。
具体解释一下:build就是你正在使用的机器,host就是你编译好的程序可以运行的平台,target就是你编译的程序可以处理的平台;这个build和host比较好理解,但是target就不好办了,到底什么意思呢?一般来说,我们平时所说的交差编译用不到target的,比如:/configure --build=i386-linux,--host=arm-linux就可以了,在386的平台上编译可以运行在arm板的程序。但是一般我们都是编译程序,而不是编译工具,如果我们编译工具,比如gcc,这个target就有用了。如果需要在同一台机器上为arm开发板编译一个可以处理mips程序的gcc,那么target就是mips了,在此就可以看到target派上用场了。下边举例说明一下,以编译binutils为例:
1. ./configure --build=mipsel-linux --host=mipsel-linux --target=mipsel-linux
说明:利用mipsel-linux的编译器对binutils进行编译,编译出来的binutils运行在mipsel-linux,这个binutils用来编译能够在mipsel-linux运行的代码。“当然没有人会用这个选项来编译binutils”
2. ./configure --build=i386-linux --host=mipsel-linux --target=mipsel-linux
will cross-build native mipsel-linux binutils oni386-linux.
说明:利用i386-linux的编译器对binutils进行编译,编译出来的binutils运行在mipsel-linux,这个binutils用来编译能够在mipsel-linux运行的代码。“这个选项可以用来为其他的机器编译它的编译器”。
3. ./configure --build=i386-linux --host=i386-linux --target=mipsel-linux
will build mipsel-linux cross-binutils on i386-linux.
说明:利用i386-linux的编译器对binutils进行编译,编译出来的binutils运行在i386-linux,这个binutils用来编译能够在mipsel-linux运行的代码。“这个选项用来在i386主机上建立一个mipsel-linux的交叉编译环境”。
4. ./configure --build=mipsel-linux --host=i386-linux --target=mipsel-linux
will cross-build mipsel-linux cross-binutils for i386-linux on mipsel-linux.
说明:利用mipsel-linux的编译器对binutils进行编译,编译出来的binutils运行在i386-linux,这个binutils用来编译能够在mipsel-linux运行的代码。“这个选项可以用来在i386主机上建立一个mipsel-linux的交叉编译环境,但是交叉编译环境在mipsel-linux 编译出来,安装到i386-linux主机上,估计没有多少人会这么用吧”
总的来说,只有host !=build的时候编译才是交叉编译,否则就是正常编译。
参考来源:
Host/Target specific installation notes for GCC
说完了上面的configure过程,再来看看CMMI流程。在自行安装编译Linux软件过程中会执行三个步骤:./configure,make,make install。
./configure(配置)
configure会根据当前系统环境和指定参数生成makefile文件,为下一步的编译做准备,可以通过在 configure 后加上参数来对安装进行控制,比如代码:./configure --prefix=/usr 意思是将该软件安装在 /usr 下面,执行文件就会安装在 /usr/bin (而不是默认的 /usr/local/bin),资源文件就会安装在 /usr/share(而不是默认的/usr/local/share)。同时一些软件的配置文件你可以通过指定 --sys--config= 参数进行设定。有一些软件还可以加上 --with、--enable、--without、--disable 等等参数对编译加以控制,可以通过允许 ./configure --help 查看详细的说明帮助。它常用的参数如下:
--help:输出帮助信息
--prefix=PREFIX:将所有文件安装到PREFIX文件夹下。实际上不同的文件会被安装到不同的子文件夹中。
--exec--prefix=EXEC--PREFIX:结构依赖文件的安装位置。默认与PREFIX相同。
--bindir=BINDIR:可执行程序目录。默认为EXEC--PREFIX/bin。
--datadir=DATADIR:程序所需只读文件的目录。默认为PREFIX/share。
--sysconfdir=SYSCONFDIR:配置文件的目录。默认为PREFIX/etc。
--libdir=LIBDIR:库文件和动态装在模块的目录。默认为EXEC--PREFIX/lib。
--includedir=INCLUDEDIR:C和C++头文件的目录。默认是PREFIX/include。
--docdir=DOCDIR:文档文件目录。默认是PREFIX/doc。
--mandir=MANDIR:手册目录。默认是PREFIX/man。
--with--includes=DIRS:DIRS是一系列冒号分隔的文件夹,这些目录被加入到编译器的头文件中。例如:--with--includes=/opt/gun/includes/
--with--libraries=DIRS:DIRS是一系列冒号分隔的文件夹,这些目录用于查找库文件。例如:--with--libraries=/opt/gnu/lib:/usr/sup/lib
--enable--locale:打开区域支持。
--enable--recode:打开单字节字符集记录的支持。
--enable--multibyte:允许使用多字节编码。
make(编译)
make,这一步就是编译,当执行make的时候,make会在当前目录下搜索Makefile(makefile)这个文本文件,而makefile里面记录了源码如何编译的详细信息。
make install(安装)
make insatll,这条命令来进行安装,这一步一般需要你有 root 权限(因为要向系统写入文件)。
其他命令:
make clean 清除编译产生的可执行文件及目标文件。
make distclean 除了清除可执行文件和目标文件外,把configure所产生的Makefile也清除掉。
make dist 将程序和相关的档案包装成一个压缩文件以供发布。
如何卸载编译安装(make install)的软件
使用安装包自带的反安装程序
常见的反安装target有:make uninstall/distclean/veryclean 等,但并不是每个源代码包都提供反安装,这不是个通用方法等。
通过删除编译时设置的单独目录
如果编译时设置了--prefix到一个单独的文件夹,就删除那个文件夹即可,但如果编译安装到了类似/usr这种地方,找一个临时目录重新安装一遍,如:
./configure --prefix=/tmp/to_remove && make install
然后遍历/tmp/to_remove的文件,删除对应安装位置的文件即可。
通过安装日志删除
安装日志里能够看得到到底安装了那些文件到那些位置,通常会使用'cp'或者'install'命令拷贝文件。可以事先记得记录'make install'的所有输出日志,'make install &> |tee make.log'。
Linux的C开发环境与Windows的有所不同,在Linux下一个完整的C开发环境包括以下3个主要的部分组成:
1、函数库:glibc
要构架一个完整的C开发环境,Glibc是必不可少的,它是Linux下C的主要函数库。Glibc有两种安装方式:
1).安装成测试用的函数库
在编译程序时用不同的选项来试用新的函数库。
2).安装成主要的C函数库
所有新编译程序均用的函数库。
Glibc2常包含几个附加包,如:LinuxThreads、locale和crypt。
2、编译器:gcc
gcc(GNU CCompiler)是GNU推出的功能强大、性能优越的多平台编译器,gcc编译器能将C、C++语言源程序、汇程式化序和目标程序编译、连接成可执行文件,以下是gcc支持编译的一些源文件的后缀及其解释:
.c为后缀的文件,C语言源代码文件;
.a为后缀的文件,是由目标文件构成的档案库文件;
.C,.cc或.cxx 为后缀的文件,是C++源代码文件;
.h为后缀的文件,是程序所包含的头文件;
.i 为后缀的文件,是已经预处理过的C源代码文件;
.ii为后缀的文件,是已经预处理过的C++源代码文件;
.m为后缀的文件,是Objective-C源代码文件;
.o为后缀的文件,是编译后的目标文件;
.s为后缀的文件,是汇编语言源代码文件;
.S为后缀的文件,是经过预编译的汇编语言源代码文件。
3、系统头文件:glibc_header
缺少了系统头文件的话,很多用到系统功能的C程序将无法通过编译;由于gcc包需要依赖binutils和cpp包,另外make包也是在编译中常用的。安装完后,就构成了最基本的C开发环境,在此C的开发环境中,可以编译多数的C写的应用程序。而对于一个C程序来说,安装完成后通常可以分成三个组成:
1).可执行文件
2).包含头文件
3).库文件
可执行文件就是最终运行的命令,包含文件是该C程序include的一些定义文件,库文件则是该C程序自定义的库(可分为静态与动态链接,后者使用的场合居多)。比如对于用RPM安装的MySQL:可 执行文件放在/usr/bin下,包含文件放在/usr/include/mysql下,库文件在/usr/lib/mysql下。只有系统可以找到程序对应的包含文件和库文件,程序可执行文件才能正常运行。
C语言编译过程一览
C语言的编译链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和用到的库文件进行组织形成最终生成可执行代码的过程。过程图解如下:
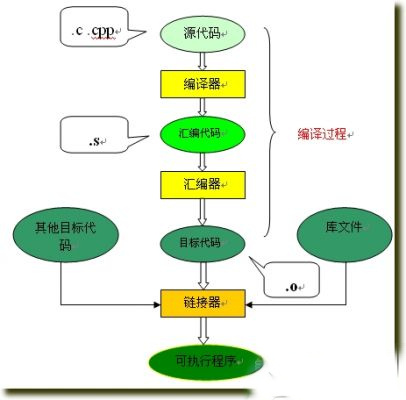
从图上可以看到,整个代码的编译过程分为编译和链接两个过程,编译对应图中的大括号括起的部分,其余则为链接过程。
编译过程
编译过程又可以分成两个阶段:编译和汇编。
编译
编译是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码,源文件的编译过程包含两个主要阶段:
第一个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内容。如#include指令就是一个预处理指令,它把头文件的内容添加到.cpp文件中。这个在编译之前修改源文件的方式提供了很大的灵活性,以适应不同的计算机和操作系统环境的限制。一个环境需要的代码跟另一个环境所需的代码可能有所不同,因为可用的硬件或操作系统是不同的。在许多情况下,可以把用于不同环境的代码放在同一个文件中,再在预处理阶段修改代码,使之适应当前的环境。
主要是以下几方面的处理:
(1).宏定义指令,如 #define a b
对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a则不被替换。还有 #undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。
(2).条件编译指令,如#ifdef,#ifndef,#else,#elif,#endif等。
这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉
(3).头文件包含指令,如#include "FileName"或者#include 等。
在头文件中一般用伪指令#define定义了大量的宏(最常见的是字符常量),同时包含有各种外部符号的声明。采用头文件的目的主要是为了使某些定义可以供多个不同的C源程序使用。因为在需要用到这些定义的C源程序中,只需加上一条#include语句即可,而不必再在此文件中将这些定义重复一遍。预编译程序将把头文件中的定义统统都加入到它所产生的输出文件中,以供编译程序对之进行处理。包含到c源程序中的头文件可以是系统提供的,这些头文件一般被放在/usr/include录下。在程序中#include它们要使用尖括号(<>)。另外开发人员也可以定义自己的头文件,这些文件一般与c源程序放在同一目录下,此时在#include中要用双引号("")。
(4).特殊符号,预编译程序可以识别一些特殊的符号。
例如在源程序中出现的LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。预编译程序对于在源程序中出现的这些串将用合适的值进行替换。
预编译程序所完成的基本上是对源程序的“替代”工作。经过此种替代,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。这个文件的含义同没有经过预处理的源文件是相同的,但内容有所不同。下一步,此输出文件将作为编译程序的输出而被翻译成为机器指令。
第二个阶段编译、优化阶段,经过预编译得到的输出文件中,只有常量;如数字、字符串、变量的定义,以及C语言的关键字,如main,if,else,for,while,{,}, +,-,*,等等。
编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
优化处理是编译系统中一项比较艰深的技术。它涉及到的问题不仅同编译技术本身有关,而且同机器的硬件环境也有很大的关系。优化一部分是对中间代码的优化。这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的。
对于前一种优化,主要的工作是删除公共表达式、循环优化(代码外提、强度削弱、变换循环控制条件、已知量的合并等)、复写传播,以及无用赋值的删除,等等。
后一种类型的优化同机器的硬件结构密切相关,最主要的是考虑是如何充分利用机器的各个硬件寄存器存放的有关变量的值,以减少对于内存的访问次数。另外,如何根据机器硬件执行指令的特点(如流水线、RISC、CISC、VLIW等)而对指令进行一些调整使目标代码比较短,执行的效率比较高,也是一个重要的研究课题。
汇编
汇编实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。目标文件由段组成。通常一个目标文件中至少有两个段:
1).代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
2).数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
UNIX环境下主要有三种类型的目标文件:
(1).可重定位文件
其中包含有适合于其它目标文件链接来创建一个可执行的或者共享的目标文件的代码和数据。
(2).共享的目标文件
这种文件存放了适合于在两种上下文里链接的代码和数据。第一种是链接程序可把它与其它可重定位文件及共享的目标文件一起处理来创建另一个目标文件;第二种是动态链接程序将它与另一个可执行文件及其它的共享目标文件结合到一起,创建一个进程映象。
(3).可执行文件
它包含了一个可以被操作系统创建一个进程来执行之的文件。汇编程序生成的实际上是第一种类型的目标文件。对于后两种还需要其他的一些处理方能得到,这个就是链接程序的工作了。
链接过程
由汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题。例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。所有的这些问题,都需要经链接程序的处理方能得以解决。
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够诶操作系统装入执行的统一整体。根据开发人员指定的同库函数的链接方式的不同,链接处理可分为两种:
(1).静态链接
在这种链接方式下,函数的代码将从其所在地静态链接库中被拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
(2).动态链接
在此种方式下,函数的代码被放到称作是动态链接库或共享对象的某个目标文件中。链接程序此时所作的只是在最终的可执行程序中记录下共享对象的名字以及其它少量的登记信息。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
对于可执行文件中的函数调用,可分别采用动态链接或静态链接的方法。使用动态链接能够使最终的可执行文件比较短小,并且当共享对象被多个进程使用时能节约一些内存,因为在内存中只需要保存一份此共享对象的代码。但并不是使用动态链接就一定比使用静态链接要优越。在某些情况下动态链接可能带来一些性能上损害。在linux下使用的gcc编译器便是把以上的几个过程进行捆绑,使用户只使用一次命令就把编译工作完成,这的确方便了编译工作,但对于初学者了解编译过程就很不利了,下图便是gcc代理的编译过程:
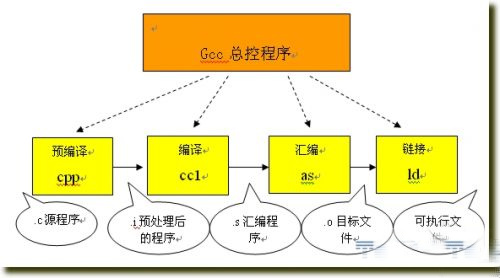
从上图可以看到:
预编译
将.c 文件转化成 .i文件
使用的gcc命令是:gcc –E
对应于预处理命令 cpp
编译
将.c/.h文件转换成.s文件
使用的gcc命令是:gcc –S
对应于编译命令 cc –S
汇编
将.s 文件转化成 .o文件
使用的 gcc 命令是:gcc –c
对应于汇编命令是 as
链接
将.o文件转化成可执行程序
使用的 gcc 命令是: gcc
对应于链接命令是 ld
总结起来编译过程就上面的四个过程:预编译、编译、汇编、链接。了解这四个过程中所做的工作,对理解头文件、库等的工作过程是有帮助的,而且清楚的了解编译链接过程还对我们在编程时定位错误,以及编程时尽量调动编译器的检测错误会有很大的帮助的。一般情况下,在支持微处理器的编译器中会捆绑相应的启动程序,如下图:
软件编译原理简介
接上文,当我们点击编译器的运行按钮时,在界面顶端的提示栏上会出现“Building”的字样,紧接着会出现“Linking”的字样,知道Building是编译过程,那这个Linking(链接)是什么过程呢?本节将对链接过程做一个讲解,了解链接的过程,可以帮助理解计算机系统的底层原理,并解答平时关于计算机怎样识别并执行程序的一些疑惑。
链接的基本概念
链接(linking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。链接可以执行与编译时(complie time),也就是源代码被翻译成机器代码时;也可以执行于加载时(load time),也就是在程序被加载器(load-er)加载到内存并执行时;甚至可以执行在运行时(run time),也就是由应用程序来执行。在早期的计算机系统中,链接是手动执行的。在现代系统中,链接是由叫做连接器(linker)的程序自动执行的。
链接的作用
链接器使分离编译成为可能,我们不用将一个大型的应用程序组织为一个巨大的源文件,而是可以把它分解为更小、更好管理的模块,可以独立地修改和编译这些模块。当我们改变这些模块中的一个时,只需简单地重新编译它,并重新链接应用,而不必重新编译其它文件。下面的讨论基于这样的环境:一个运行Linux的x86-64系统,使用标准的ELF-64目标文件格式。
编译器驱动程序
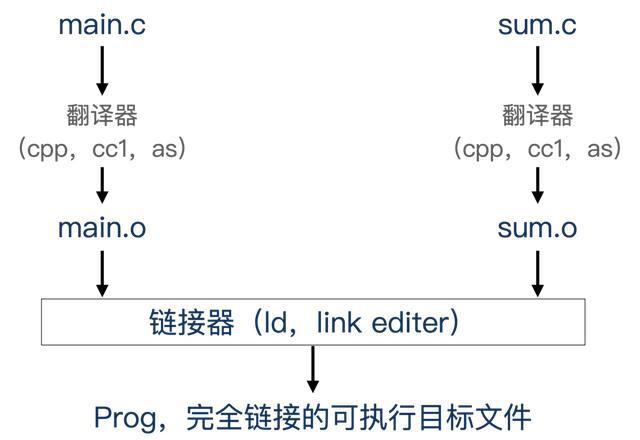
下面的C语言示例程序,由两个源文件组成,main.c和sum.c。main函数初始化一个整数数组,然后调用sum函数来对数组元素求和。
// sum.cint
sum(int *a, int n){
int s = 0;
for (int i = 0; i < n; i++) { s += a[i]; }
return s;
}// main.cint
array[2] = {1, 2};
int main(){
int val = sum(array, 2);
return val;
}
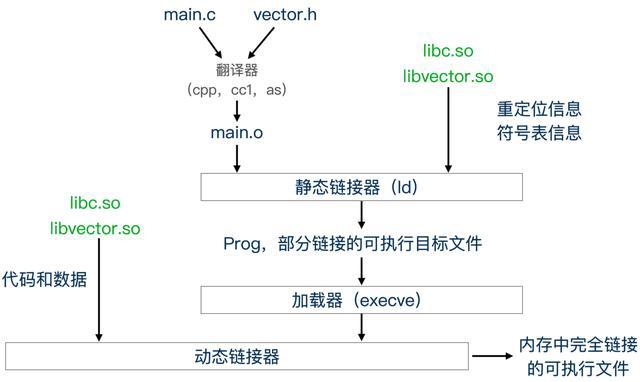
大多数的编译系统会提供编译器驱动程序(compile driver),包含语言预处理器、编译器、汇编器和链接器。首先编译器驱动程序会对main.c与sum.c文件的源代码进行翻译,翻译过程如下:

其中,main.o称为可重定位目标文件。之后,编译系统会运行链接器ld,将main.o和sum.o以及一些必要的系统目标文件组合起来,创建一个可以执行目标文件,这个过程是静态链接,过程如下:
再之后,操作系统会调用加载器(loader),将可执行文件prog中的代码和数据复制到内存中,然后执行。
静态链接
静态链接器(static linker)以一组可重定位目标文件作为输入,生成一个完全链接的、可以加载和运行的可执行目标文件。输入的可重定位目标文件由各种不同的代码和数据节(section)组成,每一节都是一个连续的字节序列。指令在一节中,初始化了的全局变量在另一个节中,而未初始化的变量又在另外一节中。
为了构造可执行文件,链接器必须完成两个重要的任务:
1、符号解析(symbol resolution)。目标文件定义和引用符号,一个个符号对应一个函数或一个全局变量或一个静态变量(即C语言中以static属性声明的变量)。符号解析的目的是将每个符号引用正好和一个符号定义关联起来。
2、重定位(relocation)。编译器和汇编器生成从地址0开始的代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使它们指向这个内存位置。
目标文件纯粹是字节块的集合,这些块中,有些包含程序代码,有些包含数据,而有些则是引导链接器和加载器的数据结构。链接器将这些块连接起来,确定被连接块的运行时位置,并且修改代码和数据块中的各种位置。
目标文件
目标文件有三种形式:
1、可重定位目标文件。包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件。
2、可执行目标文件。包含二进制代码和数据,其形式可以被直接复制到内存并执行。
3、共享目标文件。一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态的加载进内存并链接。动态库就是这种形式的。
目标文件的生成方式:
1、编译器和汇编器生成可重定位目标文件(包括共享目标文件)。
2、链接器生成可执行目标文件。
目标文件的格式:
1、在iOS和MacOS-X中,目标文件的格式是Mach-O格式。
2、x86-64 Linux和Unix系统使用可执行可连接格式ELF。
可重定位目标文件
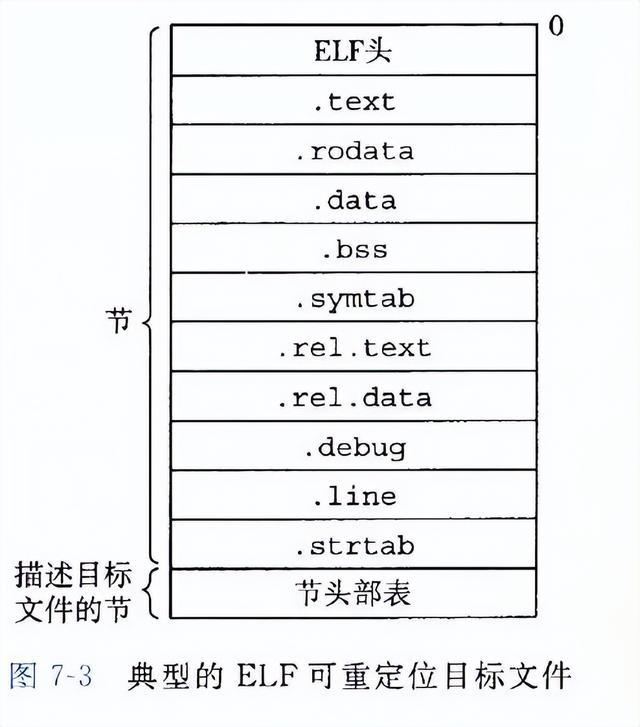
上图展示了一个典型的ELF可重定位目标文件的格式。ELF头包含很多信息,包括生成该文件的系统的字节大小,字节顺序,ELF头的大小,目标文件的类型,机器类型等等。节头部表描述了不同节的位置和大小。
加载ELF头和节头部表的是节:
.text:已编译程序的机器代码。
.rodata:只读数据,比如 printf语句中的格式串和开关语句的跳转表。
.data:已初始化的全局和静态C变量。局部C变量在运行时被保存在栈中,既不出现在,data节中,也不出现在.bss节中。
.bss:未初始化的全局和静态C变量,以及所有被初始化为0的全局或静态变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分已初始化和未初始化变量是为了空间效率:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。运行时,在内存中分配这些变量,初始值为0。
.symtab:一个符号表,它存放在程序中定义和引用的函数和全局变量的信息。一些程序员错误地认为必须通过-g选项来编译一个程序,才能得到符号表信息。实际上,每个可重定位目标文件在. symtab中都有一张符号表(除非程序员特意用 STRIP命令去掉它)。然而,和编译器中的符号表不同, symtab符号表不包含局部变量的条目。
.rel.text:一个.text节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置。一般而言,任何调用外部函数或者引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非用户显式地指示链接器包含这些信息。
.rel.data:被模块引用或定义的所有全局变量的重定位信息。一般而言,任何已初始化的全局变量,如果它的初始值是一个全局变量地址或者外部定义函数的地址,都需要被修改。
.debug:一个调试符号表,其条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的C源文件。只有以-g选项调用编译器驱动程序时,才会得到这张表。
.line:原始C源程序中的行号和.text节中机器指令之间的映射。只有以-g选项调用编译器驱动程序时,才会得到这张表。
.strtab:一个字符串表,其内容包括. symtab和, debug节中的符号表,以及节头部中的节名字。字符串表就是以nu11结尾的字符串的序列。
符号和符号表
每个可重定位目标模块(目标文件)m都有一个符号表,它包含m定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
1、由模块m定义并能被其它模块引用的全局符号。这些符号对应于非静态的C函数和全局变量。
2、由其它模块定义并被模块m引用的全局符号。这些符号称为外部符号,对应于在其它模块中定义的非静态C函数和全局变量。
3、只被模块m定义和引用的局部符号。它们对应于带static属性的C函数和全局变量。这些符号在模块m中任何位置都可见,但是不能被其它模块引用。
.symtab中的符号表不包含非静态程序变量的任何符号,这些程序变量符号在栈中被管理,链接器对此类符号不感兴趣。
如何解析多重定义的全局符号
链接器的输入是一组可重定位目标模块。每个模块定义一组符号,有些是局部的(只对定义该符号的模块可见),有些是全局的(对其他模块也可见)。如果多个模块定义同名的全局符号,会发生什么呢?下面是Linux编译系统采用的方法:在编译时,编译器向汇编器输出每个全局符号,或者是强(strong)或者是弱(weak),而汇编器把这个信息隐含地编码在可重定位目标文件的符号表里。函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义,Linux链接器使用下面的规则来处理多重定义的符号名:
规则1:不允许有多个同名的强符号。
规则2:如果有一个强符号和多个弱符号同名,那么选择强符号。
规则3:如果有多个弱符号同名,那么从这些弱符号中任意选择一个。
静态库
迄今为止,都是假设链接器读取一组可重定位目标文件,并把它们链接起来,输出一个可执行目标文件。实际上所有的编译系统都提供一种机制,将所有相关的目标模块打包成一个单独的文件,称为静态库。静态库可以用做链接器的输入,当链接器构造一个输出的可执行目标文件时,它只复制静态库里被应用程序引用的目标模块,这就减少了可执行文件在磁盘和内存中的大小。在Linux系统中,静态库由后缀.a标识。
重定位
一旦链接器完成了符号解析这一步,就把代码中的每个符号引用和正好一个符号定义(即它的一个输入目标模块中的一个符号表条目)关联起来。此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位步骤了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。重定位由两步组成:
1、重定位节和符号定义。在这一步中,链接器将所有相同类型的节合并为同一类型的新的聚合节。例如,来自所有输入模块的.data节被全部合并成一个节,这个节成为输出的可执行目标文件的.data节。然后,链接器将运行时内存地址赋给新的聚合节,赋给输人模块定义的每个节,以及赋给输人模块定义的每个符号。当这一步完成时,程序中的每条指令和全局变量都有唯一的运行时内存地址了。
2、重定位节中的符号引用。在这一步中,链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址。要执行这一步,链接器依赖于可重定位目标模块中称为重定位条目(relocation entry)的数据结构。
当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置,它也并不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行目标文件时如何修改这个引用。
可执行目标文件与加载可执行目标文件
动态链接共享库
静态库由一些缺点:静态库需要定期维护和更新;每个程序都会使用一些通用的标准函数,在运行时,这些函数的代码会被复制到每个运行进程的文本段中,在一个运行上百个进行的典型系统上,这是对内存资源的浪费。
共享库(shared library)是致力于解决静态库缺陷的一个现代创新产物。共享库是一个目标模块,在运行或加载时,可以加载到任意内存地址,并和一个在内存中的程序链接起来。这个过程称为动态链接,是由一个叫做动态链接器(dynamic linker)的程序来执行的。在Linux系统中,共享库通常由.so后缀标识。它以两种不同的方式来共享的。首先在任何给定的文件系统中,对于一个库只有一个.so文件。所有引用该哭的可执行目标文件共享这个.so文件中的代码和数据,而不是像静态库的内容那样被复制和嵌入到引用它们的可执行文件中。其次在内存中,一个共享库的.text节的一个副本可以被不同的正在运行的进程共享。
程序编译之函数库1
函数库依照是否被编译到程序内部分为动态(Dynamic)与静态(Static)函数库,供使用者调用。
1、静态函数库
2、动态函数库
3、Linux采用什么函数库
4、如何将动态函数库加载到高速缓存中
5、ldd命令使用
6、测试用例
测试用例之动态函数库
测试用例之动态静态函数库编译比较
1、静态函数库
1.1 扩展名
# find /usr -name "*.a"
/usr/lib64/libmcheck.a
/usr/lib64/librpcsvc.a
/usr/lib64/libtkstub8.5.a
......
结论:静态函数库扩展名以.a结尾。
1.2 编译操作
在编译的时候直接整合到执行程序中,因此利用静态函数库编译的文件比较大。静态函数库最大的优点就是可以在无相关办依赖库的环境中独立执行,缺点是函数库升级时,整个执行文件必须要重新编译才能将新版的函数库整合到程序中去。在升级方面,只要函数库升级了,所有使用函数库的程序都需要重新编译。
2、动态函数库
2.1 扩展名
/usr/lib64/libanl.so
/usr/lib64/libc.so
/usr/lib64/libasprintf.so
......
动态扩展名以.so结尾。
2.2 编译操作
动态与静态函数库在编译的时的差别还是挺大的,动态函数库在编译的时候,在程序里边仅需一个指针的位置而已,也就是动态函数库的内容并没有整合到执行文件中去,当要执行文件要使用的函数库功能时,程序才会主动去读取函数库来使用,因此它的文件会比较小。
这类函数库所编译出来的程序不能被独立执行。因为在我们使用到函数库功能的时候,程序才会去读取函数库,因此函数库文件必须要存在才可以的。而且函数库所在的目录也不能改变。函数库升级后,执行文件根本不需要进行重新编译。因为执行文件会直接指向新的函数库文件,前提是新旧的函数库名称相同。
3、Linux采用什么函数库
目前Linux发行的版本更多的是采用动态函数库,因为升级方便。Linux中的函数库大多数放在/lib和/lib64目录中,内核的函数库存放在/lib/modules目录中。
4、如何将动态函数库加载到高速缓存中
为什么要这样做?因为内存的访问速度是硬盘的好些倍,因此将常用的动态函数库先加载到内存当中,当软件要使用时,就不需要从硬盘读取,可以提高动态函数库的读取速度。
4.1 将想要读入高速缓存的动态函数库所在的目录写入/etc/ld.so.conf
# cat /etc/ld.so.conf
include ld.so.conf.d/*.conf
/usr/lib64/mysql #新增的内容
4.2 使用ldconfig -p命令将/etc/ld.so.conf的数据读入缓存中
# ldconfig -p
1032 libs found in cache `/etc/ld.so.cache'
p11-kit-trust.so (libc6,x86-64) => /lib64/p11-kit-trust.so
libz.so.1 (libc6,x86-64) => /lib64/libz.so.1
libyelp.so.0 (libc6,x86-64) => /lib64/libyelp.so.0
libyaml-0.so.2 (libc6,x86-64) => /lib64/libyaml-0.so.2
......
5、ldd命令使用
# ldd --help
用法:ldd [选项]… 文件…
--help 印出这份说明然后离开
--version 印出版本信息然后离开
-d, --data-relocs 进程数据重寻址
-r, --function-relocs 进程数据和函数重寻址
-u, --unused 印出未使用的直接依赖关系
-v, --verbose 印出所有信息
6、测试用例
6.1 测试用例之动态函数库
#找lsblk安装在位置
# which lsblk
/usr/bin/lsblk
#查看文件类型---二进制文件
# file lsblk
lsblk: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=ccba2a4ee56b0aa9649fc803e89d8d6111201e15, stripped
上面输出就明示了该文件是一个动态执行文件。
#lsblk命令就是依赖这些动态函数库
# ldd /usr/bin/lsblk
linux-vdso.so.1 => (0x00007ffec5de6000)
......#此处省略一些。。
libbz2.so.1 => /lib64/libbz2.so.1 (0x00007ff53d0d1000)
6.2 测试用例之动态静态函数库编译比较
#编写一个简单的C语言脚本
# cat test.c
#include<stdio.h>
int main(){
printf("hello world!\n");
return 0;
}
#采用动态函数库编译
# gcc -o test_dynamic test.c
#采用静态函数库编译
# gcc -static -o test_static test.c
#查看文件大小
# ll -h
total 860K
-rw-r--r--. 1 root root 73 Jul 2 23:52 test.c
-rwxr-xr-x. 1 root root 8.3K Jul 3 00:00 test_dynamic
-rwxr-xr-x. 1 root root 842K Jul 3 00:01 test_static
#结论:静态文件比动态文件大
#执行可执行文件,输出结果一致。Go语言默认就是使用静态编译的方式。
程序编译之函数库2
1、动态库
1.1 动态库概述
C语言动态库(也称为共享库)是在程序运行时被加载到内存中的库文件,它包含了可由多个程序共享的代码和数据。动态库在编译时不会被直接链接到目标程序中,而是在程序运行时动态加载。这种特性使得动态库具有一些优势,如节省磁盘空间、便于更新和维护、以及支持多个程序同时共享库代码。
动态库通常以.so(在Linux和类Unix系统中)或.dll(在Windows系统中)作为文件扩展名。创建动态库的过程通常包括编写源代码文件、编译生成目标文件、然后使用特定的编译器选项(如-shared)将这些目标文件链接成动态库文件。
当程序需要使用动态库中的函数或数据时,它会在运行时通过操作系统提供的动态链接机制来加载这个库。一旦库被加载,程序就可以通过库中的导出符号来调用函数或访问数据。这种动态链接的方式使得程序在编译时不需要知道所有依赖项的具体实现,从而提高了程序的灵活性和可维护性。
注意,由于动态库是在运行时加载的,因此在使用动态库的程序中,需要确保动态库文件的路径正确,并且操作系统能够找到并加载这个库。此外,如果动态库更新了版本,程序在运行时可能会加载到新的库版本,这也需要程序在设计时考虑到版本兼容性和更新策略。
1.2 动态库制作
例如,实现一个简单的数学运算MathFun.c
// 动态库中的函数,用于加法
int add(int a, int b) {
return a + b;
}
// 动态库中的函数,用于减法
int subtract(int a, int b) {
return a - b;
}
通过使用gcc编译器和-shared选项来创建动态库
gcc -shared -o MathFun.so MathFun.c
将会生成一个名为MathFun.so的动态链接库文件。
1.3 动态库使用
export命令用于设置或显示环境变量。可以通过设置LD_LIBRARY_PATH环境变量来指定动态库的搜索路径,具体步骤:找到该动态库文件,例如,MathFun.so 假设它位于/home/freeoa/dynamicdemo/lib目录下。
使用export设置LD_LIBRARY_PATH,在终端中可以使用以下命令来设置LD_LIBRARY_PATH环境变量
export LD_LIBRARY_PATH=/home/freeoa/dynamicdemo/lib/:$LD_LIBRARY_PATH
注意,把新的库路径添加到了现有LD_LIBRARY_PATH的前面,并用冒号:分隔。这样做是为了确保该库路径在搜索时具有更高的优先级。
2、静态库
2.1 静态库概述
C语言静态库(Static Library)是一种包含一组目标文件的归档文件,这些目标文件通常是由多个C语言源文件编译而成的。静态库在程序编译时被链接到目标程序中,成为程序的一部分,因此在运行时不再需要额外的库文件。与动态库(Dynamic Library)不同,静态库在编译时就已经被完全嵌入到可执行文件中,因此生成的可执行文件通常较大,但无需在运行时依赖外部库文件。
静态库通常具有.a的文件扩展名(代表archive),而在Windows中则通常使用.lib扩展名。创建静态库的过程涉及将多个目标文件(通常由.o或.obj文件组成)打包成一个单独的库文件。
使用静态库的好处之一是,它使得程序在分发时更加简单,因为所有必要的代码都已经包含在可执行文件中。此外,由于静态链接在编译时就已经完成,因此可以避免运行时动态链接可能带来的版本兼容性问题。然而,静态库也有一些缺点,比如生成的可执行文件较大,以及如果多个程序使用相同的静态库,那么每个程序都会包含库的一份完整副本,导致磁盘空间的浪费。
2.2 静态库制作
例如实现一个简单的数学运算MathFun.c
// 静态库中的函数,用于加法
int add(int a, int b) {
return a + b;
}
// 静态库中的函数,用于减法
int subtract(int a, int b) {
return a - b;
}
通过gcc -c编译源代码,生成目标文件.o
gcc -c MathFun.c -o MathFun.o
通过ar rc(或rcs)将目标文件.o打包生成静态库.a文件
ar rc libMathFun.a MathFun.o
注意,库文件需要以lib开头,例如上述数学库,libMathFun.a;如果不带lib的话,将库文件链接至可执行文件时,可能会引起编译错误,如下:
# mathfunc.a放在dynamicdemo/lib目录下
$ gcc -o calculator calculator.c -L /home/freeoa/dynamicdemo/lib -lmathfunc
/usr/bin/ld: 找不到 -lmathfunc
collect2: error: ld returned 1 exit status
# 解决方案
# 将dynamicdemo/lib下的mathfunc.a重新命名为libmathfunc.a,然后,再次使用gcc命令重新编译即可。
2.3 静态库使用
主程序calculator.c,它使用静态库中的函数
#include <stdio.h>
#include "MathFun.h"
int main() {
int a = 5;
int b = 3;
int sum = add(a, b);
int diff = subtract(a, b);
printf("Sum: %d\n", sum);
printf("Difference: %d\n", diff);
return 0;
}
为了编译这个程序并链接静态库,需要使用以下命令:
gcc -o calculator calculator.c -L /home/freeoa/dynamicdemo/lib/ -lMathFun
其中,
-L.告诉编译器在当前目录下查找库文件;
-lMathFun则告诉编译器链接名为libMathFun.a的库,注意不需要提供.a后缀。
主流编译器一览
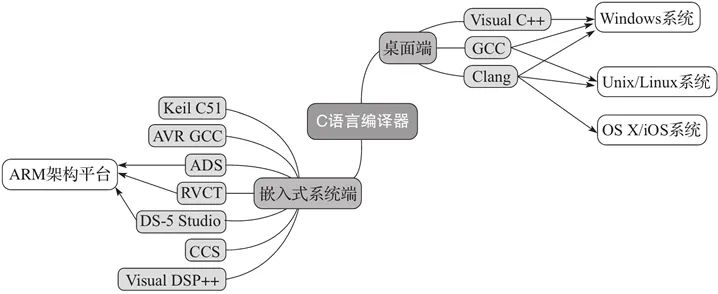
分两部分介绍C语言的编译器,分别是桌面操作系统和嵌入式操作系统。本节转自严长生的个人空间,感谢原作者。
桌面操作系统
对于当前主流桌面操作系统而言,可使用 Visual C++、GCC 以及 LLVM Clang 这三大编译器。
Visual C++(简称 MSVC)是由微软开发的,只能用于 Windows 操作系统;GCC 和 LLVM Clang 除了可用于 Windows 操作系统之外,主要用于类 Unix操作系统(包括 Linux 和 Mac)。像现在很多版本的 Linux 都默认使用 GCC 作为C语言编译器,而像 FreeBSD、macOS 等系统默认使用 LLVM Clang 编译器。由于当前 LLVM 项目主要在 Apple 的主推下发展的,所以在 macOS中,Clang 编译器又被称为 Apple LLVM 编译器。
MSVC 编译器主要用于 Windows 操作系统平台下的应用程序开发,它不开源。用户可以使用 Visual Studio Community 版本来免费使用它,但是如果要把通过 Visual Studio Community 工具生成出来的应用进行商用,那就得好好阅读一下微软的许可证和说明书了。而使用 GCC 与 Clang 编译器构建出来的应用一般没有任何限制,程序员可以将应用程序随意发布和进行商用。MSVC 编译器对 C99 标准的支持十分有限,直到发布 Visual Studio Community 2019,也才对 C11 和 C17 标准做了部分支持。所幸的是,Visual Studio Community 2017 加入了对 Clang 编译器的支持,官方称之为——Clang with Microsoft CodeGen。
C语言从诞生到现在,更新了多个版本,比如 ANSI C、C99、C11、C17 等。也就是说,应用于 Visual Studio 集成开发环境中的 Clang 编译器前端可支持 Clang 编译器的所有语法特性,而后端生成的代码则与 MSVC 效果一样,包括像 long 整数类型在 64 位编译模式下长度仍然为 4 个字节,所以各位使用的时候也需要注意。
嵌入式系统
而在嵌入式系统方面,可用的C语言编译器就非常丰富了:
用于 Keil 公司 51 系列单片机的 Keil C51 编译器;
Arduino 板搭载的开发套件,可用针对 AVR 微控制器的 AVR GCC 编译器;
ARM 自己出的 ADS(ARM Development Suite)、RVDS(RealView Development Suite)和当前最新的 DS-5 Studio;
DSP 设计商 TI(Texas Instruments)的 CCS(Code Composer Studio);
DSP 设计商 ADI(Analog Devices,Inc.)的 Visual DSP++ 编译器,等等。
通常用于嵌入式系统开发的编译工具链都没有免费版本,且一般需要通过国内代理进行购买。所以对于个人开发者或者嵌入式系统爱好者而言是一道不低的门槛。不过 Arduino 的开发套件是可免费下载使用的,并且用它做开发板连接调试也十分简单。Arduino 所采用的C编译器是基于 GCC 的。
还有像树莓派(Raspberry Pi)这种迷你电脑可以直接使用 GCC 和 Clang 编译器。另外还有像 nVidia 公司推出的 Jetson TK 系列开发板也可直接使用 GCC 和 Clang 编译器。树莓派与 Jetson TK 都默认安装了 Linux 操作系统。
在嵌入式领域,一般比较低端的单片机,比如 8 位的 MCU 所对应的C编译器可能只支持 C90 标准,有些甚至连 C90 标准的很多特性都不支持。因为它们一方面内存小,ROM 的容量也小;另一方面,本身处理器机能就十分有限,有些甚至无法支持函数指针,因为处理器本身不包含通过寄存器做间接过程调用的指令。而像 32 位处理器或 DSP,一般都至少能支持 C99 标准,它们本身的性能也十分强大。而像 ARM 出的 RVDS 编译器甚至可用 GNU 语法扩展。
下图展示了上述C语言编译器的分类。
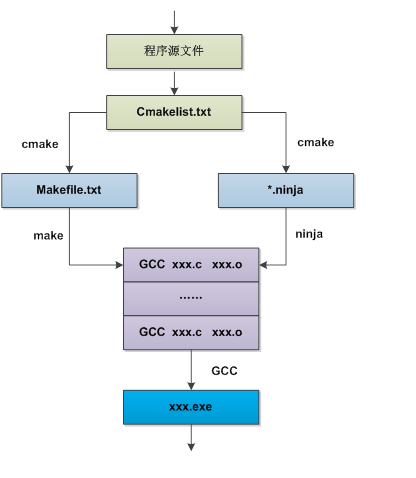
GCC、CMake、CMakelist、Make、Makefile、Ninja关系速览
人类就是在解决一个又一个麻烦中进步的。
1.GCC的诞生
1985年的一个夜晚,一位满脸胡须、五短身材、头发长乱的怪人开始编写一套C语言编译器。这个怪人后来被称作“最伟大的程序员”、“自由软件之父”,他就是 Richard Stallman。经过2年时间没日没夜的大力苦干,他完成了C语言编译器初版,称之为GNU C Complier,也就是现在大名鼎鼎GCC的前身。后来GCC快速发展,除了能编译C语言,还能编译C++、Fortran、Pascal、Objective-C、Java以及Ada 等语言。上世纪80、90年代,个人计算机CPU频率、硬盘大小、内存大小都是以MB为单位,甚至KB为单位,需要编译的程序文件个数较少,用GCC命令也足以应对。
2.新的麻烦出现 (make & makefile)
随着计算机的性能提升和普及,一个软件工程包含的源文件越来越多,比如linux,采用gcc命令逐个手动去编译,很容易混乱而且工作量大,会让人抓狂。于是 Richard Stallman 和 Roland McGrath 共同开发了make 和makefile来解决这个问题。make工具可以看成是一个智能的批处理工具,它本身并没有编译和链接的功能,而是用类似于批处理的方式—通过调用makefile文件中用户指定的命令来进行编译和链接的。makefile是什么?makefile就是一个脚本文件,简单的说就像一首歌的乐谱,make工具就像指挥家,指挥家根据乐谱指挥整个乐团怎么样演奏,make工具就根据makefile中的命令进行编译和链接的。makefile命令中就包含了调用gcc(也可以是别的编译器)去编译某个源文件的命令。
3.新的麻烦又出现(Cmake & CMakelist)
makefile在一些简单的工程下,完全可以人工手写,但是当工程非常大的时候,手写makefile也是非常麻烦。而且陆陆续续出现了各种不同平台的makefile,有GNU make、QT 的 qmake,微软的 MSnmake,BSD Make(pmake),Makepp等等。这些 Make 工具遵循着不同的规范和标准,所执行的 Makefile 格式也千差万别。这样就带来了一个严峻的问题:如果软件想跨平台,必须要保证能够在不同平台编译。而如果使用上面的 Make 工具,就得为每一种标准写一次 Makefile ,这将是一件让人抓狂的工作,如果换了个平台makefile又要重新修改。
于是就出现了Cmake这个工具,Cmake就可以更加简单地生成makefile文件给上面那个make用。当然cmake还有其他功能,就是可以跨平台生成对应平台能用的makefile,就不用再自己去修改了。cmake正是makefile的上层工具,它们的目的正是为了产生可移植的makefile,并简化自己动手写makefile时的巨大工作量。可是cmake根据什么生成makefile呢?它又要根据一个叫CMakeLists.txt文件(学名:组态档)去生成makefile。到最后CMakeLists.txt文件谁写啊?当然是你自己手写的。
4.新的麻烦又又又出现了(Ninja)
随着软件工程越来越大,越来越复杂,make的执行速度慢的问题越来越严重了。于是Google的一名程序员推出的注重速度的构建工具Ninja。Ninja 舍弃了各种高级功能,语法和用法非常简单,给它指定好了具体详细要做什么,所以启动编译的速度非常快。根据实际测试:在超过30,000个源文件的情况下,也能够在1秒钟内开始进行真正的构建。与之相比,通过资深工程师进行编写的Makefiles文件也需要10-20秒才能开始构建。
5.目前完美的结局
Cmake可以生成 .ninja 和.makefile 的工具。因为担心很多人不熟悉makefile文件和ninja文件的写法,所以cmake只需要用户通过对源码文件的简单描述(就是CMakeLists.txt文件),就能自动生成一个project的makefile文件或者ninja文件,然后就可以通过ninja或者make进行启动编译了。
该文章最后由 阿炯 于 2024-07-18 15:01:51 更新,目前是第 3 版。