编译工具链介绍
 编译工具链将程序源代码翻译成可以在计算机上运行的可执行程序。编译过程是由一系列的步骤组成的,每一个步骤都有一个对应的工具。这些工具紧密地工作在一起,前一个工具的输出是后一个工具的输入,像一根链条一样,我们称这一系列工具为编译工具链。编译工具链是与其运行的平台(CPU 架构 和操作系统)息息相关的。分为三个章节。
编译工具链将程序源代码翻译成可以在计算机上运行的可执行程序。编译过程是由一系列的步骤组成的,每一个步骤都有一个对应的工具。这些工具紧密地工作在一起,前一个工具的输出是后一个工具的输入,像一根链条一样,我们称这一系列工具为编译工具链。编译工具链是与其运行的平台(CPU 架构 和操作系统)息息相关的。分为三个章节。编译工具链之一 基本概念、组成部分、编译过程、命名规则
编译工具链之二 详解 ELF 格式及标准、UNIX 发展、ABI
编译工具链之三 ARM-MDK、IAR、GCC 的 .MAP 文件、.LST 文件
本文转自ZC·Shou的博客空间,感谢原作者。
编译工具链之一 基本概念、组成部分、编译过程、命名规则
编译工具链
软件程序的编译过程由一系列的步骤完成,每一个步骤都有一个对应的工具。这些工具紧密地工作在一起,前一个工具的输出是后一个工具的输入,像一根链条一样,我们称这一系列工具为编译工具链(Toolchain)。编译工具链主要包含 编译器等可执行程序与标准库(常用函数通用实现) 两大部分。

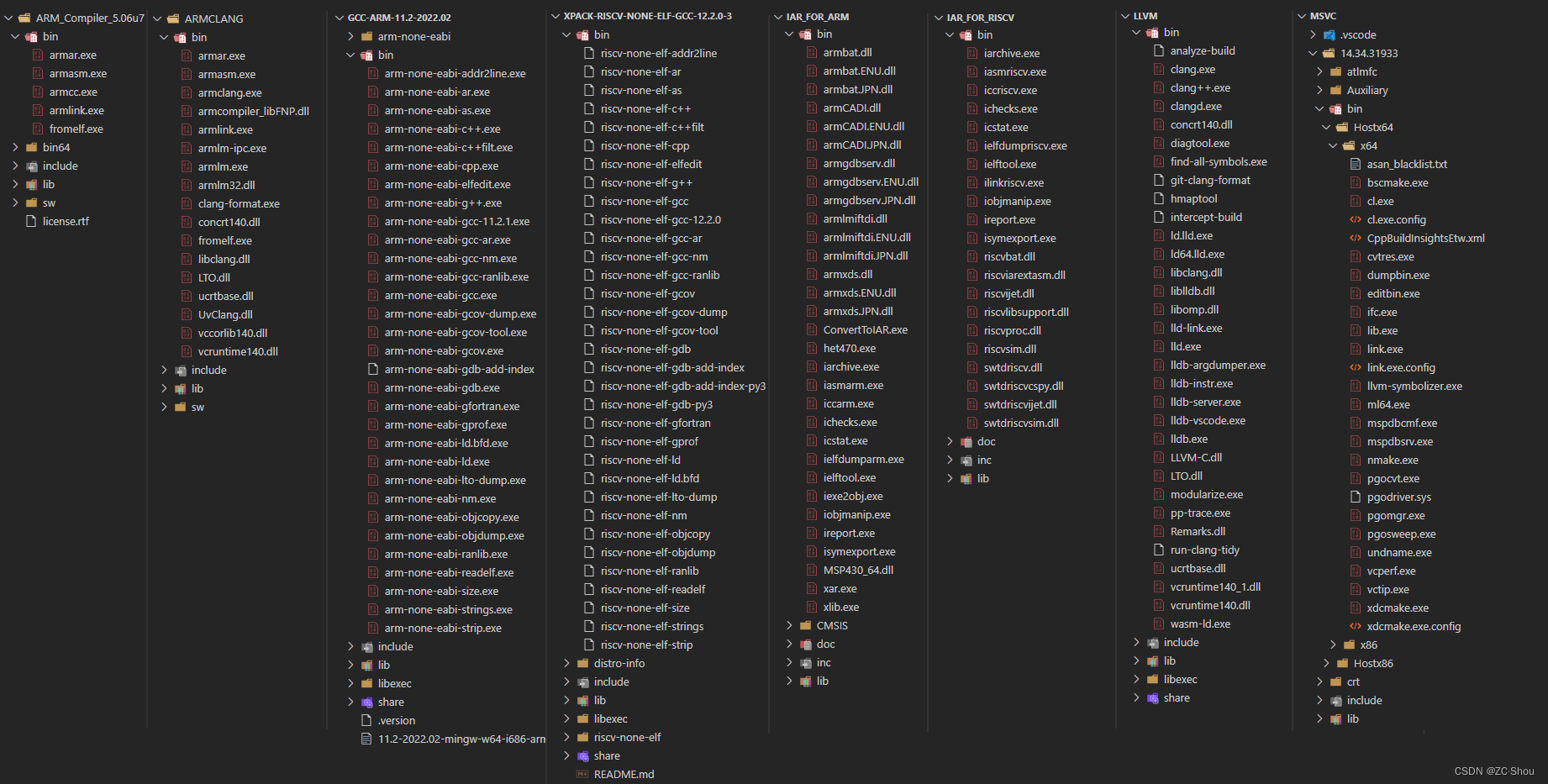
能独立提供编译工具链的厂家并不多,嵌入式平台则更少,主要就是 ARM、IAR、GNU、LLVM。其中,ARM、IAR 是收费的专用软件,其支持的架构有限,而 GNU 的 GCC 则是一款支持众多架构的开源编译套件;LLVM 则是后起之秀,同样也支持众多架构,目前用的不如 GCC 广泛!如下是常用编译工具链:
编译器
第一代编程语言的是汇编语言,因此,第一代编译器是编译汇编语言的。后来,高级语言逐步流行,但是编译工具链中仍然保留了高级语言到汇编语言这一步骤。而原来的汇编语言的编译器被称为汇编器,高级语言的编译器则就称为编译器。
链接器
高级语言诞生之后,源代码被有效组织为了不同的模块,分别实现在不同的文件中,编译器处理每个源文件,而连机器则负责将各个编译后的二进制文件合并为最终的可执行文件。
实用工具
除了编译器、链接器等工具,编译工具链中通常还会包含一些用来处理编译后二进制文件的辅助工具。例如,以 GCC 中的 objdump、readelf 为代表的的用来处理对象文件的工具。
标准库
标准库提供了一些通用函数的公共实现,绝大多数工具链都是提供一些预编译好的二进制文件(.o 文件),当我们编译自己的程序时,工具链自动以静态链接库的形式引入到我们的最终可执行程序中。这些公共实现的代码通过 include 中各头文件中的函数接口暴露给用户来引用。
通常这些预编译的文件还会被打包成 存档文件(.a 文件) 来提供(编译工具链中有相应工具来解析执行存档文件,例如,GCC 中的 ar)。
编译过程
要编译出最终的可执行程序,通常需要编译、链接、转换这三个阶段。其中,编译即编译器将源码翻译成对象文件,链接即链接器将各个对象文件组合成最终可执行程序。现代编译器通常产生一个通用格式(通常是带有调试信息)的最终可执行程序(ELF 文件),然后使用相应的工具从中提取出实际的纯可执行程序。
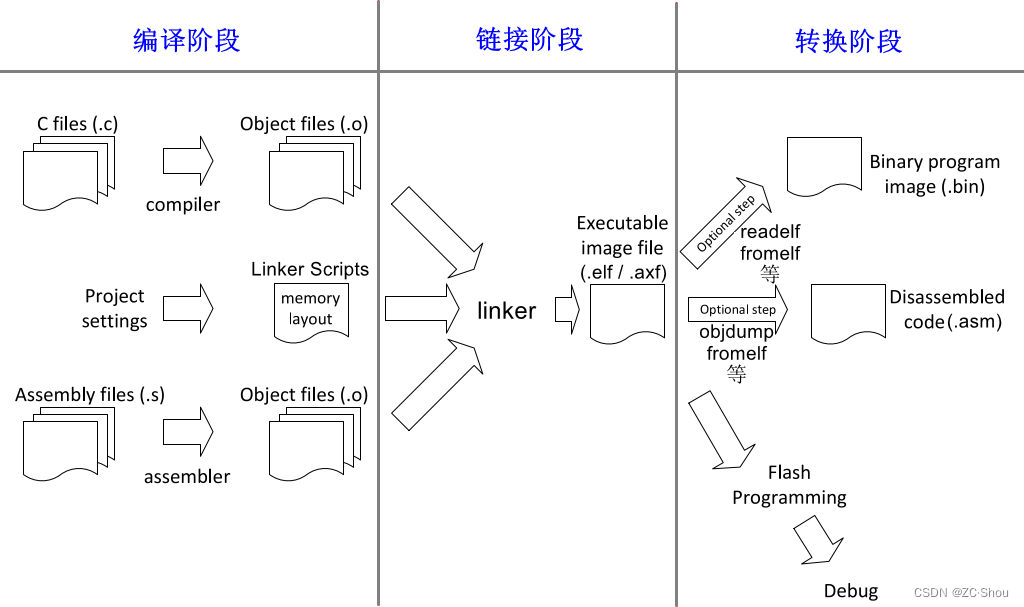
具体到编译器,其编译过程通常也是分为多个阶段的。在编译原理这门课程中,我们学过三段式编译器架构,其在编译时要依次经过词法分析、句法分析、语义分析、中间代码生成、代码优化、代码生成 六大阶段。
交叉编译
编译工具链产生可执行程序,但同时,编译工具链本身也是一个可执行程序。构建编译工具链本身时,构建编译工具链使用的平台、编译出的编译工具链运行的平台、使用编译出的编译工具链编译出的程序运行的平台三者可以完全不同。这三者就对应构建时设置 configure 的三个参数 --build、--host、--target。下图是 Windows 上的 MinGW 编译器配置信息:
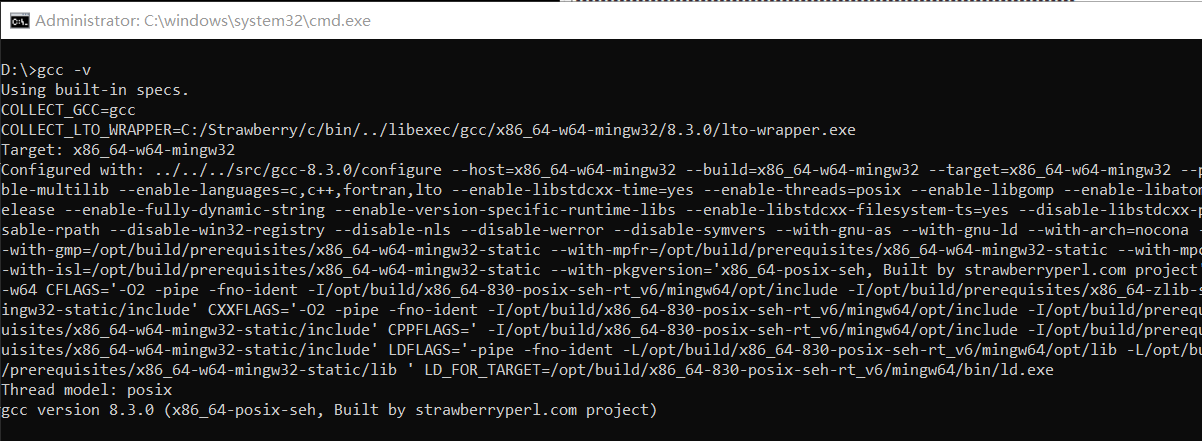
--build:这个参数指出了构建编译工具链使用的平台。如果我们不显示指定这个参数的值,那么这个参数的值就会由 config.guess 自动识别。
--host:这个参数指出了编译出的编译工具链运行的平台。这个参数的值一般就等于 --build 的值。
--target:这个参数指出了使用编译出的编译工具链编译出的程序运行的平台。
通常本地编译工具链一般就是指的 --build = --host = --target 的情况,交叉编译一般是--build = --host ≠ --target 的情况。不过,基本很少出现--build ≠ --host 的情况(例如,在 Linux 下构建 Windows 下运行的 GCC)。
交叉编译工具链
在当前平台下(例如 x86 架构的 PC)下,直接编译出来程序(或者库文件),其不可以直接在当前的平台运行(或使用),必须放到目标平台上(例如 ARM)才可以运行(或使用),这个过程就叫做交叉编译,使用的编译工具叫做交叉编译工具链。例如 PC 中的 armcc、iar、特定架构的 GCC、特定架构的 LLVM 等。
由于历史原因,我们说到交叉编译工具链通常就是指 GCC
交叉编译工具链又可以根据是否支持 Linux 系统分为 裸机程序交叉编译工具链 和 Linux 程序交叉编译工具链 这两大类。我们上面的举例中,armcc、iar 都属于裸机交叉编译工具链;而特定架构的 GCC、特定架构的 LLVM 则根据需要可以支持 Linux 系统,也可以不支持 Linux 系统,因此它既有裸机程序交叉编译工具链,也有 Linux 程序交叉编译工具链。
1.裸机程序交叉编译工具链不能编译 Linux 应用程序,但是,可以用于编译一些嵌入式实时操作系统(FreeRTOS、RT-Thread 等)
2.Linux 程序交叉编译工具链不止可以编译 linux 应用程序,也可以编译裸机程序
本地编译工具链
在当前平台(例如 x86 架构的 PC)下,直接编译出来程序(或者库文件),其可以直接在当前的平台运行(或使用)。这个过程就叫做本地编译,使用的编译工具叫做本地编译工具链(简称编译工具链)。例如 PC 上的 VC、GCC、LLVM、TCC 等。
The xPack Project
The xPack Project 是一个开源项目,其提供了一系列开发工具(重点是裸机下的 C/C++ 相关的)在不同平台的下的构建实例,其中就包含各平台的 GCC 交叉编译工具链,它使用一个多版本依赖管理器来管理各个实例。

实际开发中,我们经常会独立使用它提供的某些工具。例如,Eclipse 的嵌入式 C/C++ 插件 Eclipse Embedded CDT 就包含一些 xPack 提供的工具,以此来实现创建、构建、调试和管理 Arm 和 RISC-V 项目。
xPack Windows Build Tools:包括在 Windows 上执行构建所需的额外工具( make、rm 等)
xPack GNU Arm Embedded GCC:ARM 维护的官方 GNU ARM 嵌入工具链的一个代替,可以用于 Windows,MacOS和 GNU/Linux 平台。
xPack GNU RISC-V Embedded GCC:裸机 RISC-V GCC 发行版,由 SiFive 维护。Windows、macOS 和 GNU/Linux 都有可用的二进制文件。
xPack OpenOCD:OpenOCD 的一个新发行版,为更好/更方便地与 OpenOCD 调试插件集成而定制。Windows、macOS 和GNU/Linux 都有可用的二进制文件。
xPack QEMU Arm:QEMU(开源机器仿真器)的一个分支,旨在为 Eclipse Embedded CDT 中 的Cortex-M 仿真提供支持。Windows、macOS 和 GNU/Linux都有可用的二进制文件。
GCC
我们使用最多交叉编译工具链就是特定架构的 GNU 工具链,也就是常说的 GCC 交叉编译工具链。注意,armcc、iar 也属于交叉编译工具链,但一说起交叉编译工具链,大家往往首先想到的就是 GCC,例如,ARM 官方提供的 Arm GNU Toolchain。
随着开源运动的兴起,自由软件基金会开发了自己的开源免费的 C 语言编译器 GNU C Compiler,简称 GCC。GCC 中提供了 C Preprocessor 这个 C 语言的预处理器,简称 CPP。后来 GCC 又加入了对 C++ 等其它语言的支持,所以其名字也改为 GNU Compiler Collection。
命名规则
一般来说,交叉编译工具链的命名规则是:arch [-vendor] [-os] [-(gnu)abi]-*。但关于这个规则并没有找到在哪份官方资料上有介绍,实际有些交叉编译工具链也确实不符合上面的命名规则。
arch:表示编译工具链支持的体系架构,如 ARM、MIPS、RISC-V
vendor:表示工具链提供商,没有 vendor 时,用 none 代替。
os:表示工具链是有操作系统支持的,其编译出的程序可以在 os 给出的操作系统上运行,没有 os 支持时,也用 none 代替,表示裸机。如果同时没有 vendor 和 os 支持,则只用一个 none 代替。例如 arm-none-eabi 中的 none 表示既没有 vendor 也没有 os 支持。目前取值就只有以下两种:
none
1.C 库通常是 newlib
2.提供不需要操作系统的 C 库服务
3.允许为特定硬件目标提供基本系统调用
4.可以用来构建 Bootloader 或 Linux Kernel,不能构建 Linux 用户空间代码
linux
1.用于 Linux 操作系统的开发
2.linux 特有的 C 库的选择:glibc、uClibc-ng、musl
3.支持 Linux 系统调用
4.可以用来构建 Linux 用户空间代码,但也可以构建裸机代码,如 Bootloader 或 Linux Kernel
abi:应用二进制接口(Application Binary Interface)
1.eabi:嵌入式应用二进制接口(Embedded Application Binary Interface,EABI),这个是好像是 ARM 搞的一个标准,注意,AArch32 和 AArch64 的 EABI 并不相同。
2.gnu:这个其实是早期 GNU 针对 AArch32 架构使用的名字,后来改名字为 gnueabi。
3.gnueabi:其实就是嵌入式应用二进制接口(Embedded Application Binary Interface,EABI),只不过是 GNU 出品的。
4.elf:这个通常用在 64 位裸机架构的编译工具链中
由于 ARM 的绝对市场地位,导致了在网上搜索交叉编译工具链基本都和 ARM 有关系。这个命名规则就源自 ARM,其他架构提供的交叉编译工具链也基本是按照这个命名规则来命名的。
组成部分
GUN 交叉编译工具链中有三个核心组件:Binutils、GCC、C library,如果需要支持 Linux,则还有个 Linux kernel headers。在源代码组织上他们是相互独立的,需要单独进行交叉编译。
Binutils:GNU Binutils 是一个二进制工具的集合。
官网。
获取源代码:git clone git://sourceware.org/git/binutils-gdb.git 或者 https://ftp.gnu.org/gnu/binutils,
主要工具
ld:链接器
as:汇编器
gold:一个新的,更快的,ELF链接器。
调试/分析工具和其他工具
addr2line:将地址转换为文件名和行号。
ar:一个用于创建、修改、提取存档的实用工具
c++filt:过滤器要求编码的c++符号
dlltool:用于构建和使用 dll 的文件
elfedit:用于编辑 ELF 格式文件
gprof:显示分析信息
gprofng:收集和显示应用程序性能数据
nlmconv:将目标代码转换为 NLM
nm:列出目标文件中的符号
objcopy:复制和翻译目标文件
objdump:显示来自目标文件的信息
ranlib:生成归档文件内容的索引
readelf:显示来自任何ELF格式目标文件的信息
size:列出对象或存档文件的节大小
strings:列出文件中的可打印字符串
strip:丢弃符号
windmc:一个 Windows 兼容的消息编译器
windres:Windows 资源文件的编译器
需要针对每种 CPU 架构进行配置
gcc:GNU Compiler Collection
C、C++、Fortran、Go 等编译器前端
各种 CPU 架构的编译器后端
Provides:
1.编译器本身。例如 cc1 for C、cc1plus for C++
2.编译器调用程序。gcc、g++ 不但调用编译器本身,也调用 binutils 中的汇编器、连接器(不要被 gcc 这个名字误导,它其实是个 wrapper,会根据输入文件调用一系列其他程序。国外资料中被称为 compiler driver,国内有些资料称为引导器。)
3.目标库:libgcc(gcc 运行时)、libstdc ++(c ++ 库)、libgfortran(fortran运行时)
4.标准 c++ 库的头文件
构建 gcc 比构建 binutils 要复杂的多
Linux Kernel headers:构建需要支持 Linux 系统时必须提供。这些头文件定义了用户空间与内核之间的接口(系统调用、数据结构等)。
为了构建一个 C 库,需要 Linux 内核头文件中系统调用号的定义、各种结构类型和定义。
在内核中,头文件被分开:
1.用户空间可见的头文件,存储在 uapi 目录中:include/uapi/、arch/<ARCH>/include/uapi/asm
2.内部的内核头文件
在安装过程中需要使用
1.安装包括一个清理过程,用于从头文件中删除特定于内核的结构体
2.从 Linux 4.8 开始,安装 756 个头文件
3.内核到用户空间 ABI 通常是向后兼容的。Kernel headers 的版本必须等于或者小于目标 Linux 的版本
C library:
提供 POSIX 标准函数的实现,以及其他几个标准和扩展
基于 Linux 系统调用
几个可用的实现
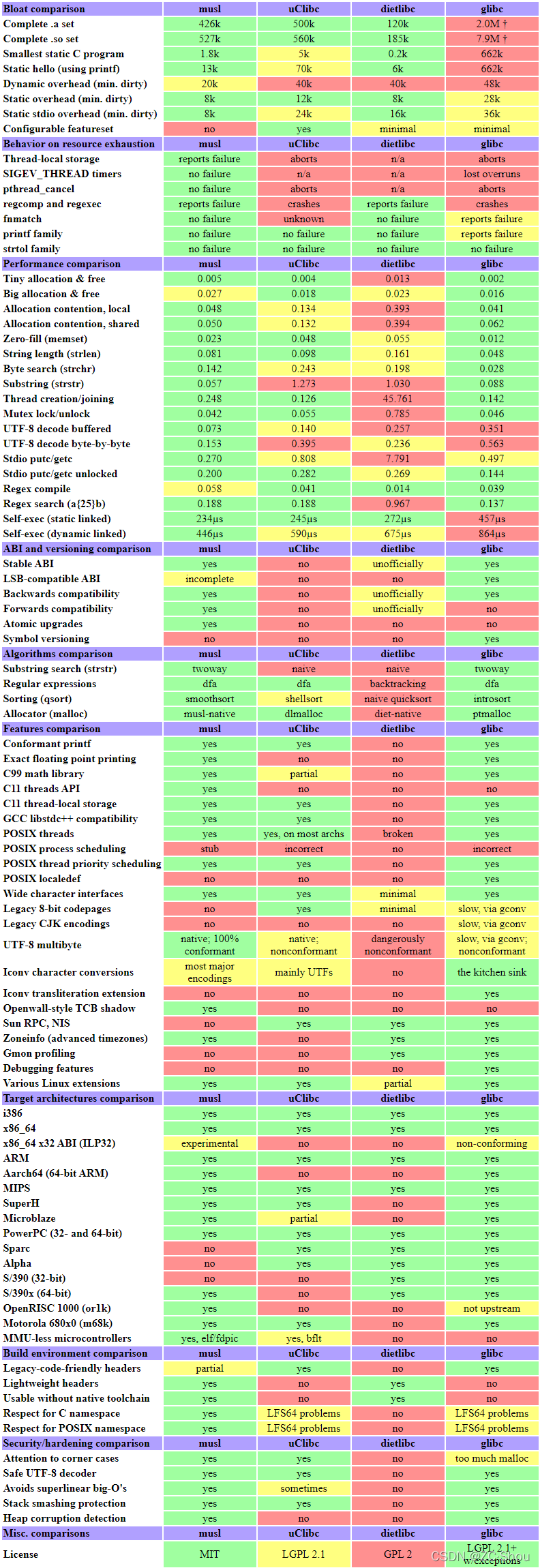
1.glibc:The GNU C Library 是 Linux C 库的事实标准,我们常见的 Linux 发行版中都使用它。支持众多的架构和操作系统,但是不支持没有 MMU 的平台,不支持静态链接。早些年由于硬件限制及 glibc 本身太大基本不能直接用于嵌入式,如今貌似也可以了。
2.uClibc-ng:以前叫 uClibc,始于 2000 年,支持非常灵活的配置。支持架构很多(包括一些 glibc 不支持的),但是仅支持 Linux 操作系统。支持多种没有 MMU 的架构,如 ARM noMMU、Blackfin 等,支持静态链接(STM32F MCU 没有 MMU,其嵌入式 Linux 环境中编译工具链就是用的它)。
3.musl:始于 2011 年,开发非常积极,最近添加了对于 noMMU 的支持。它非常小,尤其是在静态链接时。兼容性好,并且严格遵循 C 标准。
4.bionic:安卓系统使用。
5.其他一些特殊用途的:newlib(用于裸机)、dietlibc、klibc。
musl 的作者对于 Linux 常用的这几个库做了一个对比,以下是对比情况图:
在编译和安装之后,提供了:
1.动态链接器 ld.so
2.C 库本身 libc.so,及其配套库:libm、librt、libpthread、libutil、libnsl、libresolv、libcrypt
3.C 库的头文件:stdio.h、string.h 等等。
LLVM
LLVM 是一组工具链和编译器技术。回顾 GCC 的历史,虽然它取得了巨大的成功,但开发 GCC 的初衷是提供一款免费的开源的编译器,仅此而已。可后来随着 GCC 支持了越来越多的语言,其架构的问题也逐渐暴露出来。
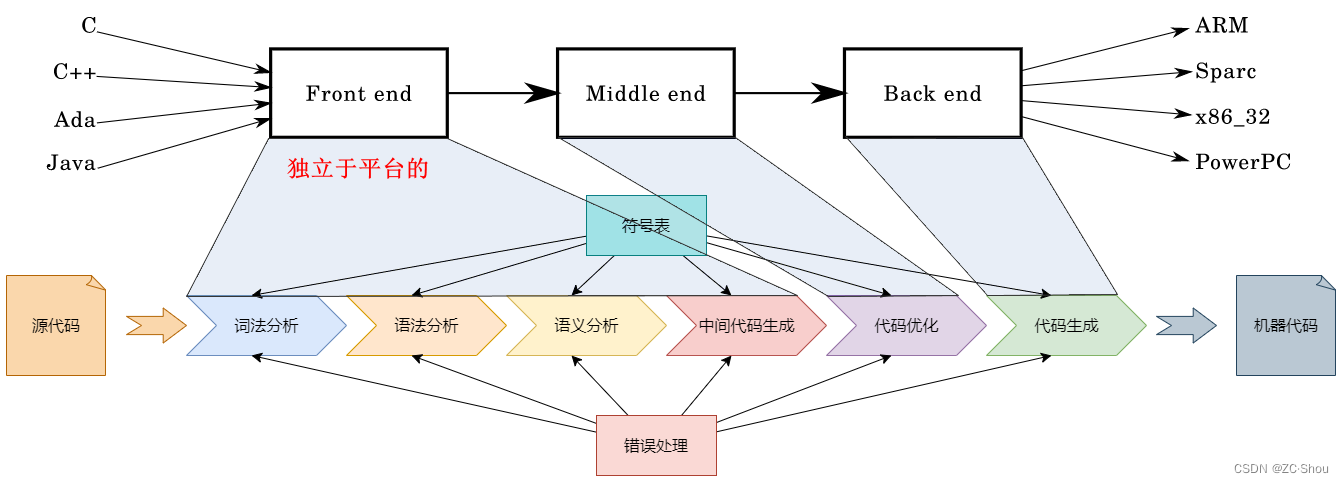
传统编译器的工作原理基本上都是三段式的,可以分为前端(Frontend)、优化器(Optimizer)、后端(Backend)。前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树(Abstract Syntax Tree);优化器对这一中间代码进行优化,试图使代码更高效;后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。
虽然这种三段式的编译器有很多优点,并且被写到了教科书中,但是在实际中这一结构却从来没有被完美实现过。
LLVM 作为后起之秀,从开始就是按照前端(Frontend)、优化器(Optimizer)、后端(Backend)的三段式进行设计,整个编译器框架非常符合人们对于编译器的设计以及非常容易理解和学习。LLVM 的在很大程度上兼容 GNU。
1.LLVM 的命名最早源自于底层虚拟机(Low Level Virtual Machine)的首字母缩写,但这个项目并不局限于创建一个虚拟机,开发者因而决定放弃这个缩写的意涵。现在 LLVM 是一个专用名词,表示编译器框架整个项目。
2.目前,很多平台都开始转投 LLVM 了,例如苹果、安卓、ARM 等等。
编译工具链之二 详解 ELF 格式及标准、UNIX 发展、ABI
在计算机及嵌入式系统中,二进制文件也有一定的标准格式,通常会包含在各平台的应用程序二进制接口 (Application Binary Interface,ABI)规范中。它是编译工具链必须要遵守的规范(编译工具链产生符合 ABI 的二进制文件)。
ABI
在计算机系统中,应用程序二进制接口 (Application Binary Interface,ABI)是一个二进制程序模块之间的标准接口规范,其定义了如何在机器代码中访问数据结构或计算机程序,这是一种低级的、硬件相关的格式。与之对应的应用层格式被称为 API,API 与 ABI 是保证兼容性的重要基础。
1.向后二进制兼容性(Backward binary compatibility,即 ABI 兼容性)保证使用旧版本库的程序在库升级为新版后仍可以正常运行,而无需重新编译。
2.向后源代码兼容性(Backward source compatibility,即 API 兼容性)保证旧程序更换为新版本的库时仍然可以成功地重新编译。
ABI 规范中一个重要部分就是定义二进制文件格式标准。现代计算机系统中流行的二进制文件格式主要有 Windows 下的 PE(Portable Executable) 、 Linux 的 ELF(Executable and Linking Format)可执行和链接格式) 以及 Apple 的 Mach-O(Mach object file format),以下是摘自维基百科的各种二进制格式:
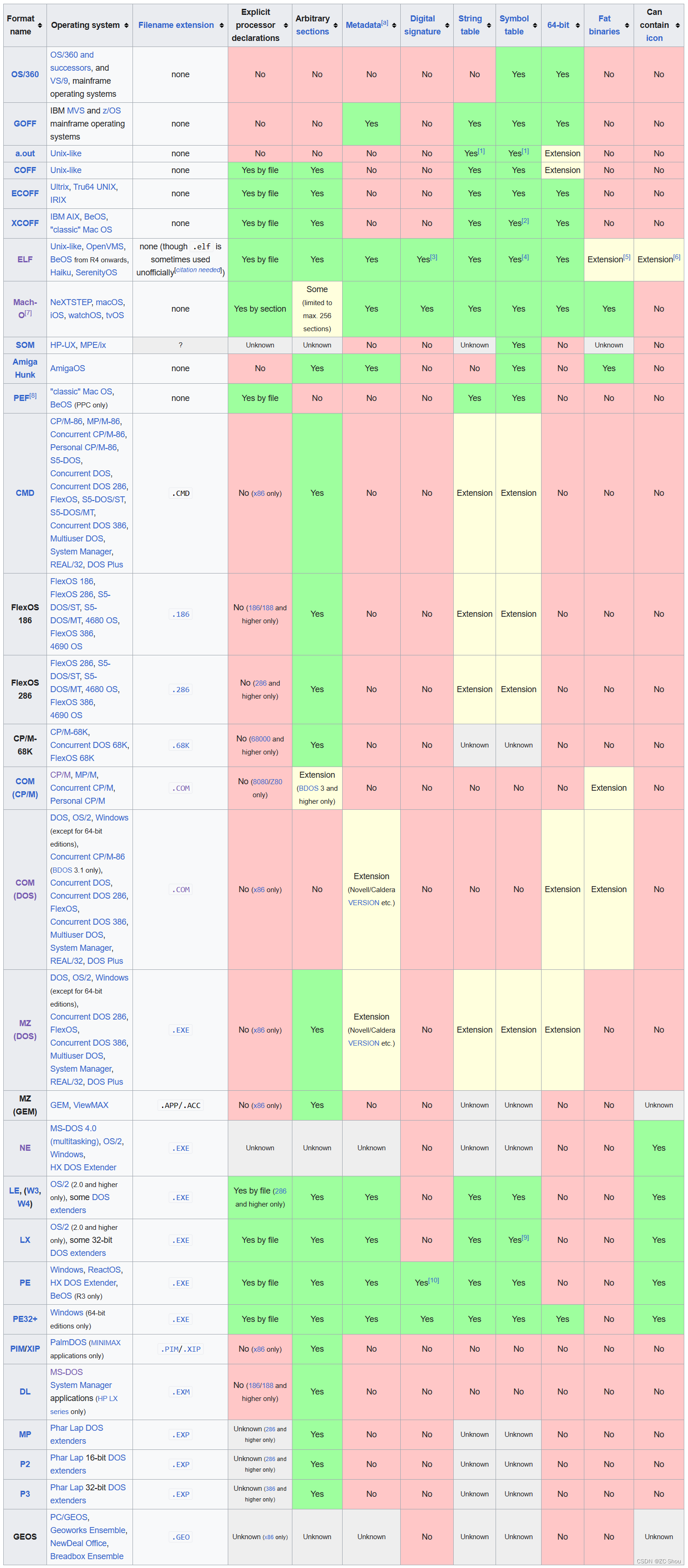
PE 和 ELF 都是 COFF(Common Object File Format)的变种,而 Mach-O 最初是为 NeXT 上使用的 Mach 微内核开发的。COFF 是在 1983 年发布 Unix System V 时由 UNIX 系统实验室(UNIX System Laboratories,USL)首先提出并且使用的文件规范。
1.1988 年发布 System V Release 4 时,UNIX 系统实验室在 COFF 的基础上,开发和发布了 ELF 格式,作为应用程序二进制接口 (Application Binary Interface,ABI)标准。
类 UNIX 系统:a.out ➔ COFF ➔ ELF
2.1993 年微软公司基于 COFF 格式,制定了 PE 格式标准,并将其用于当时的 Windows NT 3.1 系统。
DOS 系统:COM ➔ MZ ➔ NZ; Windows 系统: NZ➔ PE
3.1995 年 Linux 开始使用 ELF 文件标准
由于 ELF 在设计之初就是跨平台的通用二进制文件格式,随着 ELF 在类 Unix 系统中的普及,ELF 文件很快也成为了嵌入式中应用最多的二进制文件格式。例如,ARM、RISC-V 等架构都是在原始 ELF 标准结构的基础上扩展了自己的专用内容。
规范
ELF 原本是作为 System V Release 4 的一部分(第四章)发布的。此后不久,工具接口标准委员会(Tool Interface Standard Committee,TISC)就把 ELF 定义为了 Unix 系统的应用程序二进制接口 (Application Binary Interface,ABI)标准。现在可以在 Linux 基金会下属网站 上找到各个版本的标准文档。

TISC 共出过两个版本(v1.1和 v1.2)的标准文档。两个版本内容上差不多,但 v1.2 版本重新组织了原本在 v1.1 版本中的内容,可读性更高。两个版本的目录如下所示:
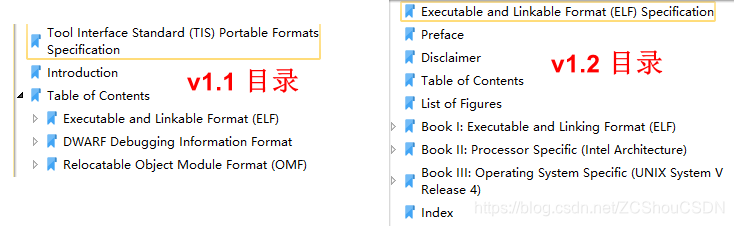
由于 TISC 的 v1.2 比较老旧,且后续没有再更新,尤其是在 64 位出现之后,原来的 ELF v1.2 已经不再适用,因此,System V 对 ELF v1.2 进行了扩展成为 System V ABI Edition 4.1 版本,并将其称为通用 ABI(Generic ABI,gABI)。
现在,类 Unix 系统都使用 System V 扩展的这个 System V ABI Edition 4.1 版本作为基础。从 System V ABI Edition 4.1 开始,ELF 标准实际上由两个基本部分组成:
1.通用部分(Generic ABI,gABI):描述了在 System V 的所有硬件实现中保持不变的接口部分。现在,gABI 由 SOC 公司负责维护,已经很多年不更新了,最终版停留在 10 June 2013
2.处理器特定部分(Processor Suppliment ABI,psABI):描述了规范的部分特定于特定的处理器架构。psABI 则是各个架构平台厂家独立维护,如下是常见架构平台的 psABI 下载地址:
x86-64 psABI:目前在 Gitlab 上维护,仓库地址 https://gitlab.com/x86-psABIs/x86-64-ABI
i386 psABI:目前在 Gitlab 上维护,仓库地址 https://gitlab.com/x86-psABIs/i386-ABI
ARM psABI:目前在 Github 上维护,仓库地址 https://github.com/ARM-software/abi-aa。注意,仓库中同时包含了 Aarch32 和 Aarch64 两架构的 psABI,它俩是不兼容。
RISC-V psABI:目前在 Github 上维护,仓库地址 https://github.com/riscv-non-isa/riscv-elf-psabi-doc
gABI 和 psABI 必须要组合使用,共同构成了完整的 ELF 标准。然而,有些架构平台(例如,ARM)的 psABI 文档中已经包含了 gABI 的部分,其中完整介绍了 ELF 相关内容。
UNIX
Unix 是一个多任务、多用户计算机操作系统家族,是第一个被广泛应用的操作系统。其设计思想被总结为 Unix 哲学,是一套针对极简主义、模块化软件开发的文化规范和哲学方法,对现代操作系统的设计有着重要意义!
最初的 Unix 开发于 1969 年的贝尔实验室研究中心,但是由于 AT&T 的垄断问题,美国政府禁止了 AT&T 自己直接出售 Unix,但可以将 Unix 授权给了政府、学术机构以及第三方公司,这就导致了出现了各种各样的 UNIX 系统(现在统一称为 类 Unix 系统)。
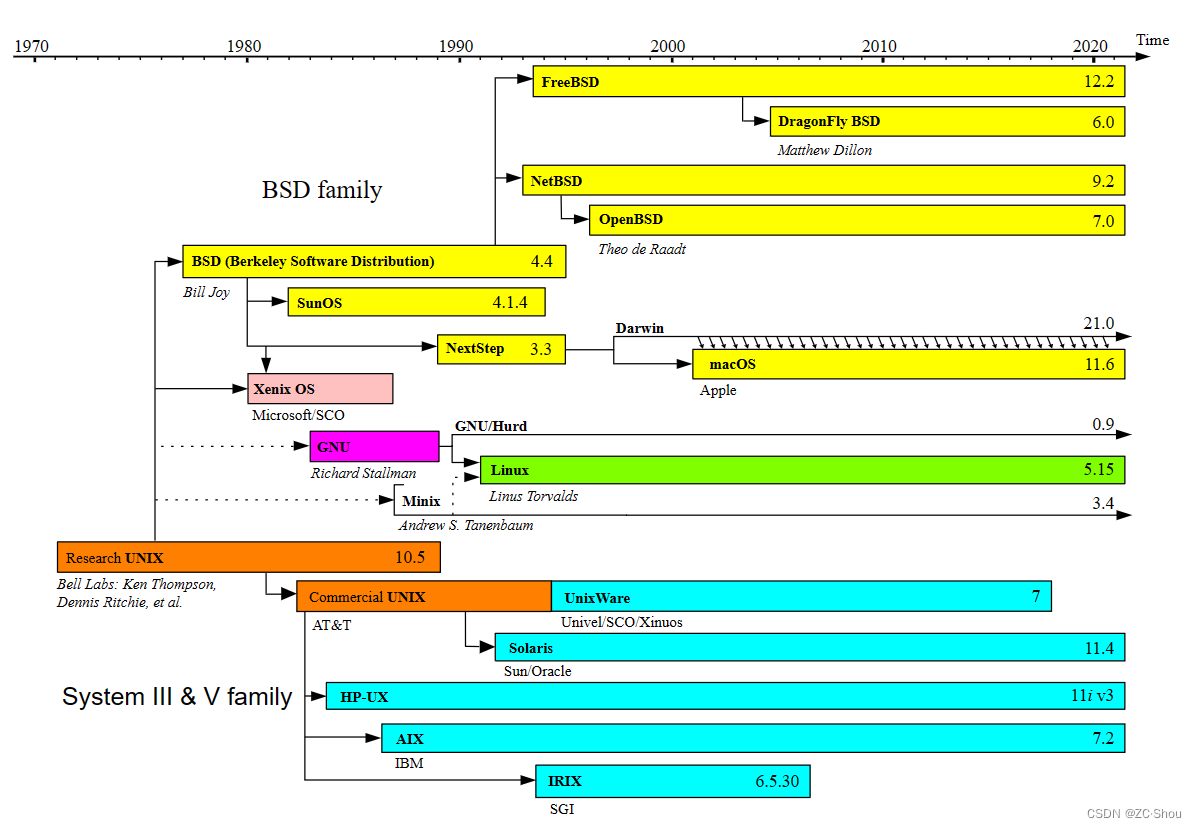
早期,UNIX System V 和 Berkeley Software Distribution (BSD,BSD Unix,Berkeley Unix) 是 UNIX 的两个主要版本。后来 AT&T 被拆解,1990 年代初,AT&T 将其 Unix 权利出售给 Novell,Novell 随后将 UNIX 商标出售给 The Open Group(一个成立于 1996 年的行业联盟)。
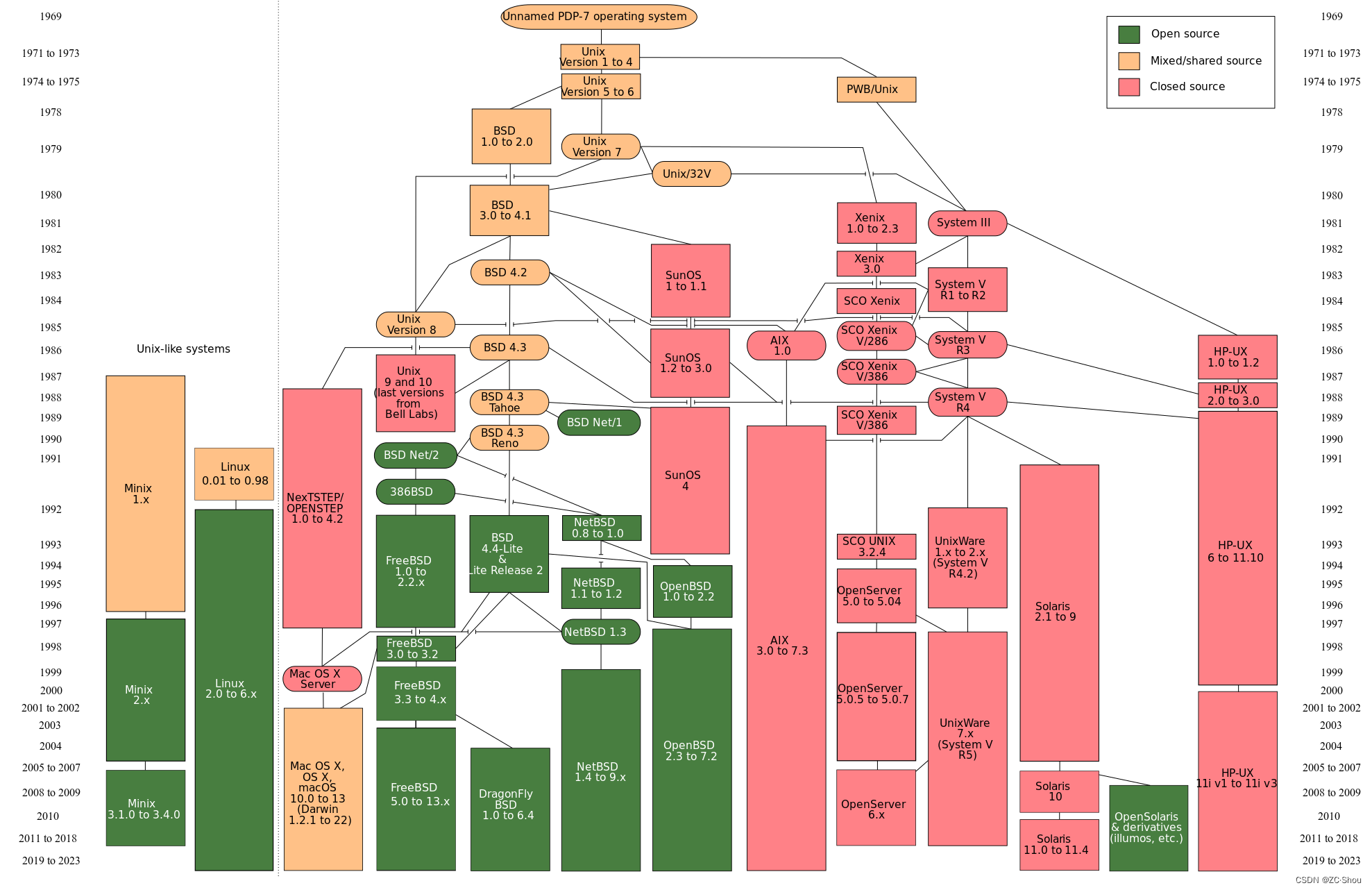
现在,The Open Group 负责认证符合单一 UNIX 规范(SUS)的操作系统,然后授权使用 UNIX 商标等权利。MacOS 和 Linux 均已通过 SUS 认证。
编译工具链
编译工具链要编译出最终的可执行程序,通常需要编译、链接、转换这三个阶段。其中,编译即编译器将源码翻译成对象文件(ELF 格式),链接即链接器将各个对象文件组合成最终可执行程序(ELF 格式)。
现代编译工具链通常产生一个 ELF 格式(通常是带有调试信息)的最终可执行程序,然后使用 ELF 处理工具从中提取出实际的纯可执行程序。目前,绝大多数编译工具链都提供一系列 ELF 文件处理实用工具。

ELF 文件
ELF(Executable and Linking Format)诞生于 UNIX 系统,后来称为了类 UNIX 系统(包括 Linux)中的二进制文件的规范。用于定义不同类型的对象文件(Object files)中都放了什么东西、以及都以什么样的格式去放这些东西。
在 ELF 文件规范中,通常把系统中采用 ELF 格式的二进制文件称为对象文件(Object File),并且归类为以下三种:
1.可重定位文件(Relocatable File ): 这类文件包含代码和数据,可用来连接成可执行文件或共享对象文件(Object File)
静态链接库归为此类,对应于 Linux 中的 .o ;Windows 的 .obj
2.可执行文件(Executable File ): 这类文件包含了可以直接执行的程序,它的代表就是 ELF 可执行文件。
Linux 下,他们一般没有扩展名,比如 /bin/bash;Windows 下的 .exe
3.共享对象文件(Object File)(Shared Object File ): 这种文件包含代码和数据,链接器可以使用这种文件跟其他可重定位的共享对象文件(Object File)链接,可用于产生新的对象文件(Object File)或可执行文件(Executable File )。
3.1.对应于 Linux 中的 .so,Windows 中的 DLL
3.2.动态链接器可以将几个这种共享对象文件(Object File)与可执行文件结合,作为进程镜像文件来运行。
在 Linux 系统中,还有一类文件,被称为核心转储文件(Core Dump File) ,当进程意外终止,系统可以将该进程地址空间的内容及终止时的一些信息转存到核心转储文件。 对应 Linux 下的 core dump。
视图
对象文件参与程序链接(构建程序)和程序执行(运行程序)。 为了方便和高效,ELF 中的对象文件(Object File)格式提供文件内容的不同视图,反映了这些活动的不同需求。 下图显示了对象文件(Object File)的组织。
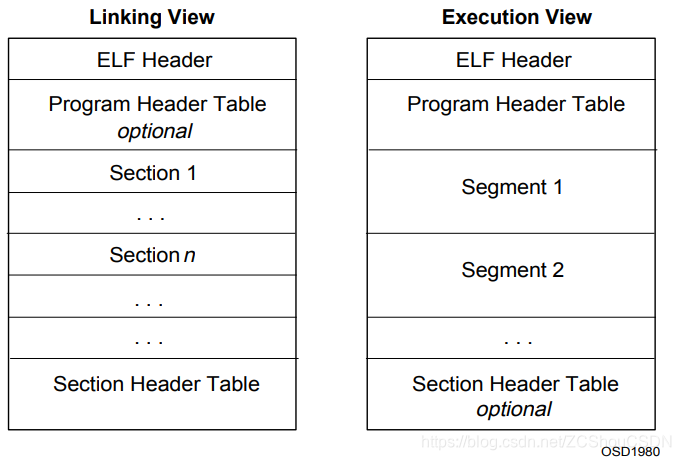
Program Header Table 在汇编和链接过程中没有用到,所以在重定位文件中可以没有;Section Header Table 中保存了所有 Section 的描述信息,Section Header Table 在加载过程中没有用到,对于可执行文件,可以没有该部分。当然,对于某些类型的文件(例如:shared objects)来说,可以同时拥有 Program header table 和 Section Header Table,这样 load 完后还可以重定位。
连接视图和执行视图在编译工具链的链接脚本文件中处理的重点。
数据表示法
对象文件(Object File)格式支持具有 8 位字节和 32 位体系结构的各种处理器。 然而,它旨在可扩展到更大(或更小)的体系结构。 因此,对象文件(Object File)用一种与机器无关的格式表示一些控制数据,从而可以识别对象文件(Object File)并以通用方式解释它们的内容。 目标处理器中的剩余数据使用目标处理器的编码,而不管创建文件的机器如何。出于可移植性的原因,ELF 不使用位字段。
| Name | Size | Alignment | Purpose |
|---|---|---|---|
| Elf32_Addr | 4 | 4 | Unsigned program address |
| Elf32_Half | 2 | 2 | Unsigned medium integer |
| Elf32_Off | 4 | 4 | Unsigned file offset |
| Elf32_Sword | 4 | 4 | Signed large integer |
| Elf32_Word | 4 | 4 | Unsigned large integer |
| unsigned char | 1 | 1 | Unsigned small integer |
对象文件格式定义的所有数据结构都遵循相关类别的自然大小和对齐准则。如果需要,数据结构包含显式填充,以确保 4 字节对象的 4 字节对齐,强制结构大小为 4 的倍数,以此类推。数据从文件开始也有适当的对齐。因此,例如,包含 Elf32_Addr 成员的结构将在文件中的 4 字节边界上对齐。
ELF Header
ELF Header 描述了体系结构和操作系统等基本信息,并指出 Section Header Table 和 Program Header Table 在文件中的什么位置。实际 ELF 文件中,只有 ELF Header 位置是绝对的,且只能在最开始的位置,其他部分的位置顺序并不固定。 ELF Header 可以使用如下数据结构表示:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT]; // Magic
Elf32_Half e_type; // Type
Elf32_Half e_machine; // Machine
Elf32_Word e_version; // Version
Elf32_Addr e_entry; // Entry point address
Elf32_Off e_phoff; // Start of program headers
Elf32_Off e_shoff; // Start of section headers
Elf32_Word e_flags; // Flags
Elf32_Half e_ehsize; // Size of this header
Elf32_Half e_phentsize; // Size of program headers
Elf32_Half e_phnum; // Number of program headers
Elf32_Half e_shentsize; // Size of section headers
Elf32_Half e_shnum; // Number of section headers
Elf32_Half e_shstrndx; // Section header string table index
} Elf32_Ehdr;
下面来详细介绍一下每个成员:
e_ident[EI_NIDENT],使用以下宏值进行索引:
| 名称 | 取值 | 意义 |
|---|---|---|
| EI_MAG0 | 0 | 文件标识 |
| EI_MAG1 | 1 | 文件标识 |
| EI_MAG2 | 2 | 文件标识 |
| EI_MAG3 | 3 | 文件标识 |
| EI_CLASS | 4 | 文件类 |
| EI_DATA | 5 | 数据编码 |
| EI_VERSION | 6 | 文件版本 |
| EI_PAD | 7 | 补齐字节开始处 |
| EI_NIDENT | 16 | e_ident[]大小 |
e_ident[EI_MAG0] ~ e_ident[EI_MAG3]:包含了 ELF 文件的魔数,依次固定是 0x7f 和 ‘E’、‘L’、‘F’。
e_ident[EI_CLASS]:取值如下
| 名称 | 取值 | 意义 | 架构 |
|---|---|---|---|
| ELFCLASSNONE | 0 | 非法类别 | 无 |
| ELFCLASS32 | 1 | 32 位目标 | AMD64 ILP32、AArch32、RV32 |
| ELFCLASS64 | 2 | 64 位目标 | AMD64 LP64、AArch64、RV64 |
e_ident[EI_DATA]:
| 名称 | 取值 | 意义 |
|---|---|---|
| ELFDATANONE | 0 | 非法数据编码 |
| ELFDATA2LSB | 1 | 高位在前(小端模式) |
| ELFDATA2MSB | 2 | 低位在前(大端模式) |
e_ident[EI_VERSION]:指定 ELF Header 的版本,当前必须为 1。
e_ident[7]~e_ident[15]:是填充符,通常是 0
e_type:标识对象文件类型。取值如下:
| 名称 | 取值 | 意义 |
|---|---|---|
| ET_NONE | 0 | 未知对象文件(Object File)格式 |
| ET_REL | 1 | 可重定位文件 |
| ET_EXEC | 2 | 可执行文件 |
| ET_DYN | 3 | 共享对象文件(Object File) |
| ET_CORE | 4 | Core 文件(转储格式) |
| ET_LOPROC | 0xff00 | 特定处理器文件 ET_LOPROC 和 ET_HIPROC 之间的取值用来标识与处理器相关的文件格式 |
| ET_HIPROC | 0xffff | 特定处理器文件 |
e_machine:指定单个文件所需的体系结构。取值如下:
| Name | Value | Meaning |
|---|---|---|
| EM_NONE | 0 | No machine |
| EM_M32 | 1 | AT&T WE 32100 |
| EM_SPARC | 2 | SPARC |
| EM_386 | 3 | Intel Architecture |
| EM_68K | 4 | Motorola 68000 |
| EM_88K | 5 | Motorola 88000 |
| EM_860 | 7 | Intel 80860 |
| EM_MIPS | 8 | MIPS RS3000 Big-Endian |
| EM_MIPS_RS4_BE | 10 | MIPS RS4000 Big-Endian |
| RESERVED | 11-16 | 保留以后使用 |
e_version:当前对象文件(Object File)的版本号。
| 名称 | 取值 | 意义 | 说明 |
|---|---|---|---|
| EV_NONE | 0 | Invalid version | |
| EV_CURRENT | 1 | Current version | 该项的取值可根据需要改变 |
e_entry:程序的虚拟地址入口点。在 ARM 中:
1.在可执行 ELF 文件中,e_entry 是镜像唯一入口点的虚拟地址,如果镜像没有唯一入口点,则为 0。
2.在可重定位ELF文件中,e_entry 是被 SHF_ENTRYSECT 所标记的段的入口点的偏移量,若没有入口点,则为 0。
3.Bit[0] = 1,表示 Thumb 指令;Bit[0:1] = 00,表示ARM指令;Bit[0:1] = 10,保留;
平台标准可以指定可执行文件总是具有入口点,在这种情况下,e_entry 指定入口点,即使为零。
e_phoff:该成员保存了 Program Header Table 的文件偏移量(以字节为单位)。如果文件没有 Program Header Table,则该成员值为零。
e_shoff:该成员保存了 Section Header Table 的文件偏移量(以字节为单位)。如果文件没有 Section Header Table,则该成员值为零。
e_flags:是一个与处理器相关联的标志。如下是 ARM 中的定义
| 名称 | 意义 |
|---|---|
| EF_ARM_ABIMASK (0xFF000000) (current version is 0x05000000) | 此 ELF 文件符合的 ARM EABI 的版本,该值为一个 8 比特的掩码。 当前 EABI 是版本5。0 表示未知符合 |
| EF_ARM_BE8 (0x00800000) | ELF 文件包含适合在 ARM Architecture v6 处理器上执行的 BE-8 代码。 该标志只能在可执行文件上设置 |
| EF_ARM_GCCMASK (0x00400FFF) | gcc-arm-xxx 生成的旧版代码(ABI 版本 4 及更早版本)可能会使用这些位 |
| EF_ARM_ABI_FLOAT_HARD (0x00000400) (ABI version 5 and later) | 设置可执行文件头(e_type = ET_EXEC 或 ET_DYN)以标注可执行文件的构建是为了符合硬件浮点过程调用标准。 与旧版(ABI 版本 5 之前)兼容,gcc 用作 EF_ARM_VFP_FLOAT |
| EF_ARM_ABI_FLOAT_SOFT (0x00000200) (ABI version 5 and later) | 设置在可执行文件头(e_type = ET_EXEC 或 ET_DYN)中明确标注可执行文件的构建符合软件浮点过程调用标准(基准标准)。 如果 EF_ARM_ABI_FLOAT_XXXX 位都清零,则默认符合基本过程调用标准。 与旧版(ABI 版本 5 之前)兼容,gcc 用作 EF_ARM_SOFT_FLOAT |
e_ehsize:该成员保存 ELF Header 的大小(以字节为单位)。
e_phentsize:该成员保存了 Program Header Table 中一个条目的字节大小,所有条目大小相同。
e_phnum: Program Header Table 中条目数量。如果文件没有 Section Header Table,则该成员值为零。
e_shentsize:该成员保存了 Section Header Table 中一个条目的字节大小,所有条目大小相同。
e_shnum:Section Header Table 中条目数量。如果文件没有 Section Header Table,则该成员值为零。
e_shstrndx:Section Header Table 中与节名称字符串表相关的表项的索引。如果文件没有节名称字符串表,此参数可以为 SHN_UNDEF。
Section Header
节头是位于对象文件(Object File)中的一个表,它提供了对 ELF 文件中所有节的访问。节中包含对象文件(Object File)中的所有信息,节满足以下条件:
1.对象文件(Object File)中的每个节都有对应的节头描述它,反过来,有节头不意味着有节。
2.每个节占用文件中一个连续字节域(这个区域可能长度为 0)。
3.文件中的节不能重叠,不允许一个字节存在于两个节中的情况发生。
4.对象文件(Object File)中可能包含非活动空间(INACTIVE SPACE)。这些区域不属于任何 头和节,其内容未指定。
ELF 头中,e_shoff 成员给出从文件头到节头表格的偏移字节数;e_shnum 给出节头表中条目数目;e_shentsize 给出每个项目的字节数。从这些信息中可以确切地定位节的具体位置、长度。节头表中比较特殊的几个下标如下:
| 名称 | 取值 | 说明 |
|---|---|---|
| SHN_UNDEF | 0 | 标记未定义的、缺失的、不相关的,或者没有含义的节引用 |
| SHN_LORESERVE | OxFF00 | 保留索引的下界 |
| SHN_LOPROC | 0xFF00 | 从此值到 SHN_HIPROC 保留给处理器特殊的语义 |
| SHN_HIPROC | 0XFF1F | 从 SHN_LOPROC 到此值保留给处理器特殊的语义 |
| SHN_ABS | 1 | 包含对应引用量的绝对取值。这些值不会被重定位所 影响 |
| SHN_COMMON | 2 | 相对于此节定义的符号是公共符号。如 FORTRAN 中 COMMON 或者未分配的 C 外部变量 |
| SHN_HIRESERVE | 保留索引的上界 |
注意,介于 SHN_LORESERVE 和 SHN_HIRESERVE 之间的表项不会出现在节头表中。Section Header 可以用如下数据结构描述(对应关系见注释):
typedef struct {
Elf32_Word sh_name; // name
Elf32_Word sh_type; // Type
Elf32_Word sh_flags; // Flg
Elf32_Addr sh_addr; // Addr
Elf32_Off sh_offset; // Off
Elf32_Word sh_size; // Size
Elf32_Word sh_link; // Lk
Elf32_Word sh_info; // Inf
Elf32_Word sh_addralign; // Al
Elf32_Word sh_entsize; // ES
} Elf32_Shdr;
sh_name:给出节名称。取值是节头字符串表节(Section Header String Table)的索引。String Table 中的名字是一个 NULL 结尾的字符串。ELF 文件规定一些标准节的名字,例如 .text、.data、.bss。
sh_type:为节的内容和语义进行分类。参见下表
| 名称 | 取值 | 含义 |
|---|---|---|
| SHT_NULL | 0 | 此值标志节头是非活动的,没有对应的节。此节头中的其他成员取值无意义 |
| SHT_PROGBITS | 1 | 此节包含程序定义的信息,其格式和含义都由程序来解释释 |
| SHT_SYMTAB | 2 | 此节包含一个符号表。目前对象文件(Object File)对每种类型的节都只能包含一个,不过这个限制将来可能发生变化。一般,SHT_SYMTAB 节提供用于链接编辑(指 ld而言) 的符号,尽管也可用来实现动态链接 |
| SHT_STRTAB | 3 | 此节包含字符串表。对象文件(Object File)可能包含多个字符串表节 |
| SHT_RELA | 4 | 此节包含重定位表项,其中可能会有补齐内容(addend),例如 32 位对象文件(Object File)中的 Elf32_Rela 类型。对象文件(Object File)可能拥有多个重定位节 |
| SHT_HASH | 5 | 此节包含符号哈希表。所有参与动态链接的目标都必须包含一个符号哈希表。目前,一个对象文件(Object File)只能包含一个哈希表, 不过此限制将来可能会解除 |
| SHT_DYNAMIC | 6 | 此节包含动态链接的信息。目前一个对象文件(Object File)中只能包含一个动态节,将来可能会取消这一限制 |
| SHT_NOTE | 7 | 此节包含以某种方式来标记文件的信息 |
| SHT_NOBITS | 8 | 这种类型的节不占用文件中的空间,其他方面和 SHT_PROGBITS 相似。尽管此节不包含任何字节,成员sh_offset 中还是会包含概念性的文件偏移 |
| SHT_REL | 9 | 此节包含重定位表项,其中没有补齐(addends),例如 32 位对象文件(Object File)中的 Elf32_rel 类型。对象文件(Object File)中可以拥有多个重定位节 |
| SHT_SHLIB | 10 | 此节类型是保留的,但具有未指定的语义。包含这种类型的节的程序不符合 ABI |
| SHT_DYNSYM | 11 | 这些节保存一个符号表 |
| SHT_LOPROC | 0x70000000 | 这个范围内的值为特定于处理器的语义保留。见各架构的 psABI |
| SHT_HIPROC | 0x7fffffff | 这个范围内的值为特定于处理器的语义保留。见各架构的 psABI |
| SHT_LOUSER | 0x80000000 | 该值指定了为应用程序保留的索引范围的下限 |
| SHT_HIUSER | 0xffffffff | 此值指定为应用程序保留的索引范围的上限。应用程序可以使用 SHT_LOUSER 和 SHT_HIUSER 之间的节类型,而不与当前或未来系统定义的节类型冲突 |
除了以上标准节类型外,ARM 架构下,还有以下特殊的类型:
| 名称 | 取值 | 含义 |
|---|---|---|
| SHT_ARM_EXIDX | 0x70000001 | 异常索引表 |
| SHT_ARM_PREEMPTMAP | 0x70000002 | BPABI DLL动态链接抢占地图 |
| SHT_ARM_ATTRIBUTES | 0x70000003 | 对象文件兼容性属性 |
| SHT_ARM_DEBUGOVERLAY | 0x70000004 | |
| SHT_ARM_OVERLAYSECTION | 0x70000005 |
sh_flags:字段定义了一个节中包含的内容是否可以修改、是否可以执行等信息。如果一个标志比特位被设置,则该位取值为 1。未定义的各位都设置为 0。
| 名称 | 取值 | 含义 |
|---|---|---|
| SHF_WRITE | 0x1 | 节包含进程执行过程中将可写的数据 |
| SHF_ALLOC | 0x2 | 此节在进程执行过程中占用内存。某些控制节并不出现于目标 文件的内存映像中,对于那些节,此位应设置为 0 |
| SHF_EXECINSTR | 0x4 | 节包含可执行的机器指令 |
| SHF_MASKPROC | 0xF0000000 | 所有包含于此掩码中的四位都用于处理器专用的语义 |
ARM 中的特殊取值如下:
| Name | Value | Purpose |
|---|---|---|
| SHF_ARM_NOREAD | 0x20000000 | 本节的内容不应由程序执行者读取 |
sh_addr:如果节将出现在进程的内存镜像中,此成员给出节的第一个字节应处的位置。否则,此字段为 0。
sh_link 和 sh_info:根据节类型的不同,sh_link 和 sh_info 的具体含义也有所不同。ARM 取值如下:
| sh_type | sh_link | sh_info |
|---|---|---|
| SHT_SYMTAB, SHT_DYNSYM | 相关联的字符串表的节头索引 | 最后一个局部符号(绑定 STB_LOCAL)的符号表索引值加一 |
| SHT_DYNAMIC | 此节中条目所用到的字符串表格 的节头索引 | 0 |
| SHT_HASH | 此哈希表所适用的符号表的节头索引 | 0 |
| SHT_REL、SHT_RELA | 相关符号表的节头索引 | 重定位所适用的节的节头索引 |
| 其它 | SHN_UNDEF | 0 |
sh_addralign:节没有最小对齐要求。 但是,包含 thumb 代码的部分必须至少为 16 位对齐,并且包含 ARM 代码的部分必须至少为 32 位对齐。具有 SHF_ALLOC 属性的任何节必须满足 sh_addralign >= 4。其他节可根据需要对齐。 例如,调试表通常没有对齐要求。并且输入到静态链接器的数据段可以自然对齐。平台标准可能会限制他们可以保证的最大对齐(通常是页面大小)。
sh_entsize:某些节中包含固定大小的项目,如符号表。对于这类节,此成员给出每个表项的长度字节数。如果节中并不包含固定长度表项的表格,此成员取值为 0。
sh_size:此成员给出本节的长度(字节数)。除非节的类型是 SHT_NOBITS,否则节占用文件中的 sh_size 字节。类型为 SHT_NOBITS 的节长度可能非零,不过却不占用文件中的空间。
sh_offset:此成员的取值给出节的第一个字节与文件头之间的偏移。不过,SHT_NOBITS 类型的节不占用文件的空间,因此其 sh_offset 成员给出的是其概念性的偏移。
Special Sections
ELF 定义了一些具体特定意义的 Section,如下表所示:
| 节前缀名 | 节类型 | 节属性 | 解释 |
|---|---|---|---|
| .bss | SHT_NOBITS | SHF_ALLOC+SHF_WRITE | 本节保存有助于程序内存映像的未初始化数据。 根据定义,当程序开始运行时,系统将使用零初始化数据。 该部分不占用文件空间,如段类型 SHT_NOBITS 所示 |
| .comment | SHT_PROGBITS | None | 本节包含版本控制信息 |
| .data | SHT_PROGBITS | SHF_ALLOC+SHF_WRITE | 这些部分保存有助于程序内存映像的已初始化数据 |
| .data1 | SHT_PROGBITS | SHF_ALLOC+SHF_WRITE | |
| .debug… | SHT_PROGBITS | None | 本节保存符号调试信息。 内容未指定。 具有前缀.debug的所有段名保留供将来使用 |
| .dynamic | SHT_DYNAMIC | SHF_ALLOC [+SHF_WRITE] | 本节保存动态链接信息,并具有SHF_ALLOC和SHF_WRITE等属性。 操作系统和处理器确定SHF_WRITE位是否被置位 |
| .hash | SHT_HASH | [SHF_ALLOC] | 本节包含一个符号哈希表 |
| .line | SHT_PROGBITS | None | 本节保存符号调试的行号信息,其中描述了源程序和机器代码之间的对应关系。 内容未指定 |
| .rodata | SHT_PROGBITS | SHF_ALLOC | 这些部分保存通常有助于过程映像中的不可写段的只读数据 |
| .rodata1 | SHT_PROGBITS | SHF_ALLOC | |
| .rel name .rela name | SHT_REL SHT_RELA | [SHF_ALLOC] | 这些节中包含了重定位信息。如果文件中 包含可加载的段,段中有重定位内容,节 的属性将包含 SHF_ALLOC 位,否则该位 置 0。传统上 name 根据重定位所适用的节 区给定。例如 .text 节的重定位节名字,将是:.rel.text 或者 .rela.text |
| .shstrtab | SHT_STRTAB | None | 本节保存节名称 |
| .strtab | SHT_STRTAB | [SHF_ALLOC] | 此节包含字符串,通常是代表与符号表项 相关的名称。如果文件拥有一个可加载的 段,段中包含符号串表,节的属性将包含 SHF_ALLOC 位,否则该位为 0 |
| .symtab | SHT_SYMTAB | [SHF_ALLOC] | 此节包含一个符号表。如果文件中包含一 个可加载的段,并且该段中包含符号表,那 么节的属性中包含SHF_ALLOC 位,否则 该位置为 0 |
| .text | SHT_PROGBITS | SHF_ALLOC+ SHF_EXECINSTR | 本节包含程序的文本或可执行指令 |
注意:
1.保留给处理器体系结构的节名称一般构成为:处理器体系结构名称简写 + 节名称。且处理器名称应该与 e_machine 中使用的名称相同
2.对象文件(Object File)中也可以包含多个名字相同的节。
3.除了以上标准节外,ARM 架构下还有以下特殊的节:
| 节前缀名 | 节类型 | 节属性 | 说明 |
|---|---|---|---|
| .ARM.exidx* | SHT_ARM_EXIDX | SHF_ALLOC + SHF_LINK_ORDER | 以.ARM.exidx开头的节包含部分展开的索引条目 |
| .ARM.extab* | SHT_PROGBITS | SHF_ALLOC | 以.ARM.extab开头的节包含异常展开信息的名称部分 |
| .ARM.preemptmap | SHT_ARM_PREEMPTMAP | SHF_ALLOC | 以.ARM.preemptmap开头的节包含一个BPABI DLL动态链接优先地图 |
| .ARM.attributes | SHT_ARM_ATTRIBUTES | none | 包含构建属性 |
| .ARM.debug_overlay | SHT_ARM_DEBUGOVERLAY | none | |
| .ARM.overlay_table | SHT_ARM_OVERLAYSECTION | See DBGOVL for details |
这里需要注意一下 Debug Sections。Debug Sections 仅在调试时使用,稍微复杂一些。ARM 可执行 ELF 文件的调试节中包含多种类型的调试信息,ELF 可执行文件的使用者(如armlink)可以通过检查可执行文件的节表来区分这些种类型的调试信息。
ARM 系列的开发工具在不同的发展时期,采用的调试信息是有区别的,后来统一采用 DWARP。目前采用的应该是 3.0 版本。关于DWARF调试标准详见:http://www.dwarfstd.org/。目前最新版本是 The DWARF Debugging Standard Version 5。
ASD debugging tables:它们提供了与 ARM 的符号调试器的向后兼容性。ASD 调试信息存储在可执行文件中名为 .ASD 的单个 Section 中。
DWARP version 1.0:当链接器在 ELF 可执行文件中包含 DWARF 1.0 调试信息时,该文件包含以下 ELF 节,每个节都有一个节头表项:
| Section name | Contents |
|---|---|
| .debug | debugging entries |
| .line | fileinfo entries |
| .debug_pubnames | table for accelerated access to debug items |
| .debug_aranges | address ranges for compilation units |
DWARF version 2.0:当链接器在 ELF 可执行文件中包含 DWARF 2.0 调试信息时,该文件包含以下 ELF 节,每个节都有一个节头表项:
| Section name | Contents |
|---|---|
| .debug_info | debugging entries |
| .debug_line | fileinfo statement program |
| .debug_pubnames | table for accelerated access to debug items |
| .debug_aranges | address ranges for compilation units |
| .debug_macinfo | macro information (#define / #undef) |
| .debug_frame | call frame information |
| .debugj_abbrev | abbreviation table |
| .debug_str | debug string table |
Program Headers
可执行文件或者共享对象文件(Object File)的程序头是一个结构数组,每个结构描述了一个段或者系统准备程序执行所必需的其它信息。对象文件(Object File)的 “段” 包含一个或者多个 “节”,也就是"段内容(Segment Contents)"。程序头仅对于可执行文件和共享对象文件(Object File)有意义。程序头可以使用如下数据结构来表示(对应关系见注释):
typedef struct {
Elf32_Word p_type; // Type
Elf32_Off p_offset; // Offset
Elf32_Addr p_vaddr; // VirtAddr
Elf32_Addr p_paddr; // PhyAddr
Elf32_Word p_filesz; // FileSiz
Elf32_Word p_memsz; // MemSiz
Elf32_Word p_flags; // Flg
Elf32_Word p_align; // Align
} Elf32_Phdr;
p_type:这个成员告诉这个数组元素描述什么样的段,或者如何解释数组元素的信息。 类型值及其含义如下图所示。
| 名称 | 取值 | 意义 |
|---|---|---|
| PT_NULL | 0 | 数组元素未使用; 其他成员的值是未定义的。 此类型使程序头表已忽略条目 |
| PT_LOAD | 1 | 数组元素指定由p_filesz和p_memsz描述的可加载段 |
| PT_DYNAMIC | 2 | 数组元素指定动态链接信息 |
| PT_INTERP | 3 | 数组元素指定要作为解释器调用的以空值结尾的路径名的位置和大小 |
| PT_NOTE | 4 | 数组元素指定辅助信息的位置和大小 |
| PT_SHLIB | 5 | 该段类型是保留的,但具有未指定的语义 |
| PT_PHDR | 6 | 数组元素(如果存在)指定程序头表本身的位置和大小 |
| PT_ARM_ARCHEXT | 0x70000000 | Platform architecture compatibility information |
| PT_ARM_EXIDX PT_ARM_UNWIND | 0x70000001 | Exception unwind tables |
p_offset:此成员给出从文件头到该段第一个字节的偏移
p_vaddr:此成员给出段的第一个字节将被放到内存中的虚拟地址。
p_paddr:此成员仅用于与物理地址相关的系统中。因为 System V 忽略所有应用程序的物理地址信息,此字段对与可执行文件和共享对象文件(Object File)而言,具体内容是未指定的。
p_filesz:此成员给出段在文件镜像中所占的字节数。可以为 0。
p_memsz: 此成员给出段在内存镜像中占用的字节数。可以为 0。
p_flags:此成员给出与段相关的标志。
| 名称 | 取值 | 意义 |
|---|---|---|
| PF_X | 1 | 可执行的段 |
| PF_W | 2 | 可写的段 |
| PF_R | 4 | 可读的段 |
| PF_MASKPROC | 0xf0000000 | 保留 |
p_align:可加载的进程段的 p_vaddr 和 p_offset 取值必须合适,相对于对页面大小的取模而言。此成员给出段在文件中和内存中如何 对齐。数值 0 和 1 表示不需要对齐。否则 p_align 应该是个正整数,并且是 2 的幂次数,p_vaddr 和 p_offset 对 p_align 取模后应该相等。
Symbol table
一个对象文件的符号表保存了定位和重定位所在程序的符号定义和引用所需的信息。符号表以数组的下标进行索引。0 指定表中的第一个条目,并用作未定义的符号索引。符号表可以使用以下数据结构表示:
typedef struct {
Elf32_Word st_name; // Name
Elf32_Addr st_value; // Value
Elf32_Word st_size; // Size
unsigned char st_info; //
unsigned char st_other;
Elf32_Half st_shndx; // Ndx
} Elf32_Sym;
st_name:该成员将对象文件(Object File)的符号字符串表中的索引保存在符号名称的字符表示中
st_value:该成员给出相关联的符号的值。 根据上下文,这可能是绝对值,地址等等; 不同对象文件(Object File)类型的符号表条目对 st_value 成员的解释略有不同。
1.在可重定位文件中,st_value 保持其索引为 SHN_COMMON 的符号的对齐约束。
2.在可重定位文件中,st_value 包含已定义符号的节偏移量。 也就是说,st_value 是 st_shndx 标识的部分开头的偏移量。
3.在可执行文件和共享对象文件中,st_value 包含虚拟地址 1。 为了使这些文件的符号对动态链接器更有用,段偏移(文件解释)让位于与段号无关的虚拟地址(存储器解释)。
st_size:许多符号具有相关尺寸。 例如,数据对象的大小是对象中包含的字节数。 如果符号没有大小或未知的大小,该成员将保持0。
st_info:该成员指定符号的类型和绑定属性。 值和值的列表如下面两个表格所示。 以下代码显示了如何操作这些值。
#define ELF32_ST_BIND(i) ((i)>>4)
#define ELF32_ST_TYPE(i) ((i)&0xf)
#define ELF32_ST_INFO(b,t) (((b)<<4)+((t)&0xf))
符号的绑定决定了链接的可见性和行为。
| Name | Value | Meaning |
|---|---|---|
| STB_LOCAL | 0 | 局部符号在包含其定义的目标文件之外是不可见的。相同名称的局部符号可以存在于多个文件中而互不干扰 |
| STB_GLOBAL | 1 | 全局符号对于被组合的所有目标文件都是可见的。一个文件对全局符号的定义将满足另一个文件对同一全局符号的未定义引用 |
| STB_WEAK | 2 | 弱符号类似于全局符号,但它们的定义优先级较低 |
| STB_LOPROC | 13 | |
| STB_HIPROC | 15 | 这个范围内的值为特定于处理器的语义保留。如果指定了含义,则处理器补充解释它们。 |
在每个符号表中,所有带有 STB_LOCAL 绑定的符号都位于弱符号和全局符号之前。符号的类型提供了关联实体的一般分类。
| Name | Value | Meaning |
|---|---|---|
| STT_NOTYPE | 0 | 没有指定符号的类型 |
| STT_OBJECT | 1 | 符号与数据对象相关联,例如变量、数组等 |
| STT_FUNC | 2 | 该符号与函数或其他可执行代码相关联 |
| STT_SECTION | 3 | 符号与节相关联。这种类型的符号表项主要用于重定位,通常具有STB_LOCAL绑定 |
| STT_FILE | 4 | 一个具有 STB_LOCAL 绑定的文件符号,它的 section 索引是 SHN_ABS,并且它位于该文件的其他 STB_LOCAL 符号之前(如果它存在的话) |
| STT_LOPROC | 13 | 这个范围内的值为特定于处理器的语义保留。如果一个符号的值指向一个节中的特定位置,那么它的节索引成员st_shndx保存着一个节头表的索引。当区段在重定位过程中移动时,符号的值也会发生变化,对符号的引用将继续指向程序中的相同位置。一些特殊的节索引值给出了其他语义 |
| STT_HIPROC | 15 |
st_other:该成员目前只有 0,没有定义。
st_shndx:每个符号表条目与某些部分有关"定义"; 该成员保存相关部分标题表索引。
在 C 语言中,符号表保存了程序实现或使用的所有全局变量和函数,如果程序引用一个自身代码未定义的符号,则称之为未定义符号,这类引用必须在静态链接期间用其他目标模块或库解决,或在加载时通过动态链接解决。
String table
字符串表节包含以 NULL(ASCII 码 0)结尾的字符序列,通常称为字符串。ELF 对象文件(Object File)通常使用字符串来表示符号和节名称。对字符串的引用通常以字符串在字符串表中的下标给出。
第一个字节,即索引 0,被定义为保存空字符。同样,字符串表的最后一个字节被定义为保存空字符,以确保所有字符串的空终止。索引为 0 的字符串指定无名称或空名称,具体取决于上下文。允许使用空字符串表段,它的 section 头的 sh_sIze 成员将包含零。对于空字符串表,非零索引无效。
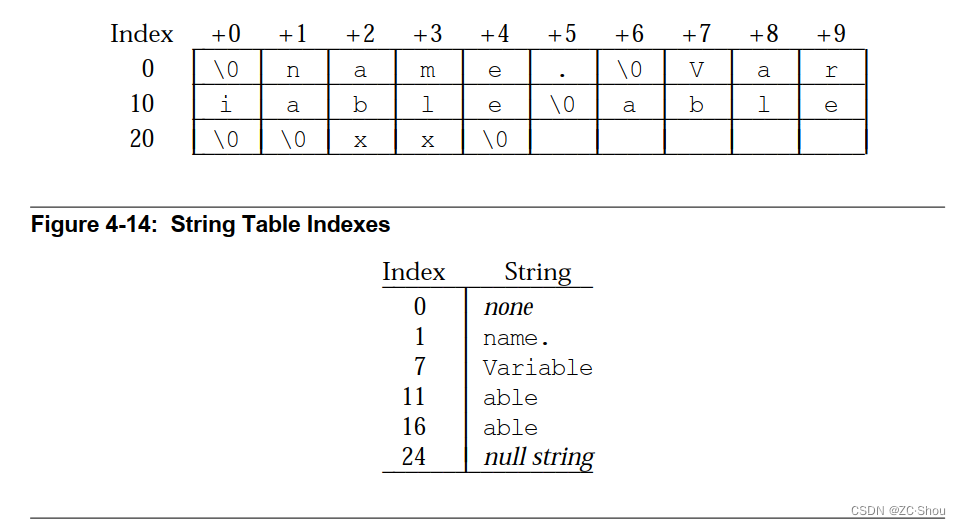
如上图所示,字符串表索引可以引用节中的任何字节。一个字符串可以出现多次;可能存在对子字符串的引用;一个字符串可以被多次引用。也允许使用未引用的字符串。
编译工具链之三 ARM-MDK、IAR、GCC 的 .MAP 文件、.LST 文件
本节介绍了.map 和 .lst 文件在嵌入式开发中的作用,特别是针对RISC-V架构和GCC编译工具链。.map文件提供了链接阶段的详细信息,包括内存映射、全局符号和丢弃的输入段,而 .lst 文件则包含更详细的汇编程序列表数据,有助于调试。
.map 文件和 .lst 文件是嵌入式开发中最有用的俩调试辅助文件。现在主要从事 RISC-V 架构,主要与 GCC 打交道,在此就重点学习一下 GCC 的 .map 文件、.lst 文件,并辅助以 ARMCC 和 IAR 作为对比。
编译
.map 文件和 .lst 文件就是编译工具链给出的构建过程的一些 LOG 文件。要编译出最终的可执行程序,通常需要编译、链接、转换这三个阶段。其中,编译即编译器将源码翻译成对象文件,链接即链接器将各个对象文件组合成最终可执行程序。现代编译器通常产生一个通用格式(通常是带有调试信息)的最终可执行程序(ELF 文件),然后使用相应的工具从中提取出实际的纯可执行程序。
能独立提供编译工具链的厂家并不多,嵌入式平台则更少,主要就是 ARM、IAR、GNU、LLVM。其中,ARM、IAR 是收费的专用软件,其支持的架构有限,而 GNU 的 GCC 则是一款支持众多架构的开源编译套件;LLVM 则是后起之秀,同样也支持众多架构,目前用的不如 GCC 广泛!
.map 文件
.map 文件对应的中文名应该是映射文件,用来展示(映射)项目构建的链接阶段的细节。通常包含程序的全局符号、交叉引用和内存映射等等信息。目前,常见的编译器套件(实际是其中的链接器),例如, GCC、ARMCC、IAR 都可以生成 .map 文件。
GCC
GCC 编译工具链中的链接器、汇编器、objdump 等工具都位于 GNU Binutils 中,他们的相关文档可以直接在官网下载。相比于 ARMCC 和 IAR,GCC 的 MAP 文件中的内容比较少!
产生方式
在 GCC 中,MAP 文件就是由链接器 ld 通过使用命令 -Map=mapfile 来输出 map 文件。需要注意,如果同时使用了 --print-map 则会只将 MAP 内容输出到编译窗口,而不会生成 MAP 文件。
需要注意的是,如果使用了编译器 gcc 作为入口(通常都是这么做,不会直接调用链接器),则需要使用 -Wl,-Map,FILE 的方式来将参数传递给链接器。编译器参数 -Wl 是专门用来传递参数给链接器的。同样,如果使用了 -Xlinker --print-map 则只会将 MAP 信息输出到编译窗口,而不会再生成 MAP 文件!
在理解内容之前,有必要先了解一下工具链提供的存档文件(Archive File)。前面说过,工具链提供了 lib 这一部分, lib 中的各个函数的实现是已经进行了预编译的,并且把预编译的各种 .o 文件打包成为存档文件(.a 文件)。编译单元即一个 .o 文件。
GCC 的 MAP 文件相比于 ARMCC 和 IAR 内容少了很多。
存档文件引用关系
MAP 文件的第一部分内容列出了我们项目中所使用的标准库中提供的函数的基本调用情况,基本格式如下:
存档文件 (编译单元)
调用存档文件中接口的文件(调用的符号)
如下图所示的示例,表示 crt0.o 中正在调用 exit 这个接口,而 exit 位于 lib_a-exit.o 这个文件中,而 lib_a-exit.o 这个文件存在于 libg.a 这个存档文件中!

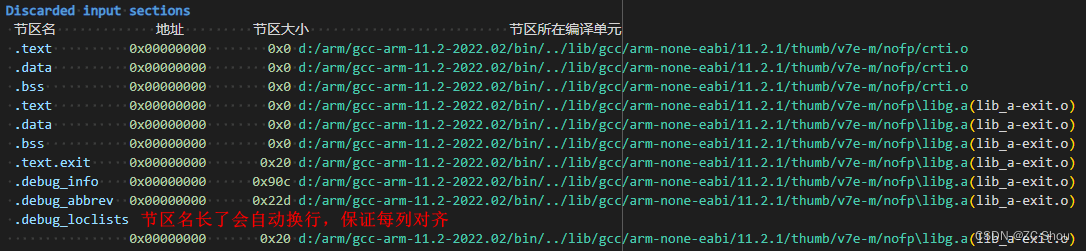
丢弃的输入段
MAP 文件的第二部分内容列出了链接器在生成最终可执行文件时丢弃的输入段,每行一个,四列的含义从左到右依次为节区名、地址、节区大小、节区所在的编译单元。注意,如果节区位于存档文件中,则最后一列是存档文件 + (编译单元)。
内存配置
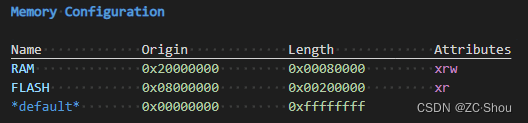
MAP文件的第三部分内容列出了我们的内存(存储)配置情况,每行一个,四列的含义从左到右依次为存储的名字、起始地址、大小(字节)、属性(r:读、x:执行、w:写)。
链接脚本和内存映射
关于链接脚本我们后面在详细介绍,这部分链接脚本就是一些 MRI 兼容的链接脚本命令,简单来说,使用 MRI 兼容的链接脚本命令引入一些对象文件(.o)。 MRI 兼容的链接脚本命令是用于早期链接器的,在 ld 手册中有说明,现在存在的唯一的目的就是兼容!
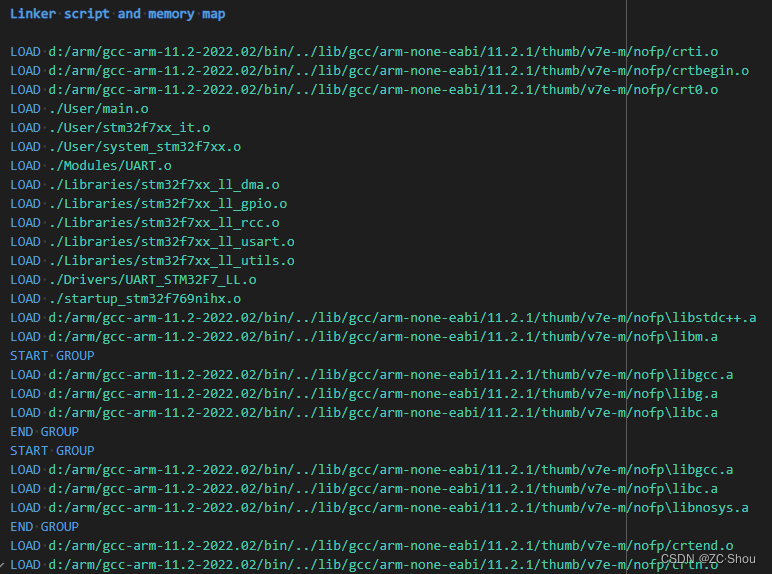
这部分最有用的是紧随其后的内存映射,这部分列出了所有符号在内存(存储)中的物理地址,这部分就是在辅助调试时最常用的!
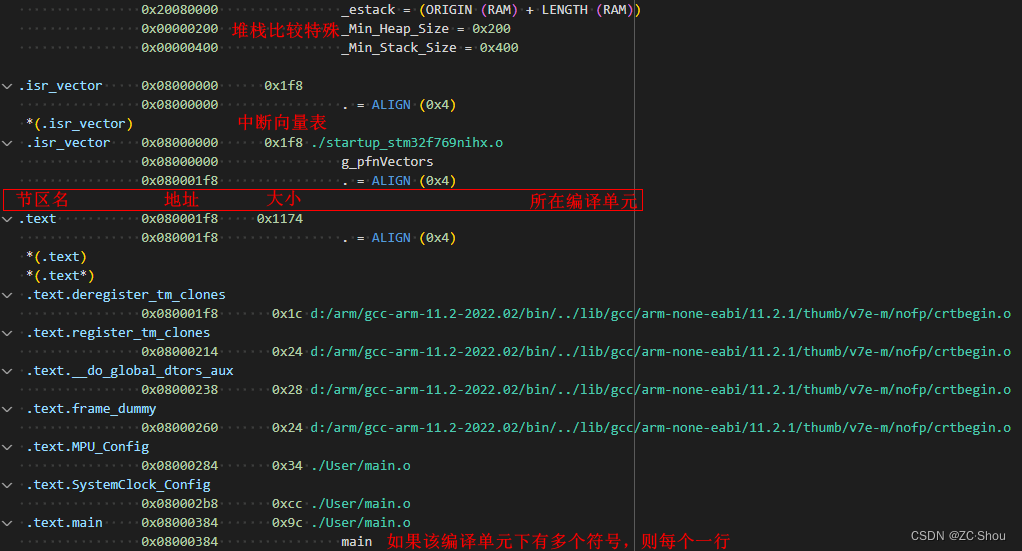
.lst 文件
.lst 文件全称是 Assembler list file,主要用来存储汇编程序列表数据,它通常会拥有比 .map 文件更详细的信息。借助 .lst 文件,同时通过查看栈帧结构(可以通过查看相应的手册来确定栈帧的组成),通过在 .lst 文件中查找 lr 的地址所在的位置,就能立刻定位到问题。
GCC
GCC 编译工具链中的链接器、汇编器、objdump 等工具都位于 GNU Binutils 中,他们的相关文档可以直接在官网下载。
产生方式
.lst 文件通常是由汇编器产生的,对于 GCC 的汇编器 as,通过使用命令 -a[cdghlmns]=[FILE] 来输出 lst 文件。但需要注意的是,-a[cdghlmns]=[FILE] 参数是独立使用汇编器 as 的时候才生效的。
与上面说的 MAP 文件产生一样,如果使用了编译器 gcc 作为入口(通常都是这么做,不会直接调用汇编器),则需要使用 -Wa,-a,FILE 的方式来将参数传递给汇编器。编译器参数 -Wa 是专门用来传递参数给汇编器的。
在实际开发中,我们经常写 -Wa,-adhlns="$@.lst",这样,每编译一个源文件就会产生一个对应的 .lst 文件。需要注意的是,如果是高级语言文件(例如 C 语言),我们需要配置编译器的参数,不要以为仅仅配置汇编器 as 就行(在多数工具中编译器和汇编器是独立配置的)!
内容介绍
在实际开发中,汇编器 as 产生的 LST 文件基本很少使用,使用最多的是使用 objdump 工具产生的最终调试程序对应的 LST 文件。这里我们主要就介绍 objdump 产生的 LST 文件。上面说过了, objdump 输出的实际是 ELF 文件内容,详细介绍见独立博文 Linux 之二十 详解 ELF 文件。
–source、–demangle、 --line-numbers、–wide
就是将反汇编与 C 源码混合在一起显示出来。并且尽可能的翻译成人能看懂的代码(翻译符号名、对应行号)!
–all-headers
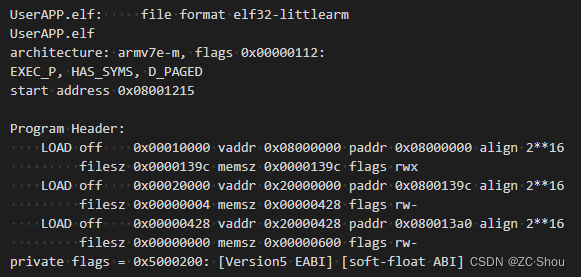
该命令会输出 Program Header,Sections 以及 SYMBOL TABLE 这个三部分的内容。编译工具产生的最终可执行文件是符合 ELF 规范的二进制文件,这里的输出内容其实都是 ELF 文件的内容,关于 ELF 文件,可以参考 ARM 之一 ELF 文件、镜像(Image)文件、可执行文件、对象文件 详解。
Program Header:这个就是 ELF 文件的程序头
Sections:这个就是从 ELF 文件中的提取的节区信息,共由 8 列组成,每列的含义说明如下:
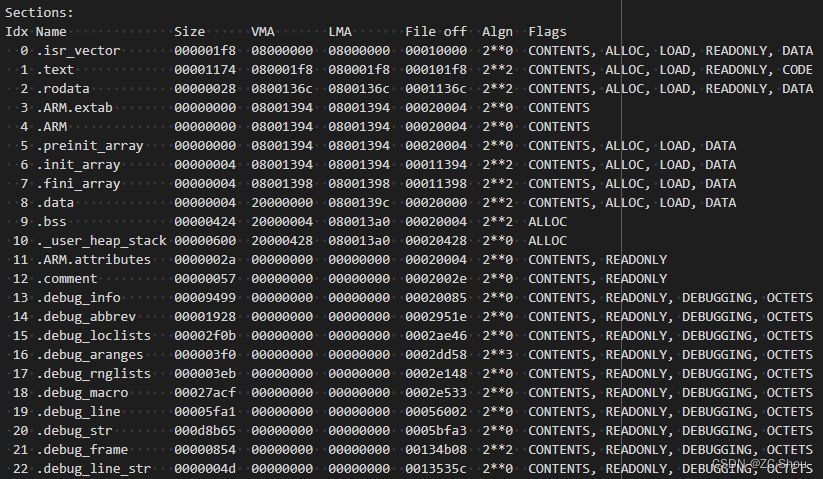
第一列(Idx):从 0 开始的索引号
第二列(Name): 节的名字
第三列(Size):节的大小(字节)
第四列(VMA):Virtual Memory Address 的缩写,表示该节在运行时的地址
第五列(LMA):Load Memory Address 的缩写,表示该节的加载地址
第六列(File off):该节在文件中的偏移
第七列(Algn):对齐字节数,只能是 2 的正整数次幂,由于纯文本没办法显示幂,这里使用 ** 表示!
第八列(Flags):该节的属性标志
SYMBOL TABLE:这个就是从 ELF 文件中的提取的符号表,由 5 列组成,每列的含义说明如下:
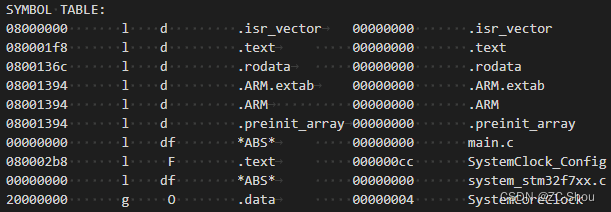
第一列:符号的值,通常就是符号的物理地址
第二列:这是一组符号标识,共由 7 个标识符组成,某些标识符可以是空格。
第一个标识符:取值如下
l : Local Symbol
g: Global Symbol
u: Unique global Symbol
! :其他情况
第二个标识符:取值为 w 表示弱符号(Weak),否则为空格表示强符号(Strong)
第三个标识符:取值为 C 表示构造函数(Constructor ),否则为空格表示普通符号
第四个标识符:取值为 W 表示警告符号(Warning),否则为空格表示普通符号。警告符号的名称是一条消息,当警告符号后面的符号被引用时显示出来。
第五个标识符:
I: 该符号是对另一个符号的间接引用
i: 在 reloc 处理期间计算的函数
:空格表示普通符号
第六个标识符:
d: 调试符号
D: 动态符号
:空格表示普通符号
第七个标识符:
F : 符号是函数的名称(Function )
f: 一个文件(file)
O: 一个对象(Object)
:空格表示普通符号
第三列:符号对应的节区。如果该节是绝对的(即没有与任何节连接),则是 *ABS*,如果该节在被转储的文件中被引用,但在那里没有定义,则是 *UND*。
第四列:对于普通符号是对齐方式,对于其他符号则是大小
第五列:符号名字