集群分布式文件系统改变企业存储方式
由现有的PC、硬盘和以太网线,基于Linux操作系统,所组成的高级计算机,不仅仅是一种以低成本获得高性能计算的方法。他们在过去10年中还颠覆了大型计算机系统的市场。但是集群计算机与磁盘之间传输数据的速度,却没能跟上微处理器和内存的发展速度,结果一些重要项目因此而增加了额外的时间和成本。不过,最近出现了一类新的集群文件系统软件,它将有可能降低公司购买存储设备的成本。
新的集群文件系统采用了开源的Lustre技术,由美国能源部(Department Of Energy)开发,惠普公司(HP)提供商业支持。它显著提高了输入输出(I/O)速度,目前已经在高校、国家实验室和超级计算研究中心产生了一定的影响,未来几年中,它还有可能进入普通商业计算领域。
“从这套系统的基本性能来看,它简直快得不可思议”。斯科特·司徒汉(Scott Studham)表示。司徒汉是美国橡树岭国家试验室(Oak Ridge National Laboratory)国家计算科学中心(National Center For Computational Sciences)的首席技术官(CTO)兼某Lustre用户团体的主席。有了Lustre,每台机器与磁盘间的I/O速度从每秒数百MB提高到每秒 2GB。由于性能几乎与连接工作站的数量保持同步上升,集群内从磁盘读取数据的总体速度可能会达到每秒几十GB。
“企业级文件系统无法达到这个速度”。皮克斯动画工作室(Pixar Animation Studio)技术副总裁格雷格·布兰多(Greg Brandeau)认为。这家工作室采用了创业公司Ibrix公司开发的集群文件系统。当他们在制作动画电影《汽车总动员》(Cars,明年发行)时,这套系统必须对2,400只处理器组成的渲染机群、每天多达2,400亿次的数据请求做出响应。皮克斯动画工作室首次使用了“光线追踪”(Ray Tracing)技术,可以带给角色反光色和更加真实的光影效果,但这会消耗大量的处理器和网络资源。“过去半年来,我们已经认识到,使用高性能计算确实能够带来与企业计算不同的效果。”布兰多表示。
不久前,惠普公司发布了可扩展文件系统(Scalable File Share)的第2版,这个产品是去年年底推出的,包含一台服务器和一只软件包,使用Lustre技术来分布集群内的存储服务,这种做法与过去几年一些 IT厂商为提高服务器性能所采取的分布式计算方式非常相似。SFS系统允许集群里的Linux节点能以高达每秒35GB的速度读取数据,而且允许高达 512TB的总存储容量,这是以前旧有系统容量的两倍。惠普公司高性能计算产品市场经理肯特·昆宁格(Kent Koeninger)表示:“之所以能达到这样的速度,关键之一是因为使用了集群技术来组建存储系统。”
提高传统文件系统的扩展性问题,与计算机管理磁盘上所存储数据的方式有关。计算机文件由分散在整个磁盘上的数据块组成,而不是一个有机的整体。文件系统追踪这些数据块,当文件需要更多空间时,系统就会分配空闲的数据块满足其需求。但是如果多台计算机争着访问数据,大部分文件系统就会锁定被某个计算机所使用的一个数据块,即使其他计算机也在请求这个数据块。当那台机器结束访问以后,集群中其他节点才可以访问那个数据块。但是当管理人员在集群里加入了更多的机器,有时是几百或者几千台,管理这些数据块就会消耗更多的CPU资源和网络带宽。
“最终,这些都导致了应用程序性能的降低”。IT市场调研公司Illuminata公司分析师大卫·福罗因德(David Freund)表示,“于是,就出现了系统的扩展性问题”。Lustre技术通过让成百上千台服务器共享一个文件系统的方式解决了这个问题。它将数据块管理功能扩展到所有设备上。尽管有几十台机器同时在处理I/O事务,但相对于其他集群里的机器,他们看上去仍旧像是同一台文件服务器。这就使得它带来的 I/O速度要比商业计算标准,比存储区域网络或网络附加存储高出很多。
“Lustre技术解决了一个高性能计算市场和通用市场都会遇到的障碍:磁盘驱动器速度无法与处理器和内存带宽的增加保持同步”。司徒汉这样认为。他还进一步解释说,当用户在集群的众多处理器上部署应用程序,从磁盘读取数据或者写入数据都会阻塞性能的发挥。这个问题非常严重,因此他在跟存储供应商谈判的时候,关心的是数据的速度,而不是容量。“在过去10年,我们往往就GB容量的价格与存储供应商讨价还价”。他说,“而今后,我们会更加关注单位带宽的成本。在我过去购买存储设备的经历中,我还是第一次提出这样的问题,‘我不关心你给我多少容量;我更关心的是单位带宽的成本。’我们正好遇到了拐点。”
集群计算机在科学和商业领域正变得日益重要。在2004年11月田纳西大学(University of Tennessee)和德国曼海姆大学(the University of Mannheim)公布的全球500台速度最快的超级计算机名单当中,有296个系统是集群计算机。存储也获得了业界更多的关注,因为旨在防止诈骗的新出台的联邦法规,也正刺激企业保留更多的数据。2005年,太阳计算机系统公司(Sun)投资41亿美元现金收购ST公司(Storage Technology Corp.)的举措,就是为了顺应这个潮流。如果高校、国家实验室以及少数比较大胆的企业能够更加广泛地采用Lustre和其他类似技术的话,就很有可能会改变目前企业普遍流行的存储采购方式。
“Lustre技术已经吸引了大量的眼球”。集群专用网络设备制造商Myricom公司的首席执行官(CEO)兼首席技术官(CTO)楚克 ·赛茨(Chuck Seitz)表示。凭借这项技术所带来的速度和低成本优势,Myricom公司的产品在一些国家实验室获得了一席之地,比如劳伦斯·利弗莫尔国家实验室(Lawrence Livermore National Laboratory)、西北太平洋国家实验室(Pacific Northwest National Laboratory)以及美国超级计算应用国家中心(NCSA)等。
NCSA在被称为“Tungsten” 的集群上运行Lustre,它拥有1,240节点、9.8Tflops浮点运算能力,主要用来运行气象科学、航天以及其他应用程序。NCSA存储技术项目经理米歇尔·巴特勒(Michelle Butler)解释说:“你肯定不愿看到一台价值800万美元的机器在那里等待数据I/O。”等待时间的减少也意味着那些拿了国家科学基金会津贴(National Science Foundation)的科学家们,可以花费更少的计算时间来从事自己的研究。“5~10年前的应用程序,由于等待时间太长,因此没有一个做I/O处理。”她说,“现在的数据铺天盖地。”
由于国家科学基金会的项目数据也运行在NCSA的计算机上,因此NCSA的存档服务器每月要增加40~60TB的数据。就在上世纪90年代末,计算机科学家还在研究怎样在程序里利用内存,以避免向磁盘读写数据。“现在不用再教他们这些东西了。”巴特勒说,“计算机科学家的习惯已经发生了很大改变。”
传统上,也有好几种方法能够扩大存储的规模。高度标准化的网络附加存储系统(NAS)使用通用的协议可以在局域网(LAN)上共享文件,比如微软公司的 CIFS系统,或者基于Unix和Linux的标准的网络文件系统(Network File System)都是如此。用户通过这些系统可以将很多电脑连上同一台服务器,共享存在于网络里的虚拟磁盘。NAS使用廉价的以太网连接各台计算机,但它传输数据的速度只有1GB,比多数应用程序运行速度都要低。由于它与本地磁盘交换数据的速度相对快于网络通信的速度,结果就造成阻塞现象。
存储区域网络(SAN)传输速度超过了NAS,最高可达2~4GB,但需要昂贵的光纤通道交换机提供支持,而且每台计算机还要配备一块价值1,000美元的板卡。此外,iSCSI协议在共享存储网络中日益普及,它允许SAN内部磁盘和计算机之间直接通过以太网通信。集群文件系统的快速磁盘通信速度可能会吸引一些特殊行业,他们对于数据I/O速度有很高的要求,比如银行、石油勘探、微芯片制造、汽车制造、航空和电影电脑动画等行业就是如此。
一些出售集群文件系统的小公司正在开始赢得一些重量级的客户。与Lustre软件相关的知识产权的拥有者集群文件系统公司(Cluster File System Inc.)将雪佛龙公司(Chevron Corp.)列入了自己的客户名单。而新兴企业Panasas公司(Panasas Inc.)的一个大客户是沃尔特-迪斯尼公司(Walt Disney Co.),Panasas公司将称为“ActiveScale”的集群文件系统与硬件进行了捆绑销售。根据Illuminata公司的透露,一些大厂商也在探索这个技术:国际商业机器公司(IBM)正在考虑在GPFS文件系统里加入基于对象的存储。戴尔公司(Dell)也在与Ibrix公司合作,销售 Ibrix公司的Fusion文件系统。
戴尔公司发现,从公司服务器运行情况来看,非常迫切需要引进Ibrix公司的技术,这个新的需求也使得戴尔公司重新检视应该如何捆绑网络与计算。戴尔公司过去在向客户销售集群产品时,基本是以1GB的带宽来匹配1Tflop浮点运算的计算能力,公司可扩展系统集团高级经理维克托·马沙耶其(Victor Mashayekhi)说。“随着时间的推移,我们看到数据处理带宽和计算能力的比值提高了,也就是说对带宽的相对要求更高了。”他说,“你会发现计算能力不得不等待数据传输,而大量的数据卡在了I/O环节。”
迫于大量数据的需求,德克萨斯高级计算中心(Texas Advanced Computing Center)引进了Ibrix公司的Fusion文件系统。这家中心位于奥斯丁德克萨斯大学(University Of Texas)校园中。中心主要是给大学的研究人员提供计算服务。目前,中心采用了文件系统来提高一个计算流体力学应用程序的性能。大约1,700位科学家采用这个程序模拟空气动力学中的湍流。项目的每一个流程都需要写入一个大小在300~400M之间的文件。中心高性能计算集团经理汤米·明雅德(Tommy Minyard)表示,如果使用NFS系统来写入所有所需数据,大约20GB的文件就要花费约50分钟。这种情况每个小时都会遇到。结果是程序每运行1小时,只有10分钟是在进行计算。而有了Ibrix公司的系统,程序的I/O写入时间缩短到每小时5分钟。“它对于系统的所有用户都带来了好处。”明雅德表示。
当然,这的确是个好消息。但从另一方面来看,集群文件系统的标准才刚刚出现,而这些软件都是由刚入行的小企业所拥有。他们所能运行计算机类型也比较有限,这也限制了软件的推广。Lustre技术只能在Linux和Catamount(来自超级计算机制造商Cray公司的一种不知名的操作系统)上运行。而且它很难安装,文档记录功能也不太完善。基于这些因素,一些商业科技经理采取了观望态度。
“Lustre看上去很有意思,但是我们目前还没有采用任何相关的系统”。梦工厂动画公司(DreamWorks Animation SKG)制作技术主管安迪·亨德里克森(Andy Hendrickson)表示,“有个很大的问题是,它能否达到所承诺的性能,它的可靠性是否足够作为制作的基础?我们对这些方面有着很高的要求”。也许在总结了所有公司对集群文件系统的所有关心问题之后,亨德里克森还会问:“如果安装了这项技术,我们需要改变多少流程?”这种新兴技术的好处能够超过给企业带来的风险,仍有待进一步观察。
要点:集群计算机里,计算机与磁盘间数据交换速度的提升无法跟上微处理器和内存增长的速度,从而也拖累了应用程序的性能。一种新兴的集群文件系统软件提高了I/O速度,可能降低企业购买存储设备的成本并改变企业购买存储的方式。集群文件系统已经在大学、实验室和超级计算研究中心里使用,而且即将进入通用商业计算市场。
上文源自:(信息周刊)
分布式存储技术(一):概念与简介
随着计算机信息技术的普及,互联网用户数量的增多,云计算、物联网等新兴技术的不断发展,数据量的增长速度越来越快,海量庞大的数据出现标志着大数据时代的来临。传统数据库和集中式存储技术数据处理效率低,速度慢,已无法适应当代信息处理的需求。为了改善传统数据模式应用的局限性以及无法优化存储空间等缺点,大数据分布式存储技术应运而生,增强了数据库的数据处理能力,提高了数据处理效率,加快了数据处理速度,分布式存储技术的应用逐渐成为各行各业发展的主要趋势,推动了大数据技术的发展。下面我们简要介绍一下大规模分布式存储技术的相关知识。
一、分布式存储系统简述
分布式存储系统,是将数据分散存储在多台独立的设备上。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
二、分布式存储技术概念
本质上来说,分布式存储技术是一种新型的数据处理技术,主要是将数据分布存储,同时在分布存储的数据之间构建联系,从而构建出一个虚拟的存储设备。不同于集中式存储技术,分布式存储技术充分的利用了网络的优势,把网络上相对比较零散的存储空间虚拟为一个整体,进而将这一空间作为数据存储的主题,而非将数据存储在特定的节点上。随着互联网技术的发展,分布式存储技术的应用越来越广泛,提升了网络存储资源的利用率,满足了人们存储数据的需求,同时为人们提供了数据共享通道,方便人们进行数据交换。
三、 分布式存储技术与集中式存储技术的区别
分布式存储技术与集中式存储技术两者的主要区别有三处:第一是数据存储量。集中式存储技术将信息数据存储在一个数据库中,数据存储量相当有限,不能满足高级别数据存储的需求。而分布式存储技术是将数据存储在零散的网络空间中,可以存储海量的数据,能满足多种级别的数据存储需求。第二是防御性。
集中式存储技术的防御性低,这是因为信息数据全部集中存储在服务器中,一旦服务器感染网络病毒或是遭受黑客攻击,全部数据将会损坏或丢失,整个网络都会随之瘫痪,可能产生很严重的后果。而分布式存储技术的防御性较高,每一个节点都可以被看作一个中心,这样即使一个节点遭受攻击或数据篡改,其他中心也能够保证整体网络的正常运行,部分数据的损坏不影响其他数据的使用,有效保证了信息安全。第三是并发性能。集中式存储技术的并发性能低,不能同时读写信息数据,在查询大量数据时速度非常慢。而分布式存储技术的并发性能好,能够同时对海量数据进行读写操作。
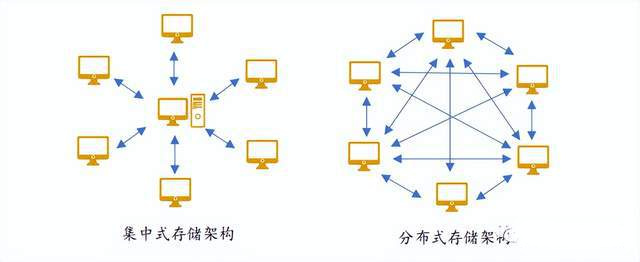
图1 集中式存储和分布式存储对比图
分布式存储技术(二):分类与关键技术
前文书我们说到了分布式存储技术的概念与简介,本文介绍一下分布式存储系统的分类和关键技术。
一、分布式存储系统分类
分布式存储的数据类型一般有以下三类:一是非结构化的数据。主要是数据之间的关联性不大,像文本图片之类的数据。二是结构化的数据。数据之间的关联性很大,关系型数据库这种,可以用表进行表示的。三是半结构化数据:介于上述两种类型之间,数据之间的关系简单。针对适合处理这几种不同的类型的数据,可将分布式存储系统划分为四类。
(1)分布式文件系统
处理非结构化数据,将非结构化的数据都当作文件形式的存储对象,处理对象是文件,形成一个分布式文件系统。
(2)分布式键值系统
存储数据关系简单的半结构化的数据,通过键值来管理半结构化的数据,一般用作缓存系统,一致性哈希算法是键值系统中常见的数据分布技术。支持简单的数据创建,读取,更新,删除操作。
(3)分布式表格系统
存储数据关系复杂的半结构化的数据,不仅支持分布式键值系统的GRUD操作,而且还是支持主键的范围扫描。主要的特点是只针对单表格,不支持表格之间的合并联接等操作。
(4)分布式数据库
存储结构化的数据,从单机的关系数据库发展而来,提供多维表格组织数据,提供SQL语言查找,同时支持多表的关联。
二、分布式存储系统关键技术
分布式存储系统中主要应用了四种技术:
(1)弹性扩展技术
可扩展性是存储系统的首要特征。在大数据时代,一个存储系统的性能主要取决于系统的可扩展性。
(2)元数据管理技术
元数据即描述数据的数据,随着信息数据量的不断增长,元数据量也在不断增加。元数据管理是存储系统首要完成的工作,因此存储系统必须要有良好的元数据管理能力。分布式存储系统具有一流的元数据管理能力,并且不需要专门的元数据服务器,减轻了企业的成本开支。
(3)存储层级内的优化技术
构建存储系统时,需要基于成本和性能来考虑,因此存储系统通常采用多层不同性价比的存储器件组成存储层次结构。大数据的规模大,因此构建高效合理的存储层次结构,可以在保证系统性能的前提下,降低系统能耗和构建成本,利用数据访问局部性原理,可以从两个方面对存储层次结构进行优化。
(4)针对应用和负载的存储优化技术
传统数据存储模型需要支持尽可能多的应用,因此需要具备较好的通用性。大数据具有大规模、高动态及快速处理等特性,通用的数据存储模型通常并不是最能提高应用性能的模型,而大数据存储系统对上层应用性能的关注远远超过对通用性的追求。针对应用和负载来优化存储,就是将数据存储与应用耦合。简化或扩展分布式文件系统的功能,根据特定应用、特定负载、特定的计算模型对文件系统进行定制和深度优化,使应用达到最佳性能。
新的集群文件系统采用了开源的Lustre技术,由美国能源部(Department Of Energy)开发,惠普公司(HP)提供商业支持。它显著提高了输入输出(I/O)速度,目前已经在高校、国家实验室和超级计算研究中心产生了一定的影响,未来几年中,它还有可能进入普通商业计算领域。
“从这套系统的基本性能来看,它简直快得不可思议”。斯科特·司徒汉(Scott Studham)表示。司徒汉是美国橡树岭国家试验室(Oak Ridge National Laboratory)国家计算科学中心(National Center For Computational Sciences)的首席技术官(CTO)兼某Lustre用户团体的主席。有了Lustre,每台机器与磁盘间的I/O速度从每秒数百MB提高到每秒 2GB。由于性能几乎与连接工作站的数量保持同步上升,集群内从磁盘读取数据的总体速度可能会达到每秒几十GB。
“企业级文件系统无法达到这个速度”。皮克斯动画工作室(Pixar Animation Studio)技术副总裁格雷格·布兰多(Greg Brandeau)认为。这家工作室采用了创业公司Ibrix公司开发的集群文件系统。当他们在制作动画电影《汽车总动员》(Cars,明年发行)时,这套系统必须对2,400只处理器组成的渲染机群、每天多达2,400亿次的数据请求做出响应。皮克斯动画工作室首次使用了“光线追踪”(Ray Tracing)技术,可以带给角色反光色和更加真实的光影效果,但这会消耗大量的处理器和网络资源。“过去半年来,我们已经认识到,使用高性能计算确实能够带来与企业计算不同的效果。”布兰多表示。
不久前,惠普公司发布了可扩展文件系统(Scalable File Share)的第2版,这个产品是去年年底推出的,包含一台服务器和一只软件包,使用Lustre技术来分布集群内的存储服务,这种做法与过去几年一些 IT厂商为提高服务器性能所采取的分布式计算方式非常相似。SFS系统允许集群里的Linux节点能以高达每秒35GB的速度读取数据,而且允许高达 512TB的总存储容量,这是以前旧有系统容量的两倍。惠普公司高性能计算产品市场经理肯特·昆宁格(Kent Koeninger)表示:“之所以能达到这样的速度,关键之一是因为使用了集群技术来组建存储系统。”
提高传统文件系统的扩展性问题,与计算机管理磁盘上所存储数据的方式有关。计算机文件由分散在整个磁盘上的数据块组成,而不是一个有机的整体。文件系统追踪这些数据块,当文件需要更多空间时,系统就会分配空闲的数据块满足其需求。但是如果多台计算机争着访问数据,大部分文件系统就会锁定被某个计算机所使用的一个数据块,即使其他计算机也在请求这个数据块。当那台机器结束访问以后,集群中其他节点才可以访问那个数据块。但是当管理人员在集群里加入了更多的机器,有时是几百或者几千台,管理这些数据块就会消耗更多的CPU资源和网络带宽。
“最终,这些都导致了应用程序性能的降低”。IT市场调研公司Illuminata公司分析师大卫·福罗因德(David Freund)表示,“于是,就出现了系统的扩展性问题”。Lustre技术通过让成百上千台服务器共享一个文件系统的方式解决了这个问题。它将数据块管理功能扩展到所有设备上。尽管有几十台机器同时在处理I/O事务,但相对于其他集群里的机器,他们看上去仍旧像是同一台文件服务器。这就使得它带来的 I/O速度要比商业计算标准,比存储区域网络或网络附加存储高出很多。
“Lustre技术解决了一个高性能计算市场和通用市场都会遇到的障碍:磁盘驱动器速度无法与处理器和内存带宽的增加保持同步”。司徒汉这样认为。他还进一步解释说,当用户在集群的众多处理器上部署应用程序,从磁盘读取数据或者写入数据都会阻塞性能的发挥。这个问题非常严重,因此他在跟存储供应商谈判的时候,关心的是数据的速度,而不是容量。“在过去10年,我们往往就GB容量的价格与存储供应商讨价还价”。他说,“而今后,我们会更加关注单位带宽的成本。在我过去购买存储设备的经历中,我还是第一次提出这样的问题,‘我不关心你给我多少容量;我更关心的是单位带宽的成本。’我们正好遇到了拐点。”
集群计算机在科学和商业领域正变得日益重要。在2004年11月田纳西大学(University of Tennessee)和德国曼海姆大学(the University of Mannheim)公布的全球500台速度最快的超级计算机名单当中,有296个系统是集群计算机。存储也获得了业界更多的关注,因为旨在防止诈骗的新出台的联邦法规,也正刺激企业保留更多的数据。2005年,太阳计算机系统公司(Sun)投资41亿美元现金收购ST公司(Storage Technology Corp.)的举措,就是为了顺应这个潮流。如果高校、国家实验室以及少数比较大胆的企业能够更加广泛地采用Lustre和其他类似技术的话,就很有可能会改变目前企业普遍流行的存储采购方式。
“Lustre技术已经吸引了大量的眼球”。集群专用网络设备制造商Myricom公司的首席执行官(CEO)兼首席技术官(CTO)楚克 ·赛茨(Chuck Seitz)表示。凭借这项技术所带来的速度和低成本优势,Myricom公司的产品在一些国家实验室获得了一席之地,比如劳伦斯·利弗莫尔国家实验室(Lawrence Livermore National Laboratory)、西北太平洋国家实验室(Pacific Northwest National Laboratory)以及美国超级计算应用国家中心(NCSA)等。
NCSA在被称为“Tungsten” 的集群上运行Lustre,它拥有1,240节点、9.8Tflops浮点运算能力,主要用来运行气象科学、航天以及其他应用程序。NCSA存储技术项目经理米歇尔·巴特勒(Michelle Butler)解释说:“你肯定不愿看到一台价值800万美元的机器在那里等待数据I/O。”等待时间的减少也意味着那些拿了国家科学基金会津贴(National Science Foundation)的科学家们,可以花费更少的计算时间来从事自己的研究。“5~10年前的应用程序,由于等待时间太长,因此没有一个做I/O处理。”她说,“现在的数据铺天盖地。”
由于国家科学基金会的项目数据也运行在NCSA的计算机上,因此NCSA的存档服务器每月要增加40~60TB的数据。就在上世纪90年代末,计算机科学家还在研究怎样在程序里利用内存,以避免向磁盘读写数据。“现在不用再教他们这些东西了。”巴特勒说,“计算机科学家的习惯已经发生了很大改变。”
传统上,也有好几种方法能够扩大存储的规模。高度标准化的网络附加存储系统(NAS)使用通用的协议可以在局域网(LAN)上共享文件,比如微软公司的 CIFS系统,或者基于Unix和Linux的标准的网络文件系统(Network File System)都是如此。用户通过这些系统可以将很多电脑连上同一台服务器,共享存在于网络里的虚拟磁盘。NAS使用廉价的以太网连接各台计算机,但它传输数据的速度只有1GB,比多数应用程序运行速度都要低。由于它与本地磁盘交换数据的速度相对快于网络通信的速度,结果就造成阻塞现象。
存储区域网络(SAN)传输速度超过了NAS,最高可达2~4GB,但需要昂贵的光纤通道交换机提供支持,而且每台计算机还要配备一块价值1,000美元的板卡。此外,iSCSI协议在共享存储网络中日益普及,它允许SAN内部磁盘和计算机之间直接通过以太网通信。集群文件系统的快速磁盘通信速度可能会吸引一些特殊行业,他们对于数据I/O速度有很高的要求,比如银行、石油勘探、微芯片制造、汽车制造、航空和电影电脑动画等行业就是如此。
一些出售集群文件系统的小公司正在开始赢得一些重量级的客户。与Lustre软件相关的知识产权的拥有者集群文件系统公司(Cluster File System Inc.)将雪佛龙公司(Chevron Corp.)列入了自己的客户名单。而新兴企业Panasas公司(Panasas Inc.)的一个大客户是沃尔特-迪斯尼公司(Walt Disney Co.),Panasas公司将称为“ActiveScale”的集群文件系统与硬件进行了捆绑销售。根据Illuminata公司的透露,一些大厂商也在探索这个技术:国际商业机器公司(IBM)正在考虑在GPFS文件系统里加入基于对象的存储。戴尔公司(Dell)也在与Ibrix公司合作,销售 Ibrix公司的Fusion文件系统。
戴尔公司发现,从公司服务器运行情况来看,非常迫切需要引进Ibrix公司的技术,这个新的需求也使得戴尔公司重新检视应该如何捆绑网络与计算。戴尔公司过去在向客户销售集群产品时,基本是以1GB的带宽来匹配1Tflop浮点运算的计算能力,公司可扩展系统集团高级经理维克托·马沙耶其(Victor Mashayekhi)说。“随着时间的推移,我们看到数据处理带宽和计算能力的比值提高了,也就是说对带宽的相对要求更高了。”他说,“你会发现计算能力不得不等待数据传输,而大量的数据卡在了I/O环节。”
迫于大量数据的需求,德克萨斯高级计算中心(Texas Advanced Computing Center)引进了Ibrix公司的Fusion文件系统。这家中心位于奥斯丁德克萨斯大学(University Of Texas)校园中。中心主要是给大学的研究人员提供计算服务。目前,中心采用了文件系统来提高一个计算流体力学应用程序的性能。大约1,700位科学家采用这个程序模拟空气动力学中的湍流。项目的每一个流程都需要写入一个大小在300~400M之间的文件。中心高性能计算集团经理汤米·明雅德(Tommy Minyard)表示,如果使用NFS系统来写入所有所需数据,大约20GB的文件就要花费约50分钟。这种情况每个小时都会遇到。结果是程序每运行1小时,只有10分钟是在进行计算。而有了Ibrix公司的系统,程序的I/O写入时间缩短到每小时5分钟。“它对于系统的所有用户都带来了好处。”明雅德表示。
当然,这的确是个好消息。但从另一方面来看,集群文件系统的标准才刚刚出现,而这些软件都是由刚入行的小企业所拥有。他们所能运行计算机类型也比较有限,这也限制了软件的推广。Lustre技术只能在Linux和Catamount(来自超级计算机制造商Cray公司的一种不知名的操作系统)上运行。而且它很难安装,文档记录功能也不太完善。基于这些因素,一些商业科技经理采取了观望态度。
“Lustre看上去很有意思,但是我们目前还没有采用任何相关的系统”。梦工厂动画公司(DreamWorks Animation SKG)制作技术主管安迪·亨德里克森(Andy Hendrickson)表示,“有个很大的问题是,它能否达到所承诺的性能,它的可靠性是否足够作为制作的基础?我们对这些方面有着很高的要求”。也许在总结了所有公司对集群文件系统的所有关心问题之后,亨德里克森还会问:“如果安装了这项技术,我们需要改变多少流程?”这种新兴技术的好处能够超过给企业带来的风险,仍有待进一步观察。
要点:集群计算机里,计算机与磁盘间数据交换速度的提升无法跟上微处理器和内存增长的速度,从而也拖累了应用程序的性能。一种新兴的集群文件系统软件提高了I/O速度,可能降低企业购买存储设备的成本并改变企业购买存储的方式。集群文件系统已经在大学、实验室和超级计算研究中心里使用,而且即将进入通用商业计算市场。
上文源自:(信息周刊)
分布式存储技术(一):概念与简介
随着计算机信息技术的普及,互联网用户数量的增多,云计算、物联网等新兴技术的不断发展,数据量的增长速度越来越快,海量庞大的数据出现标志着大数据时代的来临。传统数据库和集中式存储技术数据处理效率低,速度慢,已无法适应当代信息处理的需求。为了改善传统数据模式应用的局限性以及无法优化存储空间等缺点,大数据分布式存储技术应运而生,增强了数据库的数据处理能力,提高了数据处理效率,加快了数据处理速度,分布式存储技术的应用逐渐成为各行各业发展的主要趋势,推动了大数据技术的发展。下面我们简要介绍一下大规模分布式存储技术的相关知识。
一、分布式存储系统简述
分布式存储系统,是将数据分散存储在多台独立的设备上。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
二、分布式存储技术概念
本质上来说,分布式存储技术是一种新型的数据处理技术,主要是将数据分布存储,同时在分布存储的数据之间构建联系,从而构建出一个虚拟的存储设备。不同于集中式存储技术,分布式存储技术充分的利用了网络的优势,把网络上相对比较零散的存储空间虚拟为一个整体,进而将这一空间作为数据存储的主题,而非将数据存储在特定的节点上。随着互联网技术的发展,分布式存储技术的应用越来越广泛,提升了网络存储资源的利用率,满足了人们存储数据的需求,同时为人们提供了数据共享通道,方便人们进行数据交换。
三、 分布式存储技术与集中式存储技术的区别
分布式存储技术与集中式存储技术两者的主要区别有三处:第一是数据存储量。集中式存储技术将信息数据存储在一个数据库中,数据存储量相当有限,不能满足高级别数据存储的需求。而分布式存储技术是将数据存储在零散的网络空间中,可以存储海量的数据,能满足多种级别的数据存储需求。第二是防御性。
集中式存储技术的防御性低,这是因为信息数据全部集中存储在服务器中,一旦服务器感染网络病毒或是遭受黑客攻击,全部数据将会损坏或丢失,整个网络都会随之瘫痪,可能产生很严重的后果。而分布式存储技术的防御性较高,每一个节点都可以被看作一个中心,这样即使一个节点遭受攻击或数据篡改,其他中心也能够保证整体网络的正常运行,部分数据的损坏不影响其他数据的使用,有效保证了信息安全。第三是并发性能。集中式存储技术的并发性能低,不能同时读写信息数据,在查询大量数据时速度非常慢。而分布式存储技术的并发性能好,能够同时对海量数据进行读写操作。
图1 集中式存储和分布式存储对比图
分布式存储技术(二):分类与关键技术
前文书我们说到了分布式存储技术的概念与简介,本文介绍一下分布式存储系统的分类和关键技术。
一、分布式存储系统分类
分布式存储的数据类型一般有以下三类:一是非结构化的数据。主要是数据之间的关联性不大,像文本图片之类的数据。二是结构化的数据。数据之间的关联性很大,关系型数据库这种,可以用表进行表示的。三是半结构化数据:介于上述两种类型之间,数据之间的关系简单。针对适合处理这几种不同的类型的数据,可将分布式存储系统划分为四类。
(1)分布式文件系统
处理非结构化数据,将非结构化的数据都当作文件形式的存储对象,处理对象是文件,形成一个分布式文件系统。
(2)分布式键值系统
存储数据关系简单的半结构化的数据,通过键值来管理半结构化的数据,一般用作缓存系统,一致性哈希算法是键值系统中常见的数据分布技术。支持简单的数据创建,读取,更新,删除操作。
(3)分布式表格系统
存储数据关系复杂的半结构化的数据,不仅支持分布式键值系统的GRUD操作,而且还是支持主键的范围扫描。主要的特点是只针对单表格,不支持表格之间的合并联接等操作。
(4)分布式数据库
存储结构化的数据,从单机的关系数据库发展而来,提供多维表格组织数据,提供SQL语言查找,同时支持多表的关联。
二、分布式存储系统关键技术
分布式存储系统中主要应用了四种技术:
(1)弹性扩展技术
可扩展性是存储系统的首要特征。在大数据时代,一个存储系统的性能主要取决于系统的可扩展性。
(2)元数据管理技术
元数据即描述数据的数据,随着信息数据量的不断增长,元数据量也在不断增加。元数据管理是存储系统首要完成的工作,因此存储系统必须要有良好的元数据管理能力。分布式存储系统具有一流的元数据管理能力,并且不需要专门的元数据服务器,减轻了企业的成本开支。
(3)存储层级内的优化技术
构建存储系统时,需要基于成本和性能来考虑,因此存储系统通常采用多层不同性价比的存储器件组成存储层次结构。大数据的规模大,因此构建高效合理的存储层次结构,可以在保证系统性能的前提下,降低系统能耗和构建成本,利用数据访问局部性原理,可以从两个方面对存储层次结构进行优化。
(4)针对应用和负载的存储优化技术
传统数据存储模型需要支持尽可能多的应用,因此需要具备较好的通用性。大数据具有大规模、高动态及快速处理等特性,通用的数据存储模型通常并不是最能提高应用性能的模型,而大数据存储系统对上层应用性能的关注远远超过对通用性的追求。针对应用和负载来优化存储,就是将数据存储与应用耦合。简化或扩展分布式文件系统的功能,根据特定应用、特定负载、特定的计算模型对文件系统进行定制和深度优化,使应用达到最佳性能。