程序员的那些事
程序员反感的十件事
程序员是一个比较特殊的群体,他们因为长期和电脑打交道所养成的性格和脾气也是比较相近的。当然,既然是人,当然是会有性格的,也是会有脾气的。下面让我们来看看十件能把程序惹毛了的事情。一方面我们可以看看程序员的共性,另一方面我们也可以看看程序员的缺点。无论怎么样,我都希望他们对你的日常工作都是一种帮助。
第十位 程序注释
程序注释本来是一些比较好的习惯,当程序员老手带新手的时候,总是会告诉新手,一定要写程序注释。于是,新手们当然会听从老手的吩咐。只不过,他们可能对程序注释有些误解,于是,我们经常在程序中看到一些如下的注释:
r = n/2; //r是n的一半
//循环,仅当r- n/r不大于t
while ((r-n/r) <=t){
… …
r = 0.5 * (r-n/r); // 设置r变量
}
每当看到这样的注释——只注释是什么,而不注释为什么,相信你一定会被惹火,这是谁写的程序注释啊?不找来骂一顿看来是不会解气了。程序注释应该是告诉别 人你的意图和想法,而不是告诉别人程序的语法,这是为了程序的易读性和可维护性,这样的为了注释而注释的注释,分明不是在注释,而是在挑衅,惹毛别人当然 毋庸置疑。
第九位 打断
正当程序沉浸于编程算法的思考,或是灵感突现正在书写程序的时候,但却遭到别人的打断,那是一件非常痛苦的事情,如果被持续打断,那可能会让人一下子就烦 躁起来。打断别人的人在这种情况下是非常不礼貌的。被打断的人就像函数调用一下,当其返回时,需要重新恢复断点时的现场,当然,人不是电脑,恢复现场通常 是一个很痛苦的过程,极端的情况下可能需要从头开始寻找思绪,然后一点一点地回到断点。
因此,我看到一些程序员在需要安静不被打扰的时候,要么会选择去一个没人找得到的地方,要么会在自己的桌子上方高挂一个条幅以示众人——“本人正执行内核 程序,无法中断,请勿骚扰,谢谢!”,可能正在沉浸于工作的程序被打断是多么大的开销。自然,被打断所惹毛了的人也不在少数了。
第八位 需求变化
这个事情估计不用多说了。只要是是程序员,面对需求变化的时候可能总是很无奈的。一次两次可能还要吧接受,但也顶不住经常变啊。据说敏捷开发中有一套方法 论可以让程序员们享受需求的变化,不知道是真是假。不过,今天让你做一个书桌,明天让你把书桌改成餐桌,后天让你把餐桌改成双人床,大后天让你把床改成小 木屋,然后把小木屋再改成高楼大厦。哎,是人都会被惹毛了的。那些人只用30分钟的会议就可以作出任何决定,但后面那几十个程序员需要搭上几百个小时的辛 苦工作。如果是我,可能我也需要神兽草泥马帮助解解气了。
不过,这也正说明了,程序员并不懂得怎么和用户沟通,而用户也不懂得和程序员沟通,如果一个项目没有一个中间人(如:PM)在其中协调的话,那么整个项目 可能就是“鸡同鸭讲”,用户和程序员都会被对方所惹毛了。如果要例举几个用户被惹毛的事情,估计程序员的那种一根筋的只从技术实现上思考问题的方法应该也 能排进前5名。
第七位 经理不懂技术
外行领导内行的事例还少吗?领导一句话,无论对不对,都是对的,我们必需照做,那怕是多么愚蠢多么错误的决定,我们也得照做。程序员其实并不怕经理不懂技 术,最怕的就是不懂技术的经理装着很懂技术。最可气的是,当你据理力争的挑站领导权威的时候,领导还把你视为异类。哎,想起这样的领导别说是骂人了,打人 的冲动都有了。其实,经理只不过是一个团队的支持者,他应该帮助团队,为团队排忧解难。而不是对团队发号施令。其实管理真的很简单,如果懂的话,就帮着做,如果不懂的话,就相信下属,放手让下属做。最怕的就是又不懂技术,还不信任下属的经理了。哎,这真是程序员的痛啊。
第六位 用户文档
用户文档本来不应该那么的令人害怕。这些文档记录了一切和我们所开发的软件有关的一些话题。因为我们并不知道我们所面对的用户的电脑操作基础是什么样的, 所以,在写下这样的文档的时候,我们必需假设这个用户什么也不懂。于是,需要用最清楚,最漂亮的语言写下一个最丰富的文档。那怕一个拷贝粘贴的操作,可能 我们都要分成五、六步来完成,那怕是一个配置IP地址的操作,我们也要从开始菜单开始一步一步的描述。对于程序员来说,他们在开发过程中几乎天天都在使用 自己开发的软件,到最后,可能都有得有点吐了,但还得从最简单的部份写这些文档,当然容易令他们烦燥,让程序员来完成这样的文档可能效果会非常不好。所 以对于这样的用户文档,应该由专门的文档人员来完成和维护。
第五位 没有文档
正如上一条所说的,程序员本来就不喜欢写文档,而因为技术人员的表达能力和写作能力一般都不是太好,所以,文档写的也很烂。看看开源社区的文档可能就知道 了。但是,我们可爱的程序员另一方面最生气的却是因为没有文档。当然,让面说是的用户的文档,这里我们说的是开发方面的文档,比如设计文档,功能规格,维 护文档等等。不过,基本上都是一样的。反正,一方面,我们的程序员不喜欢写文档,另一方面,我们的程序又会被抱怨没有文档,文档太少,或者文档看不懂。呵 呵。原来在抱怨方面也有递归啊。据说,敏捷开发可以降低程序开发中的文档,据说他们可以把代码写得跟文档和示图似的,不知道是真是假。不过,我听过太多太 多的程序员抱怨没文档太少,文档太差了,这个方面要怪还是怪程序员自己。
第四位 部署环境
虽然,程序员们开发的是软件,但是我们并不知道我们的程序会被部署或安装在什么样的环境下,比如,网络上的不同,RAID上的不同,BIOS上的不同,操 作系统的不同(WinXP和Win2003),有没有杀毒软件,和其它程序是否兼容,系统中有流氓软件或病毒等等。当然,只要你的软件出现错误,无论是你 的程序的问题,还是环境的问题,反正都是你的问题,你都得全部解决。所以,程序员们并不是简单地在编程,很多时候,还要当好一个不错的系统管理员。每当最 后确认问题的原因是环境问题的时候,可能程序员都是会心生怨气。
第三位 问题报告
“我的软件不工作了”,“程序出错了”,每当我们听到这样的问题报告的时候,程序员总是感到很痛苦,因为这样的问题报告等于什么也没有说,但还要程序员去 处理这种错误。没有明确的问题描述,没有说明如何重现问题,在感觉上,当然会显得有点被人质问的感觉,甚至,在某些时候还掺杂着看不起,训斥的语气,当 然,程序员基本上都是很有个性的,都是软硬不吃的主儿,所以,每当有这样的语气报告问题的时候,他们一般也会把话给顶回去,当然,后面自己然发生一些不愉 快的事情。所以,咱们还是需要一个客服部门来帮助我们的程序员和用户做好沟通。
第二位 程序员自己
惹毛程序员的可能还是程序员自己,程序员是“相轻”的,他们基本上都是持才傲物的,总是觉得自己才是最牛的,在程序员间,他们几乎每天都要吵架,而且一吵就吵得脸红脖子粗。在他们之间,他们总是被自己惹毛。
技术上的不同见解。比如Linux和Win,VC++和VB,Vi和Emacus,Java和C++,PHP和Ruby等等,等等。什么都要吵。
老手对新手的轻视。总是有一些程序员看不起另一些程序员,说话间都带着一种傲慢和训斥。当新手去问问题的时候,老手们总是爱搭不理。
在技术上不给对方留面子。不知道为什么,程序员总是不给对方留面子,每当听到有人错误理解某个技术的时候,他们总是喜欢当众大声指证,用别人的“错误”来表明自己的“博学”,并证明他人的“无知”。
喜好鄙视。他们喜好鄙视,其实,这个世界上没有一件事是完美的,有好就有不好,要挑毛病太容易了。程序员们特别喜欢鄙视别人,无论是什么的东西,他们总是喜欢看人短而不看人长。经常挂在他们嘴上的口头禅是“太差”、“不行”等等。
程序员,长期和电脑打交道,编写出的代码电脑总是认真的运行,长期养成了程序员们目空一切的性格,却不知,这个世界上很多东西并不是能像电脑一样,只要我们输入正确的指令它就正确地运行这么简单。程序员,什么时候才能变成成熟起来……
第一位 程序员的代码
无论你当时觉得自己的设计和写的代码如何的漂亮和经典,过上一段时间后,再回头看看,你必然会觉得自己的愚蠢。当然,当你需要去维护他人的代码的时候,你一定要在一边维护中一边臭骂别人的代码。是否你还记得当初怎么怎么牛气地和别人讨论自己的设计和自己的代码如何如何完美的?可是,用不了两年,一刚从学校毕业的学生在维护你的代码的过程当中就可以对你的代码指指点点,让你的颜面完全扫地。当然,也有的人始终觉得自己的设计和代码就是最好的,不过这是用一种比较静止的眼光来看问题。编程这个世界变化总是很快的的,很多事情,只有当我们做过,我们才熟悉他,熟悉了后才知道什么是更好的方法,这是循序渐进的。所以,当你对事情越来越熟悉的时候,再回头看自己以前做的设计和代码的时候,必然会觉得自己的肤浅和愚蠢,当然看别人的设计和代码时,可能也会开始骂 人了。
12 个学习新的编程语言的方法
在这篇文章中,作者提出了 12 项关于学习技术的建议。记住每个人学习的方式都不一样。其中一些可能对你十分有用,而其他的则可能无法满足你的需求。如果你开始担心一个策略,请尝试另一个策略并看看它哪里适合你。
1. 将其与类似的语言进行比较。当你首次观看有关该语言的第一个教程或阅读代码时,请尝试猜测该语言的每个部分将会做什么,并检查你的判断是否正确。 如果记笔记可以帮助你整合信息,请拿起一张纸并记下三个列表:
看起来很熟悉的东西,并且做了预期中的事
看起来很熟悉的东西,但做了意料之外的事
看起来完全是新的东西
例如,如果我用来自 Python 和 C 背景的 Rust 代码进行此练习,那么在第一个列表中,我会放上用于表示范围的花括号!(看起来像是布尔类型的非,但实际上是 Rust 中的宏定义)则放在第二个列表,类型签名语法(type signature syntax)放在第三个列表。如果你保留着初始列表的副本,一旦你更熟练,可使用它通过语言反思你的进展,并提醒自己在尝试向其他人讲授该语言时,有哪些看起来不熟悉的概念。
2. 阅读语言的官方文档。如果希望在使用之前吸收大量信息,从阅读语言的参考资料中可能会受益。不用担心它们会对你催眠,参考文献通常是用于查找使用,而不是用来记忆。
3. 使用互联网搜索。搜索网络是一个很好的方式,可提供有关特定错误和一般最佳做法的信息。当收到错误信息时,应搜索信息中看起来是错误的独一无二的部分,但不是代码唯一的部分。例如,如果错误提示 "Error on line 53: Invalid argument exception(错误在第 53 行:无效的参数异常)",以语言名称和字符串 “Invalid argument exception” 这样的组合搜索,以找到最佳的结果。记住要将错误信息中的所有引用内容都包含在内。
还可以在网络中搜索有关解决语言中特定问题的最佳做法的博文。评估搜索结果中显示的博客帖子的质量和决定认真采用他们的建议时,请查看作者的公共代码组合以及发布日期。
4. 与社区接触。虽然博客和新闻文章具有大量有用的信息,但是你尝试编写的特定代码片段总会有些微妙之处。不要害怕在邮件列表中发帖,或加入 IRC 和 Slack 频道以寻求帮助。
要提出有帮助的回复的问题,请确保在正确的地方提问。许多语言都有 “初学者” 邮件列表或聊天频道,专门针对可能会频繁询问的问题而建立。当提出问题时,请务必先总结准备做什么、已做过的东西以及发生的情况。尽量为专家提供足够的上下文来了解问题,但不需要无关紧要的细节。提出问题后,请务必坚持一段时间来听取建议或会回答你的疑问可能产生的后续问题。
5. 编写玩具程序。一次练习一个新的概念,很少有任务可打败只使用某个概念的玩具程序。你可以将重点放在尽可能让你的代码清洁和惯用性上。如果你将解决 Project Euler 或 Rosetta Code puzzle 作为玩具程序,则可以将你的解决方案与其他使用相同语言编写的解决方案进行比较。
6. 使用该语言编写 “生产就绪(Production-Ready)” 的代码。玩具程序是一个很好的第一步,但在更逼真的的环境中使用一门语言可帮助探索其现实使用中的优势和挑战。考虑将一个熟悉的、相对较小的、经过良好测试的程序移植到新的语言,以探索其在现实使用的应用。
7. 阅读一本关于这门语言的书籍。如果有好几本有用的书,比较它们的评论,并考虑哪位作者的背景和自己的最相似。现在有很多电子书可以免费在线阅读。
在购买有关该语言的书籍之前,请先查看书籍出版的日期以及其示例所涵盖的语言版本。如果使用的是较旧的书籍,请务必使用其所使用的语言版本的示例。还要在网上调查一下,以了解自出版以来语言发生了怎样的变化。
8. 观看讲座和课程。如果你学习的语言在在线课堂中有讲授,那么视频应该是公开的。除了学术讲座之外,还可以考虑寻找录制讲座、会议谈话和有关该语言的博客。当在看电视时,谈谈你的新语言是一个将学习融入日常生活很好的方式。
9. 阅读示例代码。大多数关于编程语言的书籍都会包含代码片段。你也可以在博客和 Rosetta Code 上找到示例代码。运行示例代码、修改它们,并尝试预测修改后会发生那些情况。
10. 阅读生产代码。查找有关该语言所有类型和大小的项目的一种方法是在 GitHub 上搜索它。按最受欢迎或最具影响力进行排序,你的热门搜索将包括最受欢迎的开源工具。如果想要了解开源项目的设计,可通过邮件列表或 IRC 来与社区进行互动。你甚至可能会发现一些 bug。
11. 寻找好的工具。当使用新的语言时,可向其更有经验的用户请教,询问他们的开发环境。你可能会发现,一个特定的文本编辑器或 IDE 对于新语言的支持比你习惯通常使用的要好。调查在新语言生态系统中管理依赖关系、格式化、模糊化和单元测试代码的选项。
12. 保持你的热情。入门新的语言很容易,但变得真正精通它通常是一个需要多年的旅程。庆祝一路上你的成功,并与追随你脚步的学习者分享你所学到的知识,保持着学习编程的兴趣。
关于编程鲜为人知的真相
程序员的经历让人知道了一些关于软件编程的事情,下面的这些事情可能会让朋友们对软件开发感到惊讶:
1. 一个程序员用在写程序上的时间大概占他的工作时间的10-20%,大部分的程序员每天大约能写出10-12行的能进入最终的产品的代码 — —不管他的技术水平有多高。好的程序员花去90%的时间在思考、研究和实验,来找出最优方案。差的程序员花去90%的时间在调试问题程序、盲目的修改程序,期望某种写法能可行。“一个卓越的车床工可以要求比一个一般的车床工多拿数倍高的工资,但一个卓越的软件写手的价值会10000倍于一个普通的写手。”——比尔 盖茨
2. 一个优秀的程序员的效率会是一个普通的程序员的十倍之上。一个伟大的程序员的效率会是一个普通程序员的20-100倍。这不是夸张 — — 1960年以来的无数研究都一致的证明了这一点。一个差的程序员不仅仅是没效率 — — 他不仅不能完成任务,写出的大量代码也让别人头痛的没法维护。
3. 伟大的程序员只花很少的时间去写代码——至少指那些最终形成产品的代码。那些要花掉大量时间写代码的程序员都是太懒惰,太自大,太傲慢,不屑用现有的方案去解决老问题。伟大的程序员的精明之处在于懂得欣赏和重复利用通用模式。好的程序员并不害怕经常的重构(重写)他们的代码以求达到最好效果。差的程序员写的代码缺乏整体概念,冗余,没有层次,没有模式,导致很难重构。把这些代码扔掉重做也比修改起来容易。
4. 软件遵循熵的定律,跟其它所有东西一样。持续的变更会导致软件腐烂,腐蚀掉对原始设计的完整性概念。软件的腐烂是不可避免的,但程序员在开发软件时没有考虑完整性,将会使软件腐烂的如此之快,以至于软件在还没有完成之前就已经毫无价值了。软件完整性上的熵变可能是软件项目失败最常见的原因(第二大常见失败原因是做出的不是客户想要的东西)。软件腐烂使开发进度呈指数级速度放缓,大量的软件在失败之前都是面对着突增的时间要求和资金预算。
5. 2004年的一项研究表明大多数的软件项目(51%)会在关键功能上失败,其中15%是完全的失败。这比1994年前有很大的改进,当时是31%。
6. 尽管大多数软件都是团体开发的,但这并不是一项民/主的活动。通常,一个人负责设计,其他人负责实现细节。
7. 编程是个很难的工作。是一种剧烈的脑力劳动。好的程序员7×24小时的思考他们的工作。他们最重要的程序都是在淋浴时、睡梦中写成的。因为这最重要的工作都是在远离键盘的情况下完成的,所以软件工程不可能通过增加在办公室的工作时间或增加人手来加快进度。
典型PC系统各种操作指令的大概时间
不适合做开发人员的十种迹象
程序员能够赚大钱,软件开发人员一周七天都可以随意穿戴;任何人都可以通过自学成为一名程序员,这些仅是人们想成为开发人员的一小 部分原因。不幸的是,人才市场中到处都是拥有原始智力或学问的应聘者,但是他们却不具有成为一名优秀程序员所需要的正确的态度或品格。在决定自己是否应当成为一名软件开发人员时,你应当考虑以下几件事情。
1. 宁愿培训,也不自学
即使公司对其他类型员工有合适的培训计划,大多数开发部门也很少给程序员提供培训机会,顶多为你报销买书的费用。他们都希望程序员踏进公司的第 一天就掌握了所有(至少大部分)必需的技术。更糟的是,他们主观地认为程序员都非常聪明,很擅长解决问题。这让上层管理人员相信,优秀的程序员不需要培训。最重要的,对开发人员的培训费用是相当昂贵的。结果呢?当你职位调动时,你要弄清楚接下来要做什么,必要的话就要自学一下了。
2. 喜欢正常的工作时间
软件开发项目不能按时交工是出了名的。从某种角度而言,即便是如期完工的项目也通常落后于计划表。如果你不能忍受(或不能处理)自己的业余时间,因上级的命令而失去规律或充满变数,那么你不适合做软件开发。到了关键时刻,上级只会在乎能否将产品如期交到资产雄厚的客户手上,而不是你孩子的足球比赛或你想看的一个新的电视节目。
3. 喜欢正常加薪胜过跳槽
软件开发行业,技术无时无刻不在贬值。除非你所在公司是和缓慢变化的技术打交道,否则,你的技术很可能一天不如一天值钱。目前技术发展水平飞速变化,今天还很热门的技术明天可能就无人问津了。因此,日复一日的重复着同样的工作,还期盼得到超过不断增长的生活费用的加薪是很困难的。要想保值,就必须保证自己的技术跟得上发展的步伐。此外,如果还想加薪,就必须大大扩充自己的技术,要么获得晋升,或者直接跳槽。
4. 无法和他人和睦共处
性格内向或喜欢一个人工作是一回事。无法与他人和睦共处是另一回事,而且作为一名开发人员,这会拖你的后腿。不仅如此,你的经理很可能是一名非技术人员(或很久没有亲自从事技术工作的技术人员),所以你必须善于向非技术人员表达自己的想法。
5. 容易垂头丧气
软件开发经常会让人产生挫败感。文件材料过于陈旧或有错误、之前的程序员写的代码晦涩难懂、老板规定了一些必须遵守但毫无意义的规定……诸如此类的事情不胜枚举。一天下来,没有人愿意和一个整天在无休止地咒骂或对着显示器尖叫的人一起工作。如果因为花了8个小时完成看似10分钟就能完成的任务而抓狂,那么开发工作不适合你。
6. 思想保守,不考虑他人建议
编程过程中遇到的问题往往都有很多解决方案。如果你不能正确对待他人的批评,或者不能认真聆听他人的意见,你很可能会漏掉一些重要的东西。举个例子,几周前,一名初级程序员给我提了一个建议。经过思考,我决定尝试一下,结果证明他是正确的,而我之前的想法是错误的,而且,他的建议让一段代码的运 行时间从之前的若干天一下缩短到几个小时。如果因为经验水平的不同而忽略他的意见,那是多么愚蠢啊。
7. 不注重细节
编程过程处处都是细节。如果一部情节比《野蛮人柯南》复杂一点的电影就弄得你晕头转向,或者填写一个折扣单就让你感觉很费劲的话,那么你在软件开发这个行业也不会有长足发展。有时,像少一个句号这样的小错误,就会让原本很完美的程序产生随机错误。如果你连哪里少了句号都搞不清楚,恐怕你在这一 行业也不会有很大发展。
8. 没有工作自豪感
当然,循规蹈矩式的编写一个说得过得去的程序是有可能的。问题是,规则不是一成不变的。软件开发不像是在工厂里整天拧同样的螺丝,拧的力度大了小了都无所谓,它需要独立思考,进而需要开发人员对工作有自豪感。而且软件开发过程中,一些错误的做法很可能一开始不会对整个工作有不良影响。那些你所忽视的、看似不会引起麻烦的“小错误”,最终会酿成大祸。没有工作自豪感、不认真对待每个项目的程序员工作质量不高,从而编程事业也不会长久。
9. 不三思而后行
比起编写程序,软件开发人员(至少是优秀的开发人员)会在项目计划上花费更多的时间。通常,当程序员不假思索地打开程序编辑器就开始写代码时,他们写的大部分代码稍后就会作废。而经过深思熟虑后写出来的代码错误会更少,而且耗时短。很多程序员不知道如何合理编写程序是有原因的:软件开发的难点在于知道要编写什么,不事先仔细思考就开始盲目工作只会事倍功半。如果你只会实干不会思考,或许软件开发这项工作并不适合你。
10. 不喜欢极客类型的人
出于种种原因(其中一些是合理的),很多人不喜欢与工程师或技术人员相处。如果你认为与像呆伯特或怪人奥尔那样的人相处是一种煎熬的话,那趁早放弃进入编程行业的念头吧。所有的开发人员都像那样性格怪异吗?当然不是。但也不乏古怪的人,这足以让你在这个行业痛苦不堪。
每学一门编程语言,都离不开学习它的语言特征:
支持哪些基本数据类型,如整数,浮点数,布尔值,字符串,支持哪些高级数据类型,如数组,结构体等。
if判断和while循环语句是怎样的,是否有switch或者goto等语句。
语言函数的定义是怎样的,如何传递函数参数,有没有面向对象的语言特征等。
package包管理是怎样的,如何管理一个工程,官方提供哪些标准库,如时间处理,字符串处理,HTTP 库,加密库等。
有没有特殊的语言特征,其他语言没有的,比如某些语法糖。
传统的编程语言通常都会有如下一些缺点:
学习成本太高,如C++,为准确表达作者思想,我们要花费大量时间学习语言
编译速度太慢,代码的编写、预处理、编译与运行流程花费时间太长
缺乏类型检查,主要指诸如perl、python、php等解释性语言,这常会导致一些低级错误发生
而且计算机领域相比于前些年也发生了很多变化,比如:
计算机硬件发展迅速,软件已经不能充分发挥它们的优势,比如多CPU
语言越来越复杂,要么并发与性能不佳,要么风格不够优雅且不统一
人力成本越高越贵,项目的迭代周期越来越短
普通程序员与高级程序员的差别在哪
同样都是敲代码,为什么别人一个月工资几万,你一个月却只拿五千?是单纯在找工作的时候运气不佳?还是因为技术水平有差别?那些被大众膜拜信仰的技术大神到底牛在哪里,现状已定,普通程序员是否还有机会逆袭?或许你能从下面的总结中找到答案。从思维和习惯角度看,普通程序员和高级程序员的差别主要体现在以下四个方面:
缺乏编程思维
编程思维又叫Computational Thinking,指的是从理解问题到解决问题的思考方式,具体到程序员的实际开发工作中来看,当拥有编程思维的程序员接到一个新的需求,他们总是能迅速在大脑中分解复杂问题,将注意力聚焦到重点问题上并提前预设解决路径,比如这个需求对现有逻辑有什么影响?怎样操作才是最优解?一旦变更数据会存在哪些风险?团队最少需要多久的开发周期才能交付?拥有编程思维的高级程序员能从产品经理的需求中思考为什么要这么做。而普通程序员在收到新需求的第一反应大多不是思考,而是吐槽“为什么又要改需求,他/她到底懂不懂产品”,然后在愤懑中闷头敲代码、改Bug、继续敲代码、继续改Bug,陷入无止境的循环当中。到最后,没有编程思维的人,敲再多的代码,也只能做一名普通程序员。
不知道怎么解决Bug
普通程序员发现Bug后,直接复制粘贴靠百度,“一杯茶,一根烟,一个Bug想一天”,能不能解决全靠运气。高级程序员在发现程序报错后,首先会查看浏览器控制台是否发送了对应的请求,如果是的话再看请求码是什么,然后根据不同的错误码做出不同的调试方案,要么通过报错日志找到对应的地点进行修改,要么通过开发工具断点调试,顺藤摸瓜找到最终问题。当问题解决后,有经验的高手往往会复盘总结处理好善后问题,下次再出现类似情况就能第一时间做出反应,普通人与高手的差距往往体现在解决问题的能力上。
没有养成良好的学习习惯
我们大部分人都习惯了接受填鸭式教育,上学期间大家还尚有学习的动力,但有多少人在工作后依然能够保持良好的学习习惯?技术的世界日新月异,当很多人还停留在JDK8的时候JDK16已经悄然问世,从SpringMVC到SpringBoot再到SpringCloud全家桶,不同版本的框架正在以迅雷不及掩耳之势快速更新。很多程序员在毕业后便不再主动学习,他们的技术水平也就停留在了刚进公司的那几个月。时光流逝,每年有大量更年轻、更有热情的应届生走出校门,他们随时都有可能替代掉高薪低性价比的普通程序员,如果没有主动学习、终生学习的意识,这批人注定将会被技术大潮所淘汰。
视野狭窄,缺乏长期的目标规划
程序员长期处在996、007繁忙的工作节奏中,鲜少有时间停下来去思考自己的目标到底是什么,现在的你和刚毕业时的你相比有什么变化?五年之后你希望自己活成什么样子?很多人每天只是马不停蹄地处理各种领导派下来的任务和产品经理提出的新需求,却从来没有驻足思考过自己的目标规划和后续进步的方向。每天在舒适圈中闷头敲代码只会让自己的视野越来越狭窄,当一个程序员做到了一定程度,除了技术本身之外,视野、圈子和人脉变得越来越重要,这也直接关乎程序员个人的晋升空间。
问题摆在面前,普通程序员要想实现技术水平的跃迁,必须有针对性地做出改变。
首先,要敢于自我革新,与过去的思维习惯划清界限重新开始。在日常工作中,多去看看“大神”做的项目,看他在一开始的时候是如何设计项目的,在编程的过程中对数据库进行了哪些操作,以及为什么这么做。久而久之,当你自己的项目遇到复杂的需求时,你也能够在这个思路的基础上进行难点拆分,不断改进优化项目,这将会是你进步的开始。
其次,拓宽视野,培养终生学习的习惯。将目光从个人所在岗位转移到行业中去,多去了解国内外的技术圈发生了什么,多去看看行业内外正在进行哪些变革,每天抽出一个小时的阅读时间,从被动学习转变为主动学习。“人生在勤,不索何获”,只有站在巨人的肩膀上不断学习,才能获得长远发展机会。
最后,制定长期发展目标。想清楚自己到底想要从事什么岗位,未来在这一岗位上想要达到什么结果,将大的目标切分成阶段性目标,以此为导向不断努力。就算阶段性目标失败了也没有关系,回过头复盘总结,看在哪些地方还有进步空间。
深入理解数学与计算机系统
程序员到一定的阶段,拼的数学能力和对计算机系统的理解。数学能力需要投入的教育成本是比较高的,毕竟这是个长期的系统性工程,但是作为 IT 从业者、程序员,我认为还是需要把计算机系统搞明白、搞透,这个过程比起恶补数学,要轻松多了。曾经请教过很多大厂架构师,我发现他们对硬件的掌握水准之高,远远超过我这个硬件开发工程师的预想。看看下面这张图,内存读写流程,这个流程估计很多程序员都搞不太清楚,的确,99% 的几率用不到,但是可能就是那 1% 将决定你的职业走势。
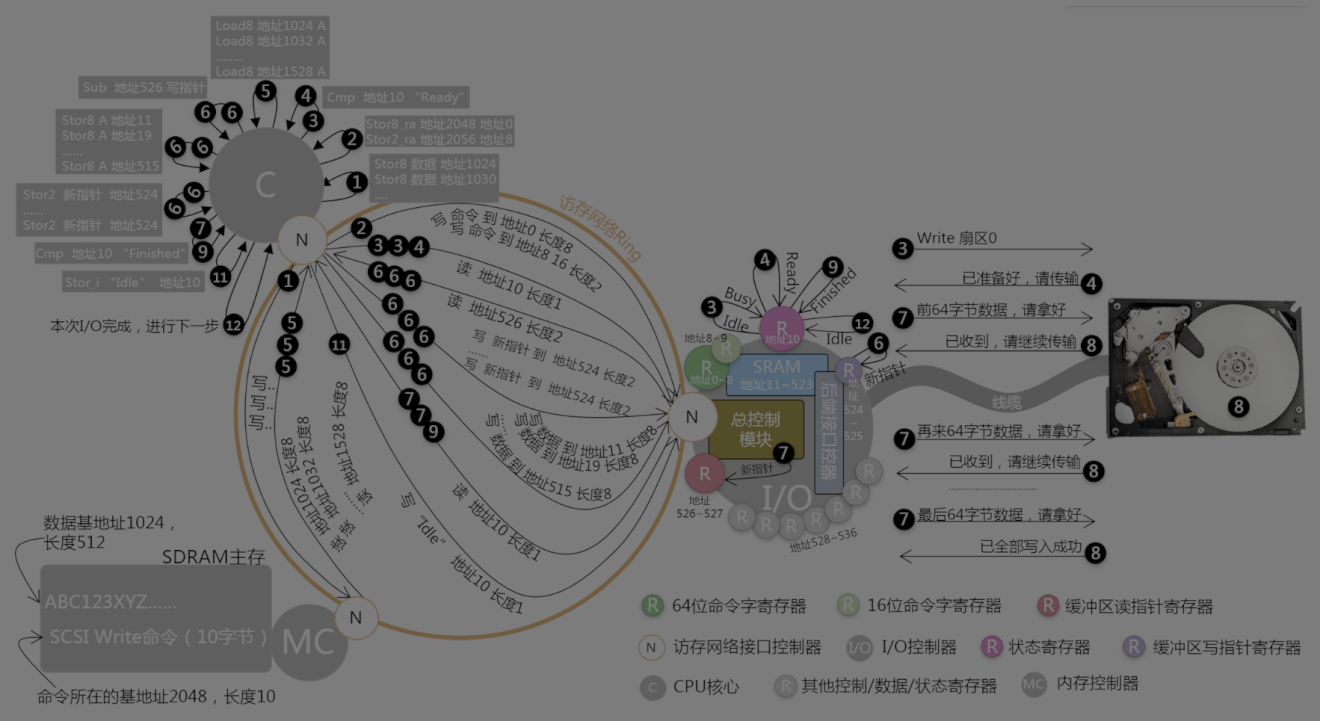
一切信息技术生态都是建立在计算机硬件系统之上的,如果不夯实这个底层领域的知识体系,那么上层的知识体系就难免成为空中楼阁。掌握计算机底层,相当于掌握基本的物理学,正如基本的物理学被纳入义务教育阶段一样,掌握计算机底层,应该是每个 IT 从业者的基本功。
防御性编程二三事
几大基本原则
当开发人员遇到意外的错误无法修复时,他们会“添加一些防御性代码”来使代码更安全,更容易找到问题所在。有时候,仅仅这样做就能解决问题。他们会加强数据验证 —— 确保检查输入和输出字段以及返回值。审查并改进错误处理 —— 也许在 “不可能”的情况周围添加一些检查。增加一些有用的日志记录和诊断功能。换句话说,这些本应该从一开始就存在的代码。
防御性编程的整个目的是为了防范你意想不到的错误。
——Steve McConnell,《代码大全》
防御性编程的几个基本原则在 Steve McConnell 经典著作《代码大全》中有详细解释:
保护你的代码免受 “外部” 传入的无效数据影响,无论你认为 “外部” 是指什么地方。这里指来自外部系统、用户、文件或模块 / 组件之外的任何数据。建立 “壁垒”、“安全区域” 或 “信任边界”——边界之外的一切都是危险的,边界之内的一切都是安全的。在壁垒代码中,验证所有输入数据:检查所有输入参数的正确类型、长度和取值范围。再次检查限制和范围。
在检查完坏数据后,决定如何处理它。防御性编程并不意味着吞没错误或隐藏错误。它是关于在健壮性(如果遇到可处理的问题则继续运行)和正确性(永远不返回错误结果)之间做出权衡。选择一种处理坏数据的策略:立即返回错误并停止运行(快速失败),返回一个中立值,替换数据值等等。确保策略明确且一致。
不要假设你代码之外的函数调用或方法调用会按照广告所述正常工作。确保你理解并测试了周围外部 API 和库的错误处理机制。
使用断言来记录假设,并突出显示 “不可能” 的条件,至少在开发和测试阶段如此。这对于长期由不同人维护或高可靠性代码特别重要。
巧妙地添加诊断代码、日志记录和跟踪功能,以帮助解释运行时发生了什么问题,尤其是当遇到问题时。
标准化错误处理。决定如何处理 “正常错误” 或 “预期错误” 和警告,并始终保持一致。
只在需要时使用异常处理,并确保你对语言的异常处理机制了如指掌。将异常作为正常处理流程的一部分的程序会遭受经典意义上代码结构混乱的可读性和可维护性问题。
Michael Nygard 在《发布!》中还提到了其他几个规则,比如永远不要无限期等待外部调用,尤其是远程调用。当出现问题时,无限期可能会很长时间。使用超时 /重试逻辑以及他的断路器稳定模式来处理远程故障。
对于 C 和 C++ 等编程语言,防御性编程还包括使用安全函数调用来避免缓冲区溢出和常见编码错误。
让自己稳拿饭碗
简介
永远不要(把自己遇到的问题)归因于(他人的)恶意,这恰恰说明了(你自己的)无能。 -- 拿破仑
为了造福大众,在 Java 编程领域创造就业机会,兄弟我在此传授大师们的秘籍。这些大师写的代码极其难以维护,后继者就是想对它做最简单的修改都需要花上数年时间。而且,如果你能对照秘籍潜心修炼,你甚至可以给自己弄个铁饭碗,因为除了你之外,没人能维护你写的代码。再而且,如果你能练就秘籍中的全部招式,那么连你自己都无法维护你的代码了!
你不想练功过度走火入魔吧。那就不要让你的代码一眼看去就完全无法维护,只要它实质上是那样就行了。否则,你的代码就有被重写或重构的风险!
总体原则
Quidquid latine dictum sit, altum sonatur.
(随便用拉丁文写点啥都会显得高大上。)
想挫败维护代码的程序员,你必须先明白他的思维方式。他接手了你的庞大程序,没有时间把它全部读一遍,更别说理解它了。他无非是想快速找到修改代码的位置、改代码、编译,然后就能交差,并希望他的修改不会出现意外的副作用。
他查看你的代码不过是管中窥豹,一次只能看到一小段而已。你要确保他永远看不到全貌。要尽量和让他难以找到他想找的代码。但更重要的是,要让他不能有把握忽略任何东西。
程序员都被编程惯例洗脑了,还为此自鸣得意。每一次你处心积虑地违背编程惯例,都会迫使他必须用放大镜去仔细阅读你的每一行代码。你可能会觉得每个语言特性都可以用来让代码难以维护,其实不然。你必须精心地误用它们才行。
命名
"当我使用一个单词的时候" Humpty Dumpty 曾经用一种轻蔑的口气说," 它就是我想表达的意思,不多也不少。“
- Lewis Carroll -- 《爱丽丝魔镜之旅》, 第 6 章
编写无法维护代码的技巧的重中之重是变量和方法命名的艺术。如何命名是和编译器无关的。这就让你有巨大的自由度去利用它们迷惑维护代码的程序员。
妙用 宝宝起名大全
买本宝宝起名大全,你就永远不缺变量名了。比如 Fred 就是个好名字,而且键盘输入它也省事。如果你就想找一些容易输入的变量名,可以试试 adsf 或者 aoeu 之类。
单字母变量名
如果你给变量起名为 a,b,c,用简单的文本编辑器就没法搜索它们的引用。而且,没人能猜到它们的含义。
创造性的拼写错误
如果你必须使用描述性的变量和函数名,那就把它们都拼错。还可以把某些函数和变量名拼错,再把其他的拼对 (例如 SetPintleOpening 和 SetPintalClosing) ,我们就能有效地将 grep 或 IDE 搜索技术玩弄于股掌之上。这招超级管用。还可以混淆不同语言(比如 colour -- 英国英语,和 color -- 美国英语)。
抽象
在命名函数和变量的时候,充分利用抽象单词,例如 it, everything, data, handle, stuff, do, routine, perform 和数字,例如 e.g. routineX48, PerformDataFunction, DoIt, HandleStuff 还有 do_args_method。
首字母大写的缩写
用首字母大写缩写(比如 GNU 代表 GNU's Not Unix) 使代码简洁难懂。真正的汉子 (无论男女) 从来不说明这种缩写的含义,他们生下来就懂。
辞典大轮换
为了打破沉闷的编程气氛,你可以用一本辞典来查找尽量多的同义词。例如 display, show, present。在注释里含糊其辞地暗示这些命名之间有细微的差别,其实根本没有。不过,如果有两个命名相似的函数真的有重大差别,那倒是一定要确保它们用相同的单词来命名 (例如,对于 "写入文件", "在纸上书写" 和 "屏幕显示" 都用 print 来命名)。在任何情况下都不要屈服于编写明确的项目词汇表这种无理要求。你可以辩解说,这种要求是一种不专业的行为,它违反了结构化设计的信息隐藏原则。
首字母大写
随机地把单词中间某个音节的首字母大写。例如 ComputeReSult()。
重用命名
在语言规则允许的地方,尽量把类、构造器、方法、成员变量、参数和局部变量都命名成一样。更高级的技巧是在 {} 块中重用局部变量。这样做的目的是迫使维护代码的程序员认真检查每个示例的范围。特别是在 Java 代码中,可以把普通方法伪装成构造器。
使用非英语字母
在命名中偷偷使用不易察觉的非英语字母,例如看上去没啥不对是吧?嘿嘿嘿... 这里的第二个 ínt 的 í 实际上是东北欧字母,并不是英语中的 i 。在简单的文本编辑器里,想看出这一点点区别几乎是不可能的。
巧妙利用编译器对于命名长度的限制
如果编译器只区分命名的前几位,比如前 8 位,那么就把后面的字母写得不一样。比如,其实是同一个变量,有时候写成 var_unit_update() ,有时候又写成 var_unit_setup(),看起来是两个不同的函数调用。而在编译的时候,它们其实是同一个变量 var_unit。
下划线,一位真正的朋友
可以拿 _ 和 __ 作为标示符。
混合多语言
随机地混用两种语言(人类语言或计算机语言都行)。如果老板要求使用他指定的语言,你就告诉他你用自己的语言更有利于组织你的思路,万一这招不管用,就去控诉这是语言歧视,并威胁起诉老板要求巨额精神损失赔偿。
扩展 ASCII 字符
扩展 ASCII 字符用于变量命名是完全合法的,包括 ß, Ð, 和 ñ 等。在简单的文本编辑器里,除了拷贝 / 粘贴,基本上没法输入。
其他语言的命名
使用外语字典作为变量名的来源。例如,可以用德语单词 punkt 代替 point。除非维护代码的程序员也像你一样熟练掌握了德语。不然他就只能尽情地在代码中享受异域风情了。
数学命名
用数学操作符的单词来命名变量。例如:
openParen = (slash + asterix) / equals;
(左圆括号 = (斜杠 + 星号)/ 等号;)
令人眩晕的命名
用带有完全不相关的感情色彩的单词来命名变量。例如:这一招可以让阅读代码的人陷入迷惑之中,因为他们在试图想清楚这些命名的逻辑时,会不自觉地联系到不同的感情场景里而无法自拔。
marypoppins = (superman + starship) / god;
(欢乐满人间 = (超人 + 星河战队)/ 上帝;)
何时使用 i
永远不要把 i 用作最内层的循环变量。 用什么命名都行,就是别用 i。把 i 用在其他地方就随便了,用作非整数变量尤其好。
惯例 -- 明修栈道,暗度陈仓
忽视 Java 编码惯例,Sun 就是这样做的。幸运的是,你违反了它编译器也不会打小报告。这一招的目的是搞出一些在某些特殊情况下有细微差别的名字来。如果你被强迫遵循驼峰法命名,你还是可以在某些模棱两可的情况下颠覆它。例如,inputFilename 和 inputfileName 两个命名都可以合法使用。在此基础上自己发明一套复杂到变态的命名惯例,然后就可以痛扁其他人,说他们违反了惯例。
小写的 l 看上去很像数字 1
用小写字母 l 标识 long 常数。例如 10l 更容易被误认为是 101 而不是 10L 。 禁用所有能让人准确区分 uvw wW gq9 2z 5s il17|!j oO08 `'" ;,. m nn rn {[()]} 的字体。要做个有创造力的人。
把全局命名重用为私有
在 A 模块里声明一个全局数组,然后在 B 模块的头文件里在声明一个同名的私有数组,这样看起来你在 B 模块里引用的是那个全局数组,其实却不是。不要在注释里提到这个重复的情况。
误导性的命名
让每个方法都和它的名字蕴含的功能有一些差异。例如,一个叫 isValid(x) 的方法在判断完参数 x 的合法性之后,还顺带着把它转换成二进制并保存到数据库里。
伪装
当一个 bug 需要越长的时间才会暴露,它就越难被发现。
- Roedy Green(本文作者)
编写无法维护代码的另一大秘诀就是伪装的艺术,即隐藏它或者让它看起来像其他东西。很多招式有赖于这样一个事实:编译器比肉眼或文本编辑器更有分辨能力。下面是一些伪装的最佳招式。
把代码伪装成注释,反之亦然
下面包括了一些被注释掉的代码,但是一眼看去却像是正常代码。 如果不是用绿色标出来,你能注意到这三行代码被注释掉了么?
for(j=0; j<array_len; j+ =8){
total += array[j+0 ];
total += array[j+1 ];
total += array[j+2 ]; /* Main body of
total += array[j+3]; * loop is unrolled
total += array[j+4]; * for greater speed.
total += array[j+5]; */
total += array[j+6 ];
total += array[j+7 ];
}
用连接符隐藏变量
对于下面的定义
#define local_var xy_z
可以把 "xy_z" 打散到两行里:
#define local_var xy\
_z // local_var OK
这样全局搜索 xy_z 的操作在这个文件里就一无所获了。对于 C 预处理器来说,第一行最后的 "\" 表示继续拼接下一行的内容。
文档
任何傻瓜都能说真话,而要把谎编圆则需要相当的智慧。
- Samuel Butler (1835 - 1902)
不正确的文档往往比没有文档还糟糕。
- Bertrand Meyer
既然计算机是忽略注释和文档的,你就可以在里边堂而皇之地编织弥天大谎,让可怜的维护代码的程序员彻底迷失。
在注释中撒谎
实际上你不需要主动地撒谎,只要没有及时保持注释和代码更新的一致性就可以了。
只记录显而易见的东西
往代码里掺进去类似于 /* 给 i 加 1 */ 这样的注释,但是永远不要记录包或者方法的整体设计这样的干货。
记录 How 而不是 Why
只解释一个程序功能的细节,而不是它要完成的任务是什么。这样的话,如果出现了一个 bug,修复者就搞不清这里的代码应有的功能。
该写的别写
比如你在开发一套航班预定系统,那就要精心设计,让它在增加另一个航空公司的时候至少有 25 处代码需要修改。永远不要在文档里说明要修改的位置。后来的开发人员要想修改你的代码门都没有,除非他们能把每一行代码都读懂。
计量单位
永远不要在文档中说明任何变量、输入、输出或参数的计量单位,如英尺、米、加仑等。计量单位对数豆子不是太重要,但在工程领域就相当重要了。同理,永远不要说明任何转换常量的计量单位,或者是它的取值如何获得。要想让代码更乱的话,你还可以在注释里写上错误的计量单位,这是赤裸裸的欺骗,但是非常有效。如果你想做一个恶贯满盈的人,不妨自己发明一套计量单位,用自己或某个小人物的名字命名这套计量单位,但不要给出定义。万一有人挑刺儿,你就告诉他们,你这么做是为了把浮点数运算凑成整数运算而进行的转换。
坑
永远不要记录代码中的坑。如果你怀疑某个类里可能有 bug,天知地知你知就好。如果你想到了重构或重写代码的思路,看在老天爷的份上,千万别写出来。切记电影《小鹿斑比》里那句台词 "如果你不能说好听的话,那就什么也不要说。"。万一这段代码的原作者看到你的注释怎么办?万一老板看到了怎么办?万一客户看到了怎么办?搞不好最后你自己被解雇了。一句” 这里需要修改 “的匿名注释就好多了,尤其是当看不清这句注释指的是哪里需要修改的情况下。切记难得糊涂四个字,这样大家都不会感觉受到了批评。
说明变量
永远不要对变量声明加注释。有关变量使用的方式、边界值、合法值、小数点后的位数、计量单位、显示格式、数据录入规则等等,后继者完全可以自己从程序代码中去理解和整理嘛。如果老板强迫你写注释,就把方法体代码混进去,但绝对不要对变量声明写注释,即使是临时变量!
在注释里挑拨离间
为了阻挠任何雇佣外部维护承包商的倾向,可以在代码中散布针对其他同行软件公司的攻击和抹黑,特别是可能接替你工作的其中任何一家。例如:
/* 优化后的内层循环
这套技巧对于 SSI 软件服务公司的那帮蠢材来说太高深了,他们只会
用 <math.h> 里的笨例程,消耗 50 倍的内存和处理时间。
*/
class clever_SSInc
{
.. .
}
可能的话,除了注释之外,这些攻击抹黑的内容也要掺到代码里的重要部分,这样如果管理层想清理掉这些攻击性的言论然后发给外部承包商去维护,就会破坏代码结构。
程序设计
编写无法维护代码的基本规则就是:在尽可能多的地方,以尽可能多的方式表述每一个事实。
- Roedy Green
编写可维护代码的关键因素是只在一个地方表述应用里的一个事实。如果你的想法变了,你也只在一个地方修改,这样就能保证整个程序正常工作。所以,编写无法维护代码的关键因素就是反复地表述同一个事实,在尽可能多的地方,以尽可能多的方式进行。令人高兴的是,像 Java 这样的语言让编写这种无法维护代码变得非常容易。例如,改变一个被引用很多的变量的类型几乎是不可能的,因为所有造型和转换功能都会出错,而且关联的临时变量的类型也不合适了。而且,如果变量值要在屏幕上显示,那么所有相关的显示和数据录入代码都必须一一找到并手工进行修改。类似的还有很多,比如由 C 和 Java 组成的 Algol 语言系列,Abundance 甚至 Smalltalk 对于数组等结构的处理,都是大有可为的。
Java 造型
Java 的造型机制是上帝的礼物。你可以问心无愧地使用它,因为 Java 语言本身就需要它。每次你从一个 Collection 里获取一个对象,你都必须把它造型为原始类型。这样这个变量的类型就必须在无数地方表述。如果后来类型变了,所有的造型都要修改才能匹配。如果倒霉的维护代码的程序员没有找全(或者修改太多),编译器能不能检测到也不好说。类似的,如果变量类型从 short 变成 int,所有匹配的造型也都要从 (short) 改成 (int)。
利用 Java 的冗余
Java 要求你给每个变量的类型写两次表述。 Java 程序员已经习惯了这种冗余,他们不会注意到你的两次表述有细微的差别,例如
Bubblegum b = new Bubblegom();
不幸的是 ++ 操作符的盛行让下面这种伪冗余代码得手的难度变大了:
swimmer = swimner + 1;
永远不做校验
永远不要对输入数据做任何的正确性或差异性检查。这样能表现你对公司设备的绝对信任,以及你是一位信任所有项目伙伴和系统管理员的团队合作者。总是返回合理的值,即使数据输入有问题或者错误。
有礼貌,无断言
避免使用 assert () 机制,因为它可能把三天的 debug 盛宴变成 10 分钟的快餐。
避免封装
为了提高效率,不要使用封装。方法的调用者需要所有能得到的外部信息,以便了解方法的内部是如何工作的。
复制粘贴修改
以效率的名义,使用 复制 + 粘贴 + 修改。这样比写成小型可复用模块效率高得多。在用代码行数衡量你的进度的小作坊里,这招尤其管用。
使用静态数组
如果一个库里的模块需要一个数组来存放图片,就定义一个静态数组。没人会有比 512 X 512 更大的图片,所以固定大小的数组就可以了。为了最佳精度,就把它定义成 double 类型的数组。
傻瓜接口
编写一个名为 "WrittenByMe" 之类的空接口,然后让你的所有类都实现它。然后给所有你用到的 Java 内置类编写包装类。这里的思想是确保你程序里的每个对象都实现这个接口。最后,编写所有的方法,让它们的参数和返回类型都是这个 WrittenByMe。这样就几乎不可能搞清楚某个方法的功能是什么,并且所有类型都需要好玩的造型方法。更出格的玩法是,让每个团队成员编写它们自己的接口 (例如 WrittenByJoe),程序员用到的任何类都要实现他自己的接口。这样你就可以在大量无意义接口中随便找一个来引用对象了。
巨型监听器
永远不要为每个组件创建分开的监听器。对所有按钮总是用同一个监听器,只要用大量的 if...else 来判断是哪一个按钮被点击就行了。
好事成堆 TM
狂野地使用封装和 OO 思想。例如这段很可能看起来不怎么好笑。别担心,只是时候未到而已。
myPanel.add( getMyButton() );
private JButton getMyButton()
{
return myButton;
}
友好的朋友
在 C++ 里尽量多使用 friend 声明。再把创建类的指针传递给已创建类。现在你不用浪费时间去考虑接口了。另外你应该用上关键字 private 和 protected 来表明你的类封装得很好。
使用三维数组
大量使用它们。用扭曲的方式在数组之间移动数据,比如用 arrayA 里的行去填充 arrayB 的列。这么做的时候,不管三七二十一再加上 1 的偏移值,这样很灵。让维护代码的程序员抓狂去吧。
混合与匹配
存取方法和公共变量神马的都要给他用上。这样的话,你无需调用存取器的开销就可以修改一个对象的变量,还能宣称这个类是个 "Java Bean"。对于那些试图添加日志函数来找出改变值的源头的维护代码的程序员,用这一招来迷惑他尤其有效。
没有秘密!
把每个方法和变量都声明为 public。毕竟某个人某天可能会需要用到它。一旦方法被声明为 public 了,就很难缩回去。对不?这样任何它覆盖到的代码都很难修改了。它还有个令人愉快的副作用,就是让你看不清类的作用是什么。如果老板质问你是不是疯了,你就告诉他你遵循的是经典的透明接口原则。
全堆一块
把你所有的没用的和过时的方法和变量都留在代码里。毕竟说起来,既然你在 1976 年用过一次,谁知道你啥时候会需要再用到呢?当然程序是改了,但它也可能会改回来嘛,你"不想要重新发明轮子"(领导们都会喜欢这样的口气)。如果你还原封不动地留着这些方法和变量的注释,而且注释写得又高深莫测,甭管维护代码的是谁,恐怕都不敢对它轻举妄动。
就是 Final
把你所有的叶子类都声明为 final。毕竟说起来,你在项目里的活儿都干完了,显然不会有其他人会通过扩展你的类来改进你的代码。这种情况甚至可能有安全漏洞。 java.lang.String 被定义成 final 也许就是这个原因吧?如果项目组其他程序员有意见,告诉他们这样做能够提高运行速度。
避免布局
永远不要用到布局。当维护代码的程序员想增加一个字段,他必须手工调整屏幕上显示所有内容的绝对坐标值。如果老板强迫你使用布局,那就写一个巨型的 GridBagLayout 并在里面用绝对坐标进行硬编码。
全局变量,怎么强调都不过分
如果上帝不愿意我们使用全局变量,他就不会发明出这个东西。不要让上帝失望,尽量多使用全局变量。每个函数最起码都要使用和设置其中的两个,即使没有理由也要这么做。毕竟,任何优秀的维护代码的程序员都会很快搞清楚这是一种侦探工作测试,有利于让他们从笨蛋中脱颖而出。
再一次说说全局变量
全局变量让你可以省去在函数里描述参数的麻烦。充分利用这一点。在全局变量中选那么几个来表示对其他全局变量进行操作的类型。
局部变量
永远不要用局部变量。在你感觉想要用的时候,把它改成一个实例或者静态变量,并无私地和其他方法分享它。这样做的好处是,你以后在其他方法里写类似声明的时候会节省时间。C++ 程序员可以百尺竿头更进一步,把所有变量都弄成全局的。
配置文件
配置文件通常是以 关键字 = 值 的形式出现。在加载时这些值被放入 Java 变量中。最明显的迷惑技术就是把有细微差别的名字用于关键字和 Java 变量。甚至可以在配置文件里定义运行时根本不会改变的常量。参数文件变量和简单变量比,维护它的代码量起码是后者的 5 倍。
子类
对于编写无法维护代码的任务来说,面向对象编程的思想简直是天赐之宝。如果你有一个类,里边有 10 个属性(成员/方法),可以考虑写一个基类,里面只有一个属性,然后产生 9 层的子类,每层增加一个属性。等你访问到最终的子类时,你才能得到全部 10 个属性。如果可能,把每个类的声明都放在不同的文件里。
编码迷局
迷惑 C
从互联网上的各种混乱 C 语言竞赛中学习,追随大师们的脚步。
追求极致
总是追求用最迷惑的方式来做普通的任务。例如要用数组来把整数转换为相应的字符串,可以这么做:
char *p;
switch (n){
case 1:
p = "one";
if (0)
case 2:
p = "two";
if (0)
case 3:
p = "three";
printf("%s", p);
break;
}
一致性的小淘气
当你需要一个字符常量的时候,可以用多种不同格式: ' ', 32, 0x20, 040。在 C 或 Java 里 10 和 010 是不同的数(0 开头的表示 16 进制),你也可以充分利用这个特性。
造型
把所有数据都以 void * 形式传递,然后再造型为合适的结构。不用结构而是通过位移字节数来造型也很好玩。
嵌套 Switch
Switch 里边还有 Switch,这种嵌套方式是人类大脑难以破解的。
利用隐式转化
牢记编程语言中所有的隐式转化细节。充分利用它们。数组的索引要用浮点变量,循环计数器用字符,对数字执行字符串函数调用。不管怎么说,所有这些操作都是合法的,它们无非是让源代码更简洁而已。任何尝试理解它们的维护者都会对你感激不尽,因为他们必须阅读和学习整个关于隐式数据类型转化的章节,而这个章节很可能是他们来维护你的代码之前完全忽略了的。
分号!
在所有语法允许的地方都加上分号,例如:
if(a);
else;
{
int d;
d = c;
};
使用八进制数
把八进制数混到十进制数列表里,就像这样:
array = new int []
{
111,
120,
013,
121,
};
嵌套
尽可能深地嵌套。优秀的程序员能在一行代码里写 10 层 (),在一个方法里写 20 层 {}。
C 数组
C 编译器会把 myArray[i] 转换成 *(myArray + i),它等同于 *(i + myArray) 也等同于 i[myArray]。高手都知道怎么用好这个招。可以用下面的函数来产生索引,这样就把代码搞乱了:
int myfunc(int q, int p) { return p%q; }
...
myfunc(6291, 8)[Array];
遗憾的是,这一招只能在本地 C 类里用,Java 还不行。
放长线钓大鱼
一行代码里堆的东西越多越好。这样可以省下临时变量的开销,去掉换行和空格还可以缩短源文件大小。记住,要去掉运算符两边的空格。优秀的程序员总是能突破某些编辑器对于 255 个字符行宽的限制。
异常
我这里要向你传授一个编程中鲜为人知的秘诀。异常是个讨厌的东西。良好的代码永远不会出错,所以异常实际上是不必要的。不要把时间浪费在这上面。子类异常是给那些知道自己代码会出错的低能儿用的。在整个应用里,你只用在 main () 里放一个 try/catch,里边直接调用 System.exit () 就行了。在每个方法头要贴上标准的抛出集合定义,到底会不会抛出异常你就不用管了。
使用异常的时机
在非异常条件下才要使用异常。比如终止循环就可以用 ArrayIndexOutOfBoundsException。还可以从异常里的方法返回标准的结果。
狂热奔放地使用线程
测试
在程序里留些 bug,让后继的维护代码的程序员能做点有意思的事。精心设计的 bug 是无迹可寻的,而且谁也不知道它啥时候会冒出来。要做到这一点,最简单的办法的就是不要测试代码。
永不测试
永远不要测试负责处理错误、当机或操作系故障的任何代码。反正这些代码永远也不会执行,只会拖累你的测试。还有,你怎么可能测试处理磁盘错误、文件读取错误、操作系统崩溃这些类型的事件呢?为啥你要用特别不稳定的计算机或者用测试脚手架来模拟这样的环境?现代化的硬件永远不会崩溃,谁还愿意写一些仅仅用于测试的代码?这一点也不好玩。如果用户抱怨,你就怪到操作系统或者硬件头上。他们永远不会知道真相的。
永远不要做性能测试
嘿,如果软件运行不够快,只要告诉客户买个更快的机器就行了。如果你真的做了性能测试,你可能会发现一个瓶颈,这会导致修改算法,然后导致整个产品要重新设计。谁想要这种结果?而且,在客户那边发现性能问题意味着你可以免费到外地旅游。你只要备好护照和最新照片就行了。
永远不要写任何测试用例
永远不要做代码覆盖率或路径覆盖率测试。自动化测试是给那些窝囊废用的。搞清楚哪些特性占到你的例程使用率的 90%,然后把 90% 的测试用在这些路径上。毕竟说起来,这种方法可能只测试到了大约你代码的 60%,这样你就节省了 40% 的测试工作。这能帮助你赶上项目后端的进度。等到有人发现所有这些漂亮的 “市场特性” 不能正常工作的时候,你早就跑路了。一些有名的大软件公司就是这样测试代码的,所以你也应该这样做。如果因为某种原因你还没走,那就接着看下一节。
测试是给懦夫用的
勇敢的程序员会跳过这个步骤。太多程序员害怕他们的老板,害怕丢掉工作,害怕客户的投诉邮件,害怕遭到起诉。这种恐惧心理麻痹了行动,降低了生产率。有科学研究成果表明,取消测试阶段意味着经理有把握能提前确定交付时间,这对于规划流程显然是有利的。消除了恐惧心理,创新和实验之花就随之绽放。程序员的角色是生产代码,调试工作完全可以由技术支持和遗留代码维护组通力合作来进行。
如果我们对自己的编程能力有充分信心,那么测试就没有必要了。如果我们逻辑地看待这个问题,随便一个傻瓜都能认识到测试根本都不是为了解决技术问题,相反,它是一种感性的信心问题。针对这种缺乏信心的问题,更有效的解决办法就是完全取消测试,送我们的程序员去参加自信心培训课程。毕竟说起来,如果我们选择做测试,那么我们就要测试每个程序的变更,但其实我们只需要送程序员去一次建立自信的培训课就行了。很显然这么做的成本收益是相当可观的。
编程语言的选择
计算机语言正在逐步进化,变得更加傻瓜化。使用最新的语言是不人性的。尽可能坚持使用你会用的最老的语言,先考虑用穿孔纸带,不行就用汇编,再不行用 FORTRAN 或者 COBOL,再不行就用 C 还有 BASIC,实在不行再用 C++。
FØRTRAN
用 FORTRAN 写所有的代码。如果老板问你为啥,你可以回答说有很多它非常有用的库,你用了可以节约时间。不过,用 FORTRAN 写出可维护代码的概率是 0,所以,要达到不可维护代码编程指南里的要求就容易多了。
用 ASM
把所有的通用工具函数都转成汇编程序。
用 QBASIC
所有重要的库函数都要用 QBASIC 写,然后再写个汇编的封包程序来处理 large 到 medium 的内存模型映射。
内联汇编
在你的代码里混杂一些内联的汇编程序,这样很好玩。这年头几乎没人懂汇编程序了。只要放几行汇编代码就能让维护代码的程序员望而却步。
宏汇编调用 C
如果你有个汇编模块被 C 调用,那就尽可能经常从汇编模块再去调用 C,即使只是出于微不足道的用途,另外要充分利用 goto, bcc 和其他炫目的汇编秘籍。
与他人共事之道
老板才是真行家
如果你的老板认为他 20 年的 FORTRAN 编程经验对于现代软件开发具有很高的指导价值,你务必严格采纳他的所有建议。投桃报李,你的老板也会信任你。这会对你的职业发展有利。你还会从他那里学到很多搞乱程序代码的新方法。
颠覆技术支持
确保代码中到处是 bug 的有效方法是永远不要让维护代码的程序员知道它们。这需要颠覆技术支持工作。永远不接电话。使用自动语音答复 “感谢拨打技术支持热线。需要人工服务请按 1,或在嘀声后留言。”,请求帮助的电子邮件必须忽略,不要给它分配服务追踪号。对任何问题的标准答复是 “我估计你的账户被锁定了,有权限帮你恢复的人现在不在。”
沉默是金
永远不要对下一个危机保持警觉。如果你预见到某个问题可能会在一个固定时间爆发,摧毁西半球的全部生命,不要公开讨论它。不要告诉朋友、同事或其他你认识的有本事的人。在任何情况下都不要发表任何可能暗示到这种新的威胁的内容。只发送一篇正常优先级的、语焉不详的备忘录给管理层,保护自己免遭秋后算账。如果可能的话,把这篇稀里糊涂的信息作为另外一个更紧急的业务问题的附件。这样就可以心安理得地休息了,你知道将来你被强制提前退休之后一段时间,他们又会求着你回来,并给你对数级增长的时薪!
每月一书俱乐部
加入一个计算机每月一书俱乐部。选择那些看上去忙着写书不可能有时间真的去写代码的作者。去书店里找一些有很多图表但是没有代码例子的书。浏览一下这些书,从中学会一些迂腐拗口的术语,用它们就能唬住那些自以为是的维护代码的程序员。你的代码肯定会给他留下深刻印象。如果人们连你写的术语都理解不了,他们一定会认为你非常聪明,你的算法非常深奥。不要在你的算法说明里作任何朴素的类比。
自立门户
你一直想写系统级的代码。现在机会来了。忽略标准库, 编写你自己的标准,这将会是你简历中的一个亮点。
推出你自己的 BNF 范式
总是用你自创的、独一无二的、无文档的 BNF 范式记录你的命令语法。永远不要提供一套带注解的例子(合法命令和非法命令之类)来解释你的语法体系。那样会显得完全缺乏学术严谨性。确保没有明显的方式来区分终结符和中间符号。永远不要用字体、颜色、大小写和其他任何视觉提示帮助读者分辨它们。在你的 BNF 范式用和命令语言本身完全一样的标点符号,这样读者就永远无法分清一段 (...), [...], {...} 或 "..." 到底是你在命令行里真正输入的,还是想提示在你的 BNF 范式里哪个语法元素是必需的、可重复的、或可选的。不管怎么样,如果他们太笨,搞不清你的 BNF 范式的变化,就没资格使用你的程序。
推出你自己的内存分配
地球人儿都知道,调试动态存储是复杂和费时的。与其逐个类去确认它没有内存溢出,还不如自创一套存储分配机制呢。其实它无非是从一大片内存中 malloc 一块空间而已。用不着释放内存,让用户定期重启动系统,这样不就清除了堆么。重启之后系统需要追踪的就那么一点东西,比起解决所有的内存泄露简单得不知道到哪里去了!而且,只要用户记得定期重启系统,他们也永远不会遇到堆空间不足的问题。一旦系统被部署,你很难想象他们还能改变这个策略。
其他杂七杂八的招
如果你给某人一段程序,你会让他困惑一天;如果你教他们如何编程,你会让他困惑一辈子。 -- Anonymous
不要重编译
让我们从一条可能是有史以来最友好的技巧开始:把代码编译成可执行文件。如果它能用,就在源代码里做一两个微小的改动 -- 每个模块都照此办理。但是不要费劲巴拉地再编译一次了。 你可以留着等以后有空而且需要调试的时候再说。多年以后,等可怜的维护代码的程序员更改了代码之后发现出错了,他会有一种错觉,觉得这些肯定是他自己最近修改的。这样你就能让他毫无头绪地忙碌很长时间。
挫败调试工具
对于试图用行调试工具追踪来看懂你的代码的人,简单的一招就能让他狼狈不堪,那就是把每一行代码都写得很长。特别要把 then 语句 和 if 语句放在同一行里。他们无法设置断点。他们也无法分清在看的分支是哪个 if 里的。
公制和美制
在工程方面有两种编码方式。一种是把所有输入都转换为公制(米制)计量单位,然后在输出的时候自己换算回各种民用计量单位。另一种是从头到尾都保持各种计量单位混合在一起。总是选择第二种方式,这就是美国之道!
持续改进
要持续不懈地改进。要常常对你的代码做出 “改进”,并强迫用户经常升级 -- 毕竟没人愿意用一个过时的版本嘛。即便他们觉得他们对现有的程序满意了,想想看,如果他们看到你又 “完善 “了它,他们会多么开心啊!不要告诉任何人版本之间的差别,除非你被逼无奈 -- 毕竟,为什么要告诉他们本来永远也不会注意到的一些 bug 呢?
“关于”
“关于” 一栏应该只包含程序名、程序员姓名和一份用法律用语写的版权声明。理想情况下,它还应该链接到几 MB 的代码,产生有趣的动画效果。但是,里边永远不要包含程序用途的描述、它的版本号、或最新代码修改日期、或获取更新的网站地址、或作者的 email 地址等。这样,所有的用户很快就会运行在不同的版本上,在安装 N+1 版之前就试图安装 N+2 版。
变更
在两个版本之间,你能做的变更自然是多多益善。你不会希望用户年复一年地面对同一套老的接口或用户界面,这样会很无聊。最后,如果你能在用户不注意的情况下做出这些变更,那就更好了 -- 这会让他们保持警惕,戒骄戒躁。
无需技能
写无法维护代码不需要多高的技能。喊破嗓子不如甩开膀子,不管三七二十一开始写代码就行了。记住,管理层还在按代码行数考核生产率,即使以后这些代码里的大部分都得删掉。
只带一把锤子
一招鲜吃遍天,轻装前进。如果你手头只有一把锤子,那么所有的问题都是钉子。
规范体系
有可能的话,忽略当前你的项目所用语言和环境中被普罗大众所接受的编程规范。比如,编写基于 MFC 的应用时,就坚持使用 STL 编码风格。
翻转通常的 True False 惯例
把常用的 true 和 false 的定义反过来用。这一招听起来平淡无奇,但是往往收获奇效。你可以先藏好下面的定义:
#define TRUE 0
#define FALSE 1
把这个定义深深地藏在代码中某个没人会再去看的文件里不易被发现的地方,然后让程序做下面这样的比较
if ( var == TRUE )
if ( var != FALSE )
某些人肯定会迫不及待地跳出来 “修正” 这种明显的冗余,并且在其他地方照着常规去使用变量 var:
if ( var )
还有一招是为 TRUE 和 FALSE 赋予相同的值,虽然大部分人可能会看穿这种骗局。给它们分别赋值 1 和 2 或者 -1 和 0 是让他们瞎忙乎的方式里更精巧的,而且这样做看起来也不失对他们的尊重。你在 Java 里也可以用这一招,定义一个叫 TRUE 的静态常量。在这种情况下,其他程序员更有可能怀疑你干的不是好事,因为 Java 里已经有了内建的标识符 true。
第三方库
在你的项目里引入功能强大的第三方库,然后不要用它们。潜规则就是这样,虽然你对这些好的工具仍然一无所知,却还是可以在你简历的 “其他工具” 一节中写上这些没用过的库。
不要用库
假装不知道有些库已经直接在你的开发工具中引入了。如果你用 VC++ 编程,忽略 MFC 或 STL 的存在,手工编写所有字符串和数组的实现;这样有助于保持你的指针技术,并自动阻止任何扩展代码功能的企图。
创建一套 Build 顺序
把这套顺序规则做得非常晦涩,让维护者根本无法编译任何他的修改代码。秘密保留 SmartJ ,它会让 make 脚本形同废物。类似地,偷偷地定义一个 javac 类,让它和编译程序同名。说到大招,那就是编写和维护一个定制的小程序,在程序里找到需要编译的文件,然后通过直接调用 sun.tools.javac.Main 编译类来进行编译。
Make 的更多玩法
用一个 makefile-generated-batch-file 批处理文件从多个目录复制源文件,文件之间的覆盖规则在文档中是没有的。这样,无需任何炫酷的源代码控制系统,就能实现代码分支,并阻止你的后继者弄清哪个版本的 DoUsefulWork () 才是他需要修改的那个。
搜集编码规范
尽可能搜集所有关于编写可维护代码的建议,例如 SquareBox 的建议 ,然后明目张胆地违反它们。
规避公司的编码规则
某些公司有严格的规定,不允许使用数字标识符,你必须使用预先命名的常量。要挫败这种规定背后的意图太容易了。比如,一位聪明的 C++ 程序员是这么写的:
#define K_ONE 1
#define K_TWO 2
#define K_THOUSAND 999
编译器警告
一定要保留一些编译器警告。在 make 里使用 “-” 前缀强制执行,忽视任何编译器报告的错误。这样,即使维护代码的程序员不小心在你的源代码里造成了一个语法错误,make 工具还是会重新把整个包 build 一遍,甚至可能会成功!而任何程序员要是手工编译你的代码,看到屏幕上冒出一堆其实无关紧要的警告,他们肯定会觉得是自己搞坏了代码。同样,他们一定会感谢你让他们有找错的机会。学有余力的同学可以做点手脚让编译器在打开编译错误诊断工具时就没法编译你的程序。当然了,编译器也许能做一些脚本边界检查,但是真正的程序员是不用这些特性的,所以你也不该用。既然你用自己的宝贵时间就能找到这些精巧的 bug,何必还多此一举让编译器来检查错误呢?
把 bug 修复和升级混在一起
永远不要推出什么 “bug 修复 " 版本。一定要把 bug 修复和数据库结构变更、复杂的用户界面修改,还有管理界面重写等混在一起。那样的话,升级就变成一件非常困难的事情,人们会慢慢习惯 bug 的存在并开始称他们为特性。那些真心希望改变这些” 特性 “的人们就会有动力升级到新版本。这样从长期来说可以节省你的维护工作量,并从你的客户那里获得更多收入。
在你的产品发布每个新版本的时候都改变文件结构
没错,你的客户会要求向上兼容,那就去做吧。不过一定要确保向下是不兼容的。这样可以阻止客户从新版本回退,再配合一套合理的 bug 修复规则(见上一条),就可以确保每次新版本发布后,客户都会留在新版本。学有余力的话,还可以想办法让旧版本压根无法识别新版本产生的文件。那样的话,老版本系统不但无法读取新文件,甚至会否认这些文件是自己的应用系统产生的!温馨提示:PC 上的 Word 文字处理软件就典型地精于此道。
抵消 Bug
不用费劲去代码里找 bug 的根源。只要在更高级的例程里加入一些抵销它的代码就行了。这是一种很棒的智力测验,类似于玩 3D 棋,而且能让将来的代码维护者忙乎很长时间都想不明白问题到底出在哪里:是产生数据的低层例程,还是莫名其妙改了一堆东西的高层代码。这一招对天生需要多回合执行的编译器也很好用。你可以在较早的回合完全避免修复问题,让较晚的回合变得更加复杂。如果运气好,你永远都不用和编译器前端打交道。学有余力的话,在后端做点手脚,一旦前端产生的是正确的数据,就让后端报错。
使用旋转锁
不要用真正的同步原语,多种多样的旋转锁更好 -- 反复休眠然后测试一个 (non-volatile 的) 全局变量,直到它符合你的条件为止。相比系统对象,旋转锁使用简便,” 通用 “性强,” 灵活 “多变,实为居家旅行必备。
随意安插 sync 代码
把某些系统同步原语安插到一些用不着它们的地方。本人曾经在一段不可能会有第二个线程的代码中看到一个临界区(critical section)代码。本人当时就质问写这段代码的程序员,他居然理直气壮地说这么写是为了表明这段代码是很” 关键 “(也是 critical)的!
优雅降级
如果你的系统包含了一套 NT 设备驱动,就让应用程序负责给驱动分配 I/O 缓冲区,然后在任何交易过程中对内存中的驱动加锁,并在交易完成后释放或解锁。这样一旦应用非正常终止,I/O 缓存又没有被解锁,NT 服务器就会当机。但是在客户现场不太可能会有人知道怎么弄好设备驱动,所以他们就没有选择(只能请你去免费旅游了)。
定制脚本语言
在你的 C/S 应用里嵌入一个在运行时按字节编译的脚本命令语言。
依赖于编译器的代码
如果你发现在你的编译器或解释器里有个 bug,一定要确保这个 bug 的存在对于你的代码正常工作是至关重要的。毕竟你又不会使用其他的编译器,其他任何人也不允许!
一个货真价实的例子
下面是一位大师编写的真实例子。让我们来瞻仰一下他在这样短短几行 C 函数里展示的高超技巧。
void* Realocate(void*buf, int os, int ns){
void*temp;
temp = malloc(os);
memcpy((void*)temp, (void*)buf, os);
free(buf);
buf = malloc(ns);
memset(buf, 0, ns);
memcpy((void*)buf, (void*)temp, ns);
return buf;
}
重新发明了标准库里已有的简单函数。
Realocate 这个单词拼写错误。所以说,永远不要低估创造性拼写的威力。
无缘无故地给输入缓冲区产生一个临时的副本。
无缘无故地造型。 memcpy () 里有 (void*),这样即使我们的指针已经是 (void*) 了也要再造型一次。另外这样可以传递任何东西作为参数,加 10 分。
永远不必费力去释放临时内存空间。这样会导致缓慢的内存泄露,一开始看不出来,要程序运行一段时间才行。
把用不着的东西也从缓冲区里拷贝出来,以防万一。这样只会在 Unix 上产生 core dump,Windows 就不会。
很显然,os 和 ns 的含义分别是”old size"和"new size"。
给 buf 分配内存之后,memset 初始化它为 0。不要使用 calloc (),因为某些人会重写 ANSI 规范,这样将来保不齐 calloc () 往 buf 里填的就不是 0 了。(虽然我们复制过去的数据量和 buf 的大小是一样的,不需要初始化,不过这也无所谓啦)
如何修复 "unused variable" 错误
如果你的编译器冒出了 "unused local variable" 警告,不要去掉那个变量。相反,要找个聪明的办法把它用起来。我最喜欢的方法是:
i = i;
大小很关键
差点忘了说了,函数是越大越好。跳转和 GOTO 语句越多越好。那样的话,想做任何修改都需要分析很多场景。这会让维护代码的程序员陷入千头万绪之中。如果函数真的体型庞大的话,对于维护代码的程序员就是哥斯拉怪兽了,它会在他搞清楚情况之前就残酷无情地将他们踩翻在地。
一张图片顶 1000 句话,一个函数就是 1000 行
把每个方法体写的尽可能的长 -- 最好是你写的任何方法或函数都没有少于 1000 行代码的,而且里边深度嵌套,这是必须的。
少个文件
一定要保证一个或多个关键文件是找不到的。利用 includes 里边再 includes 就能做到这一点。例如,在你的 main 模块里,你写上:
#include <stdcode.h>
Stdcode.h 是有的。但是在 stdcode.h 里,还有个引用:
#include "a:\\refcode.h"
然后,refcode.h 就没地方能找到了。
到处可写,无处可读
至少要把一个变量弄成这样:到处被设置,但是几乎没有哪里用到它。不幸的是,现代编译器通常会阻止你做相反的事:到处读,没处写。不过你在 C 或 C++ 里还是可以这样做的。
程序员是一个比较特殊的群体,他们因为长期和电脑打交道所养成的性格和脾气也是比较相近的。当然,既然是人,当然是会有性格的,也是会有脾气的。下面让我们来看看十件能把程序惹毛了的事情。一方面我们可以看看程序员的共性,另一方面我们也可以看看程序员的缺点。无论怎么样,我都希望他们对你的日常工作都是一种帮助。
第十位 程序注释
程序注释本来是一些比较好的习惯,当程序员老手带新手的时候,总是会告诉新手,一定要写程序注释。于是,新手们当然会听从老手的吩咐。只不过,他们可能对程序注释有些误解,于是,我们经常在程序中看到一些如下的注释:
r = n/2; //r是n的一半
//循环,仅当r- n/r不大于t
while ((r-n/r) <=t){
… …
r = 0.5 * (r-n/r); // 设置r变量
}
每当看到这样的注释——只注释是什么,而不注释为什么,相信你一定会被惹火,这是谁写的程序注释啊?不找来骂一顿看来是不会解气了。程序注释应该是告诉别 人你的意图和想法,而不是告诉别人程序的语法,这是为了程序的易读性和可维护性,这样的为了注释而注释的注释,分明不是在注释,而是在挑衅,惹毛别人当然 毋庸置疑。
第九位 打断
正当程序沉浸于编程算法的思考,或是灵感突现正在书写程序的时候,但却遭到别人的打断,那是一件非常痛苦的事情,如果被持续打断,那可能会让人一下子就烦 躁起来。打断别人的人在这种情况下是非常不礼貌的。被打断的人就像函数调用一下,当其返回时,需要重新恢复断点时的现场,当然,人不是电脑,恢复现场通常 是一个很痛苦的过程,极端的情况下可能需要从头开始寻找思绪,然后一点一点地回到断点。
因此,我看到一些程序员在需要安静不被打扰的时候,要么会选择去一个没人找得到的地方,要么会在自己的桌子上方高挂一个条幅以示众人——“本人正执行内核 程序,无法中断,请勿骚扰,谢谢!”,可能正在沉浸于工作的程序被打断是多么大的开销。自然,被打断所惹毛了的人也不在少数了。
第八位 需求变化
这个事情估计不用多说了。只要是是程序员,面对需求变化的时候可能总是很无奈的。一次两次可能还要吧接受,但也顶不住经常变啊。据说敏捷开发中有一套方法 论可以让程序员们享受需求的变化,不知道是真是假。不过,今天让你做一个书桌,明天让你把书桌改成餐桌,后天让你把餐桌改成双人床,大后天让你把床改成小 木屋,然后把小木屋再改成高楼大厦。哎,是人都会被惹毛了的。那些人只用30分钟的会议就可以作出任何决定,但后面那几十个程序员需要搭上几百个小时的辛 苦工作。如果是我,可能我也需要神兽草泥马帮助解解气了。
不过,这也正说明了,程序员并不懂得怎么和用户沟通,而用户也不懂得和程序员沟通,如果一个项目没有一个中间人(如:PM)在其中协调的话,那么整个项目 可能就是“鸡同鸭讲”,用户和程序员都会被对方所惹毛了。如果要例举几个用户被惹毛的事情,估计程序员的那种一根筋的只从技术实现上思考问题的方法应该也 能排进前5名。
第七位 经理不懂技术
外行领导内行的事例还少吗?领导一句话,无论对不对,都是对的,我们必需照做,那怕是多么愚蠢多么错误的决定,我们也得照做。程序员其实并不怕经理不懂技 术,最怕的就是不懂技术的经理装着很懂技术。最可气的是,当你据理力争的挑站领导权威的时候,领导还把你视为异类。哎,想起这样的领导别说是骂人了,打人 的冲动都有了。其实,经理只不过是一个团队的支持者,他应该帮助团队,为团队排忧解难。而不是对团队发号施令。其实管理真的很简单,如果懂的话,就帮着做,如果不懂的话,就相信下属,放手让下属做。最怕的就是又不懂技术,还不信任下属的经理了。哎,这真是程序员的痛啊。
第六位 用户文档
用户文档本来不应该那么的令人害怕。这些文档记录了一切和我们所开发的软件有关的一些话题。因为我们并不知道我们所面对的用户的电脑操作基础是什么样的, 所以,在写下这样的文档的时候,我们必需假设这个用户什么也不懂。于是,需要用最清楚,最漂亮的语言写下一个最丰富的文档。那怕一个拷贝粘贴的操作,可能 我们都要分成五、六步来完成,那怕是一个配置IP地址的操作,我们也要从开始菜单开始一步一步的描述。对于程序员来说,他们在开发过程中几乎天天都在使用 自己开发的软件,到最后,可能都有得有点吐了,但还得从最简单的部份写这些文档,当然容易令他们烦燥,让程序员来完成这样的文档可能效果会非常不好。所 以对于这样的用户文档,应该由专门的文档人员来完成和维护。
第五位 没有文档
正如上一条所说的,程序员本来就不喜欢写文档,而因为技术人员的表达能力和写作能力一般都不是太好,所以,文档写的也很烂。看看开源社区的文档可能就知道 了。但是,我们可爱的程序员另一方面最生气的却是因为没有文档。当然,让面说是的用户的文档,这里我们说的是开发方面的文档,比如设计文档,功能规格,维 护文档等等。不过,基本上都是一样的。反正,一方面,我们的程序员不喜欢写文档,另一方面,我们的程序又会被抱怨没有文档,文档太少,或者文档看不懂。呵 呵。原来在抱怨方面也有递归啊。据说,敏捷开发可以降低程序开发中的文档,据说他们可以把代码写得跟文档和示图似的,不知道是真是假。不过,我听过太多太 多的程序员抱怨没文档太少,文档太差了,这个方面要怪还是怪程序员自己。
第四位 部署环境
虽然,程序员们开发的是软件,但是我们并不知道我们的程序会被部署或安装在什么样的环境下,比如,网络上的不同,RAID上的不同,BIOS上的不同,操 作系统的不同(WinXP和Win2003),有没有杀毒软件,和其它程序是否兼容,系统中有流氓软件或病毒等等。当然,只要你的软件出现错误,无论是你 的程序的问题,还是环境的问题,反正都是你的问题,你都得全部解决。所以,程序员们并不是简单地在编程,很多时候,还要当好一个不错的系统管理员。每当最 后确认问题的原因是环境问题的时候,可能程序员都是会心生怨气。
第三位 问题报告
“我的软件不工作了”,“程序出错了”,每当我们听到这样的问题报告的时候,程序员总是感到很痛苦,因为这样的问题报告等于什么也没有说,但还要程序员去 处理这种错误。没有明确的问题描述,没有说明如何重现问题,在感觉上,当然会显得有点被人质问的感觉,甚至,在某些时候还掺杂着看不起,训斥的语气,当 然,程序员基本上都是很有个性的,都是软硬不吃的主儿,所以,每当有这样的语气报告问题的时候,他们一般也会把话给顶回去,当然,后面自己然发生一些不愉 快的事情。所以,咱们还是需要一个客服部门来帮助我们的程序员和用户做好沟通。
第二位 程序员自己
惹毛程序员的可能还是程序员自己,程序员是“相轻”的,他们基本上都是持才傲物的,总是觉得自己才是最牛的,在程序员间,他们几乎每天都要吵架,而且一吵就吵得脸红脖子粗。在他们之间,他们总是被自己惹毛。
技术上的不同见解。比如Linux和Win,VC++和VB,Vi和Emacus,Java和C++,PHP和Ruby等等,等等。什么都要吵。
老手对新手的轻视。总是有一些程序员看不起另一些程序员,说话间都带着一种傲慢和训斥。当新手去问问题的时候,老手们总是爱搭不理。
在技术上不给对方留面子。不知道为什么,程序员总是不给对方留面子,每当听到有人错误理解某个技术的时候,他们总是喜欢当众大声指证,用别人的“错误”来表明自己的“博学”,并证明他人的“无知”。
喜好鄙视。他们喜好鄙视,其实,这个世界上没有一件事是完美的,有好就有不好,要挑毛病太容易了。程序员们特别喜欢鄙视别人,无论是什么的东西,他们总是喜欢看人短而不看人长。经常挂在他们嘴上的口头禅是“太差”、“不行”等等。
程序员,长期和电脑打交道,编写出的代码电脑总是认真的运行,长期养成了程序员们目空一切的性格,却不知,这个世界上很多东西并不是能像电脑一样,只要我们输入正确的指令它就正确地运行这么简单。程序员,什么时候才能变成成熟起来……
第一位 程序员的代码
无论你当时觉得自己的设计和写的代码如何的漂亮和经典,过上一段时间后,再回头看看,你必然会觉得自己的愚蠢。当然,当你需要去维护他人的代码的时候,你一定要在一边维护中一边臭骂别人的代码。是否你还记得当初怎么怎么牛气地和别人讨论自己的设计和自己的代码如何如何完美的?可是,用不了两年,一刚从学校毕业的学生在维护你的代码的过程当中就可以对你的代码指指点点,让你的颜面完全扫地。当然,也有的人始终觉得自己的设计和代码就是最好的,不过这是用一种比较静止的眼光来看问题。编程这个世界变化总是很快的的,很多事情,只有当我们做过,我们才熟悉他,熟悉了后才知道什么是更好的方法,这是循序渐进的。所以,当你对事情越来越熟悉的时候,再回头看自己以前做的设计和代码的时候,必然会觉得自己的肤浅和愚蠢,当然看别人的设计和代码时,可能也会开始骂 人了。
12 个学习新的编程语言的方法
在这篇文章中,作者提出了 12 项关于学习技术的建议。记住每个人学习的方式都不一样。其中一些可能对你十分有用,而其他的则可能无法满足你的需求。如果你开始担心一个策略,请尝试另一个策略并看看它哪里适合你。
1. 将其与类似的语言进行比较。当你首次观看有关该语言的第一个教程或阅读代码时,请尝试猜测该语言的每个部分将会做什么,并检查你的判断是否正确。 如果记笔记可以帮助你整合信息,请拿起一张纸并记下三个列表:
看起来很熟悉的东西,并且做了预期中的事
看起来很熟悉的东西,但做了意料之外的事
看起来完全是新的东西
例如,如果我用来自 Python 和 C 背景的 Rust 代码进行此练习,那么在第一个列表中,我会放上用于表示范围的花括号!(看起来像是布尔类型的非,但实际上是 Rust 中的宏定义)则放在第二个列表,类型签名语法(type signature syntax)放在第三个列表。如果你保留着初始列表的副本,一旦你更熟练,可使用它通过语言反思你的进展,并提醒自己在尝试向其他人讲授该语言时,有哪些看起来不熟悉的概念。
2. 阅读语言的官方文档。如果希望在使用之前吸收大量信息,从阅读语言的参考资料中可能会受益。不用担心它们会对你催眠,参考文献通常是用于查找使用,而不是用来记忆。
3. 使用互联网搜索。搜索网络是一个很好的方式,可提供有关特定错误和一般最佳做法的信息。当收到错误信息时,应搜索信息中看起来是错误的独一无二的部分,但不是代码唯一的部分。例如,如果错误提示 "Error on line 53: Invalid argument exception(错误在第 53 行:无效的参数异常)",以语言名称和字符串 “Invalid argument exception” 这样的组合搜索,以找到最佳的结果。记住要将错误信息中的所有引用内容都包含在内。
还可以在网络中搜索有关解决语言中特定问题的最佳做法的博文。评估搜索结果中显示的博客帖子的质量和决定认真采用他们的建议时,请查看作者的公共代码组合以及发布日期。
4. 与社区接触。虽然博客和新闻文章具有大量有用的信息,但是你尝试编写的特定代码片段总会有些微妙之处。不要害怕在邮件列表中发帖,或加入 IRC 和 Slack 频道以寻求帮助。
要提出有帮助的回复的问题,请确保在正确的地方提问。许多语言都有 “初学者” 邮件列表或聊天频道,专门针对可能会频繁询问的问题而建立。当提出问题时,请务必先总结准备做什么、已做过的东西以及发生的情况。尽量为专家提供足够的上下文来了解问题,但不需要无关紧要的细节。提出问题后,请务必坚持一段时间来听取建议或会回答你的疑问可能产生的后续问题。
5. 编写玩具程序。一次练习一个新的概念,很少有任务可打败只使用某个概念的玩具程序。你可以将重点放在尽可能让你的代码清洁和惯用性上。如果你将解决 Project Euler 或 Rosetta Code puzzle 作为玩具程序,则可以将你的解决方案与其他使用相同语言编写的解决方案进行比较。
6. 使用该语言编写 “生产就绪(Production-Ready)” 的代码。玩具程序是一个很好的第一步,但在更逼真的的环境中使用一门语言可帮助探索其现实使用中的优势和挑战。考虑将一个熟悉的、相对较小的、经过良好测试的程序移植到新的语言,以探索其在现实使用的应用。
7. 阅读一本关于这门语言的书籍。如果有好几本有用的书,比较它们的评论,并考虑哪位作者的背景和自己的最相似。现在有很多电子书可以免费在线阅读。
在购买有关该语言的书籍之前,请先查看书籍出版的日期以及其示例所涵盖的语言版本。如果使用的是较旧的书籍,请务必使用其所使用的语言版本的示例。还要在网上调查一下,以了解自出版以来语言发生了怎样的变化。
8. 观看讲座和课程。如果你学习的语言在在线课堂中有讲授,那么视频应该是公开的。除了学术讲座之外,还可以考虑寻找录制讲座、会议谈话和有关该语言的博客。当在看电视时,谈谈你的新语言是一个将学习融入日常生活很好的方式。
9. 阅读示例代码。大多数关于编程语言的书籍都会包含代码片段。你也可以在博客和 Rosetta Code 上找到示例代码。运行示例代码、修改它们,并尝试预测修改后会发生那些情况。
10. 阅读生产代码。查找有关该语言所有类型和大小的项目的一种方法是在 GitHub 上搜索它。按最受欢迎或最具影响力进行排序,你的热门搜索将包括最受欢迎的开源工具。如果想要了解开源项目的设计,可通过邮件列表或 IRC 来与社区进行互动。你甚至可能会发现一些 bug。
11. 寻找好的工具。当使用新的语言时,可向其更有经验的用户请教,询问他们的开发环境。你可能会发现,一个特定的文本编辑器或 IDE 对于新语言的支持比你习惯通常使用的要好。调查在新语言生态系统中管理依赖关系、格式化、模糊化和单元测试代码的选项。
12. 保持你的热情。入门新的语言很容易,但变得真正精通它通常是一个需要多年的旅程。庆祝一路上你的成功,并与追随你脚步的学习者分享你所学到的知识,保持着学习编程的兴趣。
关于编程鲜为人知的真相
程序员的经历让人知道了一些关于软件编程的事情,下面的这些事情可能会让朋友们对软件开发感到惊讶:
1. 一个程序员用在写程序上的时间大概占他的工作时间的10-20%,大部分的程序员每天大约能写出10-12行的能进入最终的产品的代码 — —不管他的技术水平有多高。好的程序员花去90%的时间在思考、研究和实验,来找出最优方案。差的程序员花去90%的时间在调试问题程序、盲目的修改程序,期望某种写法能可行。“一个卓越的车床工可以要求比一个一般的车床工多拿数倍高的工资,但一个卓越的软件写手的价值会10000倍于一个普通的写手。”——比尔 盖茨
2. 一个优秀的程序员的效率会是一个普通的程序员的十倍之上。一个伟大的程序员的效率会是一个普通程序员的20-100倍。这不是夸张 — — 1960年以来的无数研究都一致的证明了这一点。一个差的程序员不仅仅是没效率 — — 他不仅不能完成任务,写出的大量代码也让别人头痛的没法维护。
3. 伟大的程序员只花很少的时间去写代码——至少指那些最终形成产品的代码。那些要花掉大量时间写代码的程序员都是太懒惰,太自大,太傲慢,不屑用现有的方案去解决老问题。伟大的程序员的精明之处在于懂得欣赏和重复利用通用模式。好的程序员并不害怕经常的重构(重写)他们的代码以求达到最好效果。差的程序员写的代码缺乏整体概念,冗余,没有层次,没有模式,导致很难重构。把这些代码扔掉重做也比修改起来容易。
4. 软件遵循熵的定律,跟其它所有东西一样。持续的变更会导致软件腐烂,腐蚀掉对原始设计的完整性概念。软件的腐烂是不可避免的,但程序员在开发软件时没有考虑完整性,将会使软件腐烂的如此之快,以至于软件在还没有完成之前就已经毫无价值了。软件完整性上的熵变可能是软件项目失败最常见的原因(第二大常见失败原因是做出的不是客户想要的东西)。软件腐烂使开发进度呈指数级速度放缓,大量的软件在失败之前都是面对着突增的时间要求和资金预算。
5. 2004年的一项研究表明大多数的软件项目(51%)会在关键功能上失败,其中15%是完全的失败。这比1994年前有很大的改进,当时是31%。
6. 尽管大多数软件都是团体开发的,但这并不是一项民/主的活动。通常,一个人负责设计,其他人负责实现细节。
7. 编程是个很难的工作。是一种剧烈的脑力劳动。好的程序员7×24小时的思考他们的工作。他们最重要的程序都是在淋浴时、睡梦中写成的。因为这最重要的工作都是在远离键盘的情况下完成的,所以软件工程不可能通过增加在办公室的工作时间或增加人手来加快进度。
典型PC系统各种操作指令的大概时间
| execute typical instruction 执行基本指令 | 1/1,000,000,000 sec = 1 nanosec |
| fetch from L1 cache memory 从一级缓存中读取数据 | 0.5 nanosec |
| branch misprediction 分支误预测 | 5 nanosec |
| fetch from L2 cache memory 从二级缓存获取数据 | 7 nanosec |
| Mutex lock/unlock 互斥加锁/解锁 | 25 nanosec |
| fetch from main memory 从主内存获取数据 | 100 nanosec |
| send 2K bytes over 1Gbps network 通过1G bps 的网络发送2K字节 | 20,000 nanosec |
| read 1MB sequentially from memory 从内存中顺序读取1MB数据 | 250,000 nanosec |
| fetch from new disk location (seek) 从新的磁盘位置获取数据(随机读取) | 8,000,000 nanosec |
| read 1MB sequentially from disk 从磁盘中顺序读取1MB数据 | 20,000,000 nanosec |
| send packet US to Europe and back 从美国发送一个报文包到欧洲再返回 | 150 milliseconds = 150,000,000 nanosec |
不适合做开发人员的十种迹象
程序员能够赚大钱,软件开发人员一周七天都可以随意穿戴;任何人都可以通过自学成为一名程序员,这些仅是人们想成为开发人员的一小 部分原因。不幸的是,人才市场中到处都是拥有原始智力或学问的应聘者,但是他们却不具有成为一名优秀程序员所需要的正确的态度或品格。在决定自己是否应当成为一名软件开发人员时,你应当考虑以下几件事情。
1. 宁愿培训,也不自学
即使公司对其他类型员工有合适的培训计划,大多数开发部门也很少给程序员提供培训机会,顶多为你报销买书的费用。他们都希望程序员踏进公司的第 一天就掌握了所有(至少大部分)必需的技术。更糟的是,他们主观地认为程序员都非常聪明,很擅长解决问题。这让上层管理人员相信,优秀的程序员不需要培训。最重要的,对开发人员的培训费用是相当昂贵的。结果呢?当你职位调动时,你要弄清楚接下来要做什么,必要的话就要自学一下了。
2. 喜欢正常的工作时间
软件开发项目不能按时交工是出了名的。从某种角度而言,即便是如期完工的项目也通常落后于计划表。如果你不能忍受(或不能处理)自己的业余时间,因上级的命令而失去规律或充满变数,那么你不适合做软件开发。到了关键时刻,上级只会在乎能否将产品如期交到资产雄厚的客户手上,而不是你孩子的足球比赛或你想看的一个新的电视节目。
3. 喜欢正常加薪胜过跳槽
软件开发行业,技术无时无刻不在贬值。除非你所在公司是和缓慢变化的技术打交道,否则,你的技术很可能一天不如一天值钱。目前技术发展水平飞速变化,今天还很热门的技术明天可能就无人问津了。因此,日复一日的重复着同样的工作,还期盼得到超过不断增长的生活费用的加薪是很困难的。要想保值,就必须保证自己的技术跟得上发展的步伐。此外,如果还想加薪,就必须大大扩充自己的技术,要么获得晋升,或者直接跳槽。
4. 无法和他人和睦共处
性格内向或喜欢一个人工作是一回事。无法与他人和睦共处是另一回事,而且作为一名开发人员,这会拖你的后腿。不仅如此,你的经理很可能是一名非技术人员(或很久没有亲自从事技术工作的技术人员),所以你必须善于向非技术人员表达自己的想法。
5. 容易垂头丧气
软件开发经常会让人产生挫败感。文件材料过于陈旧或有错误、之前的程序员写的代码晦涩难懂、老板规定了一些必须遵守但毫无意义的规定……诸如此类的事情不胜枚举。一天下来,没有人愿意和一个整天在无休止地咒骂或对着显示器尖叫的人一起工作。如果因为花了8个小时完成看似10分钟就能完成的任务而抓狂,那么开发工作不适合你。
6. 思想保守,不考虑他人建议
编程过程中遇到的问题往往都有很多解决方案。如果你不能正确对待他人的批评,或者不能认真聆听他人的意见,你很可能会漏掉一些重要的东西。举个例子,几周前,一名初级程序员给我提了一个建议。经过思考,我决定尝试一下,结果证明他是正确的,而我之前的想法是错误的,而且,他的建议让一段代码的运 行时间从之前的若干天一下缩短到几个小时。如果因为经验水平的不同而忽略他的意见,那是多么愚蠢啊。
7. 不注重细节
编程过程处处都是细节。如果一部情节比《野蛮人柯南》复杂一点的电影就弄得你晕头转向,或者填写一个折扣单就让你感觉很费劲的话,那么你在软件开发这个行业也不会有长足发展。有时,像少一个句号这样的小错误,就会让原本很完美的程序产生随机错误。如果你连哪里少了句号都搞不清楚,恐怕你在这一 行业也不会有很大发展。
8. 没有工作自豪感
当然,循规蹈矩式的编写一个说得过得去的程序是有可能的。问题是,规则不是一成不变的。软件开发不像是在工厂里整天拧同样的螺丝,拧的力度大了小了都无所谓,它需要独立思考,进而需要开发人员对工作有自豪感。而且软件开发过程中,一些错误的做法很可能一开始不会对整个工作有不良影响。那些你所忽视的、看似不会引起麻烦的“小错误”,最终会酿成大祸。没有工作自豪感、不认真对待每个项目的程序员工作质量不高,从而编程事业也不会长久。
9. 不三思而后行
比起编写程序,软件开发人员(至少是优秀的开发人员)会在项目计划上花费更多的时间。通常,当程序员不假思索地打开程序编辑器就开始写代码时,他们写的大部分代码稍后就会作废。而经过深思熟虑后写出来的代码错误会更少,而且耗时短。很多程序员不知道如何合理编写程序是有原因的:软件开发的难点在于知道要编写什么,不事先仔细思考就开始盲目工作只会事倍功半。如果你只会实干不会思考,或许软件开发这项工作并不适合你。
10. 不喜欢极客类型的人
出于种种原因(其中一些是合理的),很多人不喜欢与工程师或技术人员相处。如果你认为与像呆伯特或怪人奥尔那样的人相处是一种煎熬的话,那趁早放弃进入编程行业的念头吧。所有的开发人员都像那样性格怪异吗?当然不是。但也不乏古怪的人,这足以让你在这个行业痛苦不堪。
每学一门编程语言,都离不开学习它的语言特征:
支持哪些基本数据类型,如整数,浮点数,布尔值,字符串,支持哪些高级数据类型,如数组,结构体等。
if判断和while循环语句是怎样的,是否有switch或者goto等语句。
语言函数的定义是怎样的,如何传递函数参数,有没有面向对象的语言特征等。
package包管理是怎样的,如何管理一个工程,官方提供哪些标准库,如时间处理,字符串处理,HTTP 库,加密库等。
有没有特殊的语言特征,其他语言没有的,比如某些语法糖。
传统的编程语言通常都会有如下一些缺点:
学习成本太高,如C++,为准确表达作者思想,我们要花费大量时间学习语言
编译速度太慢,代码的编写、预处理、编译与运行流程花费时间太长
缺乏类型检查,主要指诸如perl、python、php等解释性语言,这常会导致一些低级错误发生
而且计算机领域相比于前些年也发生了很多变化,比如:
计算机硬件发展迅速,软件已经不能充分发挥它们的优势,比如多CPU
语言越来越复杂,要么并发与性能不佳,要么风格不够优雅且不统一
人力成本越高越贵,项目的迭代周期越来越短
普通程序员与高级程序员的差别在哪
同样都是敲代码,为什么别人一个月工资几万,你一个月却只拿五千?是单纯在找工作的时候运气不佳?还是因为技术水平有差别?那些被大众膜拜信仰的技术大神到底牛在哪里,现状已定,普通程序员是否还有机会逆袭?或许你能从下面的总结中找到答案。从思维和习惯角度看,普通程序员和高级程序员的差别主要体现在以下四个方面:
缺乏编程思维
编程思维又叫Computational Thinking,指的是从理解问题到解决问题的思考方式,具体到程序员的实际开发工作中来看,当拥有编程思维的程序员接到一个新的需求,他们总是能迅速在大脑中分解复杂问题,将注意力聚焦到重点问题上并提前预设解决路径,比如这个需求对现有逻辑有什么影响?怎样操作才是最优解?一旦变更数据会存在哪些风险?团队最少需要多久的开发周期才能交付?拥有编程思维的高级程序员能从产品经理的需求中思考为什么要这么做。而普通程序员在收到新需求的第一反应大多不是思考,而是吐槽“为什么又要改需求,他/她到底懂不懂产品”,然后在愤懑中闷头敲代码、改Bug、继续敲代码、继续改Bug,陷入无止境的循环当中。到最后,没有编程思维的人,敲再多的代码,也只能做一名普通程序员。
不知道怎么解决Bug
普通程序员发现Bug后,直接复制粘贴靠百度,“一杯茶,一根烟,一个Bug想一天”,能不能解决全靠运气。高级程序员在发现程序报错后,首先会查看浏览器控制台是否发送了对应的请求,如果是的话再看请求码是什么,然后根据不同的错误码做出不同的调试方案,要么通过报错日志找到对应的地点进行修改,要么通过开发工具断点调试,顺藤摸瓜找到最终问题。当问题解决后,有经验的高手往往会复盘总结处理好善后问题,下次再出现类似情况就能第一时间做出反应,普通人与高手的差距往往体现在解决问题的能力上。
没有养成良好的学习习惯
我们大部分人都习惯了接受填鸭式教育,上学期间大家还尚有学习的动力,但有多少人在工作后依然能够保持良好的学习习惯?技术的世界日新月异,当很多人还停留在JDK8的时候JDK16已经悄然问世,从SpringMVC到SpringBoot再到SpringCloud全家桶,不同版本的框架正在以迅雷不及掩耳之势快速更新。很多程序员在毕业后便不再主动学习,他们的技术水平也就停留在了刚进公司的那几个月。时光流逝,每年有大量更年轻、更有热情的应届生走出校门,他们随时都有可能替代掉高薪低性价比的普通程序员,如果没有主动学习、终生学习的意识,这批人注定将会被技术大潮所淘汰。
视野狭窄,缺乏长期的目标规划
程序员长期处在996、007繁忙的工作节奏中,鲜少有时间停下来去思考自己的目标到底是什么,现在的你和刚毕业时的你相比有什么变化?五年之后你希望自己活成什么样子?很多人每天只是马不停蹄地处理各种领导派下来的任务和产品经理提出的新需求,却从来没有驻足思考过自己的目标规划和后续进步的方向。每天在舒适圈中闷头敲代码只会让自己的视野越来越狭窄,当一个程序员做到了一定程度,除了技术本身之外,视野、圈子和人脉变得越来越重要,这也直接关乎程序员个人的晋升空间。
问题摆在面前,普通程序员要想实现技术水平的跃迁,必须有针对性地做出改变。
首先,要敢于自我革新,与过去的思维习惯划清界限重新开始。在日常工作中,多去看看“大神”做的项目,看他在一开始的时候是如何设计项目的,在编程的过程中对数据库进行了哪些操作,以及为什么这么做。久而久之,当你自己的项目遇到复杂的需求时,你也能够在这个思路的基础上进行难点拆分,不断改进优化项目,这将会是你进步的开始。
其次,拓宽视野,培养终生学习的习惯。将目光从个人所在岗位转移到行业中去,多去了解国内外的技术圈发生了什么,多去看看行业内外正在进行哪些变革,每天抽出一个小时的阅读时间,从被动学习转变为主动学习。“人生在勤,不索何获”,只有站在巨人的肩膀上不断学习,才能获得长远发展机会。
最后,制定长期发展目标。想清楚自己到底想要从事什么岗位,未来在这一岗位上想要达到什么结果,将大的目标切分成阶段性目标,以此为导向不断努力。就算阶段性目标失败了也没有关系,回过头复盘总结,看在哪些地方还有进步空间。
深入理解数学与计算机系统
程序员到一定的阶段,拼的数学能力和对计算机系统的理解。数学能力需要投入的教育成本是比较高的,毕竟这是个长期的系统性工程,但是作为 IT 从业者、程序员,我认为还是需要把计算机系统搞明白、搞透,这个过程比起恶补数学,要轻松多了。曾经请教过很多大厂架构师,我发现他们对硬件的掌握水准之高,远远超过我这个硬件开发工程师的预想。看看下面这张图,内存读写流程,这个流程估计很多程序员都搞不太清楚,的确,99% 的几率用不到,但是可能就是那 1% 将决定你的职业走势。
一切信息技术生态都是建立在计算机硬件系统之上的,如果不夯实这个底层领域的知识体系,那么上层的知识体系就难免成为空中楼阁。掌握计算机底层,相当于掌握基本的物理学,正如基本的物理学被纳入义务教育阶段一样,掌握计算机底层,应该是每个 IT 从业者的基本功。
防御性编程二三事
几大基本原则
当开发人员遇到意外的错误无法修复时,他们会“添加一些防御性代码”来使代码更安全,更容易找到问题所在。有时候,仅仅这样做就能解决问题。他们会加强数据验证 —— 确保检查输入和输出字段以及返回值。审查并改进错误处理 —— 也许在 “不可能”的情况周围添加一些检查。增加一些有用的日志记录和诊断功能。换句话说,这些本应该从一开始就存在的代码。
防御性编程的整个目的是为了防范你意想不到的错误。
——Steve McConnell,《代码大全》
防御性编程的几个基本原则在 Steve McConnell 经典著作《代码大全》中有详细解释:
保护你的代码免受 “外部” 传入的无效数据影响,无论你认为 “外部” 是指什么地方。这里指来自外部系统、用户、文件或模块 / 组件之外的任何数据。建立 “壁垒”、“安全区域” 或 “信任边界”——边界之外的一切都是危险的,边界之内的一切都是安全的。在壁垒代码中,验证所有输入数据:检查所有输入参数的正确类型、长度和取值范围。再次检查限制和范围。
在检查完坏数据后,决定如何处理它。防御性编程并不意味着吞没错误或隐藏错误。它是关于在健壮性(如果遇到可处理的问题则继续运行)和正确性(永远不返回错误结果)之间做出权衡。选择一种处理坏数据的策略:立即返回错误并停止运行(快速失败),返回一个中立值,替换数据值等等。确保策略明确且一致。
不要假设你代码之外的函数调用或方法调用会按照广告所述正常工作。确保你理解并测试了周围外部 API 和库的错误处理机制。
使用断言来记录假设,并突出显示 “不可能” 的条件,至少在开发和测试阶段如此。这对于长期由不同人维护或高可靠性代码特别重要。
巧妙地添加诊断代码、日志记录和跟踪功能,以帮助解释运行时发生了什么问题,尤其是当遇到问题时。
标准化错误处理。决定如何处理 “正常错误” 或 “预期错误” 和警告,并始终保持一致。
只在需要时使用异常处理,并确保你对语言的异常处理机制了如指掌。将异常作为正常处理流程的一部分的程序会遭受经典意义上代码结构混乱的可读性和可维护性问题。
Michael Nygard 在《发布!》中还提到了其他几个规则,比如永远不要无限期等待外部调用,尤其是远程调用。当出现问题时,无限期可能会很长时间。使用超时 /重试逻辑以及他的断路器稳定模式来处理远程故障。
对于 C 和 C++ 等编程语言,防御性编程还包括使用安全函数调用来避免缓冲区溢出和常见编码错误。
让自己稳拿饭碗
简介
永远不要(把自己遇到的问题)归因于(他人的)恶意,这恰恰说明了(你自己的)无能。 -- 拿破仑
为了造福大众,在 Java 编程领域创造就业机会,兄弟我在此传授大师们的秘籍。这些大师写的代码极其难以维护,后继者就是想对它做最简单的修改都需要花上数年时间。而且,如果你能对照秘籍潜心修炼,你甚至可以给自己弄个铁饭碗,因为除了你之外,没人能维护你写的代码。再而且,如果你能练就秘籍中的全部招式,那么连你自己都无法维护你的代码了!
你不想练功过度走火入魔吧。那就不要让你的代码一眼看去就完全无法维护,只要它实质上是那样就行了。否则,你的代码就有被重写或重构的风险!
总体原则
Quidquid latine dictum sit, altum sonatur.
(随便用拉丁文写点啥都会显得高大上。)
想挫败维护代码的程序员,你必须先明白他的思维方式。他接手了你的庞大程序,没有时间把它全部读一遍,更别说理解它了。他无非是想快速找到修改代码的位置、改代码、编译,然后就能交差,并希望他的修改不会出现意外的副作用。
他查看你的代码不过是管中窥豹,一次只能看到一小段而已。你要确保他永远看不到全貌。要尽量和让他难以找到他想找的代码。但更重要的是,要让他不能有把握忽略任何东西。
程序员都被编程惯例洗脑了,还为此自鸣得意。每一次你处心积虑地违背编程惯例,都会迫使他必须用放大镜去仔细阅读你的每一行代码。你可能会觉得每个语言特性都可以用来让代码难以维护,其实不然。你必须精心地误用它们才行。
命名
"当我使用一个单词的时候" Humpty Dumpty 曾经用一种轻蔑的口气说," 它就是我想表达的意思,不多也不少。“
- Lewis Carroll -- 《爱丽丝魔镜之旅》, 第 6 章
编写无法维护代码的技巧的重中之重是变量和方法命名的艺术。如何命名是和编译器无关的。这就让你有巨大的自由度去利用它们迷惑维护代码的程序员。
妙用 宝宝起名大全
买本宝宝起名大全,你就永远不缺变量名了。比如 Fred 就是个好名字,而且键盘输入它也省事。如果你就想找一些容易输入的变量名,可以试试 adsf 或者 aoeu 之类。
单字母变量名
如果你给变量起名为 a,b,c,用简单的文本编辑器就没法搜索它们的引用。而且,没人能猜到它们的含义。
创造性的拼写错误
如果你必须使用描述性的变量和函数名,那就把它们都拼错。还可以把某些函数和变量名拼错,再把其他的拼对 (例如 SetPintleOpening 和 SetPintalClosing) ,我们就能有效地将 grep 或 IDE 搜索技术玩弄于股掌之上。这招超级管用。还可以混淆不同语言(比如 colour -- 英国英语,和 color -- 美国英语)。
抽象
在命名函数和变量的时候,充分利用抽象单词,例如 it, everything, data, handle, stuff, do, routine, perform 和数字,例如 e.g. routineX48, PerformDataFunction, DoIt, HandleStuff 还有 do_args_method。
首字母大写的缩写
用首字母大写缩写(比如 GNU 代表 GNU's Not Unix) 使代码简洁难懂。真正的汉子 (无论男女) 从来不说明这种缩写的含义,他们生下来就懂。
辞典大轮换
为了打破沉闷的编程气氛,你可以用一本辞典来查找尽量多的同义词。例如 display, show, present。在注释里含糊其辞地暗示这些命名之间有细微的差别,其实根本没有。不过,如果有两个命名相似的函数真的有重大差别,那倒是一定要确保它们用相同的单词来命名 (例如,对于 "写入文件", "在纸上书写" 和 "屏幕显示" 都用 print 来命名)。在任何情况下都不要屈服于编写明确的项目词汇表这种无理要求。你可以辩解说,这种要求是一种不专业的行为,它违反了结构化设计的信息隐藏原则。
首字母大写
随机地把单词中间某个音节的首字母大写。例如 ComputeReSult()。
重用命名
在语言规则允许的地方,尽量把类、构造器、方法、成员变量、参数和局部变量都命名成一样。更高级的技巧是在 {} 块中重用局部变量。这样做的目的是迫使维护代码的程序员认真检查每个示例的范围。特别是在 Java 代码中,可以把普通方法伪装成构造器。
使用非英语字母
在命名中偷偷使用不易察觉的非英语字母,例如看上去没啥不对是吧?嘿嘿嘿... 这里的第二个 ínt 的 í 实际上是东北欧字母,并不是英语中的 i 。在简单的文本编辑器里,想看出这一点点区别几乎是不可能的。
巧妙利用编译器对于命名长度的限制
如果编译器只区分命名的前几位,比如前 8 位,那么就把后面的字母写得不一样。比如,其实是同一个变量,有时候写成 var_unit_update() ,有时候又写成 var_unit_setup(),看起来是两个不同的函数调用。而在编译的时候,它们其实是同一个变量 var_unit。
下划线,一位真正的朋友
可以拿 _ 和 __ 作为标示符。
混合多语言
随机地混用两种语言(人类语言或计算机语言都行)。如果老板要求使用他指定的语言,你就告诉他你用自己的语言更有利于组织你的思路,万一这招不管用,就去控诉这是语言歧视,并威胁起诉老板要求巨额精神损失赔偿。
扩展 ASCII 字符
扩展 ASCII 字符用于变量命名是完全合法的,包括 ß, Ð, 和 ñ 等。在简单的文本编辑器里,除了拷贝 / 粘贴,基本上没法输入。
其他语言的命名
使用外语字典作为变量名的来源。例如,可以用德语单词 punkt 代替 point。除非维护代码的程序员也像你一样熟练掌握了德语。不然他就只能尽情地在代码中享受异域风情了。
数学命名
用数学操作符的单词来命名变量。例如:
openParen = (slash + asterix) / equals;
(左圆括号 = (斜杠 + 星号)/ 等号;)
令人眩晕的命名
用带有完全不相关的感情色彩的单词来命名变量。例如:这一招可以让阅读代码的人陷入迷惑之中,因为他们在试图想清楚这些命名的逻辑时,会不自觉地联系到不同的感情场景里而无法自拔。
marypoppins = (superman + starship) / god;
(欢乐满人间 = (超人 + 星河战队)/ 上帝;)
何时使用 i
永远不要把 i 用作最内层的循环变量。 用什么命名都行,就是别用 i。把 i 用在其他地方就随便了,用作非整数变量尤其好。
惯例 -- 明修栈道,暗度陈仓
忽视 Java 编码惯例,Sun 就是这样做的。幸运的是,你违反了它编译器也不会打小报告。这一招的目的是搞出一些在某些特殊情况下有细微差别的名字来。如果你被强迫遵循驼峰法命名,你还是可以在某些模棱两可的情况下颠覆它。例如,inputFilename 和 inputfileName 两个命名都可以合法使用。在此基础上自己发明一套复杂到变态的命名惯例,然后就可以痛扁其他人,说他们违反了惯例。
小写的 l 看上去很像数字 1
用小写字母 l 标识 long 常数。例如 10l 更容易被误认为是 101 而不是 10L 。 禁用所有能让人准确区分 uvw wW gq9 2z 5s il17|!j oO08 `'" ;,. m nn rn {[()]} 的字体。要做个有创造力的人。
把全局命名重用为私有
在 A 模块里声明一个全局数组,然后在 B 模块的头文件里在声明一个同名的私有数组,这样看起来你在 B 模块里引用的是那个全局数组,其实却不是。不要在注释里提到这个重复的情况。
误导性的命名
让每个方法都和它的名字蕴含的功能有一些差异。例如,一个叫 isValid(x) 的方法在判断完参数 x 的合法性之后,还顺带着把它转换成二进制并保存到数据库里。
伪装
当一个 bug 需要越长的时间才会暴露,它就越难被发现。
- Roedy Green(本文作者)
编写无法维护代码的另一大秘诀就是伪装的艺术,即隐藏它或者让它看起来像其他东西。很多招式有赖于这样一个事实:编译器比肉眼或文本编辑器更有分辨能力。下面是一些伪装的最佳招式。
把代码伪装成注释,反之亦然
下面包括了一些被注释掉的代码,但是一眼看去却像是正常代码。 如果不是用绿色标出来,你能注意到这三行代码被注释掉了么?
for(j=0; j<array_len; j+ =8){
total += array[j+0 ];
total += array[j+1 ];
total += array[j+2 ]; /* Main body of
total += array[j+3]; * loop is unrolled
total += array[j+4]; * for greater speed.
total += array[j+5]; */
total += array[j+6 ];
total += array[j+7 ];
}
用连接符隐藏变量
对于下面的定义
#define local_var xy_z
可以把 "xy_z" 打散到两行里:
#define local_var xy\
_z // local_var OK
这样全局搜索 xy_z 的操作在这个文件里就一无所获了。对于 C 预处理器来说,第一行最后的 "\" 表示继续拼接下一行的内容。
文档
任何傻瓜都能说真话,而要把谎编圆则需要相当的智慧。
- Samuel Butler (1835 - 1902)
不正确的文档往往比没有文档还糟糕。
- Bertrand Meyer
既然计算机是忽略注释和文档的,你就可以在里边堂而皇之地编织弥天大谎,让可怜的维护代码的程序员彻底迷失。
在注释中撒谎
实际上你不需要主动地撒谎,只要没有及时保持注释和代码更新的一致性就可以了。
只记录显而易见的东西
往代码里掺进去类似于 /* 给 i 加 1 */ 这样的注释,但是永远不要记录包或者方法的整体设计这样的干货。
记录 How 而不是 Why
只解释一个程序功能的细节,而不是它要完成的任务是什么。这样的话,如果出现了一个 bug,修复者就搞不清这里的代码应有的功能。
该写的别写
比如你在开发一套航班预定系统,那就要精心设计,让它在增加另一个航空公司的时候至少有 25 处代码需要修改。永远不要在文档里说明要修改的位置。后来的开发人员要想修改你的代码门都没有,除非他们能把每一行代码都读懂。
计量单位
永远不要在文档中说明任何变量、输入、输出或参数的计量单位,如英尺、米、加仑等。计量单位对数豆子不是太重要,但在工程领域就相当重要了。同理,永远不要说明任何转换常量的计量单位,或者是它的取值如何获得。要想让代码更乱的话,你还可以在注释里写上错误的计量单位,这是赤裸裸的欺骗,但是非常有效。如果你想做一个恶贯满盈的人,不妨自己发明一套计量单位,用自己或某个小人物的名字命名这套计量单位,但不要给出定义。万一有人挑刺儿,你就告诉他们,你这么做是为了把浮点数运算凑成整数运算而进行的转换。
坑
永远不要记录代码中的坑。如果你怀疑某个类里可能有 bug,天知地知你知就好。如果你想到了重构或重写代码的思路,看在老天爷的份上,千万别写出来。切记电影《小鹿斑比》里那句台词 "如果你不能说好听的话,那就什么也不要说。"。万一这段代码的原作者看到你的注释怎么办?万一老板看到了怎么办?万一客户看到了怎么办?搞不好最后你自己被解雇了。一句” 这里需要修改 “的匿名注释就好多了,尤其是当看不清这句注释指的是哪里需要修改的情况下。切记难得糊涂四个字,这样大家都不会感觉受到了批评。
说明变量
永远不要对变量声明加注释。有关变量使用的方式、边界值、合法值、小数点后的位数、计量单位、显示格式、数据录入规则等等,后继者完全可以自己从程序代码中去理解和整理嘛。如果老板强迫你写注释,就把方法体代码混进去,但绝对不要对变量声明写注释,即使是临时变量!
在注释里挑拨离间
为了阻挠任何雇佣外部维护承包商的倾向,可以在代码中散布针对其他同行软件公司的攻击和抹黑,特别是可能接替你工作的其中任何一家。例如:
/* 优化后的内层循环
这套技巧对于 SSI 软件服务公司的那帮蠢材来说太高深了,他们只会
用 <math.h> 里的笨例程,消耗 50 倍的内存和处理时间。
*/
class clever_SSInc
{
.. .
}
可能的话,除了注释之外,这些攻击抹黑的内容也要掺到代码里的重要部分,这样如果管理层想清理掉这些攻击性的言论然后发给外部承包商去维护,就会破坏代码结构。
程序设计
编写无法维护代码的基本规则就是:在尽可能多的地方,以尽可能多的方式表述每一个事实。
- Roedy Green
编写可维护代码的关键因素是只在一个地方表述应用里的一个事实。如果你的想法变了,你也只在一个地方修改,这样就能保证整个程序正常工作。所以,编写无法维护代码的关键因素就是反复地表述同一个事实,在尽可能多的地方,以尽可能多的方式进行。令人高兴的是,像 Java 这样的语言让编写这种无法维护代码变得非常容易。例如,改变一个被引用很多的变量的类型几乎是不可能的,因为所有造型和转换功能都会出错,而且关联的临时变量的类型也不合适了。而且,如果变量值要在屏幕上显示,那么所有相关的显示和数据录入代码都必须一一找到并手工进行修改。类似的还有很多,比如由 C 和 Java 组成的 Algol 语言系列,Abundance 甚至 Smalltalk 对于数组等结构的处理,都是大有可为的。
Java 造型
Java 的造型机制是上帝的礼物。你可以问心无愧地使用它,因为 Java 语言本身就需要它。每次你从一个 Collection 里获取一个对象,你都必须把它造型为原始类型。这样这个变量的类型就必须在无数地方表述。如果后来类型变了,所有的造型都要修改才能匹配。如果倒霉的维护代码的程序员没有找全(或者修改太多),编译器能不能检测到也不好说。类似的,如果变量类型从 short 变成 int,所有匹配的造型也都要从 (short) 改成 (int)。
利用 Java 的冗余
Java 要求你给每个变量的类型写两次表述。 Java 程序员已经习惯了这种冗余,他们不会注意到你的两次表述有细微的差别,例如
Bubblegum b = new Bubblegom();
不幸的是 ++ 操作符的盛行让下面这种伪冗余代码得手的难度变大了:
swimmer = swimner + 1;
永远不做校验
永远不要对输入数据做任何的正确性或差异性检查。这样能表现你对公司设备的绝对信任,以及你是一位信任所有项目伙伴和系统管理员的团队合作者。总是返回合理的值,即使数据输入有问题或者错误。
有礼貌,无断言
避免使用 assert () 机制,因为它可能把三天的 debug 盛宴变成 10 分钟的快餐。
避免封装
为了提高效率,不要使用封装。方法的调用者需要所有能得到的外部信息,以便了解方法的内部是如何工作的。
复制粘贴修改
以效率的名义,使用 复制 + 粘贴 + 修改。这样比写成小型可复用模块效率高得多。在用代码行数衡量你的进度的小作坊里,这招尤其管用。
使用静态数组
如果一个库里的模块需要一个数组来存放图片,就定义一个静态数组。没人会有比 512 X 512 更大的图片,所以固定大小的数组就可以了。为了最佳精度,就把它定义成 double 类型的数组。
傻瓜接口
编写一个名为 "WrittenByMe" 之类的空接口,然后让你的所有类都实现它。然后给所有你用到的 Java 内置类编写包装类。这里的思想是确保你程序里的每个对象都实现这个接口。最后,编写所有的方法,让它们的参数和返回类型都是这个 WrittenByMe。这样就几乎不可能搞清楚某个方法的功能是什么,并且所有类型都需要好玩的造型方法。更出格的玩法是,让每个团队成员编写它们自己的接口 (例如 WrittenByJoe),程序员用到的任何类都要实现他自己的接口。这样你就可以在大量无意义接口中随便找一个来引用对象了。
巨型监听器
永远不要为每个组件创建分开的监听器。对所有按钮总是用同一个监听器,只要用大量的 if...else 来判断是哪一个按钮被点击就行了。
好事成堆 TM
狂野地使用封装和 OO 思想。例如这段很可能看起来不怎么好笑。别担心,只是时候未到而已。
myPanel.add( getMyButton() );
private JButton getMyButton()
{
return myButton;
}
友好的朋友
在 C++ 里尽量多使用 friend 声明。再把创建类的指针传递给已创建类。现在你不用浪费时间去考虑接口了。另外你应该用上关键字 private 和 protected 来表明你的类封装得很好。
使用三维数组
大量使用它们。用扭曲的方式在数组之间移动数据,比如用 arrayA 里的行去填充 arrayB 的列。这么做的时候,不管三七二十一再加上 1 的偏移值,这样很灵。让维护代码的程序员抓狂去吧。
混合与匹配
存取方法和公共变量神马的都要给他用上。这样的话,你无需调用存取器的开销就可以修改一个对象的变量,还能宣称这个类是个 "Java Bean"。对于那些试图添加日志函数来找出改变值的源头的维护代码的程序员,用这一招来迷惑他尤其有效。
没有秘密!
把每个方法和变量都声明为 public。毕竟某个人某天可能会需要用到它。一旦方法被声明为 public 了,就很难缩回去。对不?这样任何它覆盖到的代码都很难修改了。它还有个令人愉快的副作用,就是让你看不清类的作用是什么。如果老板质问你是不是疯了,你就告诉他你遵循的是经典的透明接口原则。
全堆一块
把你所有的没用的和过时的方法和变量都留在代码里。毕竟说起来,既然你在 1976 年用过一次,谁知道你啥时候会需要再用到呢?当然程序是改了,但它也可能会改回来嘛,你"不想要重新发明轮子"(领导们都会喜欢这样的口气)。如果你还原封不动地留着这些方法和变量的注释,而且注释写得又高深莫测,甭管维护代码的是谁,恐怕都不敢对它轻举妄动。
就是 Final
把你所有的叶子类都声明为 final。毕竟说起来,你在项目里的活儿都干完了,显然不会有其他人会通过扩展你的类来改进你的代码。这种情况甚至可能有安全漏洞。 java.lang.String 被定义成 final 也许就是这个原因吧?如果项目组其他程序员有意见,告诉他们这样做能够提高运行速度。
避免布局
永远不要用到布局。当维护代码的程序员想增加一个字段,他必须手工调整屏幕上显示所有内容的绝对坐标值。如果老板强迫你使用布局,那就写一个巨型的 GridBagLayout 并在里面用绝对坐标进行硬编码。
全局变量,怎么强调都不过分
如果上帝不愿意我们使用全局变量,他就不会发明出这个东西。不要让上帝失望,尽量多使用全局变量。每个函数最起码都要使用和设置其中的两个,即使没有理由也要这么做。毕竟,任何优秀的维护代码的程序员都会很快搞清楚这是一种侦探工作测试,有利于让他们从笨蛋中脱颖而出。
再一次说说全局变量
全局变量让你可以省去在函数里描述参数的麻烦。充分利用这一点。在全局变量中选那么几个来表示对其他全局变量进行操作的类型。
局部变量
永远不要用局部变量。在你感觉想要用的时候,把它改成一个实例或者静态变量,并无私地和其他方法分享它。这样做的好处是,你以后在其他方法里写类似声明的时候会节省时间。C++ 程序员可以百尺竿头更进一步,把所有变量都弄成全局的。
配置文件
配置文件通常是以 关键字 = 值 的形式出现。在加载时这些值被放入 Java 变量中。最明显的迷惑技术就是把有细微差别的名字用于关键字和 Java 变量。甚至可以在配置文件里定义运行时根本不会改变的常量。参数文件变量和简单变量比,维护它的代码量起码是后者的 5 倍。
子类
对于编写无法维护代码的任务来说,面向对象编程的思想简直是天赐之宝。如果你有一个类,里边有 10 个属性(成员/方法),可以考虑写一个基类,里面只有一个属性,然后产生 9 层的子类,每层增加一个属性。等你访问到最终的子类时,你才能得到全部 10 个属性。如果可能,把每个类的声明都放在不同的文件里。
编码迷局
迷惑 C
从互联网上的各种混乱 C 语言竞赛中学习,追随大师们的脚步。
追求极致
总是追求用最迷惑的方式来做普通的任务。例如要用数组来把整数转换为相应的字符串,可以这么做:
char *p;
switch (n){
case 1:
p = "one";
if (0)
case 2:
p = "two";
if (0)
case 3:
p = "three";
printf("%s", p);
break;
}
一致性的小淘气
当你需要一个字符常量的时候,可以用多种不同格式: ' ', 32, 0x20, 040。在 C 或 Java 里 10 和 010 是不同的数(0 开头的表示 16 进制),你也可以充分利用这个特性。
造型
把所有数据都以 void * 形式传递,然后再造型为合适的结构。不用结构而是通过位移字节数来造型也很好玩。
嵌套 Switch
Switch 里边还有 Switch,这种嵌套方式是人类大脑难以破解的。
利用隐式转化
牢记编程语言中所有的隐式转化细节。充分利用它们。数组的索引要用浮点变量,循环计数器用字符,对数字执行字符串函数调用。不管怎么说,所有这些操作都是合法的,它们无非是让源代码更简洁而已。任何尝试理解它们的维护者都会对你感激不尽,因为他们必须阅读和学习整个关于隐式数据类型转化的章节,而这个章节很可能是他们来维护你的代码之前完全忽略了的。
分号!
在所有语法允许的地方都加上分号,例如:
if(a);
else;
{
int d;
d = c;
};
使用八进制数
把八进制数混到十进制数列表里,就像这样:
array = new int []
{
111,
120,
013,
121,
};
嵌套
尽可能深地嵌套。优秀的程序员能在一行代码里写 10 层 (),在一个方法里写 20 层 {}。
C 数组
C 编译器会把 myArray[i] 转换成 *(myArray + i),它等同于 *(i + myArray) 也等同于 i[myArray]。高手都知道怎么用好这个招。可以用下面的函数来产生索引,这样就把代码搞乱了:
int myfunc(int q, int p) { return p%q; }
...
myfunc(6291, 8)[Array];
遗憾的是,这一招只能在本地 C 类里用,Java 还不行。
放长线钓大鱼
一行代码里堆的东西越多越好。这样可以省下临时变量的开销,去掉换行和空格还可以缩短源文件大小。记住,要去掉运算符两边的空格。优秀的程序员总是能突破某些编辑器对于 255 个字符行宽的限制。
异常
我这里要向你传授一个编程中鲜为人知的秘诀。异常是个讨厌的东西。良好的代码永远不会出错,所以异常实际上是不必要的。不要把时间浪费在这上面。子类异常是给那些知道自己代码会出错的低能儿用的。在整个应用里,你只用在 main () 里放一个 try/catch,里边直接调用 System.exit () 就行了。在每个方法头要贴上标准的抛出集合定义,到底会不会抛出异常你就不用管了。
使用异常的时机
在非异常条件下才要使用异常。比如终止循环就可以用 ArrayIndexOutOfBoundsException。还可以从异常里的方法返回标准的结果。
狂热奔放地使用线程
测试
在程序里留些 bug,让后继的维护代码的程序员能做点有意思的事。精心设计的 bug 是无迹可寻的,而且谁也不知道它啥时候会冒出来。要做到这一点,最简单的办法的就是不要测试代码。
永不测试
永远不要测试负责处理错误、当机或操作系故障的任何代码。反正这些代码永远也不会执行,只会拖累你的测试。还有,你怎么可能测试处理磁盘错误、文件读取错误、操作系统崩溃这些类型的事件呢?为啥你要用特别不稳定的计算机或者用测试脚手架来模拟这样的环境?现代化的硬件永远不会崩溃,谁还愿意写一些仅仅用于测试的代码?这一点也不好玩。如果用户抱怨,你就怪到操作系统或者硬件头上。他们永远不会知道真相的。
永远不要做性能测试
嘿,如果软件运行不够快,只要告诉客户买个更快的机器就行了。如果你真的做了性能测试,你可能会发现一个瓶颈,这会导致修改算法,然后导致整个产品要重新设计。谁想要这种结果?而且,在客户那边发现性能问题意味着你可以免费到外地旅游。你只要备好护照和最新照片就行了。
永远不要写任何测试用例
永远不要做代码覆盖率或路径覆盖率测试。自动化测试是给那些窝囊废用的。搞清楚哪些特性占到你的例程使用率的 90%,然后把 90% 的测试用在这些路径上。毕竟说起来,这种方法可能只测试到了大约你代码的 60%,这样你就节省了 40% 的测试工作。这能帮助你赶上项目后端的进度。等到有人发现所有这些漂亮的 “市场特性” 不能正常工作的时候,你早就跑路了。一些有名的大软件公司就是这样测试代码的,所以你也应该这样做。如果因为某种原因你还没走,那就接着看下一节。
测试是给懦夫用的
勇敢的程序员会跳过这个步骤。太多程序员害怕他们的老板,害怕丢掉工作,害怕客户的投诉邮件,害怕遭到起诉。这种恐惧心理麻痹了行动,降低了生产率。有科学研究成果表明,取消测试阶段意味着经理有把握能提前确定交付时间,这对于规划流程显然是有利的。消除了恐惧心理,创新和实验之花就随之绽放。程序员的角色是生产代码,调试工作完全可以由技术支持和遗留代码维护组通力合作来进行。
如果我们对自己的编程能力有充分信心,那么测试就没有必要了。如果我们逻辑地看待这个问题,随便一个傻瓜都能认识到测试根本都不是为了解决技术问题,相反,它是一种感性的信心问题。针对这种缺乏信心的问题,更有效的解决办法就是完全取消测试,送我们的程序员去参加自信心培训课程。毕竟说起来,如果我们选择做测试,那么我们就要测试每个程序的变更,但其实我们只需要送程序员去一次建立自信的培训课就行了。很显然这么做的成本收益是相当可观的。
编程语言的选择
计算机语言正在逐步进化,变得更加傻瓜化。使用最新的语言是不人性的。尽可能坚持使用你会用的最老的语言,先考虑用穿孔纸带,不行就用汇编,再不行用 FORTRAN 或者 COBOL,再不行就用 C 还有 BASIC,实在不行再用 C++。
FØRTRAN
用 FORTRAN 写所有的代码。如果老板问你为啥,你可以回答说有很多它非常有用的库,你用了可以节约时间。不过,用 FORTRAN 写出可维护代码的概率是 0,所以,要达到不可维护代码编程指南里的要求就容易多了。
用 ASM
把所有的通用工具函数都转成汇编程序。
用 QBASIC
所有重要的库函数都要用 QBASIC 写,然后再写个汇编的封包程序来处理 large 到 medium 的内存模型映射。
内联汇编
在你的代码里混杂一些内联的汇编程序,这样很好玩。这年头几乎没人懂汇编程序了。只要放几行汇编代码就能让维护代码的程序员望而却步。
宏汇编调用 C
如果你有个汇编模块被 C 调用,那就尽可能经常从汇编模块再去调用 C,即使只是出于微不足道的用途,另外要充分利用 goto, bcc 和其他炫目的汇编秘籍。
与他人共事之道
老板才是真行家
如果你的老板认为他 20 年的 FORTRAN 编程经验对于现代软件开发具有很高的指导价值,你务必严格采纳他的所有建议。投桃报李,你的老板也会信任你。这会对你的职业发展有利。你还会从他那里学到很多搞乱程序代码的新方法。
颠覆技术支持
确保代码中到处是 bug 的有效方法是永远不要让维护代码的程序员知道它们。这需要颠覆技术支持工作。永远不接电话。使用自动语音答复 “感谢拨打技术支持热线。需要人工服务请按 1,或在嘀声后留言。”,请求帮助的电子邮件必须忽略,不要给它分配服务追踪号。对任何问题的标准答复是 “我估计你的账户被锁定了,有权限帮你恢复的人现在不在。”
沉默是金
永远不要对下一个危机保持警觉。如果你预见到某个问题可能会在一个固定时间爆发,摧毁西半球的全部生命,不要公开讨论它。不要告诉朋友、同事或其他你认识的有本事的人。在任何情况下都不要发表任何可能暗示到这种新的威胁的内容。只发送一篇正常优先级的、语焉不详的备忘录给管理层,保护自己免遭秋后算账。如果可能的话,把这篇稀里糊涂的信息作为另外一个更紧急的业务问题的附件。这样就可以心安理得地休息了,你知道将来你被强制提前退休之后一段时间,他们又会求着你回来,并给你对数级增长的时薪!
每月一书俱乐部
加入一个计算机每月一书俱乐部。选择那些看上去忙着写书不可能有时间真的去写代码的作者。去书店里找一些有很多图表但是没有代码例子的书。浏览一下这些书,从中学会一些迂腐拗口的术语,用它们就能唬住那些自以为是的维护代码的程序员。你的代码肯定会给他留下深刻印象。如果人们连你写的术语都理解不了,他们一定会认为你非常聪明,你的算法非常深奥。不要在你的算法说明里作任何朴素的类比。
自立门户
你一直想写系统级的代码。现在机会来了。忽略标准库, 编写你自己的标准,这将会是你简历中的一个亮点。
推出你自己的 BNF 范式
总是用你自创的、独一无二的、无文档的 BNF 范式记录你的命令语法。永远不要提供一套带注解的例子(合法命令和非法命令之类)来解释你的语法体系。那样会显得完全缺乏学术严谨性。确保没有明显的方式来区分终结符和中间符号。永远不要用字体、颜色、大小写和其他任何视觉提示帮助读者分辨它们。在你的 BNF 范式用和命令语言本身完全一样的标点符号,这样读者就永远无法分清一段 (...), [...], {...} 或 "..." 到底是你在命令行里真正输入的,还是想提示在你的 BNF 范式里哪个语法元素是必需的、可重复的、或可选的。不管怎么样,如果他们太笨,搞不清你的 BNF 范式的变化,就没资格使用你的程序。
推出你自己的内存分配
地球人儿都知道,调试动态存储是复杂和费时的。与其逐个类去确认它没有内存溢出,还不如自创一套存储分配机制呢。其实它无非是从一大片内存中 malloc 一块空间而已。用不着释放内存,让用户定期重启动系统,这样不就清除了堆么。重启之后系统需要追踪的就那么一点东西,比起解决所有的内存泄露简单得不知道到哪里去了!而且,只要用户记得定期重启系统,他们也永远不会遇到堆空间不足的问题。一旦系统被部署,你很难想象他们还能改变这个策略。
其他杂七杂八的招
如果你给某人一段程序,你会让他困惑一天;如果你教他们如何编程,你会让他困惑一辈子。 -- Anonymous
不要重编译
让我们从一条可能是有史以来最友好的技巧开始:把代码编译成可执行文件。如果它能用,就在源代码里做一两个微小的改动 -- 每个模块都照此办理。但是不要费劲巴拉地再编译一次了。 你可以留着等以后有空而且需要调试的时候再说。多年以后,等可怜的维护代码的程序员更改了代码之后发现出错了,他会有一种错觉,觉得这些肯定是他自己最近修改的。这样你就能让他毫无头绪地忙碌很长时间。
挫败调试工具
对于试图用行调试工具追踪来看懂你的代码的人,简单的一招就能让他狼狈不堪,那就是把每一行代码都写得很长。特别要把 then 语句 和 if 语句放在同一行里。他们无法设置断点。他们也无法分清在看的分支是哪个 if 里的。
公制和美制
在工程方面有两种编码方式。一种是把所有输入都转换为公制(米制)计量单位,然后在输出的时候自己换算回各种民用计量单位。另一种是从头到尾都保持各种计量单位混合在一起。总是选择第二种方式,这就是美国之道!
持续改进
要持续不懈地改进。要常常对你的代码做出 “改进”,并强迫用户经常升级 -- 毕竟没人愿意用一个过时的版本嘛。即便他们觉得他们对现有的程序满意了,想想看,如果他们看到你又 “完善 “了它,他们会多么开心啊!不要告诉任何人版本之间的差别,除非你被逼无奈 -- 毕竟,为什么要告诉他们本来永远也不会注意到的一些 bug 呢?
“关于”
“关于” 一栏应该只包含程序名、程序员姓名和一份用法律用语写的版权声明。理想情况下,它还应该链接到几 MB 的代码,产生有趣的动画效果。但是,里边永远不要包含程序用途的描述、它的版本号、或最新代码修改日期、或获取更新的网站地址、或作者的 email 地址等。这样,所有的用户很快就会运行在不同的版本上,在安装 N+1 版之前就试图安装 N+2 版。
变更
在两个版本之间,你能做的变更自然是多多益善。你不会希望用户年复一年地面对同一套老的接口或用户界面,这样会很无聊。最后,如果你能在用户不注意的情况下做出这些变更,那就更好了 -- 这会让他们保持警惕,戒骄戒躁。
无需技能
写无法维护代码不需要多高的技能。喊破嗓子不如甩开膀子,不管三七二十一开始写代码就行了。记住,管理层还在按代码行数考核生产率,即使以后这些代码里的大部分都得删掉。
只带一把锤子
一招鲜吃遍天,轻装前进。如果你手头只有一把锤子,那么所有的问题都是钉子。
规范体系
有可能的话,忽略当前你的项目所用语言和环境中被普罗大众所接受的编程规范。比如,编写基于 MFC 的应用时,就坚持使用 STL 编码风格。
翻转通常的 True False 惯例
把常用的 true 和 false 的定义反过来用。这一招听起来平淡无奇,但是往往收获奇效。你可以先藏好下面的定义:
#define TRUE 0
#define FALSE 1
把这个定义深深地藏在代码中某个没人会再去看的文件里不易被发现的地方,然后让程序做下面这样的比较
if ( var == TRUE )
if ( var != FALSE )
某些人肯定会迫不及待地跳出来 “修正” 这种明显的冗余,并且在其他地方照着常规去使用变量 var:
if ( var )
还有一招是为 TRUE 和 FALSE 赋予相同的值,虽然大部分人可能会看穿这种骗局。给它们分别赋值 1 和 2 或者 -1 和 0 是让他们瞎忙乎的方式里更精巧的,而且这样做看起来也不失对他们的尊重。你在 Java 里也可以用这一招,定义一个叫 TRUE 的静态常量。在这种情况下,其他程序员更有可能怀疑你干的不是好事,因为 Java 里已经有了内建的标识符 true。
第三方库
在你的项目里引入功能强大的第三方库,然后不要用它们。潜规则就是这样,虽然你对这些好的工具仍然一无所知,却还是可以在你简历的 “其他工具” 一节中写上这些没用过的库。
不要用库
假装不知道有些库已经直接在你的开发工具中引入了。如果你用 VC++ 编程,忽略 MFC 或 STL 的存在,手工编写所有字符串和数组的实现;这样有助于保持你的指针技术,并自动阻止任何扩展代码功能的企图。
创建一套 Build 顺序
把这套顺序规则做得非常晦涩,让维护者根本无法编译任何他的修改代码。秘密保留 SmartJ ,它会让 make 脚本形同废物。类似地,偷偷地定义一个 javac 类,让它和编译程序同名。说到大招,那就是编写和维护一个定制的小程序,在程序里找到需要编译的文件,然后通过直接调用 sun.tools.javac.Main 编译类来进行编译。
Make 的更多玩法
用一个 makefile-generated-batch-file 批处理文件从多个目录复制源文件,文件之间的覆盖规则在文档中是没有的。这样,无需任何炫酷的源代码控制系统,就能实现代码分支,并阻止你的后继者弄清哪个版本的 DoUsefulWork () 才是他需要修改的那个。
搜集编码规范
尽可能搜集所有关于编写可维护代码的建议,例如 SquareBox 的建议 ,然后明目张胆地违反它们。
规避公司的编码规则
某些公司有严格的规定,不允许使用数字标识符,你必须使用预先命名的常量。要挫败这种规定背后的意图太容易了。比如,一位聪明的 C++ 程序员是这么写的:
#define K_ONE 1
#define K_TWO 2
#define K_THOUSAND 999
编译器警告
一定要保留一些编译器警告。在 make 里使用 “-” 前缀强制执行,忽视任何编译器报告的错误。这样,即使维护代码的程序员不小心在你的源代码里造成了一个语法错误,make 工具还是会重新把整个包 build 一遍,甚至可能会成功!而任何程序员要是手工编译你的代码,看到屏幕上冒出一堆其实无关紧要的警告,他们肯定会觉得是自己搞坏了代码。同样,他们一定会感谢你让他们有找错的机会。学有余力的同学可以做点手脚让编译器在打开编译错误诊断工具时就没法编译你的程序。当然了,编译器也许能做一些脚本边界检查,但是真正的程序员是不用这些特性的,所以你也不该用。既然你用自己的宝贵时间就能找到这些精巧的 bug,何必还多此一举让编译器来检查错误呢?
把 bug 修复和升级混在一起
永远不要推出什么 “bug 修复 " 版本。一定要把 bug 修复和数据库结构变更、复杂的用户界面修改,还有管理界面重写等混在一起。那样的话,升级就变成一件非常困难的事情,人们会慢慢习惯 bug 的存在并开始称他们为特性。那些真心希望改变这些” 特性 “的人们就会有动力升级到新版本。这样从长期来说可以节省你的维护工作量,并从你的客户那里获得更多收入。
在你的产品发布每个新版本的时候都改变文件结构
没错,你的客户会要求向上兼容,那就去做吧。不过一定要确保向下是不兼容的。这样可以阻止客户从新版本回退,再配合一套合理的 bug 修复规则(见上一条),就可以确保每次新版本发布后,客户都会留在新版本。学有余力的话,还可以想办法让旧版本压根无法识别新版本产生的文件。那样的话,老版本系统不但无法读取新文件,甚至会否认这些文件是自己的应用系统产生的!温馨提示:PC 上的 Word 文字处理软件就典型地精于此道。
抵消 Bug
不用费劲去代码里找 bug 的根源。只要在更高级的例程里加入一些抵销它的代码就行了。这是一种很棒的智力测验,类似于玩 3D 棋,而且能让将来的代码维护者忙乎很长时间都想不明白问题到底出在哪里:是产生数据的低层例程,还是莫名其妙改了一堆东西的高层代码。这一招对天生需要多回合执行的编译器也很好用。你可以在较早的回合完全避免修复问题,让较晚的回合变得更加复杂。如果运气好,你永远都不用和编译器前端打交道。学有余力的话,在后端做点手脚,一旦前端产生的是正确的数据,就让后端报错。
使用旋转锁
不要用真正的同步原语,多种多样的旋转锁更好 -- 反复休眠然后测试一个 (non-volatile 的) 全局变量,直到它符合你的条件为止。相比系统对象,旋转锁使用简便,” 通用 “性强,” 灵活 “多变,实为居家旅行必备。
随意安插 sync 代码
把某些系统同步原语安插到一些用不着它们的地方。本人曾经在一段不可能会有第二个线程的代码中看到一个临界区(critical section)代码。本人当时就质问写这段代码的程序员,他居然理直气壮地说这么写是为了表明这段代码是很” 关键 “(也是 critical)的!
优雅降级
如果你的系统包含了一套 NT 设备驱动,就让应用程序负责给驱动分配 I/O 缓冲区,然后在任何交易过程中对内存中的驱动加锁,并在交易完成后释放或解锁。这样一旦应用非正常终止,I/O 缓存又没有被解锁,NT 服务器就会当机。但是在客户现场不太可能会有人知道怎么弄好设备驱动,所以他们就没有选择(只能请你去免费旅游了)。
定制脚本语言
在你的 C/S 应用里嵌入一个在运行时按字节编译的脚本命令语言。
依赖于编译器的代码
如果你发现在你的编译器或解释器里有个 bug,一定要确保这个 bug 的存在对于你的代码正常工作是至关重要的。毕竟你又不会使用其他的编译器,其他任何人也不允许!
一个货真价实的例子
下面是一位大师编写的真实例子。让我们来瞻仰一下他在这样短短几行 C 函数里展示的高超技巧。
void* Realocate(void*buf, int os, int ns){
void*temp;
temp = malloc(os);
memcpy((void*)temp, (void*)buf, os);
free(buf);
buf = malloc(ns);
memset(buf, 0, ns);
memcpy((void*)buf, (void*)temp, ns);
return buf;
}
重新发明了标准库里已有的简单函数。
Realocate 这个单词拼写错误。所以说,永远不要低估创造性拼写的威力。
无缘无故地给输入缓冲区产生一个临时的副本。
无缘无故地造型。 memcpy () 里有 (void*),这样即使我们的指针已经是 (void*) 了也要再造型一次。另外这样可以传递任何东西作为参数,加 10 分。
永远不必费力去释放临时内存空间。这样会导致缓慢的内存泄露,一开始看不出来,要程序运行一段时间才行。
把用不着的东西也从缓冲区里拷贝出来,以防万一。这样只会在 Unix 上产生 core dump,Windows 就不会。
很显然,os 和 ns 的含义分别是”old size"和"new size"。
给 buf 分配内存之后,memset 初始化它为 0。不要使用 calloc (),因为某些人会重写 ANSI 规范,这样将来保不齐 calloc () 往 buf 里填的就不是 0 了。(虽然我们复制过去的数据量和 buf 的大小是一样的,不需要初始化,不过这也无所谓啦)
如何修复 "unused variable" 错误
如果你的编译器冒出了 "unused local variable" 警告,不要去掉那个变量。相反,要找个聪明的办法把它用起来。我最喜欢的方法是:
i = i;
大小很关键
差点忘了说了,函数是越大越好。跳转和 GOTO 语句越多越好。那样的话,想做任何修改都需要分析很多场景。这会让维护代码的程序员陷入千头万绪之中。如果函数真的体型庞大的话,对于维护代码的程序员就是哥斯拉怪兽了,它会在他搞清楚情况之前就残酷无情地将他们踩翻在地。
一张图片顶 1000 句话,一个函数就是 1000 行
把每个方法体写的尽可能的长 -- 最好是你写的任何方法或函数都没有少于 1000 行代码的,而且里边深度嵌套,这是必须的。
少个文件
一定要保证一个或多个关键文件是找不到的。利用 includes 里边再 includes 就能做到这一点。例如,在你的 main 模块里,你写上:
#include <stdcode.h>
Stdcode.h 是有的。但是在 stdcode.h 里,还有个引用:
#include "a:\\refcode.h"
然后,refcode.h 就没地方能找到了。
到处可写,无处可读
至少要把一个变量弄成这样:到处被设置,但是几乎没有哪里用到它。不幸的是,现代编译器通常会阻止你做相反的事:到处读,没处写。不过你在 C 或 C++ 里还是可以这样做的。
该文章最后由 阿炯 于 2023-12-08 14:45:40 更新,目前是第 2 版。